



点击下方卡片,关注“自动驾驶之心”公众号
MCAM:面向自车层面驾驶视频理解的多模态因果分析模型
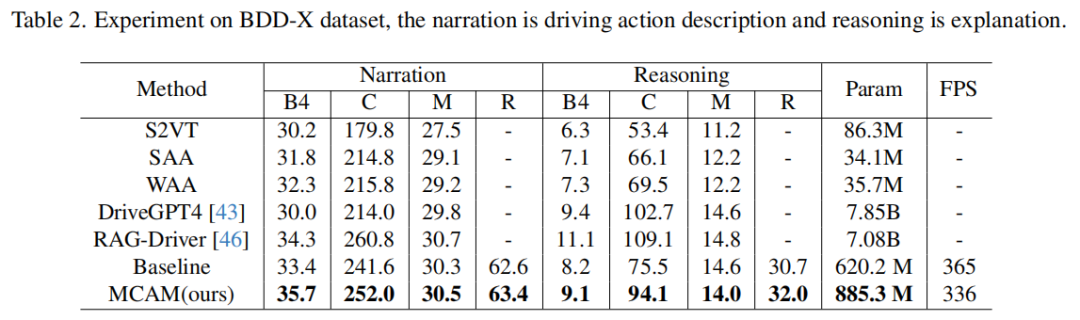
重庆大学&国防科技大ICCV25中稿的工作,本文提出 MCAM 模型,通过 DSDAG 因果图建模自车状态动态演化,在BDD-X数据集上将驾驶行为描述任务BLEU-4提升至 35.7%,推理任务BLEU-4提升至 9.1%,显著优于DriveGPT4等基线模型。
论文标题:MCAM: Multimodal Causal Analysis Model for Ego-Vehicle-Level Driving Video Understanding
论文链接:https://arxiv.org/abs/2507.06072
代码:https://github.com/SixCorePeach/MCAM
主要贡献:
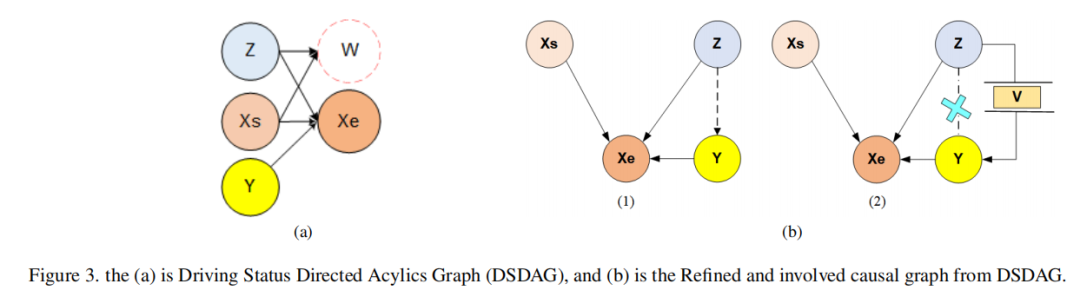
提出驾驶状态有向无环图(DSDAG),用于建模动态驾驶交互和状态转换,为因果分析模块(CAM)提供结构化理论基础。
提出多模态因果分析模型(MCAM),这是首个针对 ego-vehicle 级驾驶视频理解任务引入因果分析结构的框架,通过驾驶状态建模发现真实因果关系,实现鲁棒的 ego-vehicle 级驾驶视频理解。
在 BDD-X 和 CoVLA 数据集上的大量实验表明,MCAM 能有效减轻虚假相关性的干扰,在 ego-vehicle 级驾驶行为理解上表现优异。
算法框架:
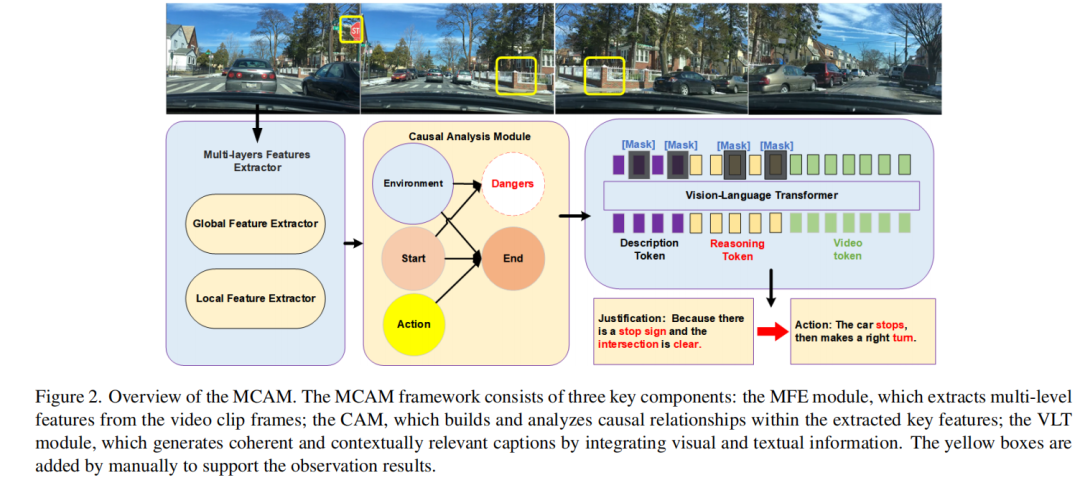
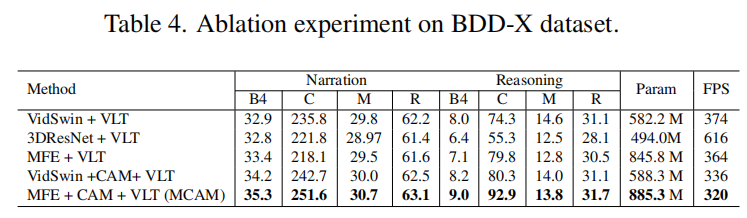
实验结果:
可视化:


本文内容均上传至,打造了『自动驾驶之心知识星球』。近4000人的自动驾驶&具身智能前沿技术和求职问答社区,欢迎加入~
大额新人优惠!欢迎扫码加入~

告别人工标注!TigAug实现自动驾驶交通灯检测自动化测试,错误识别率降低39.8%
复旦大学与同济大学提出 TigAug 数据增强技术,显著提升交通灯检测模型的鲁棒性:
