



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Bozhou Zhang等
编辑 | 自动驾驶之心
端到端自动驾驶的核心目标是将原始传感器输入直接映射为未来驾驶轨迹,无需传统模块化流水线(如单独的感知、预测、规划模块)。这类方法虽简化了系统设计,但现有方案多采用one-shot的范式——仅依赖当前时刻的场景信息推理自车轨迹(图1),会导致两个问题:
忽略场景动态演化:在复杂交互场景(如车流变道、路口转弯)中,无法预测周围环境(如其他车辆、行人)的时序变化,导致规划不准;
忽视车辆行为对环境的影响:自动驾驶车辆自身的未来动作(如减速、转向)会改变周围场景的演变(如引导后车调整车速),这种双向依赖关系在现有系统中未被有效建模。
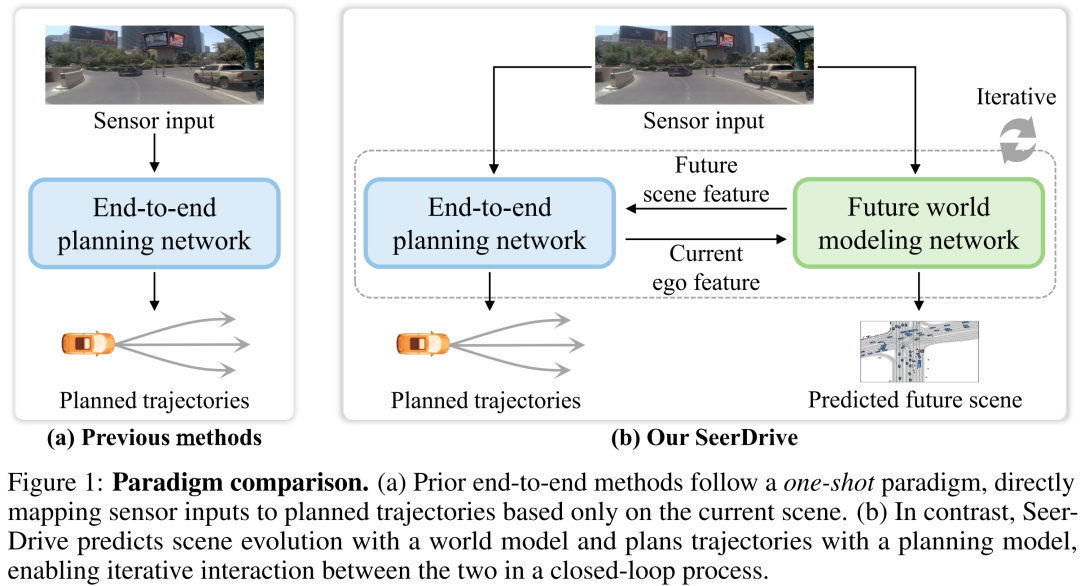
为解决上述问题,复旦和上海创智学院提出SeerDrive,借鉴“世界模型(world models)”的思想,提出轨迹规划与场景演化的双向建模范式:通过预测未来BEV表示捕捉场景动态,同时让规划结果反馈给场景预测的优化,形成闭环迭代(图1),最终实现更具适应性的决策。
论文标题:Future-Aware End-to-End Driving: Bidirectional Modeling of Trajectory Planning and Scene Evolution
论文链接:https://arxiv.org/abs/2510.11092
开源链接:https://github.com/LogosRoboticsGroup/SeerDrive
