



端到端多模态规划已成为自动驾驶领域的变革性范式,能有效应对行为多模态问题及长尾场景下的泛化挑战。
本文提出端到端框架AnchDrive,该框架可有效引导扩散策略(diffusion policy),以降低传统生成模型的高计算成本。
与从纯噪声开始去噪不同,AnchDrive利用丰富的混合轨迹锚点(hybrid trajectory anchors)为规划器初始化。这些锚点来源于两个互补的数据源:一是包含通用驾驶先验知识的静态词汇表,二是一组动态的、具备情境感知能力的轨迹。其中,动态轨迹由Transformer实时解码生成,该Transformer可处理密集型与稀疏型感知特征。随后,扩散模型通过学习预测轨迹偏移分布来优化这些锚点,从而实现精细化调整。这种基于锚点的引导式设计,能够高效生成多样化、高质量的轨迹。在NAVSIM基准测试中的实验表明,AnchDrive达到了新的性能上限(state-of-the-art),并展现出强大的泛化能力。
论文标题:AnchDrive: Bootstrapping Diffusion Policies with Hybrid Trajectory Anchors for End-to-End Driving
论文链接:https://arxiv.org/abs/2509.20253
更多关于端到端自动驾驶、VLA、世界模型的前沿技术,欢迎加入『自动驾驶之心知识星球』!

一、引言
近年来,端到端自动驾驶算法受到广泛关注,其相较于传统基于规则的运动规划方法,具有更优的可扩展性与适应性。这类方法通过直接从摄像头图像、激光雷达(LiDAR)点云等原始传感器数据中学习控制信号,绕过了模块化设计流程的复杂性,减少了感知误差的累积,并提升了系统整体的一致性与鲁棒性。
早期的端到端规划器(包括UniAD、VAD和Transfuser)依赖自车查询(ego queries)来回归单模态轨迹;而近年来的方法(如SparseDrive)则探索将稀疏感知模块与并行运动规划器相结合。然而,在交叉路口、高速变道等复杂交通场景中,车辆的潜在行为可能具有高度模糊性与多样性。若忽略驾驶行为固有的不确定性,以及环境感知所要求的多模态决策需求,仅依赖单一预测轨迹往往会导致预测结果过度自信,甚至完全失效。
因此,近期研究开始整合多模态建模策略,生成多个符合当前场景约束的轨迹提案,以提升决策覆盖率。VADv2和HydraMDP等方法通过采用预定义的离散轨迹集实现这一目标。尽管这种方式在一定程度上提高了覆盖率,但对固定轨迹集的依赖会将本质上连续的控制过程离散化,进而限制模型的表达性与灵活性。
