



❝自动驾驶VLA的思维链应该更灵活。
尽管思维链(Chain-of-Thought, CoT)等推理技术已广泛应用于视觉-语言-动作(Vision-Language-Action, VLA)模型,并在端到端自动驾驶中展现出良好性能,但现有融合CoT推理的方法在简单场景中往往表现不佳——不仅未提升决策质量,还会引入不必要的计算开销。
为解决这一问题,清华&小米等团队提出AdaThinkDrive:一种受“快慢思考”理论启发、具备双模式推理机制的新型VLA框架。具体而言,该框架首先在大规模自动驾驶(Autonomous Driving, AD)场景上进行预训练,通过问答和轨迹数据集获取世界知识与驾驶常识;在SFT阶段,引入包含“快速回答(无CoT)”和“慢速思考(有CoT)”的双模式数据集,使模型能够区分需要推理的场景;此外,本文还提出“自适应思考奖励策略”,并结合GRPO通过比较不同推理模式下的轨迹质量,对模型选择性应用CoT的行为进行奖励。在Navsim基准测试集上的大量实验表明,AdaThinkDrive的预测驾驶模型评分(Predictive Driver Model Score, PDMS)达到90.3,比最佳纯视觉基线模型高出1.7分;消融实验进一步显示,该模型性能优于“永不思考”和“始终思考”两种基线模型,PDMS分别提升2.0分和1.4分,且推理时间较“始终思考”基线模型减少14%,证明其能通过自适应推理实现准确率与效率的平衡。
论文标题:AdaThinkDrive: Adaptive Thinking via Reinforcement Learning for Autonomous Driving
论文链接:https://arxiv.org/abs/2509.13769
更多关于自动驾驶VLA、思维链和强化学习的前沿进展及技术讨论,欢迎加入自动驾驶之心知识星球!与4000名自动驾驶从业人员&学术大佬一同交流。

一、引言
近年来,自动驾驶系统正从传统的模块化流水线逐步转向端到端架构。尽管模块化方法具有工程灵活性,但存在组件间信息损失的问题,导致在复杂和长尾场景中出现累积误差,泛化能力受限。端到端方法通过在统一模型中联合优化感知、预测与规划,在一定程度上缓解了这一问题,但其对有限有监督数据的依赖仍限制了模型的鲁棒性。为解决该问题,近期研究开始探索视觉-语言模型(Vision-Language Models, VLMs),通过大规模驾驶数据集预训练提升模型的场景理解能力。
当前基于VLM的自动驾驶方法主要分为两类:一类是元动作方法,专注于生成高层指导信息;另一类是基于规划的方法,通过语言建模直接预测轨迹。后者中,思维链(CoT)技术的应用日益广泛,其能生成结构化输出,同时提升模型的可解释性与轨迹质量。然而CoT在自动驾驶VLA中的应用仍处于起步阶段。
