 VLA与端到端自动驾驶现状分析
VLA与端到端自动驾驶现状分析




这两天和星球大佬聊了下关于端到端和VLA的看法,感受颇深,分享给大家:
关于端到端的讨论
学术界的端到端现在是遍地开花的状态,什么流派都有,毕竟【端到端】只是一个范式,你只要实现用一个模型把传感器输入和轨迹规划的输出串起来,这就是端到端。
所以做什么的都有。
但是,AI进入大模型时代后,相信大家都有一个共识,那就是数据集的迭代速度一定不能比技术迭代慢太多,技术日新月异的时候,如果数据集反反复复还是那几个,那么毫无疑问数据集一定会阻碍技术的迭代。
摩尔定律不仅体现在芯片算力上,也体现在整个计算机行业。一旦数据集固定下来,以现在的AI技术和庞大算力,其测试指标的收敛速度也会越来越快。
所以才有一些研究团队在发论文的同时发布一个数据集,这样可以保持很长一段时间的高impact输出。
学术界的端到端现在处在方法远比问题多的状态。
工业界的端到端更加务实,车上的算力限制就能把相当一部分热门模型拒之门外。但是,工业界最得天独厚的优势就是有海量的数据,这给模型研发提供了无限可能。
要知道,chatgpt的成功很大程度上归功于互联网给了我们收集海量数据的机会。为什么超大规模transformer模型率先在NLP领域取得巨大成功,就是因为文本数据是互联网行业的舒适圈,互联网想获取海量文本太容易了。
话题回到智驾,工业界想要获取海量驾驶数据也太容易了,稍微有点用户规模的企业数据量都是天文数字,数据阻碍技术迭代的问题在工业界是不存在的。
相反,新的问题源源不断,随便做点什么就是一项专利,想发点东西出去中个paper不是难事,只是老板不让,数据也不能让外面看到,我们也没那个精力。
有了数据加持,我们更容易看清哪些学术界的方法是真材实料,哪些是花架子,我们搞研发也不会刻意追求方法漂亮,which is important for paper,实用即正义。
算力虽然有限制,但我们的方法论上受到的限制要少得多,智驾已经过了靠demo和paper证明实力的阶段,现在展示实力就靠量产模型的表现。
所以在我们看来,目前工业界对端到端技术的研发进度,可能已经领先于学术界了。
如果您也想进一步和自动驾驶学术界及工业界的大佬交流,欢迎加入自动驾驶之心知识星球!星球目前集视频 + 图文 + 学习路线 + 问答 + 求职交流为一体,是一个综合类的自驾社区,已经超过4000人了。

强化学习究竟如何提升VLA性能?
强化学习适用于那些【你没有正确答案,但你知道正确/错误答案各有哪些特点】的问题。VLA的应用场景就是典型的没有正确答案,只有答案特点的问题。
比如一辆车要把你从家里送到商场,可选的路线有很多种,每条路线上走哪个车道有很多种,走在一条车道上,什么时候变到另一个车道上也有很多种。
每一种都是对的,都可以选择。
训练时我们不可能把每一种走法都示范一遍,我们有示范的路线也绝对不是唯一的正确答案,甚至都不是最优的答案。
要知道,模仿学习的基础逻辑仍然是最大似然估计,即假定我们看到的训练数据就是其内在概率模型在最高概率下呈现的样子。所以模仿学习天然倾向于认为,展示给模型的示范结果就是最优结果。
而强化学习就不受这个约束,在强化学习中,车辆平稳抵达+10,压实线-10,闯红灯-20,急刹车-5,……
这些正向的、负向的特点可以写成reward来训练模型。模型只会把reward最大的解当做最优解,从而即节省了采集示范数据的成本,又避免了错误示范、次优示范的干扰。
VLA到底靠不靠谱,有哪些算法可以作为量产参考?
短期难说,长期是趋势。
目前短期看到的一些成果,还是情绪价值的内容偏多一些,VLA在真实控车的过程中究竟发挥了多大作用还是个未知数。
张三吃了一个苹果,转身把一袋大米扛上了10楼,这个苹果可能是普通苹果,可能是兴奋剂苹果,也可能张三不吃这个苹果也能上10楼。
长期来说,Large Vision-Language Model能串连世间一切,这已经是一个不争的事实,可能没必要再质疑,至少主流的厂家都不会质疑,疑问只是要多久才能实现。
我认为用不了太久。
量产参考的不会仅仅是算法。一个VLA模型重要的不仅是它的算法,还有它的数据,训练策略。要选算法的话,必须要综合考虑多重因素,是否容易部署;用于训练的数据情况如何,自己拥有的数据是否是上位平替;训练策略是否复杂,预期的复现难度如何等。绝对不是简单的看看测试指标就下结论。
以上。
如果您也想和自动驾驶学术界或工业界的大佬交流,欢迎加入自动驾驶之心知识星球。我们是一个认真做内容的社区,一个培养未来领袖的地方。