扩散模型(diffusion models)已成为一种极具潜力的替代方案,其具备的生成能力与自适应能力非常适合多模态轨迹规划。该模型能够直接从自车与周围智能体轨迹的高维联合分布中采样,且在高维连续控制空间中展现出强大的建模能力——这一点已在图像合成、机器人运动规划等领域的成功应用中得到验证。扩散模型能够自然地对条件分布进行建模,因此可轻松整合轨迹历史、地图语义、自车目标等关键上下文输入,从而提升策略生成过程中的一致性与情境相关性。此外,与许多基于Transformer的架构不同,扩散模型在测试阶段可通过可控采样加入额外约束,无需重新训练模型。
尽管存在如DDIM等用于加速采样的改进方法,但传统扩散模型仍需经过多次迭代去噪步骤,导致推理过程中产生较高的计算成本与延迟成本。为解决这一问题,以往研究表明,利用先验信息从非标准噪声分布开始初始化生成过程,可缩短采样路径。基于这一思路,DiffusionDrive提出了一种截断扩散策略(truncated diffusion strategy),将生成过程锚定到一组固定的轨迹锚点上,使采样可从中间状态开始,从而减少所需的迭代次数。然而,此类固定锚点集缺乏灵活性,无法适应需要动态生成锚点的场景。
针对这一局限,本文提出新型端到端多模态自动驾驶框架AnchDrive。该框架采用多头轨迹解码器,结合场景感知信息动态生成一组动态轨迹锚点,以捕捉局部环境条件下的行为多样性。同时,本文从大规模人类驾驶数据中构建了一个覆盖范围广泛的静态锚点集,为模型提供跨场景的行为先验知识。其中,动态锚点能为当前场景提供符合情境的引导,而静态锚点集则可缓解模型对训练分布的过拟合问题,提升模型在未见过环境中的泛化能力。通过利用这一混合锚点集,基于扩散模型的规划器能够在减少去噪步骤的同时,生成高质量、多样化的预测轨迹。
本文在Navsim-v2仿真平台上以闭环方式对AnchDrive进行评估,该平台包含具有反应性的背景交通智能体与高保真度合成多视角图像。在navtest测试集上的实验结果显示,AnchDrive的扩展预测驾驶模型评分(EPDMS)达到85.5,表明其在复杂驾驶场景中能够生成稳健且符合情境的行为。
本文的主要贡献如下:
提出端到端自动驾驶框架AnchDrive,该框架采用从混合轨迹锚点集初始化的截断扩散过程。这种整合动态与静态锚点的方法,显著提升了初始轨迹质量,并实现了稳健的规划。在具有挑战性的Navsim-v2基准测试中,该方法的有效性得到了验证。
设计了包含密集分支与稀疏分支的混合感知模型。其中,密集分支构建鸟瞰图(BEV)表征,作为规划器的主要输入;稀疏分支则提取实例级线索(如检测到的障碍物、车道边界、车道中心线、停止线等),以增强规划器对障碍物与道路几何结构的理解。
二、相关工作回顾
端到端自动驾驶
近年来,端到端自动驾驶算法因其相较于传统基于规则的运动规划方法具有更优的可扩展性和适应性,受到了广泛关注。这类方法通过直接从原始传感器数据(如相机图像或激光雷达点云)中学习控制信号,绕过了模块化设计流程的复杂性,减少了感知误差的累积,并提升了系统整体的一致性和鲁棒性。
