



作者 | Jiahao Wang 来源 | 我爱计算机视觉
原文链接:Waymo与谷歌DeepMind联手提出Drive&Gen
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
最近,自动驾驶领域迎来了两位“新玩家”:端到端(End-to-End, E2E)驾驶模型和视频生成模型。E2E模型试图用一个“大模型”直接从传感器输入预测驾驶操作,大大简化了传统复杂的模块化系统;而视频生成模型则为我们描绘了一个美好的前景——在虚拟世界里无限“免费”地测试自动驾驶。
但问题也随之而来:AI生成的视频真的足够“真实”,能骗过自动驾驶系统,并用来做严肃的评估吗?我们又该如何深入了解E2E驾驶模型的“脾气”,修复它的短板,让它在没见过的新场景(比如突然的暴雨天)里也能从容应对?
为了回答这些问题,来自约翰霍普金斯大学、Waymo和谷歌DeepMind的研究者们联手,在即将于IROS 2025会议上发表的论文中,提出了一个名为 Drive&Gen 的新框架。这个名字很直白,就是将 驾驶(Drive) 和 生成(Gen) 结合起来,旨在连接E2E驾驶模型和生成式世界模型,共同评估和提升彼此。

论文: Drive&Gen: Co-Evaluating End-to-End Driving and Video Generation Models
作者: Jiahao Wang, Zhenpei Yang, Yijing Bai, Yingwei Li, Yuliang Zou, Bo Sun, Abhijit Kundu, Jose Lezama, Luna Yue Huang, Zehao Zhu, Jyh-Jing Hwang, Dragomir Anguelov, Mingxing Tan, Chiyu Max Jiang
机构: 约翰霍普金斯大学、Waymo、谷歌DeepMind
论文地址: https://arxiv.org/abs/2510.06209
背景:当E2E驾驶遇上生成式AI
传统的自动驾驶系统像一个部门林立的大公司,感知、预测、规划等模块各司其职,虽然稳定,但流程繁琐,一个环节出错就可能影响全局。而E2E模型就像一个全能的创业团队,直接从摄像头画面等原始输入,一步到位输出驾驶决策,简洁高效,潜力巨大。
与此同时,视频生成模型的进步让我们看到了构建“数字孪生”世界的希望。如果能随心所欲地生成各种天气、光照、交通状况的驾驶视频,无疑将大大降低路测成本和风险,加速自动驾驶的迭代。
然而,理想很丰满,现实却很骨感。一方面,我们很难判断生成的视频在“驾驶模型”眼中是否真实。人眼看着没问题,可能在模型看来却漏洞百出。另一方面,E2E模型像个“黑箱”,我们虽然知道它很强,但不知道它到底学到了什么,有什么偏见,以及在面对训练数据里很少见的场景(即“分布外”场景)时,它能否做出正确决策。
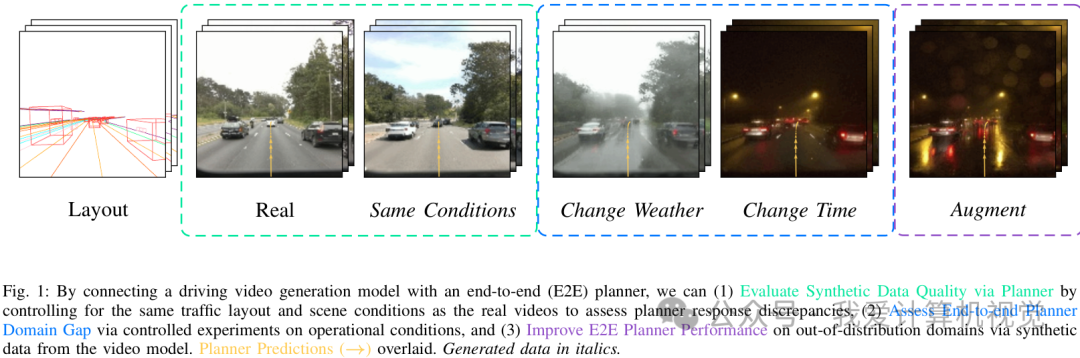
Drive&Gen框架正是为了解决这一矛盾而生。它巧妙地将两者结合:用E2E规划器作为“考官”,去评估生成视频的真实性;反过来,再利用生成模型的可控性,创造出各种“极限挑战”场景,去诊断和提升E2E规划器的能力。
Drive&Gen:如何让虚拟照进现实?
