



点击下方卡片,关注“具身智能之心”公众号
作者丨Zheng Geng等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
想象这样一组反差场景:VLA 模型能流畅完成叠毛巾、整理衣物等几何类操作,可面对 “用机械臂抓起陌生调料瓶”“给未知零件定位 3D 姿态” 这类任务时,却频频失误——要么抓空,要么把物体碰倒。这背后藏着具身智能落地的关键瓶颈:6D 物体位姿估计。
玩过机器人操作的朋友都知道,“抓零件”“放调料瓶” 这类需要精准交互的任务,核心是 “靠空间感知说话”——得知道物体的 3D 位置(平移)和朝向(旋转),还要确保测算的尺度与真实世界一致。可现有方法总在 “妥协”:要么依赖预先扫描的 CAD 模型(现实中根本找不到那么多),要么需要多视角图像(实时场景中哪来得及拍),就算是单视图重建,也会陷入 “不知道物体真实大小” 的尺度模糊困境。
这就导致了鲜明的能力断层:VLA 能靠视觉规划完成 “叠毛巾” 这类不依赖精准空间定位的任务,却在 “抓陌生物体” 这类需要 6D 位姿支撑的操作上寸步难行。根本原因在于,仅凭 RGB 视觉和语言指令,无法构建 “生成模型-真实物体-空间姿态” 的闭环关联——而机器人与物理世界的交互,恰恰依赖这种精准的空间感知。
基于此背景,由北京智源研究院、清华大学、南洋理工大学等机构联合提出的 OnePoseViaGen,给出了一套颠覆性解决方案:它不需要预设 3D 模型,仅凭一张参考图,就能通过 “单视图 3D 生成 + 粗精对齐 + 文本引导域随机化” 的组合拳,完成未知物体的 6D 位姿估计。在 YCBInEOAT、LM-O 等权威 benchmarks 上,它的表现远超 Oryon、Any6D 等主流方法,甚至能支撑机械臂完成灵巧抓取,成功率达到 73.3%—— 这无疑为具身智能补上了 “空间感知” 的关键一块。
所以,今天我们就来聊聊 OnePoseViaGen——让机器人真正 “看懂” 物体空间位置的具身智能新方案。

关键研究成果:OnePoseViaGen 框架
下面我们对 OnePoseViaGen的关键研究成果进行详细解读,整体流程如图 2 所示。遵循 “先解决 3D 模型缺失问题,再校准真实尺度与位姿,最后缩小域差距提升鲁棒性” 的递进逻辑,逐步突破单样本 6D 位姿估计的三大核心挑战,整体流程环环相扣,每个步骤的输出均为下一步的关键输入。