1)突破性技术:通过系统化变换(天气、相机、交通灯属性)生成增强图像,结合蜕变关系自动检测模型错误行为并提升模型性能。
2)关键数据:
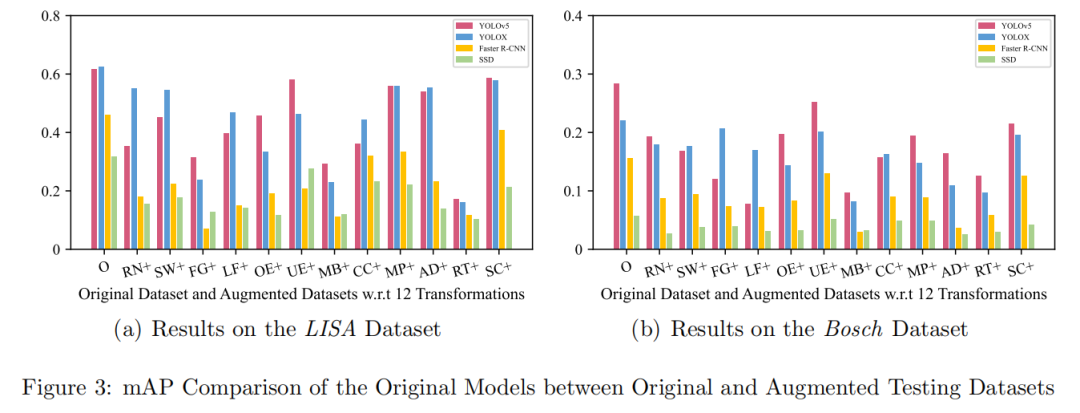
a)错误检测有效性:原始模型在增强测试集上平均 mAP 下降 39.8%(图3、图4)。
b)性能提升:使用增强数据重新训练后,模型在增强测试集上 mAP 平均提升 67.5%(图5、图6)。
c)效率:单张图像合成耗时 0.88秒,模型重训练平均耗时 36小时(图7)。
论文标题:TigAug: Data Augmentation for Testing Traffic Light Detection in Autonomous Driving Systems
链接:https://arxiv.org/abs/2507.05932
主要贡献:
提出了原型工具 TigAug,用于自动增强交通灯图像,以检测自动驾驶系统(ADSs)中交通灯检测模型的错误行为并提升其性能。
构建了两个变形关系家族和三个变换家族(基于对天气环境、相机属性和交通灯属性的系统理解),支持交通灯图像的自动增强。
通过大规模实验验证了 TigAug 的有效性(能检测错误行为且提升模型性能)和效率,并公开了工具源码与实验数据。
算法框架:
实验结果:
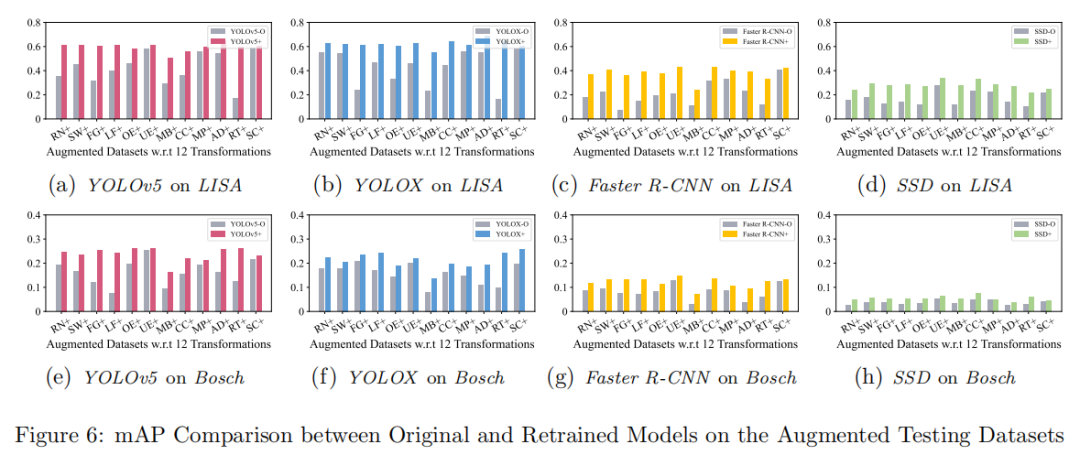
可视化:


LeAD:融合端到端自动驾驶与大语言模型的双速率规划系统
同济大学提出LLM增强的双速率自动驾驶规划系统LeAD,通过融合实时E2E规划与LLM的语义推理能力,显著提升复杂边缘场景处理性能,在CARLA仿真平台以71.96驾驶分(路线完成率93.43%) 超越现有基线模型。
论文标题:LeAD: The LLM Enhanced Planning System Converged with End-to-end Autonomous Driving
论文链接:https://arxiv.org/abs/2507.05754
主要贡献:
提出 LeAD 系统,这是一种创新的自动驾驶架构,利用大语言模型(LLM)进行场景语义理解和类人逻辑推理,实现基于场景理解的规划。