SeerDrive的设计原理
SeerDrive的整体 pipeline 包含特征编码、未来BEV世界建模、未来感知规划、迭代优化四大模块,核心是通过“预测未来场景→指导规划→反馈优化场景”的闭环,实现双向交互。
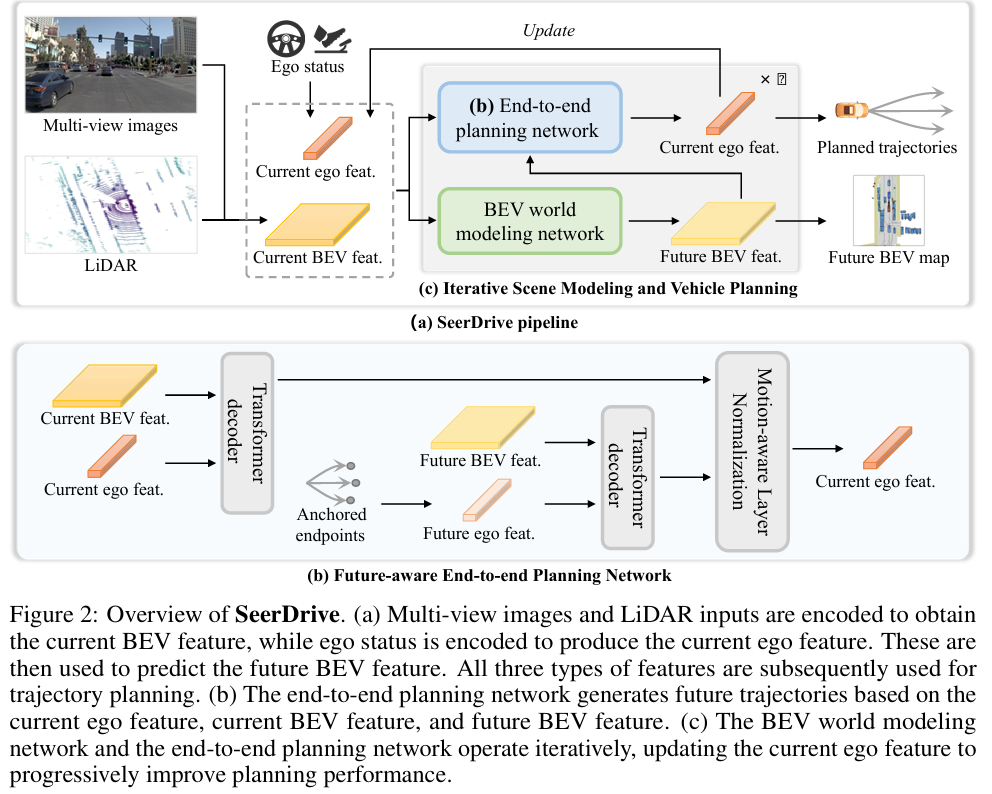
特征编码:从传感器输入到结构化特征
首先将多模态传感器输入(多视图图像 、LiDAR点云 )和车辆自身状态(ego status )编码为结构化特征,为后续建模奠定基础:
当前帧BEV特征:采用TransFuser模型融合多视图图像与LiDAR,生成当前场景的BEV特征图,公式为:
其中 , 为BEV空间维度, 为特征通道数(默认256)。同时,通过轻量级BEV解码器生成当前BEV语义图 ,用于训练监督。
当前Ego特征:将锚定多模态轨迹 (通过K-Means从真值轨迹聚类得到)和ego状态 输入MLP编码器,生成当前ego特征:
其中 , 为轨迹模态数(NAVSIM中设为256,nuScenes中设为6)。
未来BEV世界建模:预测场景动态
基于当前BEV和ego特征,构建世界模型预测未来场景演化,核心是生成未来BEV特征(而非复杂图像),兼顾效率与结构化表示:
首先将当前BEV特征沿空间维度展平,并在模态维度重复(匹配 个轨迹模态),得到 ;
将其与当前ego特征 拼接,形成当前场景特征 ;
采用Transformer编码器作为BEV世界模型,生成未来场景特征 ,从中提取未来BEV特征 ;
最后通过BEV解码器生成未来BEV语义图 ,用于监督场景预测 accuracy。
关键公式为:
核心组件1:Future-Aware Planning