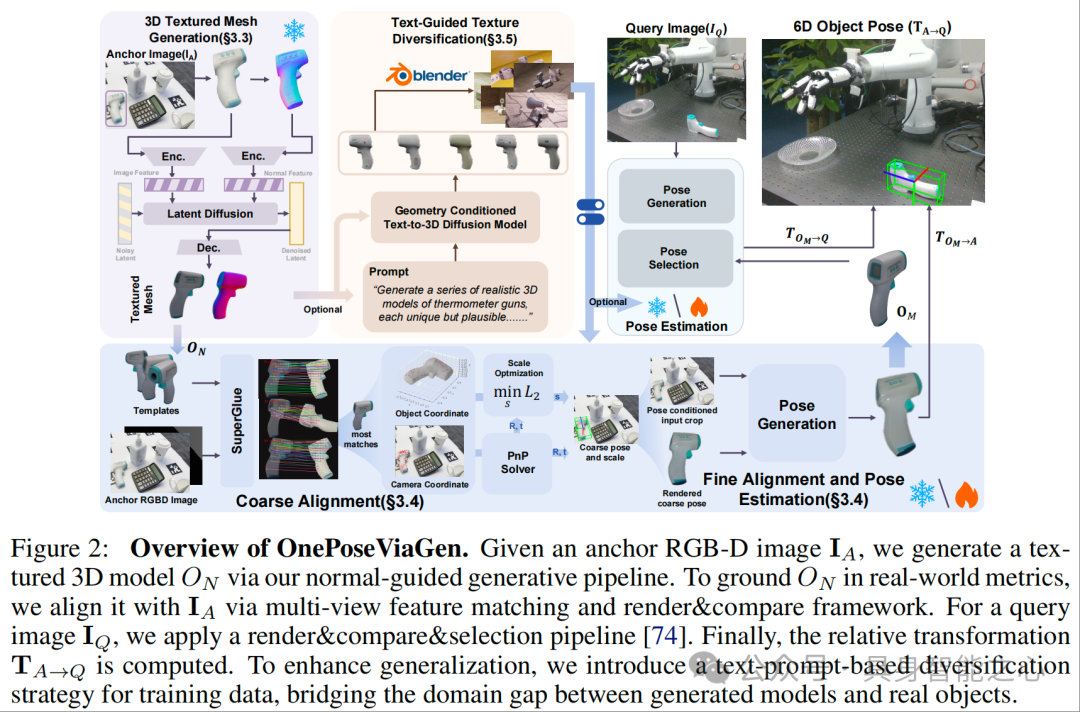
首先要明确任务的核心定义:已知单张 RGB-D 锚点图像 和查询图像 ,需估计物体从 坐标系到 坐标系的相对刚性变换 (包含旋转R和平移t),同时需确定尺度因子s,将生成的标准化模型校准到真实世界尺度。这一定义直接决定了后续方法需同时解决 “模型生成”“尺度 - 位姿对齐”“域适配” 三个关键问题。
基于法向量引导的 3D 纹理网格生成
从单张锚点图像出发,第一步要解决 “3D 模型缺失” 的问题。没有 3D 模型,就无法进行后续的位姿估计。这里选择基于单视图 3D 生成技术,以 Hi3DGen 为基础进行改进:
预处理:对单张 RGB-D 锚点图像进行分割,裁剪掉背景以减少噪声干扰;
法向量估计:通过图像到法向量的转换,生成物体表面法向量图X,确保几何一致性;
3D 生成:基于改进的 Hi3DGen 模型,输入裁剪后的图像 和法向量图X,生成标准化的 3D 纹理模型 (物体中心坐标系,尺度归一化)。
该步骤无需多视图或预训练 3D 模型,仅通过单图即可快速生成高保真的 3D 表示。
粗到精的尺度-位姿联合对齐
拿到标准化模型 后,核心矛盾转为 “如何将归一化模型与真实世界对齐”。由于 的尺度和位姿与 中的真实物体不匹配,直接使用会导致严重的位姿估计误差,因此设计了 “粗到精” 的两步对齐策略,确保精度逐步提升。
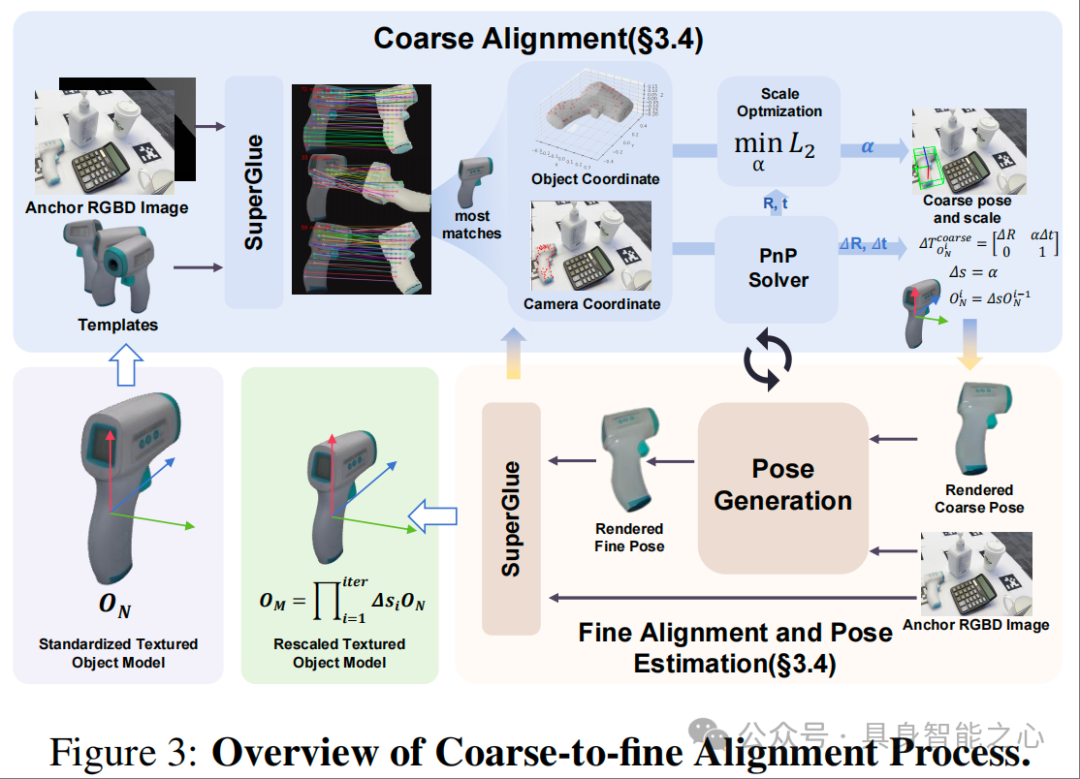
(1)粗对齐:快速获得一个合理的初始尺度和位姿。
多视图渲染:用相机内参K从n个球面视角渲染 ,生成多视图模板;
特征匹配:通过 SuperPoint 提取特征点,SuperGlue 匹配渲染视图与 的 2D 点对,选择匹配数最多的视图;
3D 点提升与 PnP 估计:利用深度信息将 2D 点对提升为 3D 点对,通过 Perspective-n-Point(PnP)算法估计初始 6D 位姿(含尺度模糊);
尺度优化:最小化 “渲染 3D 点经位姿变换后” 与 “真实 3D 点” 的 L2 误差,求解全局尺度因子 ,得到粗对齐位姿 和尺度 。
(2)精对齐:进一步优化位姿与尺度
基于粗对齐结果,进一步迭代优化提升精度:
位姿更新:采用改进的 FoundationPose 框架,通过 “渲染当前位姿的模型→与 计算差异→预测位姿增量 ” 的迭代方式,更新位姿;
