



分享下最近自动驾驶领域的前沿文章,涉及端到端、Diffusion Policy、OCC、VLM几个方向!更多内容欢迎加入自动驾驶之心知识星球,行业动态、大佬交流、技术问答、求职内推,一站直达。每天仅需七毛钱,欢迎加入与我们共创自动驾驶未来~

KDP-AD
基于专家路由的知识驱动扩散策略在端到端自动驾驶中的应用
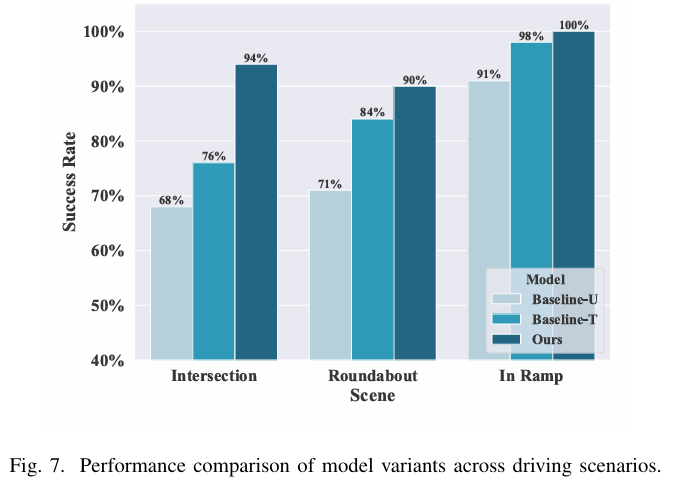
同济大学与北卡罗来纳大学教堂山分校的研究团队提出了一种基于知识驱动与专家路由的扩散策略(KDP),在仿真环境中实现了在匝道合并、交叉路口和环形交叉路口三种典型场景中分别达到100%、94%和90%的成功率,显著优于强化学习、规则基和模仿学习基线方法。
论文标题:A Knowledge-Driven Diffusion Policy for End-to-End Autonomous Driving Based on Expert Routing
论文链接:https://arxiv.org/abs/2509.04853
项目主页:https://perfectxu88.github.io/KDP-AD/
主要贡献:
提出知识驱动的端到端驾驶框架:将混合专家(Mixture of Experts, MoE)中的专家重塑为抽象驾驶知识单元,突破传统任务中心式模型设计局限,实现模块化、组合式的策略学习,支持跨场景知识复用与新行为的涌现式生成。