Drive&Gen的核心思想是“协同评估”。它包含一个可控的视频生成模型和一个E2E驾驶规划器。
可控的视频生成
研究者们扩展了一个名为W.A.L.T的视频扩散模型,使其能够接受多种条件的控制,生成高度定制化的驾驶视频。
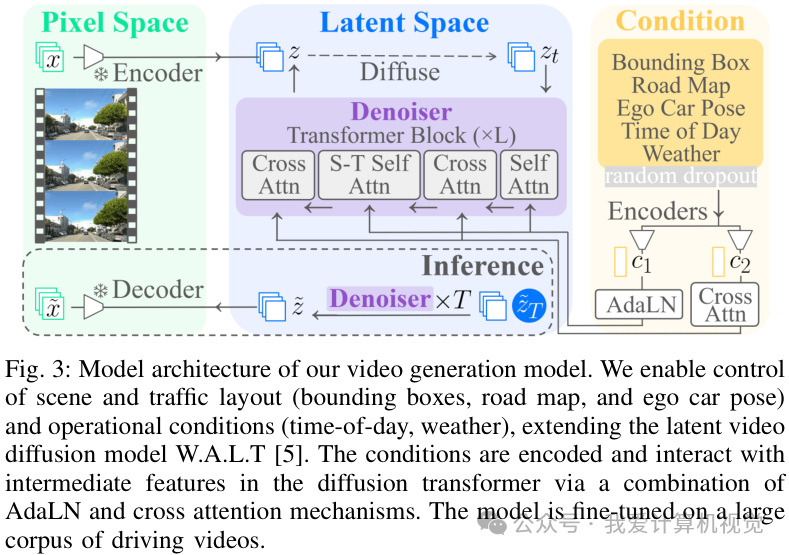
这个模型的输入控制信号非常丰富,包括:
场景布局: 道路地图、车辆的位置和大小(即边界框)、自车姿态。
运行条件: 一天中的具体时间(通过更精确的太阳角度来控制光照)、天气(如下雨或晴天)。
通过这些控制,模型不仅能复现和真实视频几乎一样的场景,还能“凭空”创造出真实世界中不存在的场景,比如将一个晴朗的白天场景无缝切换到大雨滂沱的午夜。
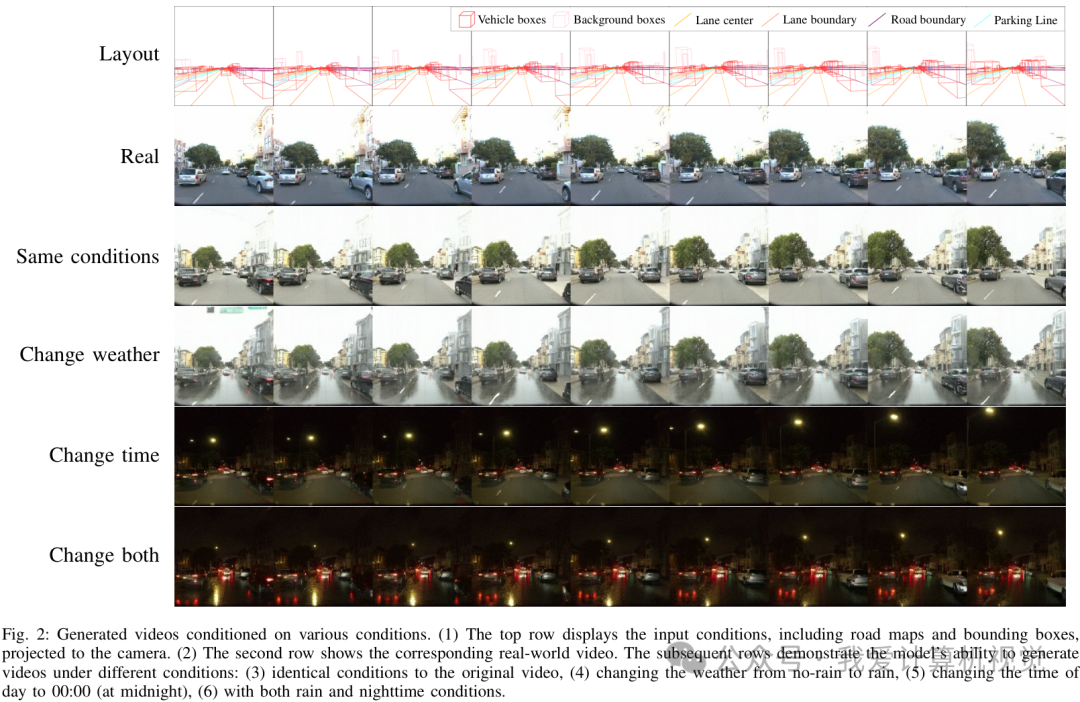
用驾驶模型评估真实性:行为置换检验
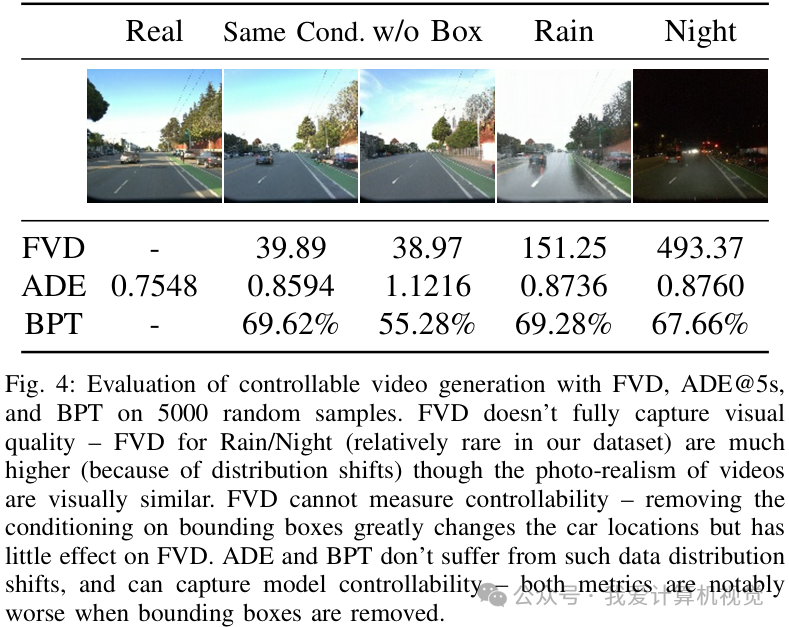