尺度重优化:每次位姿更新后,重新运行粗对齐中的特征匹配与尺度优化,确保尺度一致性;
收敛条件:迭代至误差收敛或达到最大迭代次数,最终得到 metric 级 3D 模型 和其在 中的精准位姿 。
文本引导的生成式域随机化
生成的模型 本质上是基于单张锚点图像生成的,仅代表一个物体实例,缺乏真实世界中物体的外观多样性(如不同纹理、材质),且生成模型与真实图像在光照、背景、遮挡等方面存在明显域差距,直接用于查询图像的位姿估计会导致鲁棒性不足。因此设计了文本引导的生成式域随机化策略:
纹理多样化生成:以 和文本提示(如 “生成一系列真实的额温枪 3D 模型,纹理独特但结构一致”)为输入,通过 Trellis 模型生成结构一致、纹理多样的 3D 变体;
合成数据渲染:用 Blender 在随机光照、背景、遮挡条件下渲染这些变体,构建大规模合成数据集;
微调位姿估计器:用合成数据集微调 “渲染 - 比较” 网络,缩小生成模型与真实图像的域差距,提升对遮挡、光照变化的鲁棒性。
综合实践
当所有准备工作完成后,就可以对查询图像 进行位姿估计:
位姿估计:利用 metric 模型 ,采用 FoundationPose 的 “渲染 - 比较 - 选择” 策略,估计 在 中的位姿 ;
相对变换计算:通过锚点与查询图像的绝对位姿,推导物体的相对 6D 变换:
核心结果1:基准数据集验证
通过与当前主流方法(Oryon、LoFTR、Gedi、Any6D、GigaPose)对比,OnePoseViaGen 在所有数据集上均实现性能超越,尤其在高挑战场景下优势显著。
YCBInEOAT 数据集(表 1)
表 1 量化了各方法在不同物体上的 ADD 和 ADD-S 指标,核心结论如下:
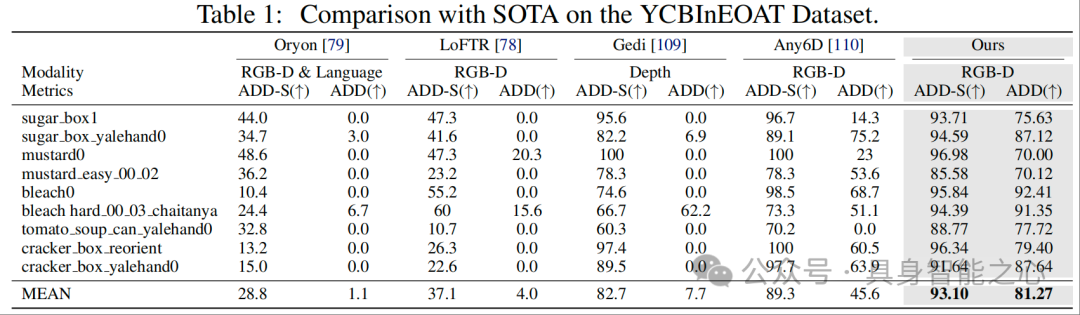
整体优势:OnePoseViaGen 平均 ADD 达 81.27%,平均 ADD-S 达 93.10%,远超其他方法 —— 例如 Oryon 平均 ADD 仅 1.1%、LoFTR 仅 4.0%、Any6D 仅 45.6%,即使是表现较好的 Gedi,平均 ADD 也仅 7.7%;
高挑战物体突破:在 “sugar box1”“tomato soup can yalehand0” 等基线方法失效的场景中,OnePoseViaGen 仍保持高准确率:
“sugar box1”:Any6D 的 ADD 仅 14.3%,而 OnePoseViaGen 达 75.63%;
“tomato soup can yalehand0”:Any6D 的 ADD 为 0.0%(完全失效),OnePoseViaGen 达 77.72%;
这一结果证明,OnePoseViaGen 通过 “单图 3D 生成 + 尺度-位姿对齐”,解决了基线方法在 “无 3D 模型、单样本输入” 下的性能骤降问题。
TOYL 数据集(表 2)
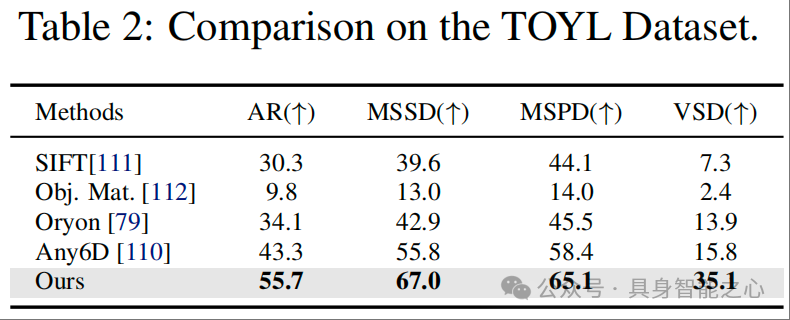
TOYL 数据集聚焦复杂光照与远距离挑战,表 2 显示 OnePoseViaGen 在所有 BOP 指标上均领先:
AR 指标:OnePoseViaGen 达 55.7%,比次优方法 Any6D(43.3%)高 12.4 个百分点,比传统方法 SIFT(30.3%)高 25.4 个百分点;
距离类指标:MSSD(67.0%)、MSPD(65.1%)分别比 Any6D 高 11.2、6.7 个百分点,VSD(35.1%)更是比 Any6D(15.8%)高 19.3 个百分点;
关键结论:生成的 3D 模型提供了可靠的几何约束,减少了对纹理的依赖。
LM-O 数据集(表 3)
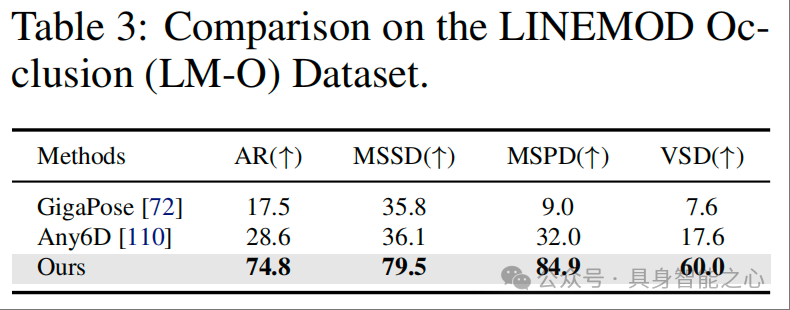
LM-O 是高遮挡无纹理场景的 “硬骨头”,表 3 和表 8(LM-O 各物体详细指标)显示 OnePoseViaGen 的显著优势:
整体 AR:达 74.8%,远超 GigaPose(17.5%)和 Any6D(28.6%),即使是无纹理的 “can”“holepunch” 等物体,AR 也能达到 87.3%、79.2%;

图 10(LM-O 定性结果)直观展示了性能:红色 / 绿色 / 蓝色线为模型坐标轴,粉色线为估计位姿的渲染轮廓,可见即使物体被严重遮挡(如 “driller” 被盒子遮挡),渲染轮廓仍与真实物体边缘高度重合,验证了方法的抗遮挡能力。
核心结果 2:真实机器人操作验证
基准数据集验证了 “算法精度”,真实机器人实验则验证 “落地实用性”,通过两类任务证明 OnePoseViaGen 可支撑精准抓取与协作:
实验设计
任务 1(单臂抓取 - 放置):15 种物体(如马克杯、积木、扳手),随机放置在 10×10cm 区域( orientation 随机 ±15°),需抓取后放置到指定托盘,成功标准为 “抓取稳定(提升≥5cm 无滑落)→运输无碰撞→放置后稳定 3 秒无倾倒”;