融合扩散建模与专家路由机制:将扩散策略(Diffusion Policy)与 MoE 架构结合,扩散组件通过条件去噪过程生成时序连贯的多模态动作序列,保障长时域(long-horizon)一致性;MoE 路由机制依据场景动态激活专家,实现知识的模块化组织与选择性复用,平衡多模态表达与场景适应性。
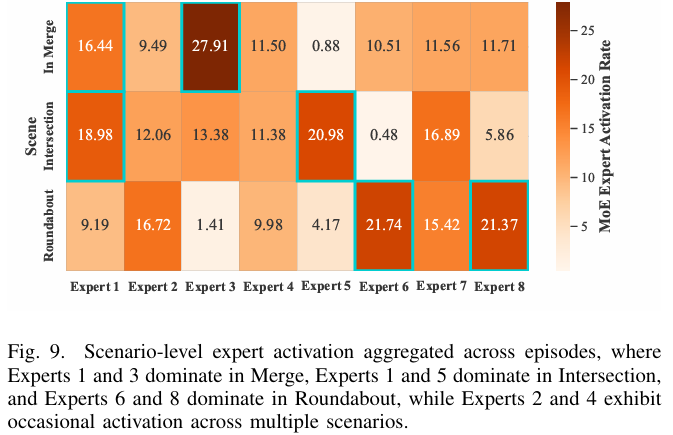
开展全面实证验证:在汇入匝道(In Ramp)、无信号交叉口(Intersection)、环岛(Roundabout)等典型驾驶场景中,验证了所提框架(KDP)相较于强化学习(PPO-Lag)、规则驱动(RPID)、模仿学习(IBC)等基线方法,在成功率、碰撞风险控制、控制平滑性及泛化能力上的显著优势,并通过消融实验与专家激活分析验证了核心组件(稀疏专家激活、Transformer 骨干)的有效性。
算法框架:
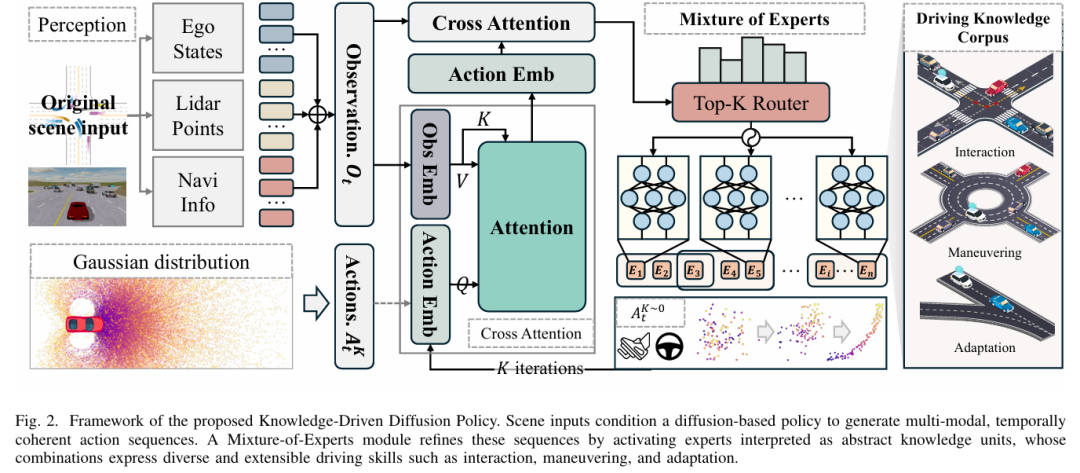
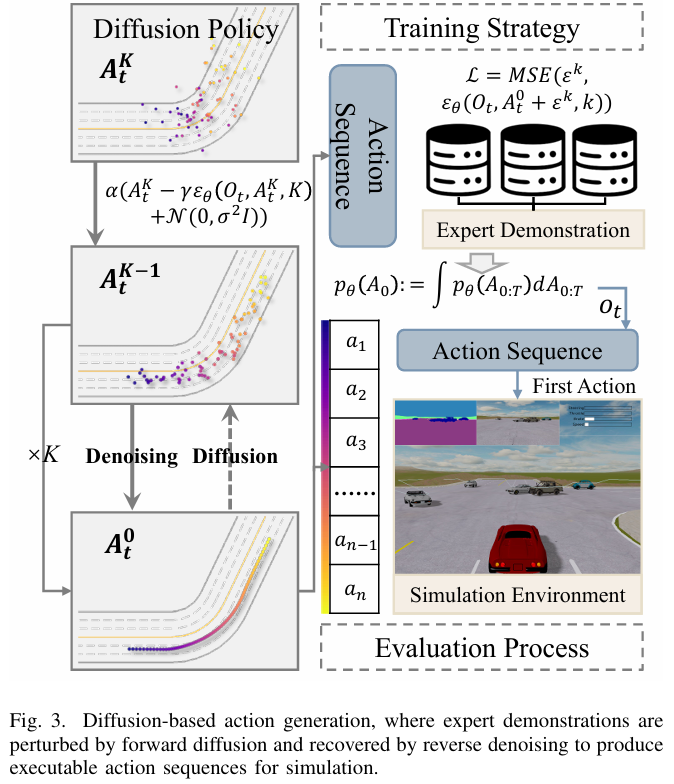
实验结果:
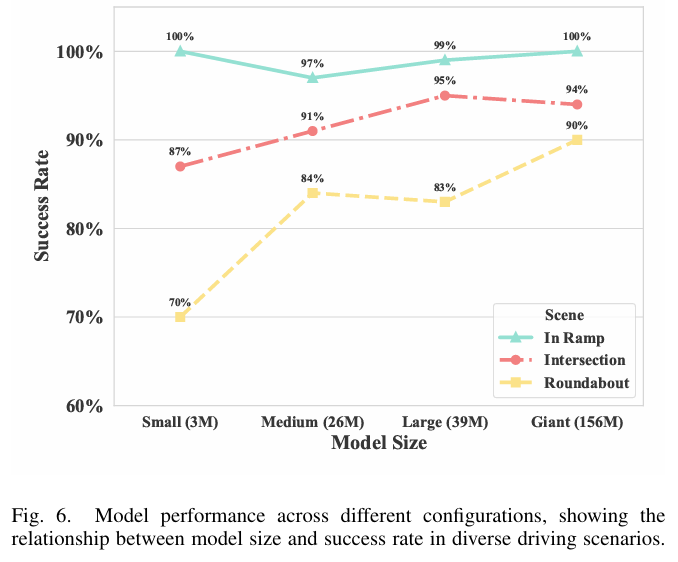