设计双向自然语言编解码器,实现感知 / 决策数据与语言表示的转换,增强 LLM 对信息的可靠理解和逻辑决策能力。
提出双速率系统架构,协同整合具备实时能力的端到端(E2E)框架与具有场景理解和推理能力的 LLM 增强模块,保障系统高效运行,并在 CARLA Leaderboard 自动驾驶闭环测试中成功完成任务。
算法框架:
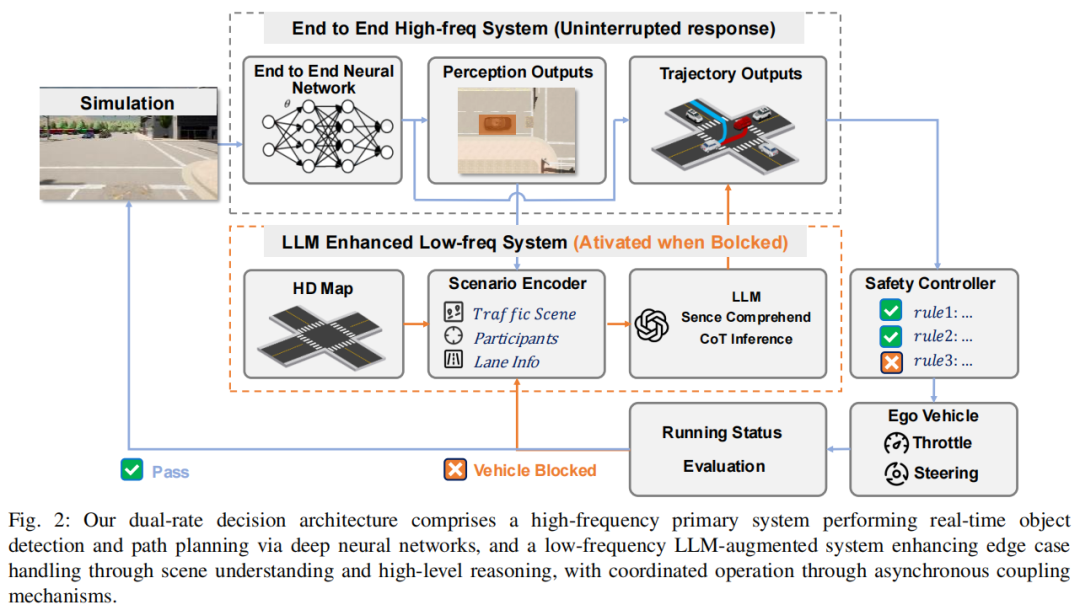
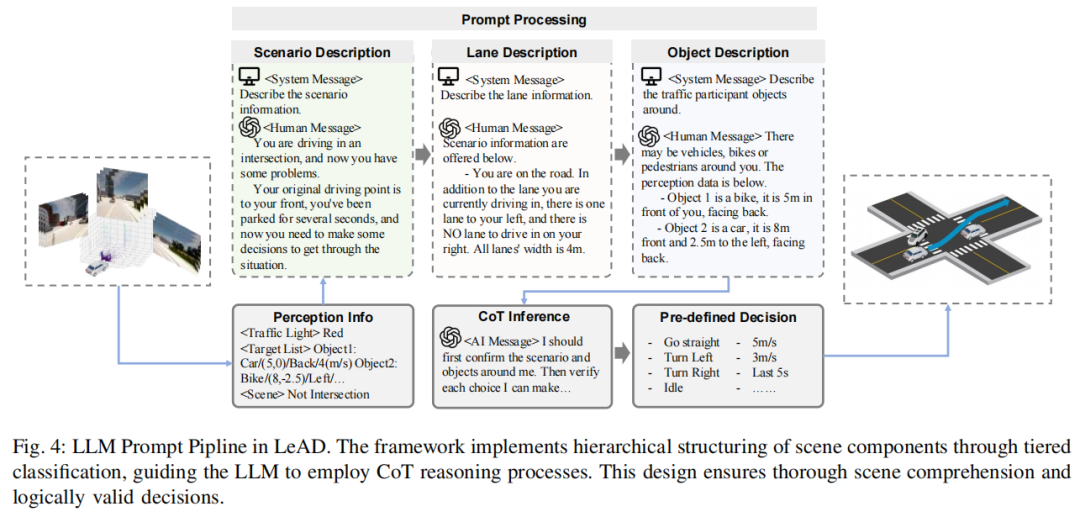
实验结果:


可视化:

DRO-EDL-MPC:基于证据深度学习的分布鲁棒模型预测控制框架,实现自动驾驶动态安全约束
韩国科学技术院的研究人员突破了安全自动驾驶中不确定性感知的技术瓶颈,提出了DRO-EDL-MPC算法,在计算效率上实现了5倍提升(相比W-DRO-CVaR方法),并在CARLA模拟器中显著降低了碰撞率(不确定场景下碰撞率接近于零)。
论文标题:DRO-EDL-MPC: Evidential Deep Learning-Based Distributionally Robust Model Predictive Control for Safe Autonomous Driving
论文链接:https://arxiv.org/abs/2507.05710
项目主页:https://dro-edl-mpc.github.io
主要贡献:
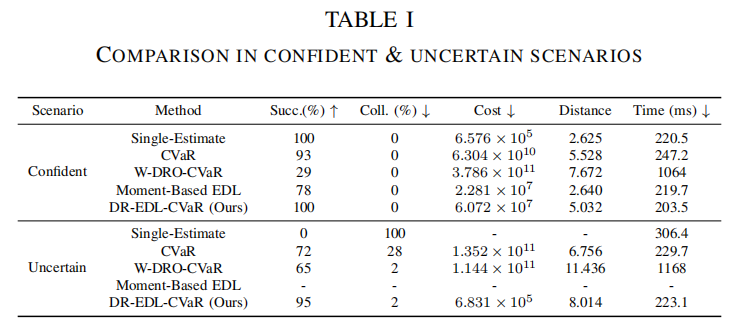
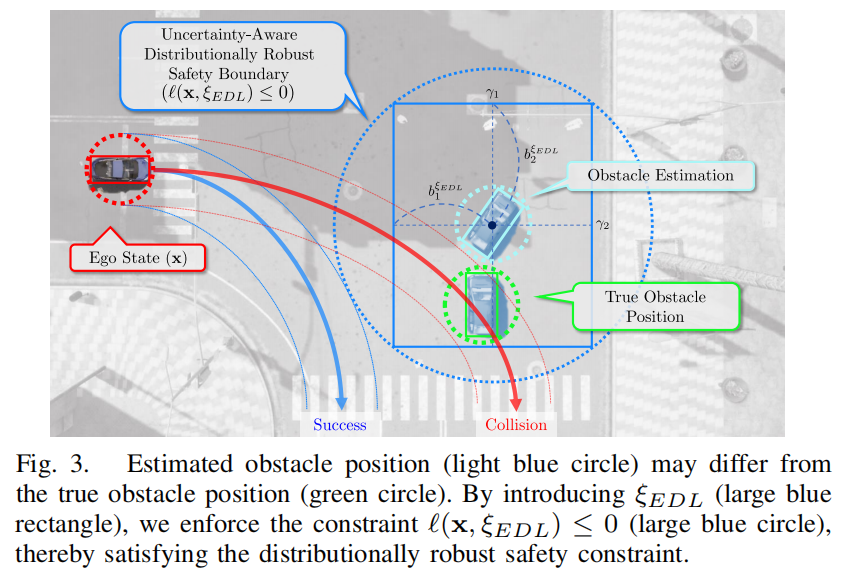
提出 DR-EDL-CVaR 约束:一种基于证据分布累积概率构建不确定性感知模糊集的分布鲁棒安全约束,可同时处理数据不确定性(通过 CVaR 风险度量)和模型不确定性(通过模糊集中的最坏情况优化)。
提出 DRO-EDL-MPC 算法:将 DR-EDL-CVaR 整合到模型预测控制(MPC)框架中,实现计算可行的自动驾驶运动规划,能根据感知置信度动态调整保守性。
在 CARLA 模拟器中验证了算法有效性:高感知置信时保持效率,低置信时通过保守约束确保安全,且计算效率优于 W-DRO-CVaR 等方法。