早期的端到端规划器(如UniAD、VAD和Transfuser)依赖自车查询来回归单模态轨迹,而近年来的方法(如SparseDrive)则探索了将稀疏感知模块与并行运动规划器相结合的方案。然而,在复杂交通场景下(如交叉路口或高速变道),车辆的潜在行为可能具有高度模糊性和多样性。若忽视驾驶行为固有的不确定性以及环境感知所要求的多模态决策需求,仅依赖单一预测轨迹往往会导致预测结果过度自信,甚至完全失效。
因此,近期研究开始融入多模态建模策略,生成多个符合当前场景约束的轨迹候选方案,以提升决策覆盖范围。VADv2和HydraMDP等方法通过使用预定义的离散轨迹集实现这一目标。尽管这种方式在一定程度上扩大了覆盖范围,但对固定轨迹集的依赖本质上会将原本连续的控制过程离散化,从而限制了模型的表达能力和灵活性。
扩散模型已成为一种颇具潜力的替代方案,其具备的生成能力和自适应能力非常适合多模态轨迹规划。该模型能够直接从自车与周围智能体轨迹的高维联合分布中采样,并且在高维连续控制空间中展现出强大的建模能力——这一点已在图像合成、机器人运动规划等领域的成功应用中得到验证。扩散模型天然具备建模条件分布的能力,这使得整合关键上下文输入(包括轨迹历史、地图语义和自车目标)的过程变得简单直接,进而提升了策略生成过程中的一致性和上下文相关性。此外,与许多基于Transformer的架构不同,扩散模型在测试时可通过可控采样引入额外约束,而无需重新训练。
尽管已有诸如DDIM等用于加速采样的改进方案,但传统扩散模型仍需大量迭代去噪步骤,导致推理阶段的计算成本和延迟较高。为解决这一问题,先前的研究表明,利用先验信息从非标准噪声分布初始化生成过程,可缩短采样路径。基于这一思路,DiffusionDrive提出了一种截断扩散策略,将生成过程锚定于一组固定的轨迹锚点,使采样能从中间状态开始,从而减少所需的迭代次数。然而,此类固定锚点集缺乏灵活性,无法适应需要动态生成锚点的场景。
本文提出的AnchDrive正是为解决这一局限而设计的新型端到端多模态自动驾驶框架。AnchDrive采用多头部轨迹解码器,结合场景感知动态生成一组动态轨迹锚点,以捕捉局部环境条件下的行为多样性。同时,我们从大规模人类驾驶数据中构建了一个覆盖范围广泛的静态锚点集,提供跨场景的行为先验。这些动态锚点能为当前场景提供量身定制的上下文感知引导,而静态锚点集则可缓解模型对训练分布的过拟合,提升对未见过环境的泛化能力。通过利用这一混合锚点集,我们基于扩散的规划器能够在减少去噪步骤的同时,生成高质量、多样化的预测结果。
我们在Navsim-v2仿真平台的闭环设置下对AnchDrive进行了评估,该平台包含具有反应性的背景交通智能体和高保真合成多视角图像。在navtest测试集上的实验表明,AnchDrive的扩展预测驾驶模型得分(EPDMS)达到85.5,证明其在复杂驾驶场景中能够生成稳健且符合上下文的行为。