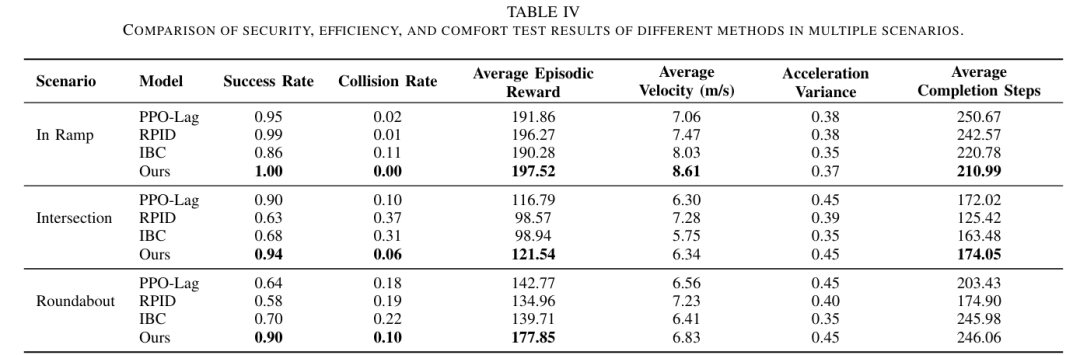
可视化:
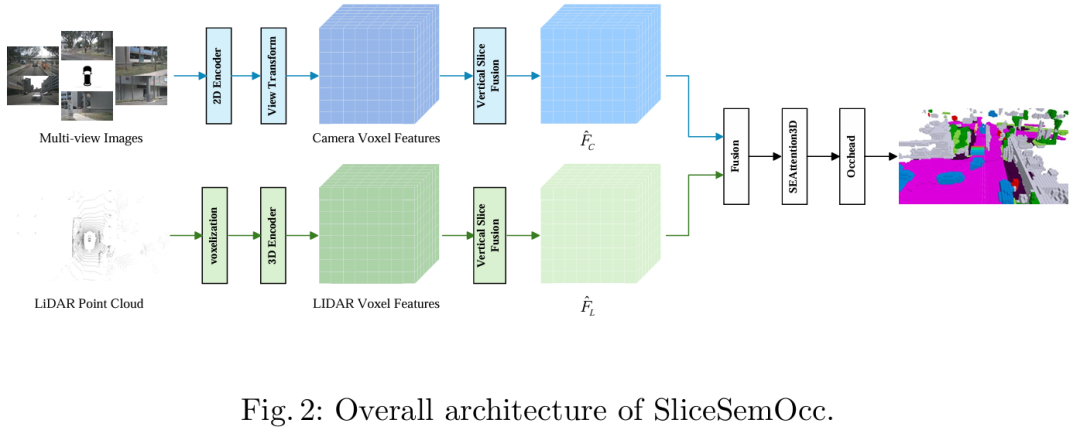
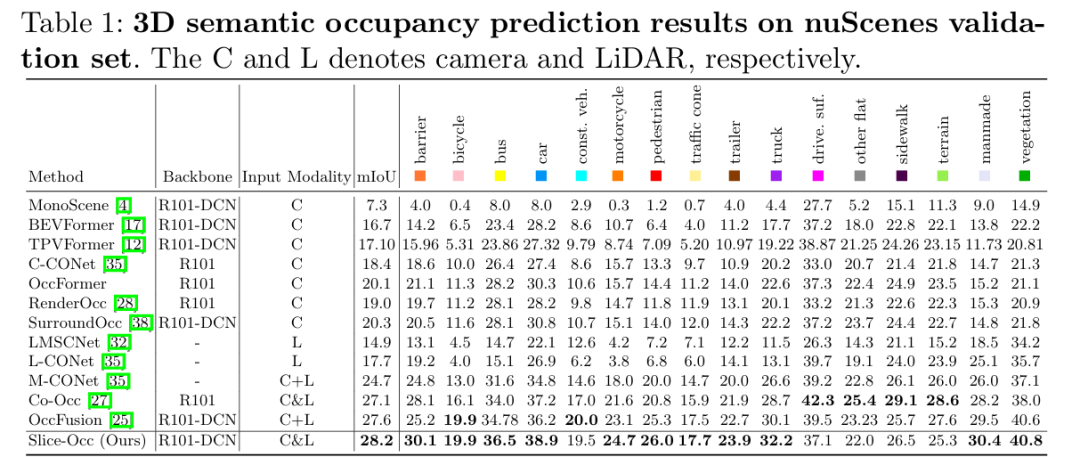
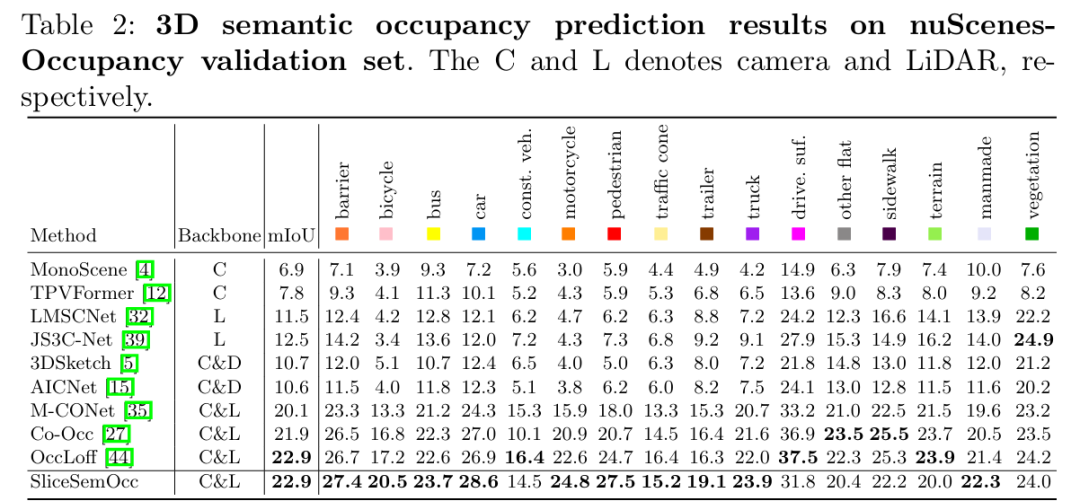
SliceSemOcc
基于垂直切片的多模态3D语义占据预测新框架
南京航空航天大学等单位提出了一种基于垂直切片的多模态3D语义占用预测框架SliceSemOcc,通过引入高度感知的通道注意力和分层融合策略,在nuScenes-SurroundOcc数据集上将mIoU从24.7%提升至28.2%(相对提升14.2%),尤其在小型物体类别上表现显著提升。
论文标题:SliceSemOcc: Vertical Slice Based Multimodal 3D Semantic Occupancy Representation
论文链接:https://arxiv.org/abs/2509.03999
主要贡献:
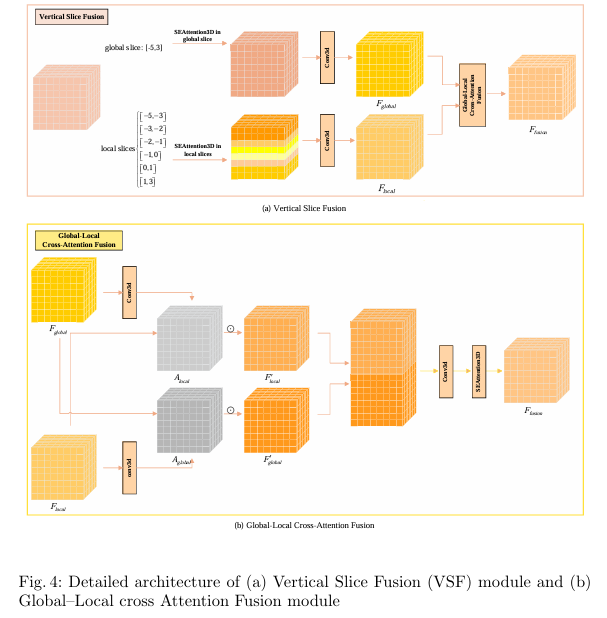
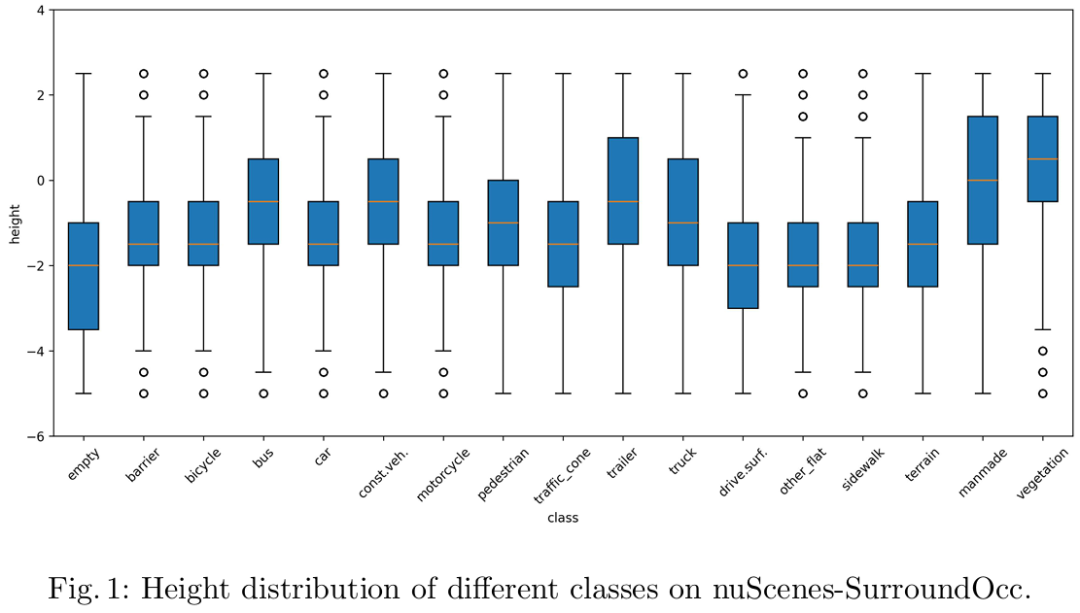