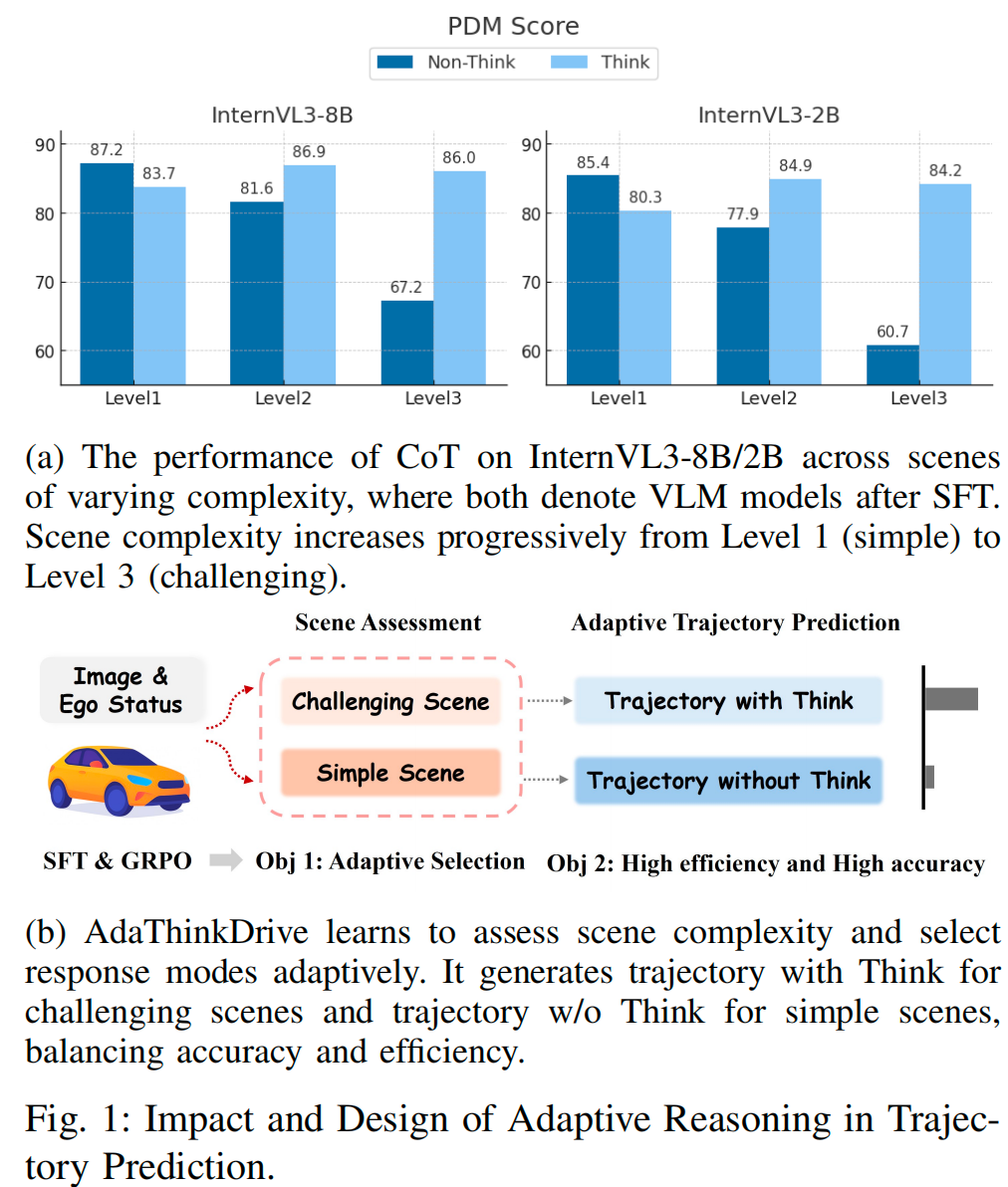
为探索CoT的应用潜力,本文在不同场景复杂度下对VLA模型的推理性能展开对比研究。具体而言,我们将驾驶场景划分为三个复杂度等级(如图1a所示)。实验发现,对于InternVL3-8B和2B两种模型,在简单场景(1级)中,“非思考模型”(Non-Think)性能更优;而随着场景复杂度提升(2级和3级),“思考模型”(Think)则持续表现更佳。这一结果揭示了现有CoT方法的关键局限:在简单场景中易出现“过度推理”。尽管CoT推理在复杂场景中能带来显著收益,但在简单场景中会增加不必要的认知步骤,并提升不确定性。
上述发现表明,最优推理策略并非通用,而是取决于场景复杂度。因此,要提升自动驾驶的决策准确率与推理效率,让模型基于场景复杂度选择性地启用推理,就成为一项关键需求。
基于此,本文提出AdaThinkDrive——一种具备“快速回答/慢速思考”机制的视觉-语言-动作(VLA)端到端轨迹预测框架(如图1b所示)。首先,我们对Navsim基准测试集展开系统分析,评估现有方法在不同场景复杂度下的性能;在此基础上,设计三阶段自适应推理策略,使模型能在可学习奖励机制的引导下,自主决定何时推理、何时直接执行动作。在实现层面,我们首先在大规模驾驶数据上对模型进行预训练;随后,使用定制化的双模式Navsim规划数据集进行有监督微调(SFT),使模型既能生成“思考”(Think)输出,也能生成“非思考”(Non-Think)输出;最后,采用GRPO作为强化学习算法,并构建兼顾“轨迹准确率”“动作合理性”与“推理简洁性”的奖励结构。这种设计使AdaThinkDrive能在规划性能与计算效率之间达到最优平衡。
本文的主要贡献如下:
针对不同场景复杂度,对VLA模型中CoT的性能展开对比研究。通过在Navsim基准测试集上评估“思考”与“非思考”两种范式,发现现有CoT方法在简单场景中存在过度推理的关键局限,进而凸显自适应推理策略的必要性;
提出AdaThinkDrive端到端VLA框架,其“快速回答/慢速思考”机制能基于场景复杂度,在“直接预测”与“显式推理”之间自适应切换;此外,基于GRPO设计“自适应思考奖励策略”,指导模型自主决定何时推理、何时直接执行动作;
在Navsim基准测试集上,AdaThinkDrive的PDMS达到90.3,比最佳纯视觉基线模型高出1.7分;同时,该模型展现出优秀的自适应推理能力:在96%的复杂场景中选择性启用CoT,在84%的简单场景中默认采用直接轨迹预测;此外,与“始终思考”基线模型相比,其推理时间减少14%,充分证明该框架能有效平衡高性能与计算效率。