如何量化生成视频的“真实性”?传统的视频质量指标如FVD(Fréchet Video Distance)并不完全适用,因为它更关注像素层面的分布差异,而无法衡量视频是否符合驾驶逻辑。
为此,论文提出了一个全新的评估指标——行为置换检验(Behavioral Permutation Test, BPT)。这个方法非常巧妙,它的核心思想是:如果一个生成的视频足够真实,那么E2E驾驶模型在看到这个生成视频和它对应的真实视频后,应该做出基本相同的驾驶决策。
具体来说,BPT会比较规划器在真实视频和生成视频上预测出的轨迹集合。如果两个轨迹集合的差异很小,小到像是在一个集合内部随机抽样产生的波动,那么BPT就判定生成视频“骗”过了规划器,是足够真实的。

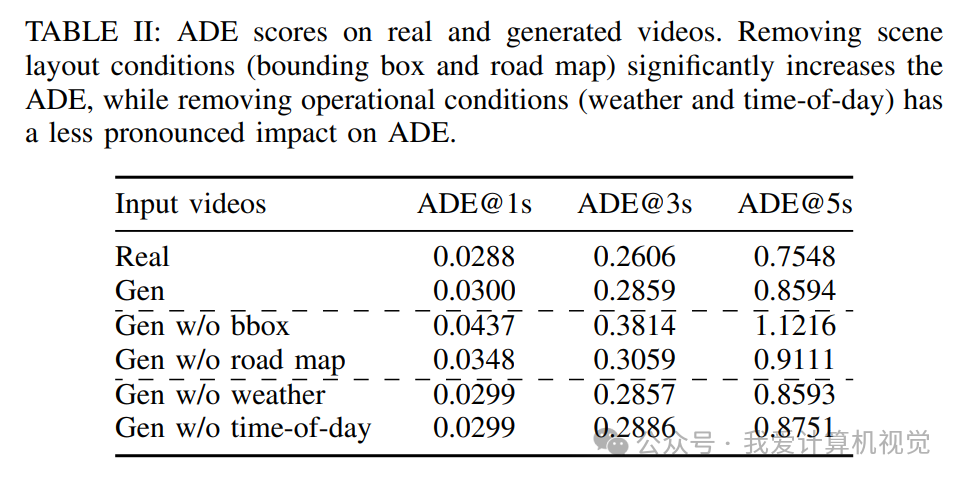
实验证明,BPT比FVD和ADE(平均位移误差)等传统指标更能捕捉到影响驾驶决策的关键差异。例如,当移除场景中的车辆(边界框)信息时,生成的视频内容会大变,此时BPT和ADE指标都会显著恶化,而FVD指标却变化不大,说明FVD没能抓住重点。
实验:合成数据真的能提升性能吗?