『自动驾驶之心知识星球』目前集视频 + 图文 + 学习路线 + 问答 + 求职交流为一体,是一个综合类的自驾社区,已经超过4000人了。我们期望未来2年内做到近万人的规模。给大家打造一个交流+技术分享的聚集地,是许多初学者和进阶的同学经常逛的地方。
社区内部还经常为大家解答各类实用问题:端到端如何入门?自动驾驶多模态大模型如何学习?自动驾驶VLA的学习路线。数据闭环4D标注的工程实践。快速解答,方便大家应用到项目中。
更有料的是:星球内部为大家梳理了近40+技术路线,无论你是咨询行业应用、还是要找最新的VLA benchmark、综述和学习入门路线,都能极大缩短检索时间。星球还为大家邀请了数十位自动驾驶领域嘉宾,都是活跃在一线产业界和工业界的大佬(经常出现的顶会和各类访谈中哦)。欢迎随时提问,他们将会为大家答疑解惑。除了上面的问题,我们还为大家梳理了很多其它的内容:
端到端自动驾驶如何入门?一段式/二段式量产中如何使用?
传统规划控制想转端到端VLA,求学习路线图!
自动驾驶多模态大模型预训练数据集有哪些?求自动驾驶VLA微调数据集?
多传感器融合现在还适合就业吗?
3DGS和闭环仿真如何结合?应用中需要考虑哪些元素?
世界模型是个啥?业内如何应用,研究还有切入点么?
业内哪家公司前景好一些,适合跳槽,都有什么岗位开放招聘?求星主内推~
博士入学,哪个方向容易出成果?
闭环强化学习如何入门?
端到端自动驾驶学习路线推荐。
......
我们会不定期和一线的学术界&工业界大佬畅聊自动驾驶发展趋势,探讨技术走向和量产痛点:
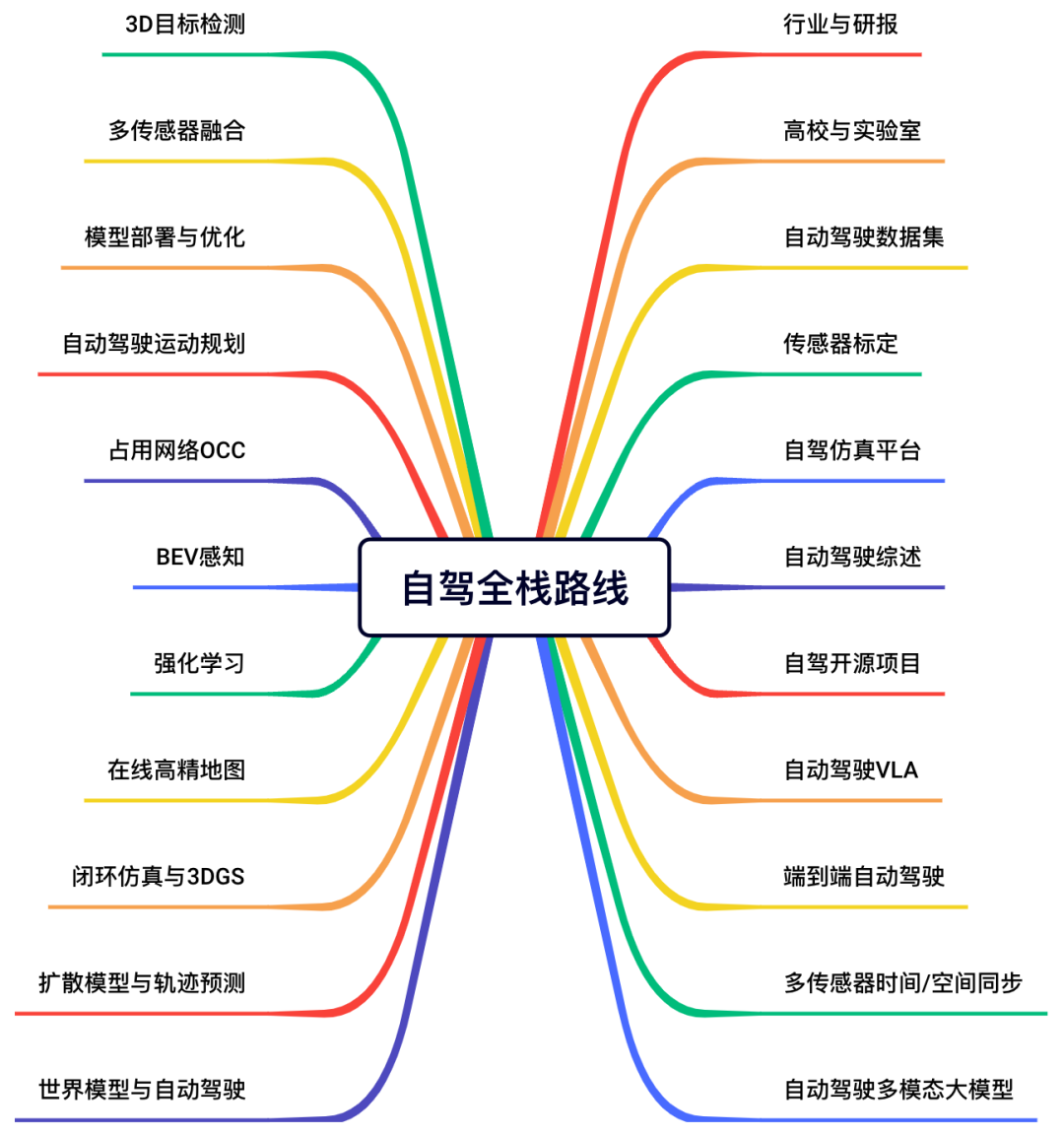
针对入门者,我们整理了完备的小白入门技术栈和全栈路线图。
国内首个自驾全栈社区:自动驾驶之心知识星球