二、相关工作回顾
自动驾驶中的视觉-语言-动作模型(VLA)
近年来,视觉-语言模型(VLMs)在自动驾驶领域受到越来越多的关注,其通过融合视觉与文本输入,实现感知、规划与决策的一体化。目前该领域的方法大致可分为两类范式:第一类聚焦场景理解与高层推理,例如Senna模型通过解读传感器输入生成元动作,为下游规划器提供指导,但对实际驾驶性能的提升仍有限;第二类范式则从原始输入中直接预测驾驶轨迹。为提升模型的可解释性与准确率,近期方法逐渐引入中间推理过程(思维链,CoT),以揭示内部决策机制。例如EMMA、ReasonPlan和Sce2DriveX等研究表明,领域专用推理能显著改进轨迹预测效果。然而,本文分析发现,CoT的优势主要体现在复杂场景中,在简单场景中不仅难以带来收益,甚至可能产生负面影响。
高效推理模型
随着长思维链(Long CoT)在大语言模型(如DeepSeek)中日益普及,冗长的推理过程导致计算成本大幅增加。AdaptThink通过对比实验提出解决方案:对于简单任务,直接输出答案的准确率更高;而对于复杂任务,推理过程能提升性能,从而在效率与准确率间取得平衡。当前主流的自适应CoT触发方法多基于强化学习,核心在于token级控制与奖励设计,主要可分为三类:(1)简洁推理,通过奖励塑造或严格长度约束实现推理过程的简洁化;(2)动态早期终止,允许模型自适应终止推理;(3)按需推理,使模型能根据任务复杂度自主决定是否启动推理。
在自动驾驶场景中,“何时慢速思考、何时快速响应”的决策尤为关键:在高速公路巡航等简单场景中,无需复杂推理即可实现准确预测;而在路口或拥堵环境等复杂场景中,模型必须仔细分析场景、识别关键智能体,才能生成合理轨迹。本文旨在让模型高效地在必要时启动慢速思考,并在不同推理模式间自适应切换。
三、AdaThinkDrive算法详解
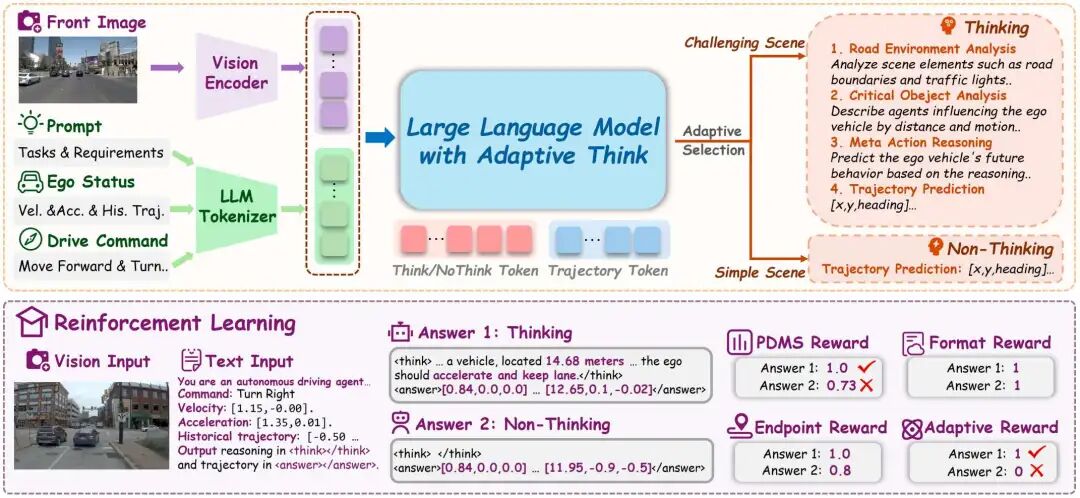
本节详细阐述所提出的AdaThinkDrive框架设计,主要包括三部分内容:(1)数据准备(含预训练数据与混合SFT数据);(2)两阶段监督微调模块(为模型提供有效初始化);(3)基于强化学习的复杂度感知自适应思考(提升模型效率与准确率)。整体框架如图2所示。
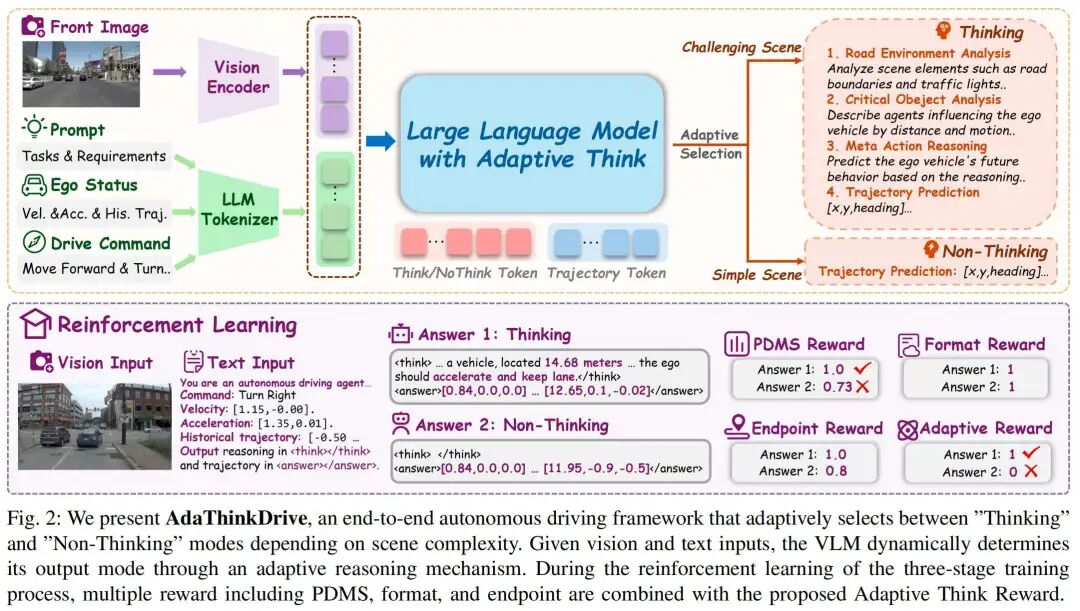
问题建模
输入查询包含前视图像、高层导航指令(如“前进”“左转”“右转”)、自车状态信息(如速度、加速度)以及近三帧的历史轨迹。AdaThinkDrive支持两种推理模式。给定查询,模型根据联合分布共同确定推理模式与输出,公式如下:
对于每个查询,所选模式需最大化任务特定的期望效用,即:
模型的总体目标是学习一个策略,为每个查询选择合适的模式,以最大化查询分布上的期望效用:
数据准备
为使模型具备基础驾驶知识,并理解何时应用CoT推理更有利,我们首先进行如下数据准备工作。
预训练数据
为将通用VLMs适配到自动驾驶场景,我们整合了多个开源驾驶问答数据集,包括DriveLM、LingoQA、ImpromptuVLA、NuScenes-QA、NuInstruct和OminiDrive。此外,在SFT阶段,我们遵循CoT范式为Navsim构建了多轮问答推理数据集,涵盖道路边界估计、关键目标识别、自车动作预测及相关场景理解子任务。
混合SFT数据
SFT数据集包含“推理密集型”与“直接回答型”两类样本:推理数据由辅助模型结合规则化方法生成,确保推理轨迹的高质量;对于交通灯状态、天气条件等详细场景描述,利用Qwen2.5-VL-72B自动生成细粒度标注。
为捕捉场景的动态交互特性,我们识别出可能与自车发生交互的动态智能体,并将其分为三类(如图3所示):(1)路径内最近目标(CIPO-1):位于自车车道内的智能体;(2)潜在并入目标(CIPO-2):根据车道几何结构与相对位置判断,可能并入自车车道的智能体;(3)运动交互目标:预测轨迹与自车轨迹存在交集的智能体。对于道路边界等静态元素,利用Navsim地图重建车道拓扑结构,识别自车未来行驶路径上的关键边界特征。
此外,针对数据集中的每个查询,我们同时生成“思考型”响应(保留完整推理过程)与“非思考型”响应(省略显式推理,但保持结构一致性)。所有样本中,轨迹均直接填充至指定标签区域。最终构建的有监督数据集记为,该SFT数据用于“预热”模型,使其具备区分两种响应模式的基础能力,具体流程可参考图2。
场景分类
为支持自适应推理,我们将Navsim训练集与验证集按复杂度分为三个等级(Level 1、Level 2、Level 3),分类标准与“思考型/非思考型”数据集的构建逻辑一致,主要依据两个因素:(1)自车是否靠近道路边界;(2)是否存在可能影响驾驶决策的关键目标。其中,Level 1为“无上述两种情况”的场景,Level 2为“仅满足一种情况”的场景,Level 3为“两种情况均满足”的场景。我们将数据集定义为,其中对应Level 1(简单场景),对应Level 2与Level 3(复杂场景),这两类标签为下游强化学习提供了原则性初始化依据。

两阶段监督微调
为构建兼具驾驶知识与轨迹规划能力的模型,我们设计了两阶段微调流程:第一阶段注入通用驾驶知识,第二阶段聚焦轨迹生成能力与输出格式合规性。