算法框架:
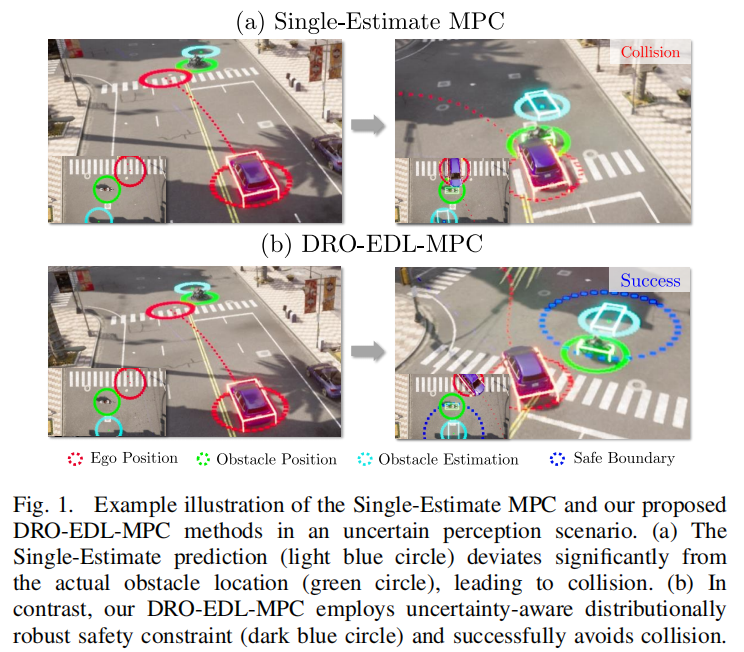

实验结果:
可视化:

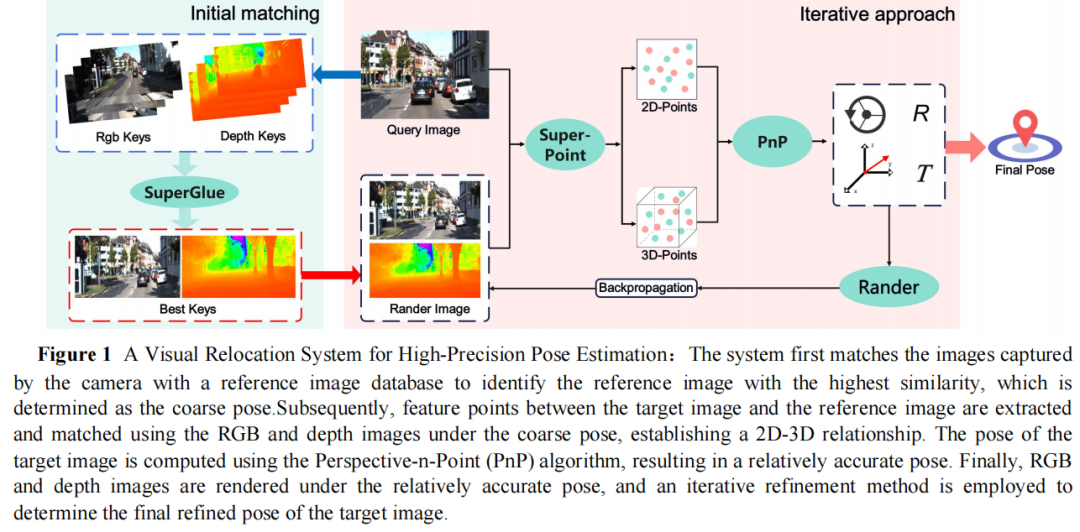
3DGS-LSR:基于3D高斯溅射的自动驾驶大规模重定位方法
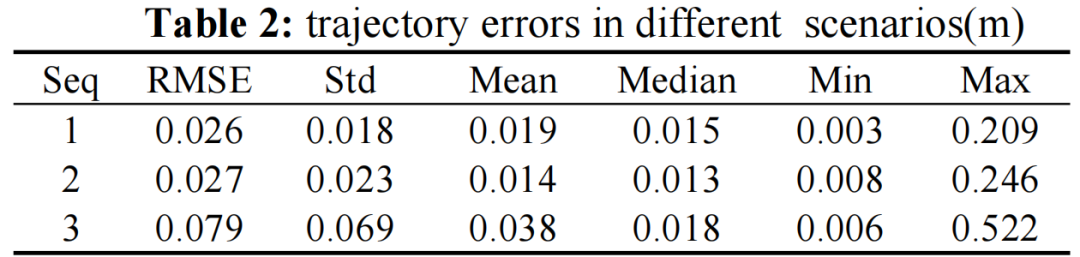
武汉大学提出基于 3D 高斯溅射的大规模重定位框架 3DGS-LSR,仅用单目 RGB 图像在 KITTI 数据集实现厘米级定位(城镇道路 0.026m / 林荫道 0.029m),显著超越现有方法(如 DSAC++、3DGS-Reloc)。
论文标题:3DGS_LSR:Large_Scale Relocation for Autonomous Driving Based on 3D Gaussian Splatting
论文链接:https://arxiv.org/abs/2507.05661
主要贡献:
提出 3DGS-LSR 框架,基于 3D 高斯溅射(3DGS)实现大规模重定位,仅通过单目 RGB 图像即可达成厘米级定位,解决了复杂城市环境中 GNSS 定位不可靠及传统地图方法存储与计算效率不足的问题。
结合高效匹配算法与 3DGS 地图的快速渲染能力,设计迭代优化策略,实现实时、高精度的迭代重定位。
摆脱对不可靠 GNSS 的依赖,仅利用相机传感器即可实现厘米级重定位,适用于资源受限的机器人平台。
算法框架:
实验结果:
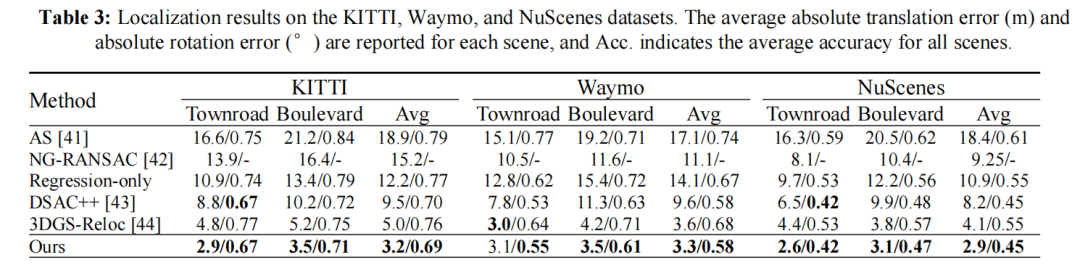
可视化:


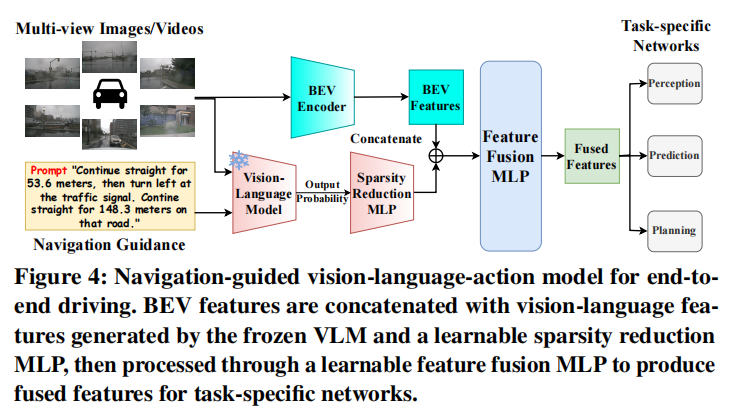
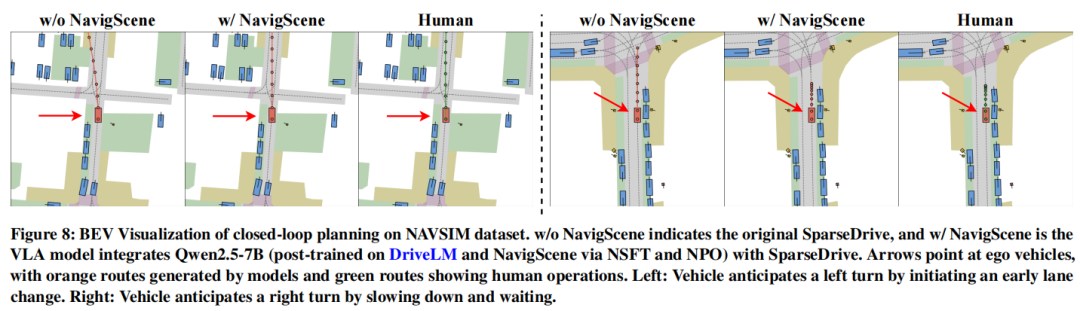
NavigScene:融合局部感知与全局导航的超视距自动驾驶突破
中佛罗里达大学 & 小鹏汽车 团队ACMMM25中稿的工作,本文提出导航引导框架NavigScene,通过融合全局导航信息与局部感知,将自动驾驶系统的长距离规划能力提升至人类水平:在nuScenes数据集上使平均L2轨迹误差降低至0.76m(比基线提升24%),碰撞率从32.48‱降至20.71‱;跨城市泛化测试中,新加坡→波士顿场景平均L2误差降低15%。