社区创建的出发点是给大家提供一个自动驾驶相关的技术交流平台,交流学术和工程上的问题。星球内部的成员来自国内外知名高校实验室、自动驾驶相关的头部公司,其中高校和科研机构包括但不限于:上海交大、北京大学、CMU、清华大学、西湖大学、上海人工智能实验室、港科大、港大、南洋理工、新加坡国立、ETH、南京大学、华中科技大学、ETH等等!公司包括但不限于:蔚小理、地平线、华为、大疆、广汽、上汽、博世、轻舟智航、斑马智行、小米汽车、英伟达、Momenta、百度等等。前沿技术聚集地一直是自动驾驶之心的标签!
我们为大家汇总了近40+开源项目、近60+自动驾驶相关数据集、行业主流自驾仿真平台、以及各类技术学习路线,包括但不限于:
自动驾驶感知学习路线 | 自动驾驶仿真学习路线 | 自动驾驶规划控制学习路线 |
|---|---|---|
端到端学习路线 | 3DGS算法原理 | 基于搜索的规划 |
VLA学习路线 | NeRF原理 | 基于采样的规划 |
多模态大模型 | Carla仿真 | 基于车辆运动学的规划 |
占用网络 | Apollo仿真 | 基于数值优化的规划 |
BEV感知 | Autoware仿真 | 横纵解耦规划框架 |
扩散模型 | 联合仿真 | 横纵联合规划框架 |
世界模型 | 自驾仿真产品架构分析 | 基于几何的路径跟踪 |
多传感器融合 | 闭环仿真 | 模型预测控制 |
轨迹预测 | 相关数据集 | 联合预测 |
...... | ...... | ...... |
星球内容一览
星球内容一览!

欢迎加入自动驾驶之心知识星球,与4000名自动驾驶从业人员&学术大佬一同交流。

也欢迎添加负责人微信,和我们一起聊聊自动驾驶。


















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