在第一阶段,模型在大规模驾驶相关问答语料上进行预训练,提升对驾驶领域认知的理解能力,覆盖可行驶区域识别、目标定位、交通语义理解等任务。
在第二阶段,引入轨迹预测任务:对于每个查询,生成两种输出——含推理过程的,以及仅含最终轨迹的。
微调过程中,模型同时对两种输出进行监督训练,目标是最大化条件概率,损失函数定义如下:
该训练策略使模型能在统一接口下学习“思考”与“非思考”两种推理模式,且对任一模式无偏向性。最终,模型可针对任意查询生成两种响应,为GRPO阶段的自适应推理奠定基础。
基于强化学习的自适应思考
经过SFT后,AdaThinkDrive已具备对同一查询生成两种推理模式的初始能力,但不会出现模式“坍缩”(即仅输出单一模式)。然而,我们的目标是让策略模型自适应选择最优推理模式以提升效率,因此在有监督学习之外,额外引入强化学习阶段,明确教会模型如何在不同模式间切换,同时优化规划能力。
为使模型既掌握“如何推理”,又理解“何时推理”,并能利用推理过程实现准确轨迹预测,我们设计了四个互补的奖励组件:PDMS奖励、格式奖励、端点奖励与自适应思考奖励。
PDMS奖励
轨迹奖励采用预测驾驶模型评分(PDMS)作为评估指标,取值为0到1的离散值,直接反映轨迹的整体质量。
格式奖励
格式奖励用于确保输出符合预设格式,包括标签的正确使用(如指定的轨迹标签与推理标签),以及预测轨迹的标准化表示。对于格式违规的任一环节,均给予离散惩罚,以保证输出结构与内容的一致性。
端点奖励
为促进预测轨迹与真实轨迹的端点对齐,我们基于最终点的L1距离设计分段式端点奖励:偏差小于2米时得满分1.0,偏差在2-4米、4-6米、6-10米、10-15米时分别递减至0.8、0.6、0.4、0.2,偏差大于等于15米时得0分。该设计既对大幅误差进行惩罚,又能敏感捕捉端点附近的小幅偏差。
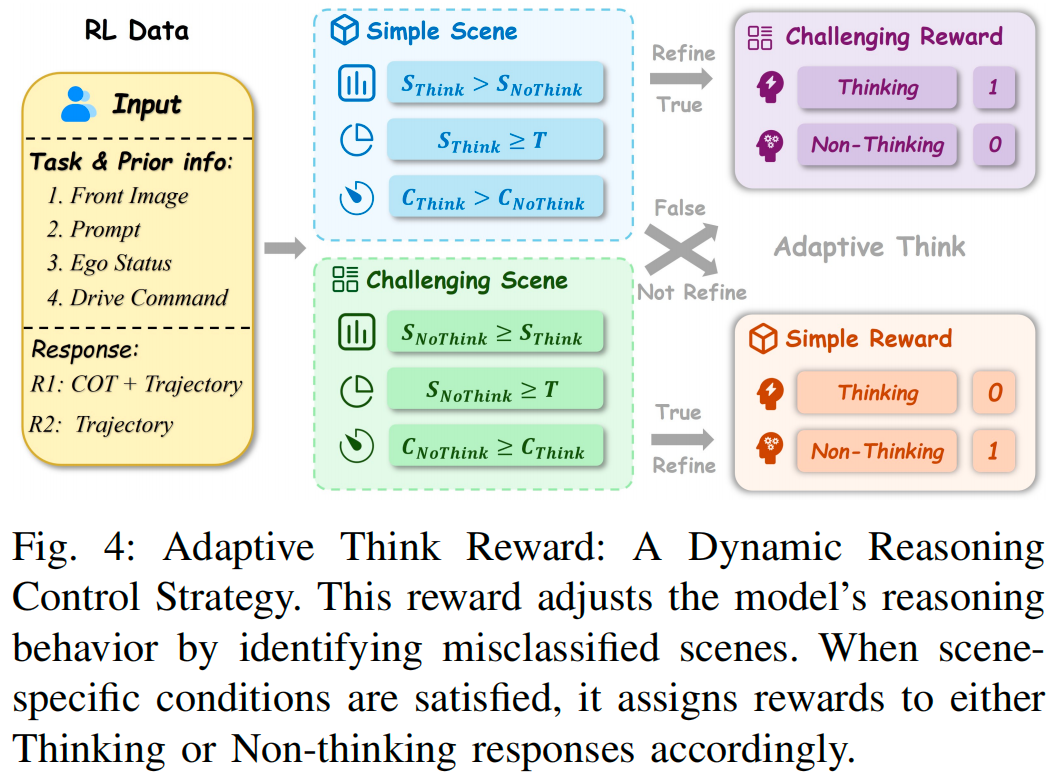
自适应思考奖励
在强化学习训练过程中,策略模型的能力会动态演变,同一场景在训练不同阶段可能被模型判定为“简单”或“复杂”。为应对这一动态性,我们设计了自适应思考奖励,用于指导模型学习“何时思考”,避免过度依赖人工定义的静态场景标签。这些人工标签仅作为推理的初始依据,防止模型出现“模式坍缩”(即仅输出“思考”或“非思考”模式,无法适配场景的实际推理需求);而动态调整机制则允许模型根据实际推理需求修正场景标签,逐步学习自适应思考,同时提升决策效率与预测准确率。
自适应思考奖励通过多轮采样(rollouts)引导模型动态调整推理行为,详细流程如图4与算法1所示。

强化学习过程中的总奖励由上述四个定制化奖励组件加权整合得到。