任务 2(双臂交接):Arm1 抓取物体→移动到交接区→Arm2 闭合夹爪(力传感器确认抓稳,阈值 5N)→Arm1 松开→Arm2 放置,成功需满足 “全流程无掉落、无碰撞”。
结果
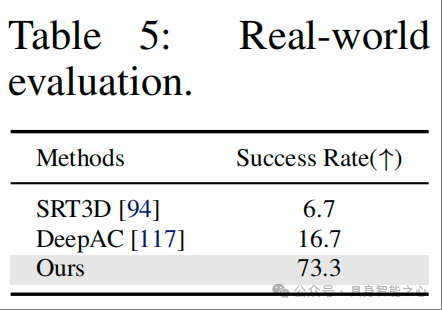
OnePoseViaGen 的整体成功 rate 达 73.3%,远超基线方法 SRT3D(6.7%)和 DeepAC(16.7%)—— 基线方法因位姿估计误差大(如抓取时手部遮挡导致位姿偏移),常出现 “抓空” 或 “放置倾斜”;

定性结果:图 4 展示了实验过程,左列为锚点图像,中列为生成的 3D 模型,右列为机器人抓取时的位姿估计结果,可见生成的模型与真实物体纹理、结构高度一致,估计的位姿能精准指导机械臂抓取(如抓取芥末瓶时,灵巧手的指尖位置与物体轮廓匹配);
关键优势:即使在抓取过程中出现手部遮挡(如 XHAND1 的手指遮挡物体侧面),仍能通过 3D 模型的几何约束精准估计位姿,避免因遮挡导致的抓取失败。
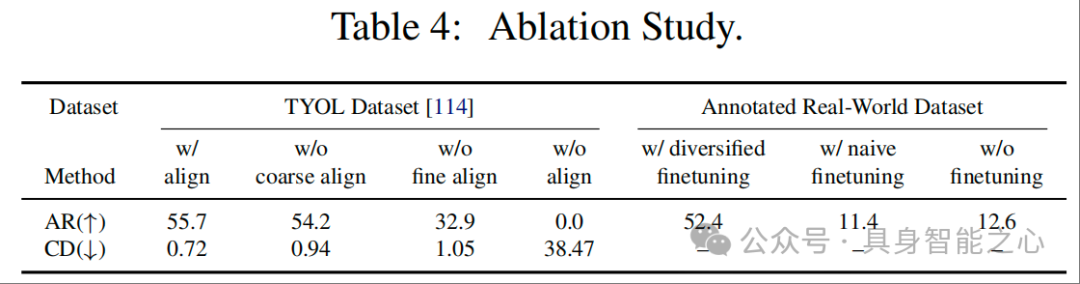
核心结果 3:消融实验
消融实验聚焦 “粗到精对齐” 和 “生成式域随机化微调” 两大核心模块,通过 “移除模块→观察性能变化”,量化各模块的必要性,结果如表 4 所示,充分验证了粗到精对齐的必要性以及生成式域随机化微调是 “提升方法鲁棒性的关键”。
总结
OnePoseViaGen是首个单图 3D 生成与位姿估计融合的 pipeline,证明生成式建模可直接提升位姿估计性能,无需依赖 3D 模型或多视图。通过粗到精的尺度 - 位姿联合优化、文本引导的域随机化、真实场景验证,为 “长尾分布未知物体的精准操作” 提供了新方案,推动机器人从 “特定场景” 向 “开放世界” 交互迈进。
参考
[1]One View, Many Worlds: Single-Image to 3D Object Meets Generative Domain Randomization for One-Shot 6D Pose Estimation


















 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