传统规划直接融合当前与未来BEV特征会导致表示纠缠,SeerDrive采用解耦策略(decoupled strategy) ,让当前与未来场景分别指导规划,再通过运动感知层归一化(MLN)融合结果:
当前场景指导规划:当前ego特征 与当前BEV特征 通过Transformer解码器交互,更新后的ego特征输入MLP解码器,生成轨迹 ;
未来场景指导规划:以锚定轨迹的端点初始化未来ego特征 (匹配未来BEV对应的时间步),使其与未来BEV特征 通过Transformer解码器交互,生成轨迹 ;
融合当前与未来信息:采用MLN将 与 融合,得到未来感知的ego表示,最终生成轨迹 。
关键公式为:
该设计确保规划同时利用当前感知与未来场景预判,避免表示混淆(图 2(b)展示了该模块的细节)。
核心组件2:迭代场景建模与车辆规划
为强化轨迹规划与场景演化的双向依赖,SeerDrive引入闭环迭代优化:
首次迭代中,世界模型生成的未来BEV指导规划模块生成初始轨迹;
将规划模块优化后的当前ego特征 反馈给世界模型,更新未来场景特征 和未来BEV特征 ;
基于更新后的未来BEV,规划模块进一步优化轨迹,重复该过程 次(实验验证 时性能与效率最优,table 5)。
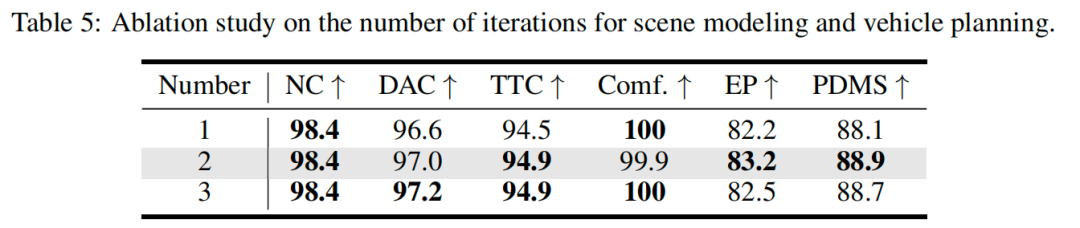
每次迭代都会生成一组未来BEV语义图和轨迹( , ),所有结果均用于训练监督,确保迭代过程的稳定性(图3展示了迭代交互流程)。
端到端训练:损失函数设计
总损失由BEV语义图损失( )和轨迹损失( )组成,平衡场景预测与轨迹规划的优化目标:
语义图损失:包含当前BEV损失和 次迭代的未来BEV损失,公式为:
其中 为平衡因子(NAVSIM中分别设为10、0.1,nuScenes中均设为1)。
轨迹损失:包含 次迭代中 、 、 的损失,公式为:
其中 为平衡因子(NAVSIM中设为1,nuScenes中设为1)。
总损失:
实验结果
实验在NAVSIM和nuScenes两上展开,重点验证SeerDrive的SOTA性能及核心组件的必要性。
数据集与评价指标
NAVSIM:基于nuPlan构建,包含1192个训练/验证场景、136个测试场景,涵盖动态意图变化,采用8相机+LiDAR输入(2Hz);评价指标为PDMS分数,包含无责任碰撞(NC)、可行驶区域合规性(DAC)、碰撞时间(TTC)、舒适性(Comf.)、车辆进度(EP)5个子指标。
nuScenes:包含1000个场景,采用6相机+LiDAR输入(2Hz);评价指标为L2位移误差(越小越好)和碰撞率(越小越好)。
与SOTA方法的对比
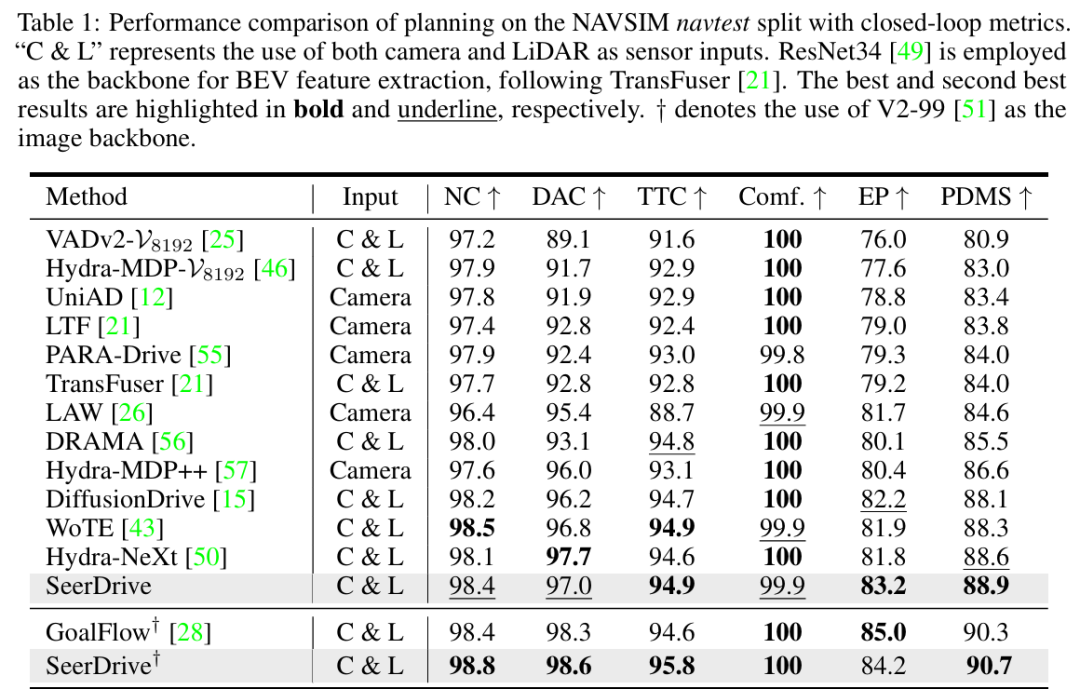
NAVSIM测试集(table 1):
SeerDrive在PDMS分数上达到88.9,超越Hydra-NeXt(88.6)、WoTE(88.3)、DiffusionDrive(88.1)等方法;当采用V2-99骨干网络时,PDMS进一步提升至90.7,超过GoalFlow的90.3,且计算成本更低。
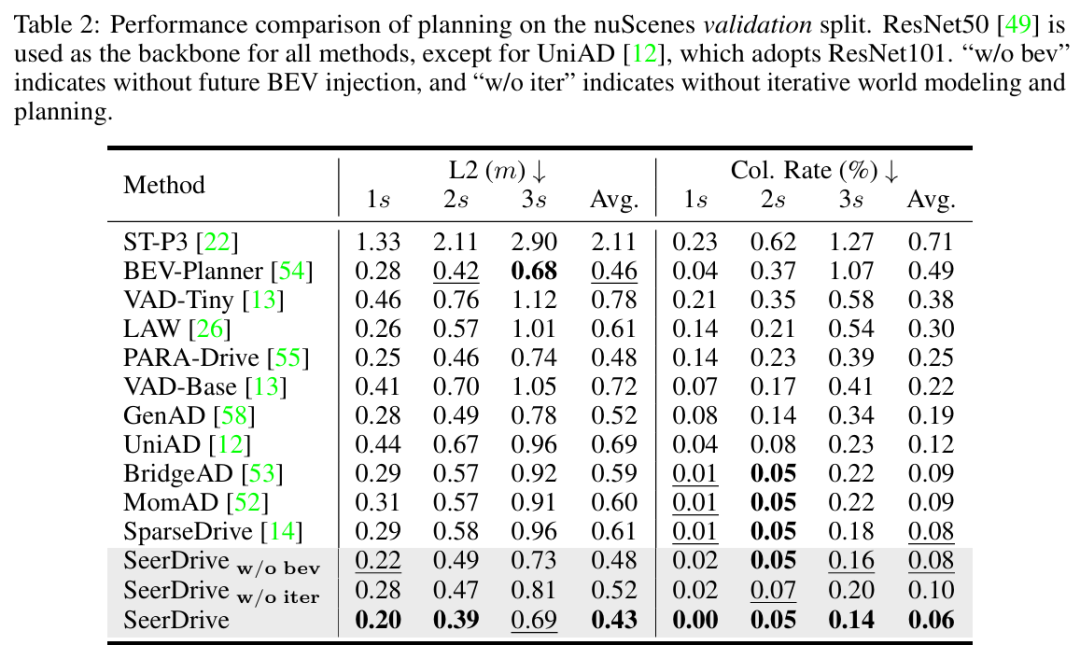
nuScenes验证集(table 2):