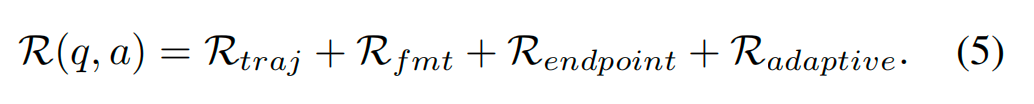
本文采用GRPO作为训练算法:对于每个查询,从旧策略中采样一组候选输出,并基于这些输出的奖励信号优化当前策略。为保证训练稳定性、避免策略剧烈波动,GRPO引入了“截断重要性权重”与“KL散度正则项”——前者抑制过度的策略更新,后者限制当前策略与参考策略的偏差。GRPO的最终优化目标定义如下(其中,与为超参数,相对优势基于一组候选输出的标准化奖励差值计算):
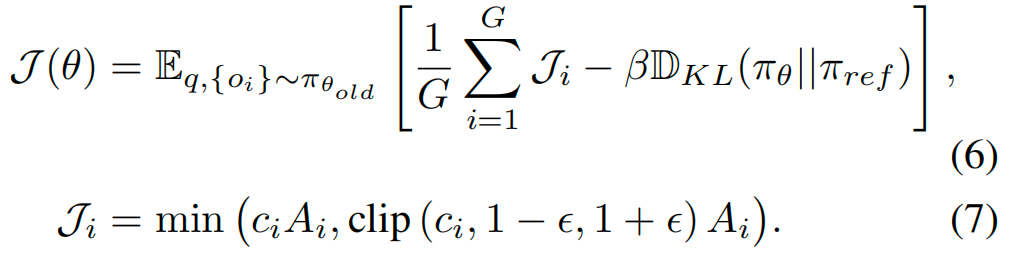
通过强化学习,策略模型可形成自适应推理策略,能根据不同复杂度的场景动态调整推理模式。
实验结果分析
数据集与评估指标
数据集
本文在NAVSIM数据集上开展全面的实验与评估——该数据集是基于OpenScene平台构建的、以规划为核心的自动驾驶数据集。除了从NAVSIM中采集的推理数据外,本文还对多个开源数据集(如DriveLM、ImpromptuVLA、LingoQA)进行格式重构,将其视觉问答(VQA)样本调整为更适配CoT推理的形式,以进一步丰富训练数据。
评估指标
NAVSIM基准测试提供了非反应式仿真环境,并采用预测驾驶模型评分(PDMS) 作为闭环规划指标。该指标整合了5个子指标,从多维度评估自动驾驶性能:
无责任碰撞(No At-Fault Collision, NC):衡量无责任碰撞事件的发生率;
可行驶区域合规性(Drivable Area Compliance, DAC):评估车辆对可行驶区域的遵守程度;
碰撞时间(Time-to-Collision, TTC):反映车辆与障碍物的安全距离余量;
舒适性(Comfort, CF):量化驾驶过程的平稳性;
自车进度(Ego Progress, EP):评估车辆沿规划路线的行驶效率。
PDMS通过对上述子指标的综合计算,形成对自动驾驶闭环规划能力的整体评价,指标值越高表示性能越优。
实现细节
本文以InternVL3-8B作为基础模型,训练过程分为三个阶段,具体参数设置如下:
第一阶段(驾驶知识预训练):在大规模驾驶知识数据集上进行有监督微调,训练轮次(epoch)为2,学习率1×10⁻⁵,批次大小(batch size)为1;
第二阶段(轨迹生成微调):在含“思考”与“非思考”标注的Navsim规划数据集上微调,训练轮次为2,学习率4×10⁻⁵,批次大小为2;
第三阶段(强化学习优化):采用强化学习训练,训练轮次为2,学习率2×10⁻⁶,批次大小为4,训练硬件为64块NVIDIA H20 GPU。
此外,自适应思考奖励中的置信度阈值(T)设置为0.9。