论文标题:NavigScene: Bridging Local Perception and Global Navigation for Beyond-Visual-Range Autonomous Driving
论文链接:https://arxiv.org/abs/2507.05227
主要贡献:
提出 NavigScene,这是一个新颖的辅助数据集,将局部多视图传感器输入与全局自然语言导航指导配对,填补了自动驾驶中局部感知与全局导航上下文之间的关键空白。
基于 NavigScene 实现了三种互补范式:导航引导推理、导航引导偏好优化、导航引导视觉 - 语言 - 动作模型,增强了自动驾驶系统在超出视觉范围限制下的推理和泛化能力。
在问答任务和端到端驾驶任务(包括感知、预测、规划)上进行了综合实验,证明将全局导航知识融入自动驾驶系统可显著提升性能。
算法框架:
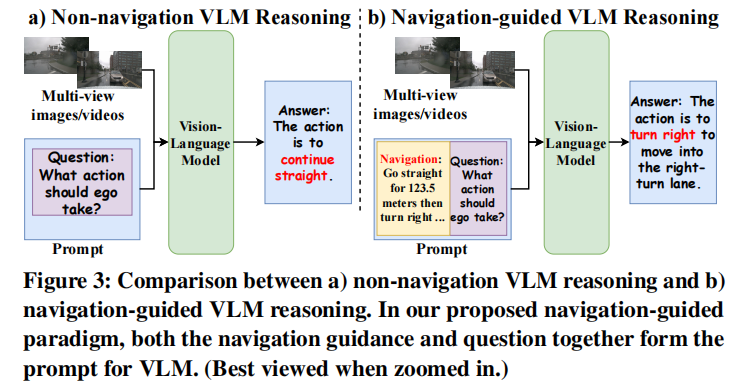
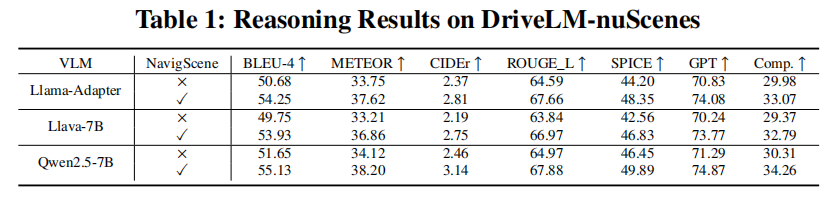
实验结果:
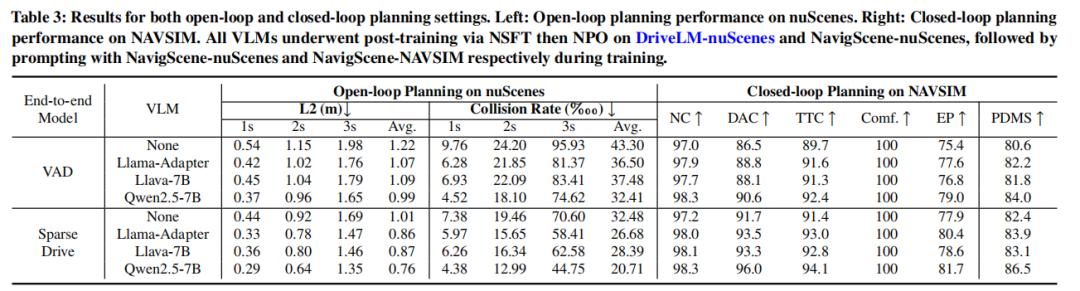
可视化:
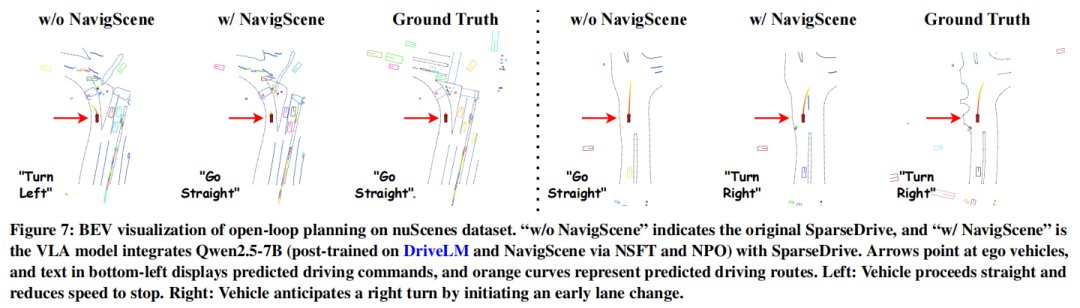
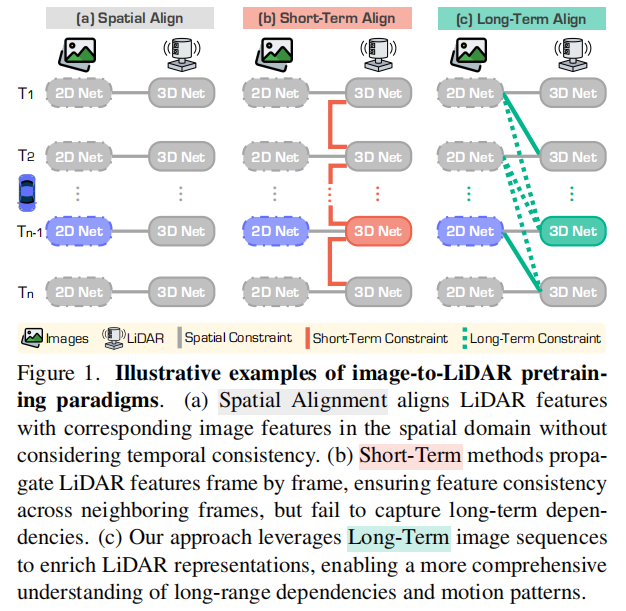
突破单帧局限:跨视角与长时序蒸馏增强LiDAR表征学习
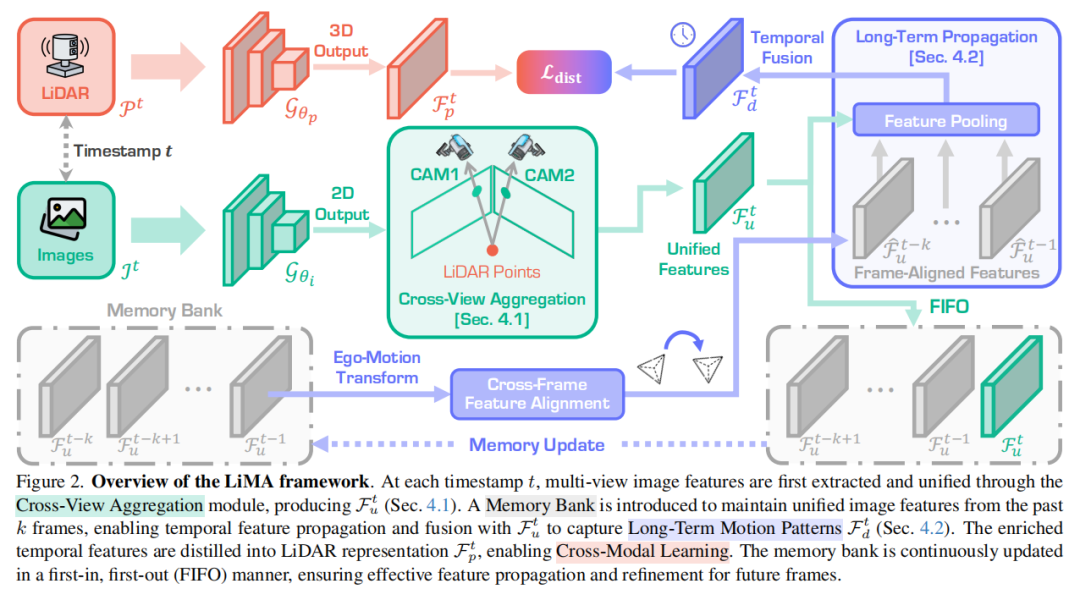
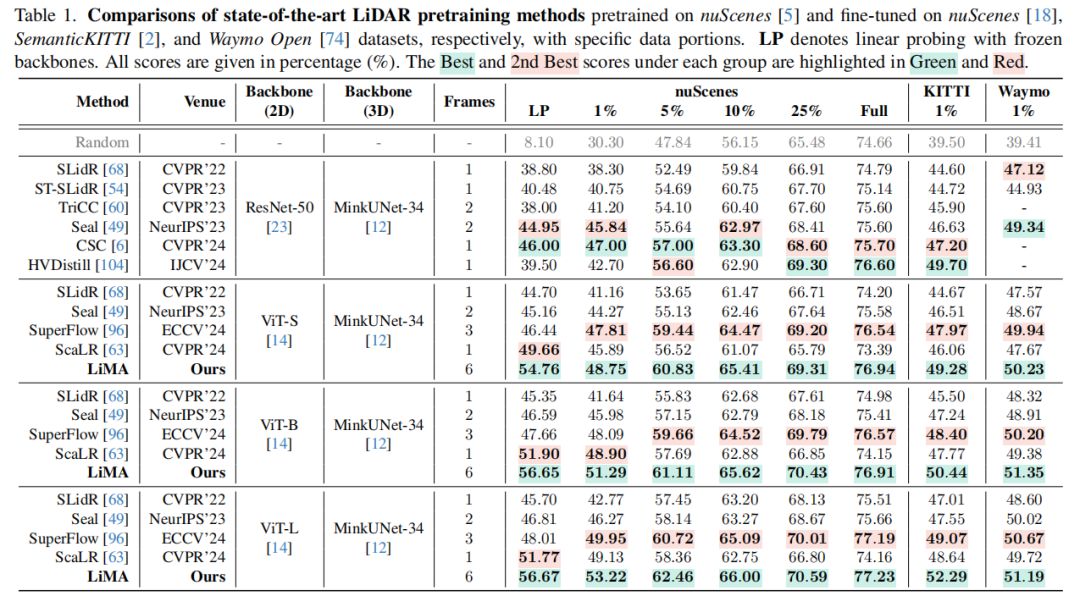
南京航空航天大学、新加坡国立大学、浙江大学、南京邮电大学等单位ICCV25中稿的工作,本文提出了一种名为 LiMA 的长时序图像-LiDAR 记忆聚合框架,通过跨视角对齐、长时序特征传播和跨序列记忆对齐三大核心技术,显著提升了 LiDAR 表示学习的时空建模能力,在 LiDAR 语义分割(nuScenes 数据集线性探测 mIoU 达 56.67%)和 3D 目标检测(nuScenes-C 鲁棒性评测 mCE 降至 91.43%)任务中实现突破性性能提升。