本文的主要贡献如下:
提出AnchDrive这一端到端自动驾驶框架,该框架采用从混合轨迹锚点集初始化的截断扩散过程。这种整合动态锚点与静态锚点的方法,显著提升了初始轨迹质量,并实现了稳健的规划。我们在具有挑战性的Navsim-v2基准测试中验证了其有效性。
设计了包含密集分支与稀疏分支的混合感知模型。密集分支构建鸟瞰图(BEV)表征,作为规划器的主要输入;稀疏分支则提取实例级线索(如检测到的障碍物、车道边界、中心线和停止线),以增强规划器对障碍物和道路几何结构的理解。
用于轨迹预测的扩散模型
扩散模型在轨迹预测中的应用已展现出捕捉多模态行为的巨大潜力。在行人预测领域,开创性工作(如MID)将预测重构为反向扩散过程,而LED则引入加速技术以直接学习多模态分布。然而,这些模型并未充分解决车辆运动的复杂性——车辆运动涉及复杂的交互作用以及对交通规则的遵守。
为填补这一空白,后续研究将这些原理适配于车辆轨迹预测。DiffusionDrive引入了动作条件去噪策略,以生成多样化且符合场景的轨迹。在此基础上,DriveSuprim实现了一种从粗到细的框架:首先生成轨迹先验,然后通过基于环境语义和导航意图的条件扩散对其进行优化。这些分层方法提升了采样效率,并为建模丰富的轨迹分布提供了规范化途径,克服了回归类方法中常见的“均值坍缩”问题,为运动规划奠定了稳健的基础。
三、算法详解
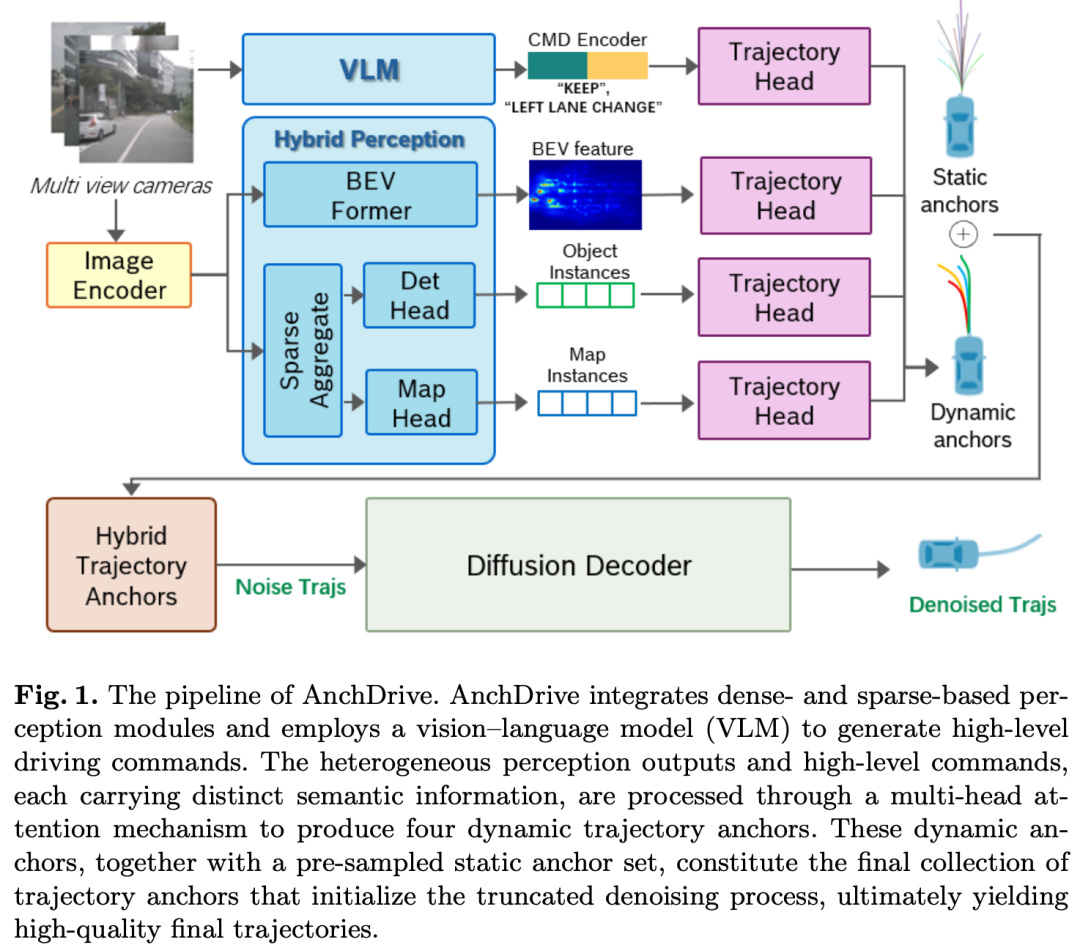
本节将拆解模型架构,并详细分析其各组成部分。模型整体架构如图1所示。
混合感知
感知模块的设计理念是将环境的隐式上下文与显式结构信息协同结合,为下游规划任务提供对场景全面且稳健的理解。为此,我们的架构包含两个并行分支:用于隐式特征提取的密集感知分支,以及用于显式实体识别的稀疏感知分支。
密集感知分支
密集感知分支旨在构建周围环境的整体统一表征。该分支采用基于投影的方法,将多视角相机图像的特征转换为单一的BEV视角。我们生成一个128×128网格的BEV特征图,覆盖自车坐标系下64×64米的区域。这种密集特征图作为主要的上下文输入,为后续规划模块提供了丰富的、关于场景纹理和空间关系的隐式引导。
稀疏感知分支
与之互补的是,稀疏感知分支负责从场景中精确提取关键的实例级实体。该分支采用基于采样的策略,执行两项关键任务:3D目标检测和在线高精地图矢量化。其输出具有结构化和显式的特点,具体包括:1)带属性(如位姿、尺寸、朝向和速度)的3D目标边界框;2)矢量化地图元素(如车道边界、路缘和停止线),每个元素均用点序列表示。这些结构化输出随后通过多层感知机(MLP)编码,生成独特的目标嵌入和地图嵌入。