性能对比
AdaThinkDrive的整体性能
表I展示了AdaThinkDrive与当前主流方法在NAVSIM基准测试上的闭环指标对比。在纯视觉输入设置下,AdaThinkDrive的PDMS达到90.3,刷新了该设置下的最优性能(SOTA)。与此前纯视觉最佳方法Hydra-NeXt相比,AdaThinkDrive的PDMS提升了1.7分,充分证明其在模型建模能力与轨迹预测准确性上的显著优势。
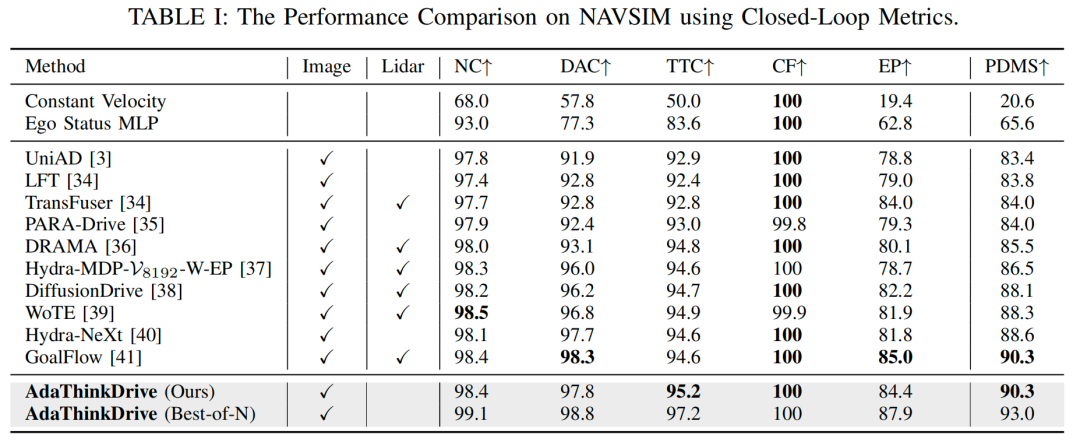
尽管仅依赖视觉输入,AdaThinkDrive的性能仍与多模态方法GoalFlow相当,进一步验证了其自适应推理机制的有效性,以及在复杂驾驶场景中的强泛化能力。此外,在“N选优规划”(best-of-N planning)策略下,本文利用Navsim参考轨迹评估器从4个生成候选轨迹中筛选最优轨迹,最终PDMS达到93.0,创下该基准测试的最高得分。
自适应思考的定量评估
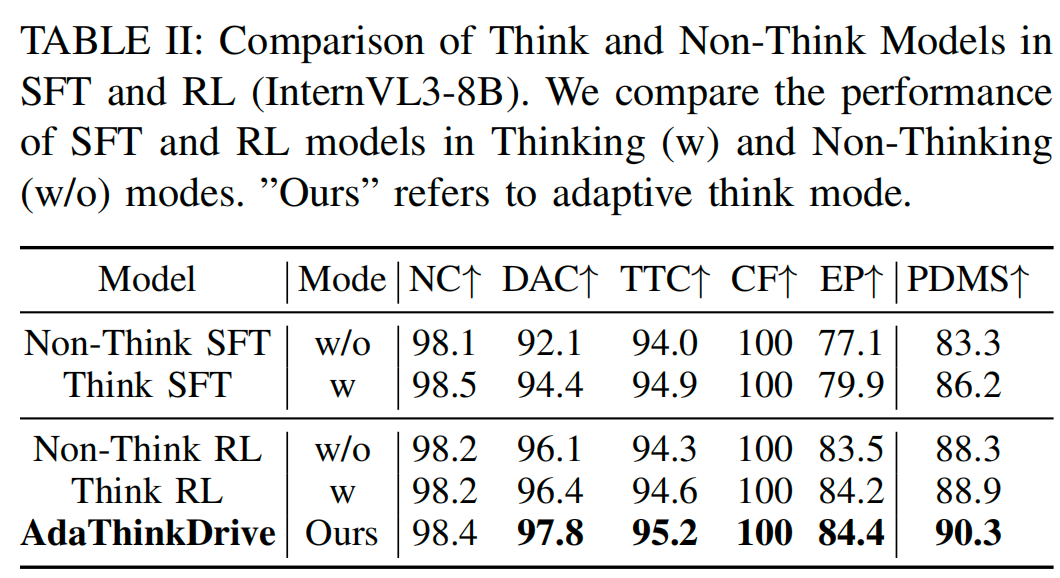
本文首先将AdaThinkDrive与以下两类模型进行对比(结果见表II):
思考/非思考SFT模型(Think/Non-Think SFT):仅训练为“始终生成CoT”或“永不生成CoT”的SFT模型;
思考/非思考RL模型(Think/Non-Think RL):在对应思考/非思考SFT模型基础上微调得到的RL模型。
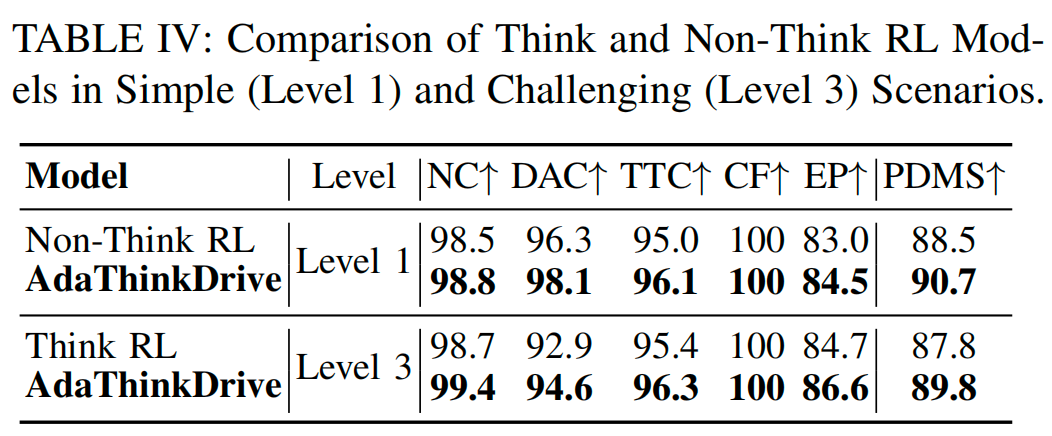
对比结果显示,AdaThinkDrive的整体性能最优,其PDMS比非思考RL模型高2.0分,比思考RL模型高1.4分。如表IV所示,在1级(简单)场景中,AdaThinkDrive的PDMS比非思考RL模型高2.2分;在3级(复杂)场景中,其PDMS比思考RL模型高2.0分。这一结果充分体现了AdaThinkDrive的核心优势:在简单场景中跳过冗余推理以提升效率,在复杂场景中利用结构化推理提高准确性,实现了两种策略的优势融合。
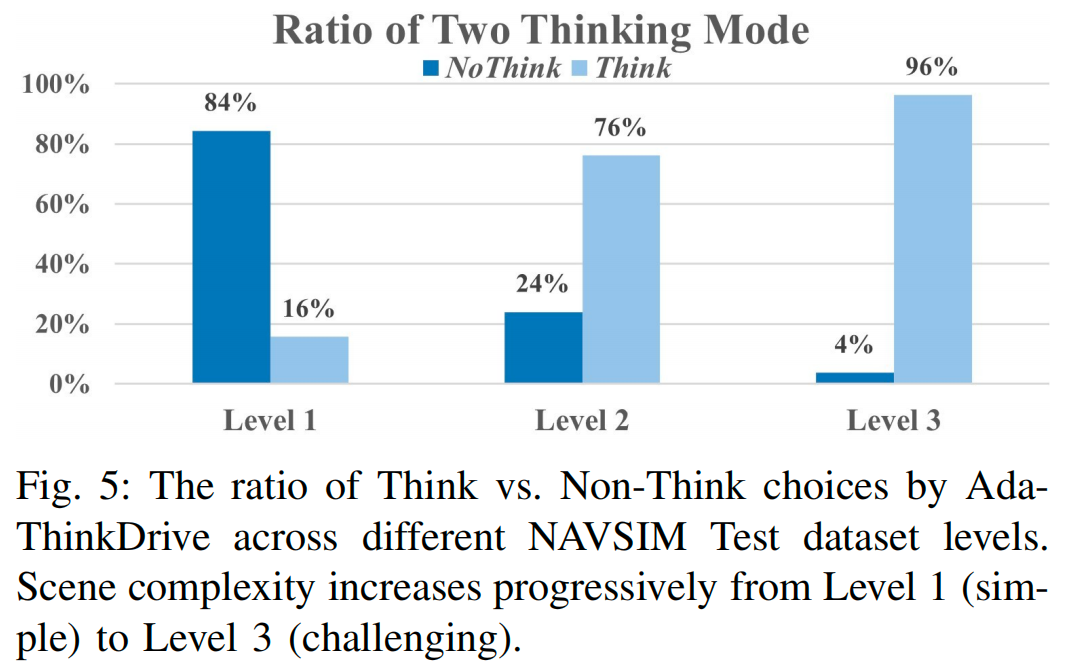
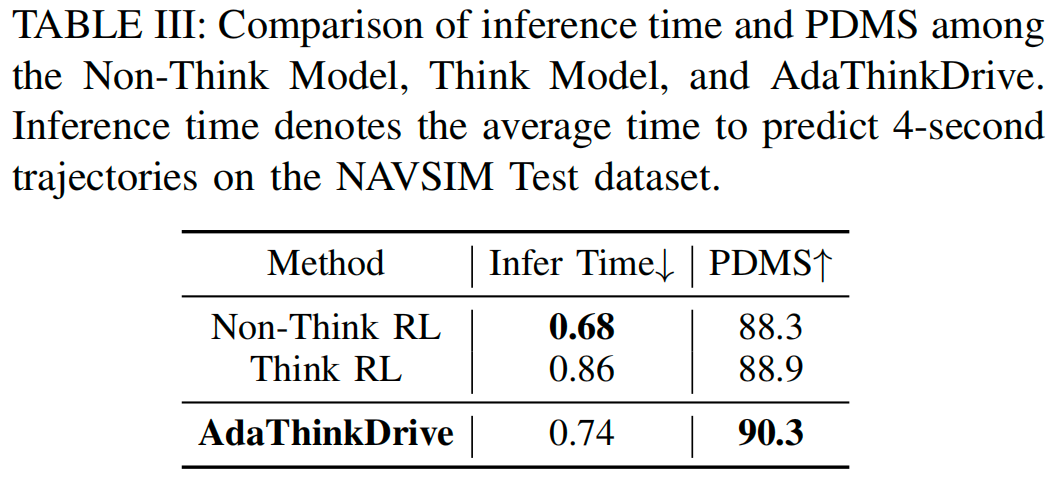
对不同场景复杂度的行为分析(图5)进一步验证了这一点:AdaThinkDrive在简单场景中更倾向于选择“非思考”模式,在复杂场景中则逐步增加“思考”模式的使用比例,展现出灵活的动态推理控制能力。此外,表III显示,与非思考RL模型相比,AdaThinkDrive的推理时间仅增加9%,但PDMS提升了2.0分;与思考RL模型相比,其推理时间减少14%,同时保持更高的PDMS。这些结果共同证明,自适应推理能在多样化驾驶场景中实现准确性与效率的平衡。