论文标题:Beyond One Shot, Beyond One Perspective: Cross-View and Long-Horizon Distillation for Better LiDAR Representations
论文链接:https://arxiv.org/abs/2507.05260
代码:http://github.com/Xiangxu-0103/LiMA
主要贡献:
提出了 LiMA(long-term image-to-LiDAR Memory Aggregation)框架,通过显式建模驾驶序列中的时间结构,捕捉长程时间依赖关系以增强 LiDAR 表征学习。
设计了三个关键组件:跨视图聚合模块(Cross-View Aggregation),用于统一多视图特征并构建高质量记忆库;长期特征传播机制(Long-Term Feature Propagation),实现跨帧特征对齐与融合以捕捉长程依赖;跨序列记忆对齐策略(Cross-Sequence Memory Alignment),提升在多样驾驶场景中的泛化能力。
大量实验验证了 LiMA 的有效性,在主流 LiDAR 感知基准上,显著提升了 LiDAR 语义分割和 3D 目标检测性能,且预训练效率高,下游任务无额外计算开销。
算法框架:
实验结果:
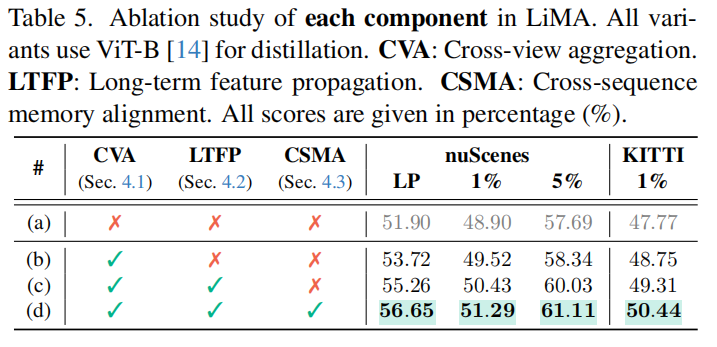
可视化:

动态掩码与相对空间缩减策略,实现自动驾驶强化学习训练效率倍增
美国密歇根大学迪尔伯恩分校提出动态掩码与相对动作空间缩减策略,显著提升自动驾驶强化学习的训练效率与控制精度,在CARLA仿真中实现100万步快速收敛(比基线快2倍)且成功率持平(80% vs 基线100%),车道偏离降低至0.07米。
论文标题:Action Space Reduction Strategies for Reinforcement Learning in Autonomous Driving