这种双分支设计的核心优势在于其协同作用。密集BEV为规划器提供了对场景的整体隐式理解,而稀疏分支的显式输出则承担双重作用:不仅作为强有力的特征输入,提升规划器对特定实体(如障碍物和车道)的感知能力,还可直接用于下游任务(如精确碰撞检测和可行驶区域验证)。这种融合了学习到的隐式模式与显式几何约束的混合范式,克服了单模态感知的局限性,为规划决策提供了更丰富、更可靠的基础。
扩散策略
诸如去噪扩散概率模型(DDPM)之类的扩散模型,已成为一类强大的深度生成模型,擅长捕捉复杂的多模态数据分布。这种能力使其天然适合建模自动驾驶行为中固有的不确定性和多模态特性。扩散模型的核心原理包含两个阶段:向数据逐步添加噪声的固定前向过程,以及通过去噪重建数据的学习反向过程。
在前向过程中,干净轨迹会在T个离散时间步内被逐步添加高斯噪声,直至变为纯噪声。任意时间步t的带噪轨迹(记为)可通过以下公式直接采样得到:
式中,服从均值为0、协方差矩阵为单位矩阵的高斯分布;是预定义的噪声调度表,用于控制每个时间步的信噪比。
反向过程的目标是训练一个去噪网络,该网络基于当前带噪轨迹、时间步,以及关键的上下文条件来预测添加的噪声ε。在本文应用中,条件包含从感知模块提取的信息,如BEV特征、道路拓扑和动态障碍物。这一设计将去噪器转化为条件策略。在推理阶段,该策略通过从初始状态开始,在条件的引导下迭代应用学习到的去噪函数,生成轨迹,最终恢复出干净且可行的轨迹。
用于初始化扩散的混合轨迹锚点
传统扩散模型在实时自动驾驶中部署的主要障碍,在于其从纯噪声开始的迭代去噪过程会产生高昂的计算成本。为解决这一局限,我们提出一种初始化扩散策略,该策略利用一组高质量、上下文感知的轨迹锚点。我们的方法并非遍历完整的去噪链,而是从精心挑选的锚点集初始化过程,仅执行最终的优化阶段,从而在保持生成轨迹保真度的同时,显著提升推理效率。
这种混合锚点集通过动态整合两个互补来源构建而成:
动态轨迹锚点
为生成兼具上下文相关性和驾驶意图一致性的锚点,我们设计了一个多头部解码器,该解码器处理四个异质输入流(每个流编码不同的语义信息):(1)整体BEV场景表征;(2)显著实例的稀疏、目标中心特征;(3)捕捉道路拓扑的高精(HD)地图特征;(4)来自视觉-语言模型(VLM)的高层导航指令。这些输入通过多头注意力机制整合后,传递至四个并行的轨迹头部,每个头部生成一个独特的动态锚点。这种架构支持多样化的意图建模——例如,一个头部可能优先遵循VLM发出的“左转”指令,而另一个头部则专注于避开附近的障碍物。
静态锚点与混合集融合
为缓解模型对频繁出现的训练场景的过拟合,并提升对新环境的泛化能力,我们额外采用了一个从大规模人类驾驶数据中预采样的静态锚点集。该集合编码了关于多样化驾驶行为的广泛先验知识。在推理阶段,动态生成的锚点与该静态锚点集融合,形成最终的、全面的轨迹锚点集合,该集合同时实现了广泛的覆盖范围和高度的多样性。
基于锚点的轨迹优化
这种融合后的锚点集作为扩散模型的初始化输入。模型并非从头合成轨迹,而是预测真值与最近的高质量锚点之间的残差偏移——这一过程类似于YOLO等目标检测框架中的锚框优化。