自适应思考的定性分析
图6展示了AdaThinkDrive与基线模型在简单场景和复杂场景中的定性对比结果。在简单场景中,思考RL模型将远处目标误判为关键目标,导致不必要的推理,最终生成的轨迹偏离可行驶区域;而AdaThinkDrive跳过冗余推理,直接输出平滑、准确的轨迹。在复杂场景中,非思考RL模型未能准确评估与前车的距离,生成的轨迹存在安全风险;而AdaThinkDrive能识别关键目标(如前车),并生成符合安全要求的轨迹。这些案例直观证明,AdaThinkDrive能根据场景复杂度自适应调整推理策略,同时提升驾驶安全性与决策质量。

消融实验
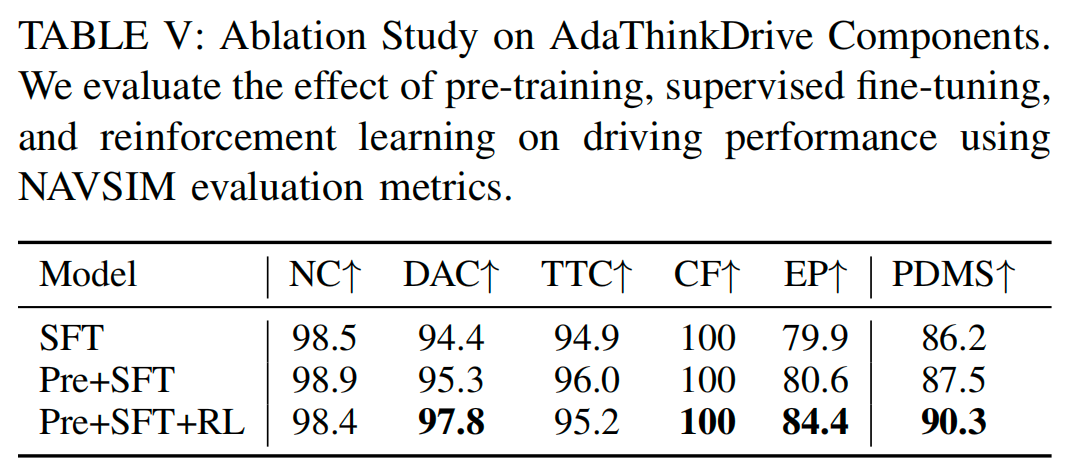
AdaThinkDrive的三阶段训练消融
表V展示了AdaThinkDrive三阶段训练流程(预训练、SFT、RL)的消融实验结果。仅使用NAVSIM轨迹数据进行SFT时,模型PDMS为86.2;加入大规模驾驶问答数据集预训练后,PDMS提升至87.5,增幅1.3分;进一步引入自适应思考强化学习与本文提出的自适应思考奖励后,PDMS达到90.3,增幅2.8分。这一结果表明,预训练能提升模型的驾驶知识储备,而自适应强化学习策略则是增强模型推理与决策能力的关键,二者共同保障了AdaThinkDrive的高性能。
奖励设计的有效性对比
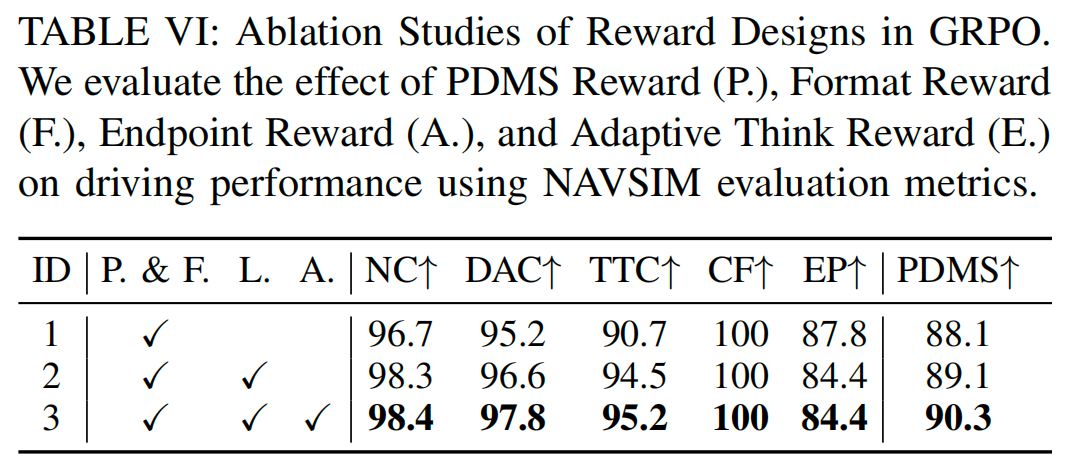
表VI展示了不同奖励组合对PDMS的影响。仅使用基础PDMS奖励与格式奖励时,模型PDMS为88.1;加入端点奖励后,PDMS小幅提升至89.1;进一步加入自适应思考奖励后,PDMS达到90.3。这一结果表明,自适应思考奖励是提升规划效率与准确性的核心组件,能有效增强模型在多样化场景中的决策能力。
五、结论
本文认为,在简单场景中进行推理往往会增加计算开销,却无法提升决策质量。为解决这一问题,本文提出了AdaThinkDrive——一种视觉-语言-动作(VLA)框架,能让智能体自适应学习“何时需要思考”。本文的核心贡献是提出了以“自适应思考奖励”为指导的强化学习框架,该框架能使模型的推理行为与场景复杂度相匹配。
在NAVSIM基准测试上的实验结果表明,AdaThinkDrive实现了当前最优(SOTA)性能。这些发现充分证明,自适应思考对于自动驾驶系统实现准确且高效的决策至关重要。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