SeerDrive的平均L2位移误差为0.43m,平均碰撞率为0.06%,显著优于SparseDrive(L2=0.61m,碰撞率=0.08%)、MomAD(L2=0.60m,碰撞率=0.09%)等方法;即使去掉未来BEV注入(SeerDrive w/o bev)或迭代优化(SeerDrive w/o iter),性能仍优于部分SOTA,证明核心设计的有效性。
消融实验:核心组件的必要性
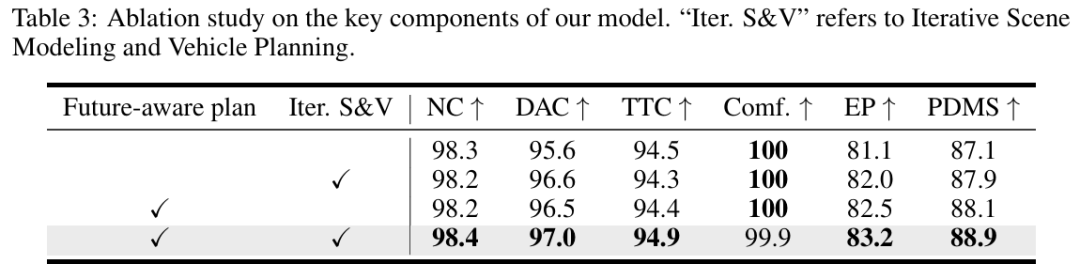
组件有效性(table 3):去掉未来感知规划或迭代优化,PDMS均下降(如两者都去掉时PDMS从88.9降至87.1),说明双向建模和迭代优化是性能提升的关键。
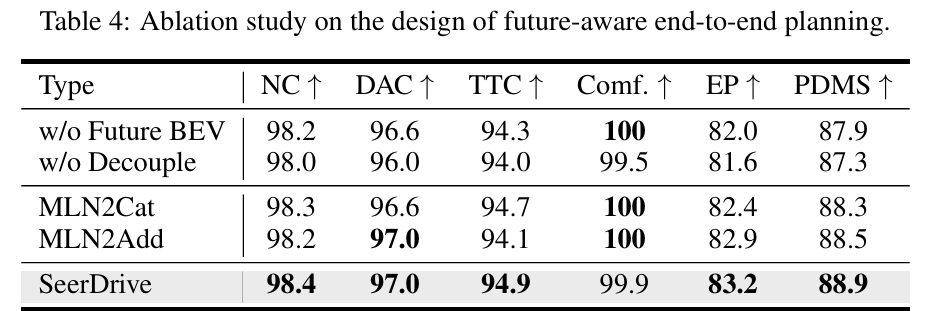
未来感知规划设计(table 4):去掉未来BEV注入(PDMS=87.9)、解耦策略(PDMS=87.3)或MLN(改用拼接/相加,PDMS=88.3/88.5),性能均低于完整设计,验证了解耦策略和MLN的重要性。
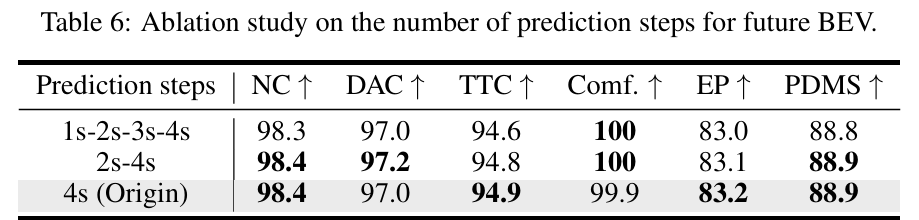
迭代次数与未来BEV预测步(table 5、table 6):迭代2次时性能最优(PDMS=88.9),迭代1次或3次均导致性能下降;仅预测最终规划步的未来BEV(4s)即可满足需求,增加中间步(如1s-2s-3s-4s)无性能提升但增加复杂度。
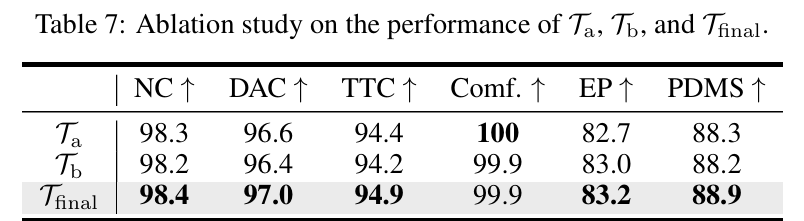
轨迹模态与初始化(table 7、table 8): 的PDMS(88.9)显著高于 (88.3)和 (88.2),证明融合当前与未来信息的价值;用锚定端点初始化未来ego特征的效果最优(PDMS=88.9),优于随机初始化(88.6)或锚定轨迹初始化(88.7)。