该设计具有三个显著优势:(1)效率——从高质量锚点初始化可大幅减少去噪步骤,满足实时规划严苛的延迟要求;(2)性能——通过将生成能力集中于细粒度优化(而非从头生成),模型实现了更高的轨迹精度;(3)鲁棒性——动态锚点(场景特定适配)与静态锚点(通用先验覆盖)之间的协同作用,显著提升了模型在复杂驾驶场景中的鲁棒性和多模态预测性能。
四、实验结果分析
本节首先展示AnchDrive在NAVSIM v2 navtest基准测试集上的性能表现,接着通过消融实验验证所提模块的有效性,最后提供一系列可视化案例以阐明本方法的优势。
实现细节
实验基于NAVSIM基准测试数据集开展,该数据集是面向规划任务的驾驶数据集,源自OpenScene重新分发的nuPlan数据集。NAVSIM提供8个摄像头的360度视野覆盖以及5个传感器融合生成的激光雷达(LiDAR)点云数据,标注频率为2Hz,标注内容包括高清(HD)地图和目标边界框。该数据集侧重于包含动态驾驶意图的复杂场景,排除了静止或恒速行驶等简单场景。
评估过程采用NAVTEST基准测试集中的扩展预测驾驶模型分数(Extended Predictive Driver Model Score, EPDMS)作为评价指标。EPDMS整合了多个基于规则的子分数,可对驾驶质量进行全面评估,其数学定义如下:
其中,函数用于处理人类参考驾驶员完全遵守某条规则的情况,以避免潜在的除零问题,其定义为:
上述子分数分为两类:一类是乘法惩罚分数集合,分别对应“无责任碰撞”“可行驶区域合规性”“行驶方向合规性”和“交通信号灯合规性”;另一类是加权平均分数集合,分别对应“碰撞时间”“自车进度”“历史舒适性”“车道保持”和“扩展舒适性”。
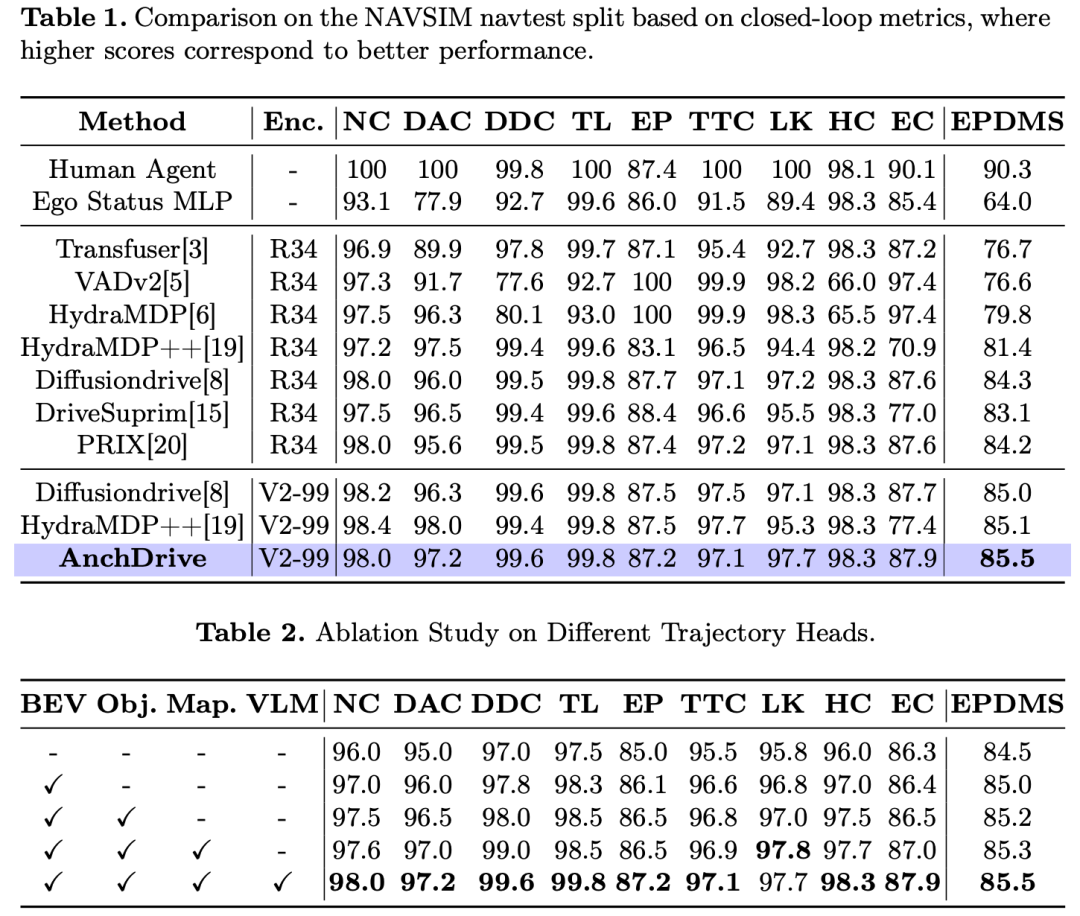
定量对比
在NAVSIM navtest数据集分割上,我们将AnchDrive与当前主流方法进行了基准测试对比。在所有仅使用摄像头(Camera-Only)的方法中,AnchDrive取得了85.5的EPDMS最高分,展现出卓越的性能。
相较于依赖大型预定义锚点词汇表的VADv2方法,AnchDrive的EPDMS分数显著提升了8.9,同时将轨迹锚点数量从8192个大幅减少至仅20个,缩减比例达400倍。这一性能优势同样适用于Hydra-MDP及其改进版本Hydra-MDP++等采用大型词汇表采样范式的方法,AnchDrive的EPDMS分数分别比这两种方法高出5.7和4.1。
此外,与同样采用截断扩散策略的基准方法DiffusionDrive(R34骨干网络)直接对比时,AnchDrive的EPDMS分数提升了1.2,且在所有子分数指标上均优于该基准方法。值得注意的是,上述所有结果均由完全端到端的模型实现,模型直接从数据中学习,未依赖任何手工设计的后处理步骤。