论文链接:https://arxiv.org/abs/2507.05251
主要贡献:
提出两种新型结构化动作空间修改策略 —— 动态掩码(dynamic masking)和相对动作空间缩减(relative action space reduction),二者基于实时上下文和状态转换进行动作掩码,在保留动作一致性的同时剔除无效或次优选择;
构建了多模态近端策略优化(Proximal Policy Optimization, PPO)框架,融合语义图像序列和标量车辆状态,实现对自动驾驶场景的有效感知与决策;
通过在 CARLA 模拟器多场景下的实验,系统证明动作空间缩减可显著提升训练稳定性和策略性能,其中动态掩码和相对策略在学习速度、控制精度与泛化能力间取得更优平衡,凸显了上下文感知动作空间设计对自动驾驶强化学习可扩展性与可靠性的重要性。
算法框架:

实验结果:
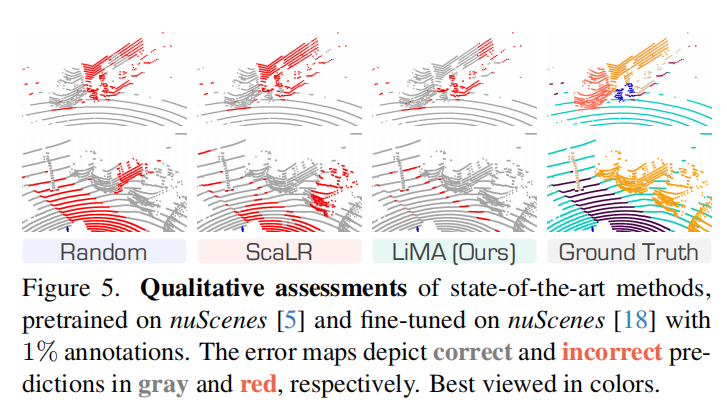
可视化:
突破特征局限:数据集设计如何影响多智能体轨迹预测性能
数据集制作流程(基于Section III)
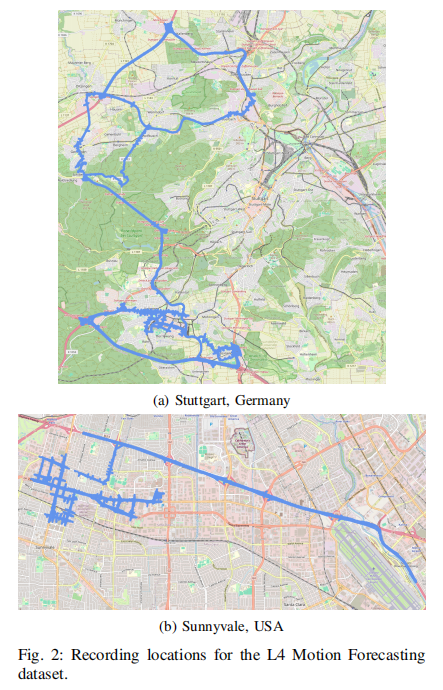
1)数据来源:德国(斯图加特)和美国(森尼韦尔)的测试车辆(图1),配备多传感器(摄像头、激光雷达、雷达)。
2)采集时长:2022年4月–2024年4月,400+小时原始数据(10Hz采样)。
3)关键处理步骤:
a)质量控制:剔除损坏数据、异常采样序列、ID错误场景。
b)地理/环境平衡:按地区(德/美)、环境(城市/乡村)分割训练(80%)、验证(10%)、测试(10%)集(图5)。
c)场景分割:提取11秒连续场景(同Argoverse 2标准),保留完整焦点轨迹(focal track)。
d)HD地图提取:以自车轨迹为中心,提取100米半径内的车道、人行横道、限速标志等(图6)。
e)对象分类:原始25类对象→压缩为5类(同AV2),保留车辆、公交车等关键动态主体(图4)。
论文标题:Beyond Features: How Dataset Design Influences Multi-Agent Trajectory Prediction Performance