定性结果:场景演化与规划的对齐
figure 3展示了右转和左转场景的定性结果:
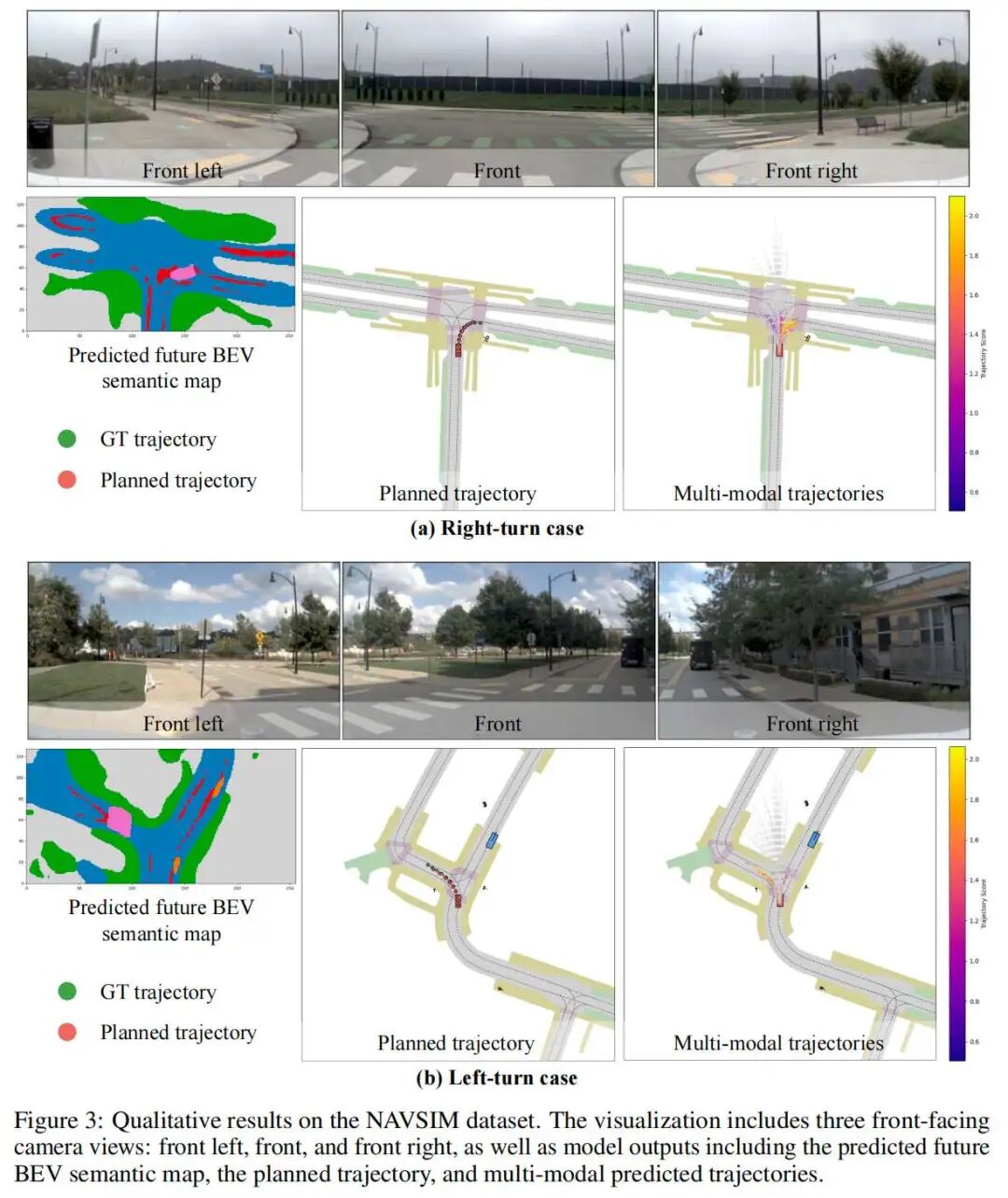
预测的未来BEV语义图能准确反映场景演化(如车辆转弯后的位置变化);
规划轨迹 与真值轨迹(GT trajectory)高度对齐;
多模态轨迹(Multi-modal trajectories)覆盖了多种可能的未来运动(如转弯角度的微小差异),体现对不确定性的鲁棒性。
四、相关工作对比与局限
与现有方法的核心差异
端到端自动驾驶:UniAD、VADv2、DiffusionDrive等方法仅优化规划过程,未建模场景演化与规划的双向依赖;SeerDrive则通过未来BEV和迭代优化,让两者深度交互。
世界模型:DriveDreamer、GAIA-1等侧重生成高保真图像,计算成本高;SeerDrive采用BEV表示,更轻量且适配规划需求。
联合世界建模与规划:WoTE仅用世界模型从候选轨迹中选最优,无特征级交互;SeerDrive则将未来BEV作为规划的特征级输入,并通过迭代反馈优化,互动更深入(table 10)。

局限与未来方向
局限:BEV世界模型未利用基础模型的泛化能力,而现成基础模型(如大语言模型、视觉基础模型)虽泛化性强,但推理速度慢且难与规划模块联合优化。
未来方向:探索“基础模型+规划”的紧密集成范式,在保持效率的同时提升泛化能力,应对更复杂的极端场景(如紧急制动、多车交汇)。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