提出垂直切片融合(VSF)模块:采用双尺度垂直切片策略,分别提取覆盖全高度范围([-5, 3] m)的全局切片与聚焦小目标集中高度区间(如 [-5,-3]、[-3,-2] 等 6 个关键子区间)的局部切片;通过双向交叉注意力机制融合两类切片特征,实现细粒度空间细节与全局场景上下文的联合建模,针对性解决小目标表征不足与全局结构建模缺失的问题。
设计 SEAttention3D 通道注意力模块:突破传统 SENet-style 注意力对所有高度层分配统一权重的局限,在平均池化过程中仅对空间平面维度(X、Y 轴)操作以保留高度轴(Z 轴)分辨率,并通过 1D 卷积与激活函数生成高度层专属的通道权重,实现对不同高度语义特征的差异化增强,强化垂直结构表征能力。
验证方法有效性:在 nuScenes-SurroundOcc 和 nuScenes-OpenOccupancy 两大数据集上完成全面实验,SliceSemOcc 分别实现 28.2% 和 22.9% 的整体 mIoU,较基线模型(如 M-CONet)相对提升 14.2% 和 13.9%,尤其在小目标类别(障碍物、自行车、行人等)上增益显著;通过消融实验验证了双尺度切片、SEAttention3D、交叉注意力融合等核心组件的必要性。
算法框架:
实验结果:
可视化:

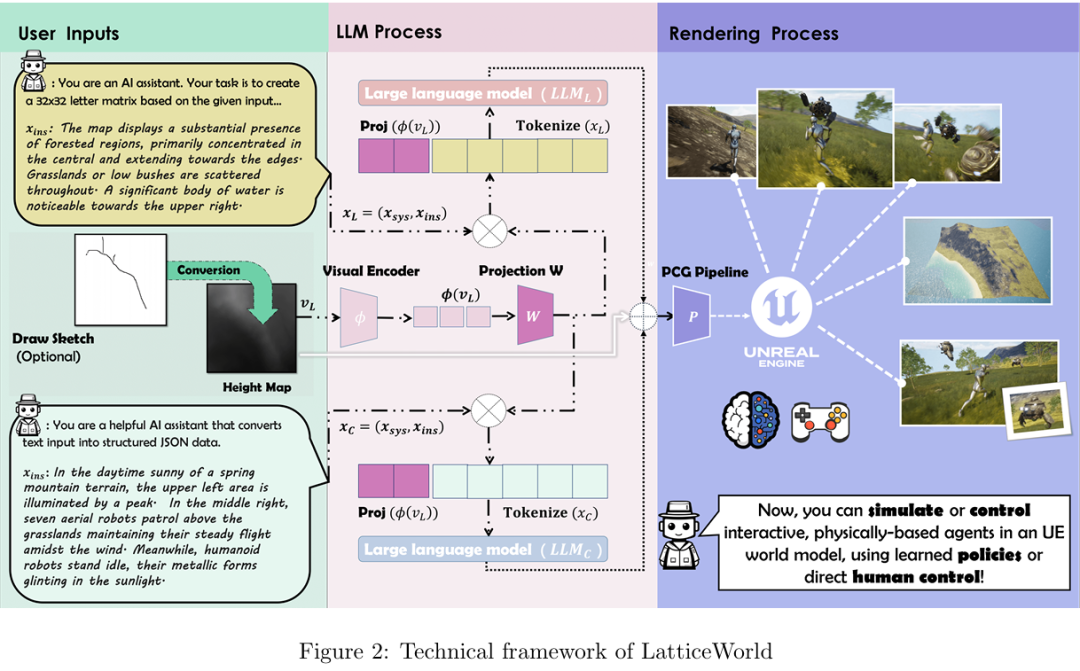
LatticeWorld
基于多模态大语言模型的交互式复杂世界生成框架
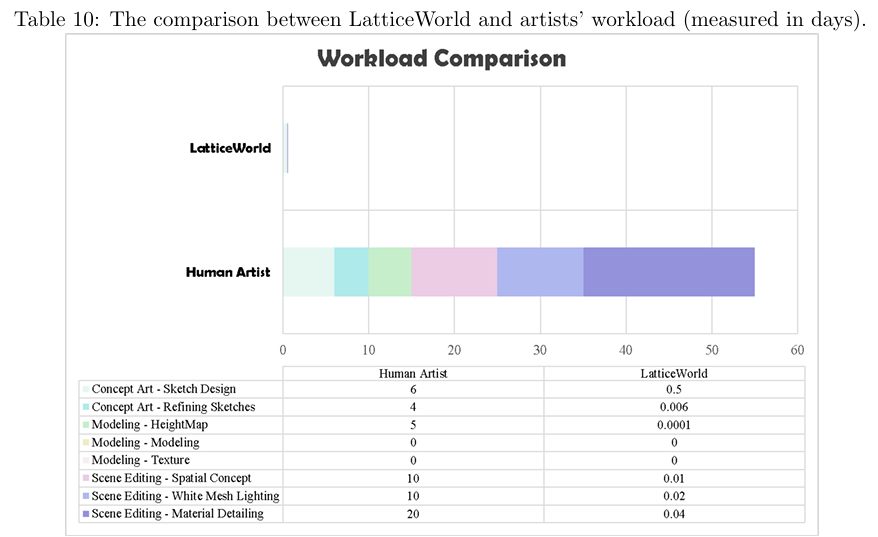
网易(NetEase)与清华大学的研究团队提出了一种基于轻量级多模态大语言模型(LLaMA-2-7B)与Unreal Engine 5的交互式3D世界生成框架LatticeWorld,实现了90倍以上的工业级场景生成效率提升(从55天缩短至0.6天以内),并支持多模态输入、动态多智能体交互与高保真物理仿真。
论文标题:LatticeWorld: A Multimodal Large Language Model-Empowered Framework for Interactive Complex World Generation
论文链接:https://arxiv.org/abs/2509.05263
主要贡献:
提出 LatticeWorld 框架:融合轻量级多模态大语言模型(LLaMA-2-7B)与工业级渲染引擎(Unreal Engine 5,UE5),支持多模态输入(文本描述 + 视觉指令如高度图 / 草图),可生成具备动态多智能体交互、高保真物理模拟、实时渲染的大规模 3D 交互世界,填补现有方法在 “交互性 + 工业级效率” 上的空白。