论文链接:https://arxiv.org/abs/2507.05098
主要贡献:
构建了 L4 Motion Forecasting 数据集,该数据集基于德国和美国的实地采集数据,在地理位置多样性(跨两国)和特征细节(含额外的车道、停止线及智能体特征)上有别于现有数据集,且与 Argoverse 2 结构兼容,便于模型复用与对比。
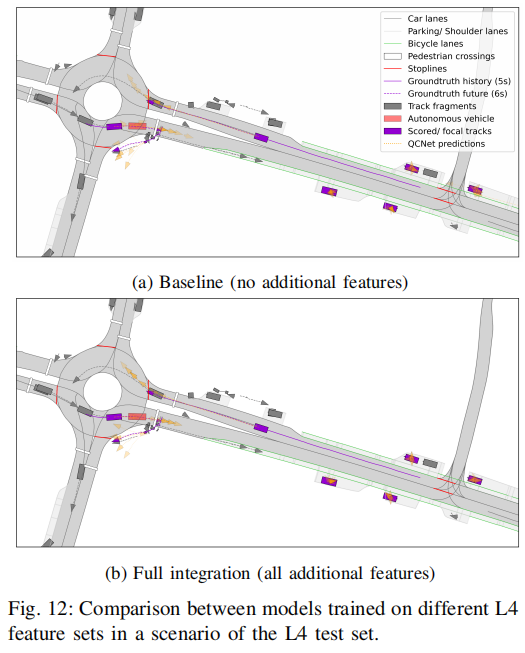
系统评估了额外特征对轨迹预测性能的影响,发现基于 QCNet 的实验中,补充的地图和智能体特征未带来显著性能提升,验证了现有公共数据集特征集的充足性。
探究了跨数据集知识迁移效应,发现训练于单一数据集的模型在另一数据集上性能下降(如 AV2 训练模型在 L4 上表现较差),而 AV2 预训练结合 L4 微调的模型泛化能力更优,体现了数据集多样性对学习要求的影响。
分析了地理区域间的知识迁移,表明多国家数据集(如包含德美数据的 L4)能提升模型在特定区域的性能,单一国家数据训练的模型可一定程度泛化至另一国家,但多样性数据集效果更优。

最后欢迎大家加入知识星球,硬核资料在星球置顶:加入后可以获取自动驾驶视频课程、硬件及代码学习资料。业内最全的全栈学习路线图,独家业内招聘信息分享~

我们目标是未来3年内打造一个万人聚集的智能驾驶&具身智能社区,这里也非常欢迎优秀的同学加入我们(目前已经有华为天才少年、自驾领域研究前沿的多为大佬加入)。我们和多家业内公司搭建了学术 + 产品+ 招聘完整的桥梁和链路,同时内部在教研板块也基本形成了闭环(课程 + 硬件+问答)。社区里面既能看到最新的行业技术动态、技术分享,也有非常多的技术讨论、入门问答,以及必不可少的行业动态及求职分享。具身智能这么火,要不要考虑转行?自动驾驶技术的未来发展趋势如何?大模型如何预自动驾驶&具身智能结合?这些都是我们持续关注的
加入后如果不满意,三天内(72h)可全额退款!


















 1758
1758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