有了可靠的评估方法和可控的生成模型,研究者们进行了一系列实验,证明了Drive&Gen框架的价值。
评估生成视频质量
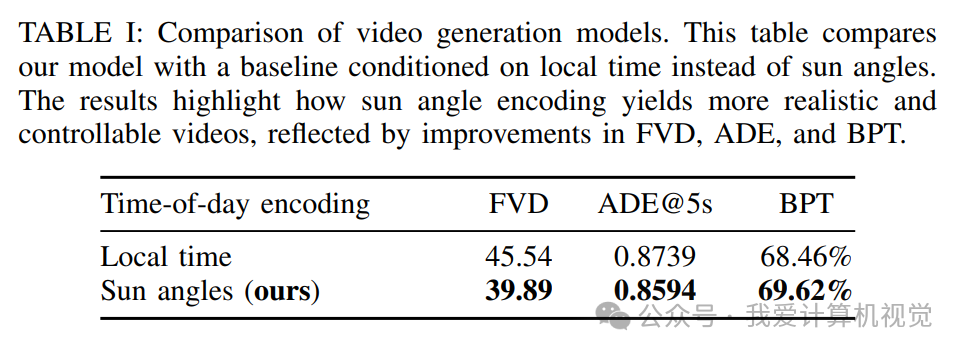
他们验证了生成视频的质量。在与真实视频相同的条件下,模型生成的视频能够让规划器产生非常相似的轨迹预测。BPT的“失败拒绝率”达到了 69.62%(理论上限为95%),这说明在大多数情况下,规划器无法区分真实视频和生成视频。
诊断并提升E2E规划器
更重要的价值在于,Drive&Gen可以用来诊断和提升E2E规划器的泛化能力。研究者们利用生成模型,创造了大量真实数据中稀缺的“分布外”场景,如雨天和夜晚。
他们将这些合成数据与少量真实数据混合,用来微调E2E规划器。结果令人振奋:
整体性能提升: 加入合成数据后,规划器在真实世界验证集上的5秒平均位移误差(ADE@5s)从0.7548降低到了 0.7333。

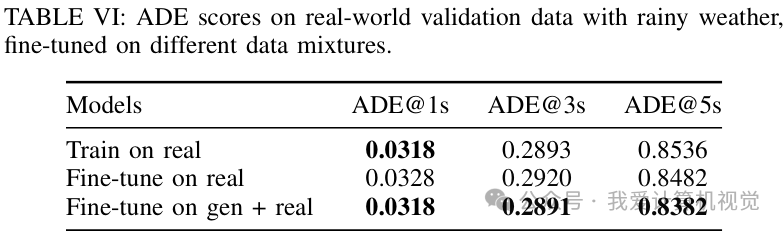
雨天场景: 在雨天这个典型的分布外场景中,性能提升尤为明显,ADE@5s从0.8536降低到 0.8382。
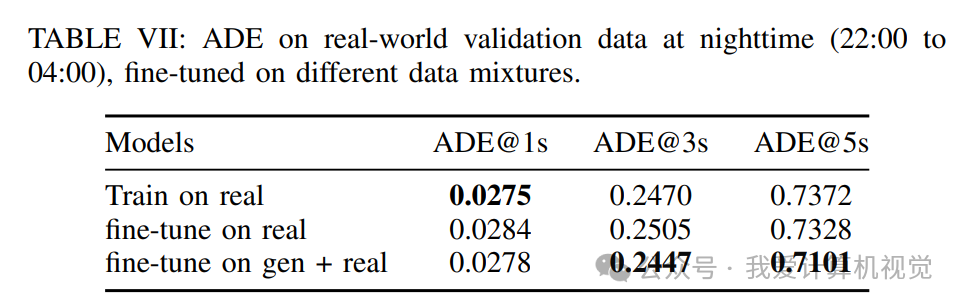
夜间场景: 在夜间场景下,性能同样得到改善,ADE@5s从0.7372降低到 0.7101。
定性结果也同样说明了问题。如下图所示,原始模型在绿灯前会犹豫不决地停车,或者在绕过停靠车辆时动作迟缓;而经过合成数据微调后,模型能做出更果断、更安全的驾驶决策。

这些实验有力地证明,高质量、可控的合成数据是一种极具成本效益的方案,能够有效弥补真实世界数据的不足,帮助自动驾驶模型拓展其运行设计域(Operational Design Domains, ODD)。
这项工作最核心的贡献在于,它不仅仅是展示了一个更酷的视频生成模型,而是为“生成式AI如何赋能自动驾驶研发”这一核心问题,提供了一套系统性的评估和优化方法论。它让我们离那个“在元宇宙里训练和测试自动驾驶”的未来又近了一步。
大家对这种用生成数据来“考验”和“训练”自动驾驶的方法怎么看?欢迎在评论区留下你的看法!
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