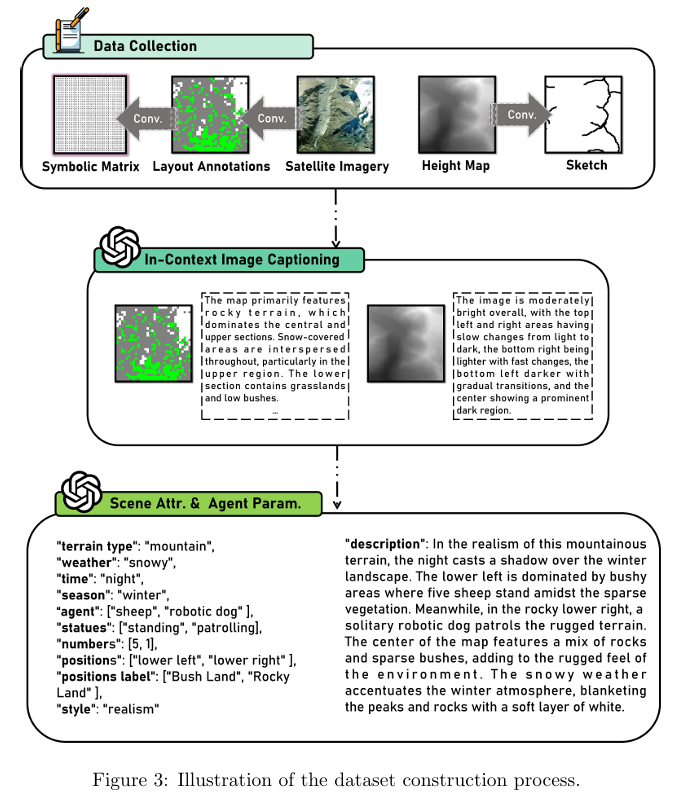
设计可解释的中间表示:提出 32×32符号矩阵作为场景布局中间表示,将空间信息编码为 LLM 可处理的序列形式,既解决传统视觉生成模型的布局不可控问题,又提升 LLM 对空间关系的理解精度,实现布局生成的语义可解释性。
构建专属多模态数据集:基于 LoveDA(开源遥感数据集)和 Wild(自研荒野场景数据集),结合 GPT-4o 标注与提示工程,构建包含 “文本描述 - 视觉指令(高度图 / 草图)- 符号布局 - 环境配置” 的数据集,支撑固定高度 / 变高度场景、环境配置的模型训练,保障数据质量与多样性。
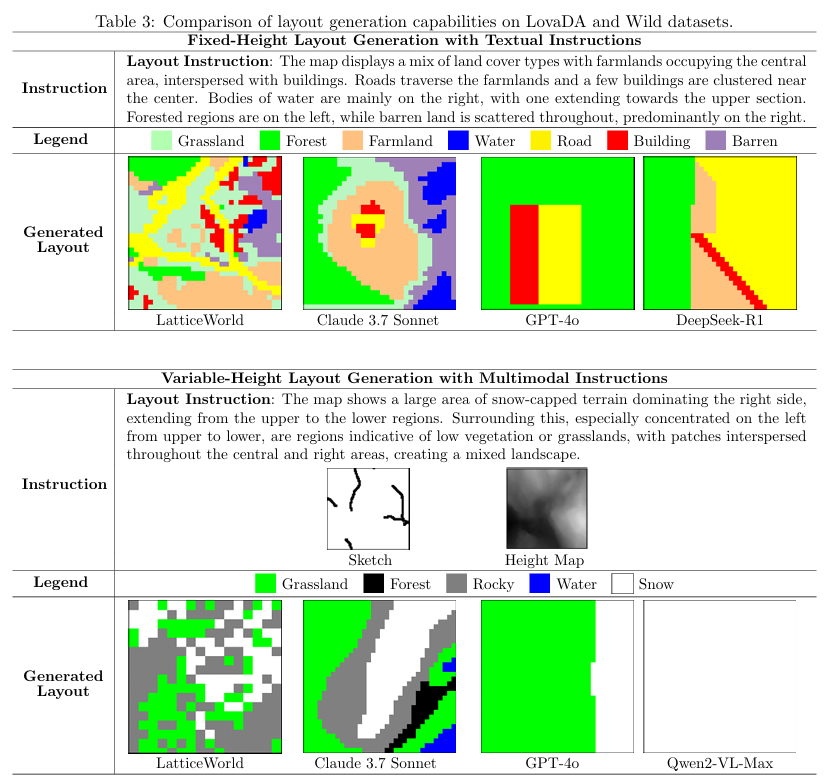
实验验证性能优势:在场景布局准确性(对比 GPT-4o、Claude 3.7 Sonnet 等模型)、视觉保真度上优于现有方法;同时较传统人工生产流程,效率提升超 90 倍,且保持高创作质量,兼顾学术性能与工业应用价值。
算法框架:
实验结果:
可视化:


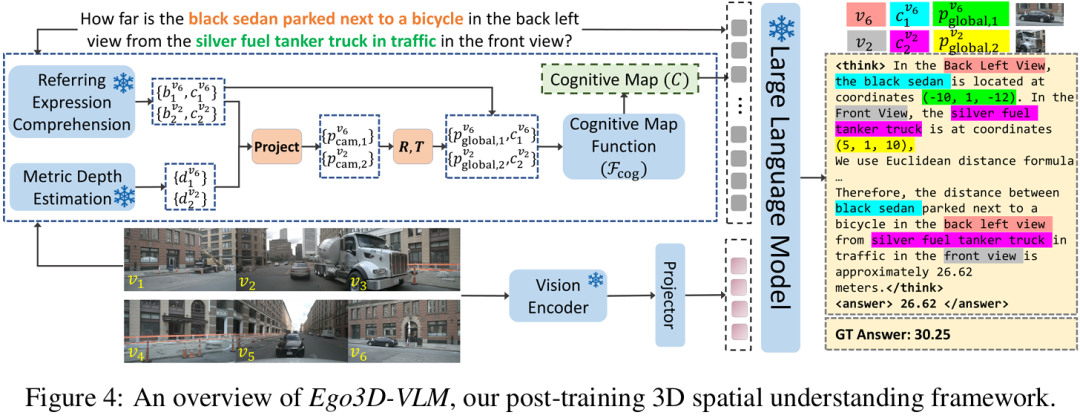
Ego3D-Bench
基于自车中心多视角场景的视觉语言模型空间推理研究