消融实验
表2呈现了针对动态锚点生成器各组件贡献的系统性消融实验结果。实验以不包含任何动态轨迹头的模型作为基线,当引入第一个基于BEV特征的轨迹头后,EPDMS分数实现了0.5的基础性提升。随后,融入基于目标特征的轨迹头后,NC(无责任碰撞)分数得到显著提高,这表明模型能从以目标为中心的锚点引导中有效学习避撞行为。进一步加入基于地图特征的轨迹头后,DAC(可行驶区域合规性)和DDC(行驶方向合规性)等指标均有所提升,这凸显了显式地图感知在增强模型对道路语义和结构依从性方面的关键作用。
最终,通过整合来自视觉语言模型(VLM)的高级驾驶指令,模型性能获得额外提升,EPDMS分数达到最终的85.5。
我们还针对截断扩散模型的去噪步骤数量开展了消融实验,表3的结果揭示了一个关键发现:对于从高质量候选锚点初始化的扩散过程而言,更多的去噪步骤并不一定能保证性能的单调提升,反而会不可避免地增加推理延迟。因此,为在规划性能与计算效率之间取得最佳平衡,最终版本的AnchDrive模型选择2步去噪步骤。
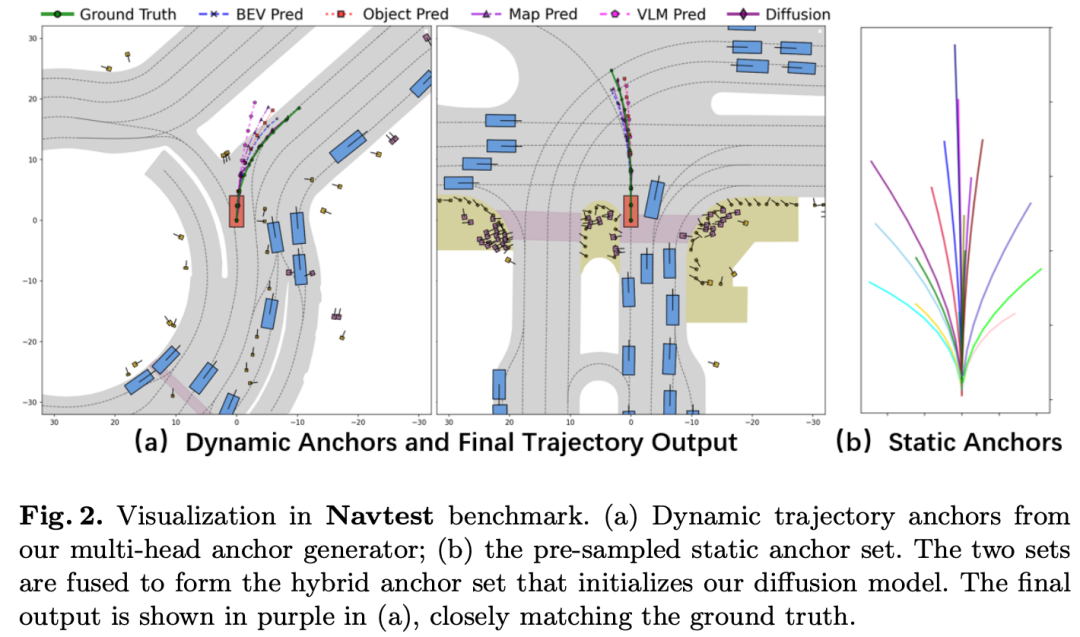
可视化
为评估AnchDrive的泛化能力与优越性,图2展示了在典型驾驶场景中的定性结果。右侧面板(b)呈现了静态锚点集的分布情况,该静态锚点集通过对nuPlan数据集进行k均值聚类得到,涵盖了多种常见的人类驾驶动作。左侧面板(a)所示的两个场景中,动态轨迹头生成的动态锚点与具体场景上下文高度相关,且所有动态生成的锚点均与真实轨迹(Ground Truth)距离较近。这种高质量的初始化使扩散模型能够高效地将锚点优化为最终轨迹,且该最终轨迹与真实轨迹几乎完全吻合。这些结果充分证明了AnchDrive在轨迹规划中的准确性与安全性,尤其在复杂的城市驾驶场景中表现突出。
五、结论
本文提出了AnchDrive——一种新型端到端自动驾驶框架,旨在高效生成多样化且安全的行驶轨迹。该框架的核心创新在于采用截断扩散策略,其扩散过程并非从纯噪声开始,而是从紧凑且高质量的混合轨迹锚点集“热启动”。
这种独特的混合锚点集通过融合两类互补的锚点生成:一类是动态锚点,由BEV特征、目标特征、地图特征和VLM指令等实时场景上下文生成;另一类是静态锚点集,包含通用驾驶先验知识。该方法使AnchDrive能够充分利用扩散模型强大的轨迹优化能力。
实验结果表明,AnchDrive在具有挑战性的NAVSIM v2基准测试集上达到了当前最佳(SOTA)性能,显著优于依赖大型固定锚点集的现有方法,同时也展现出相对于同类扩散基方法的明显优势,为运动规划领域建立了一种高效且强大的新范式。

















 22
22

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