华为科技加拿大公司与华为云的研究团队提出了Ego3D-Bench基准和Ego3D-VLM后训练框架,显著提升了视觉语言模型在自我中心多视角场景中的三维空间推理能力,实现了多选题准确率平均提升12%和绝对距离估计RMSE平均提升56%的进展。
论文标题:Spatial Reasoning with Vision-Language Models in Ego-Centric Multi-View Scenes
论文链接:https://arxiv.org/pdf/2509.06266
主要贡献:
提出 Ego3D-Bench 基准:首个针对视觉语言模型(VLMs)的以自我为中心(ego-centric)多视图 3D 空间理解基准,基于 nuScenes、Waymo Open Dataset、Argoverse 1 三个户外动态数据集构建,包含 8600 + 高质量问答(QA)对,覆盖绝对距离测量、相对距离测量、定位、运动推理、行驶时间 5 类任务,填补了现有基准在 “真实具身智能体(如自动驾驶、机器人)多视图空间推理” 场景的空白。
提出 Ego3D-VLM 后训练框架:一种插件式(plug-and-play)后训练方案,通过构建 “文本认知地图(textual cognitive map)” 提升 VLMs 的 3D 空间推理能力。该框架先利用指代表达式理解(REC)模型和度量深度估计器获取目标 2D 位置与深度,再转换为全局 3D 坐标,最终生成以自我为中心的文本认知地图;无需重构点云或鸟瞰图(BEV),仅聚焦查询相关目标,兼顾效率与性能,可集成至任意现有 VLMs。
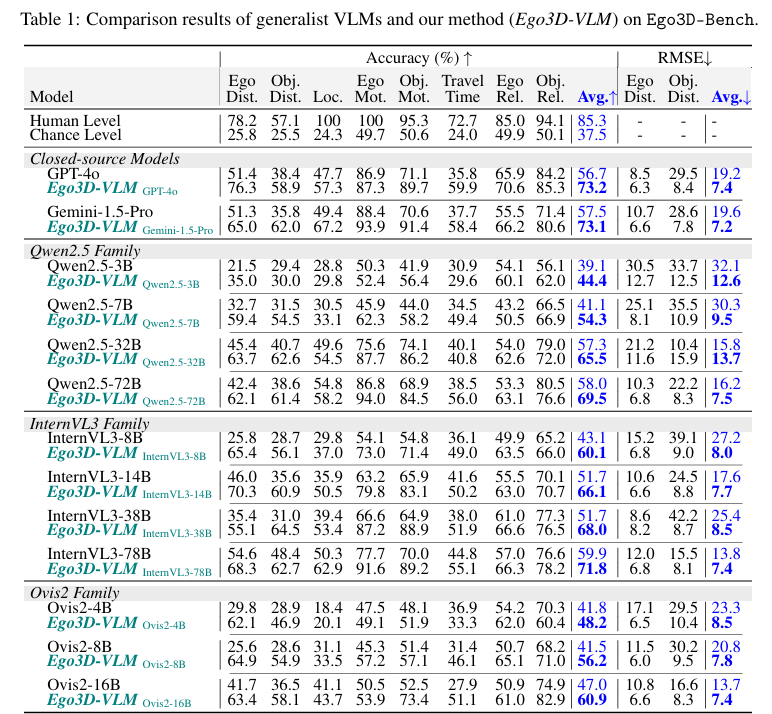
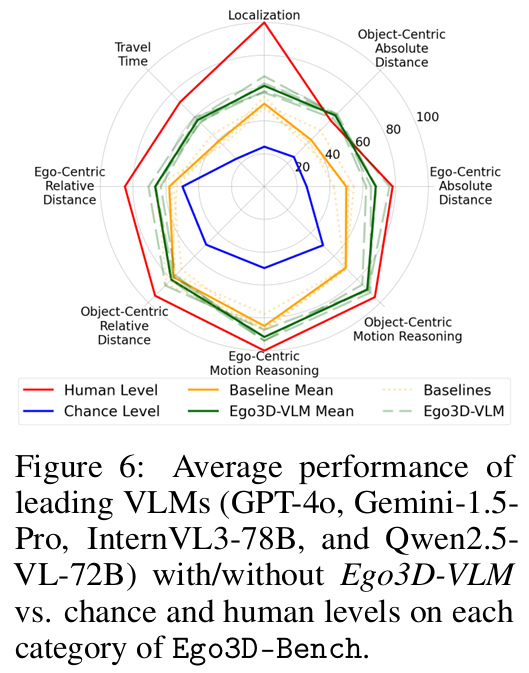
验证框架有效性:在 16 个 SOTA VLMs(含 GPT-4o、Gemini-1.5-Pro、InternVL3、Qwen2.5-VL 等)上开展实验,结果显示 Ego3D-VLM 平均提升多选项 QA 准确率 12%,绝对距离估计的均方根误差(RMSE)相对改善 56%;且在 All-Angle Bench、VSI-Bench 等其他多视图基准上仍具适应性,验证了泛化能力。
算法框架:
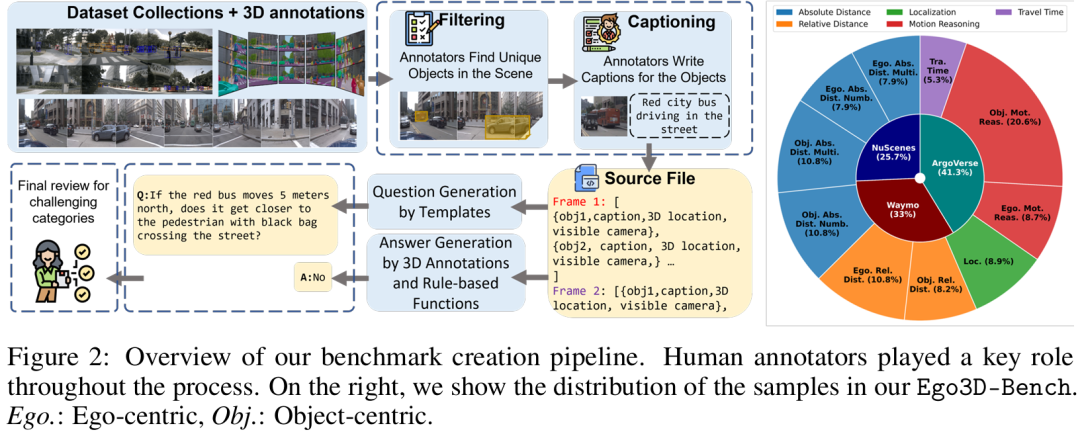
实验结果:
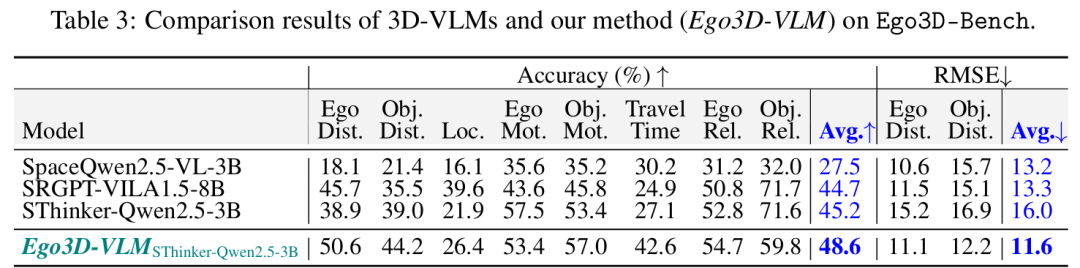
可视化:

















 5198
5198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









