





点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享复旦大学和上海创新研究院最新的工作 - VeteranAD!从“感知–规划”到“感知即规划“的端到端全新范式。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群加入,也欢迎添加小助理微信AIDriver005做进一步咨询
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Bozhou Zhang等
编辑 | 自动驾驶之心
端到端自动驾驶在近几年取得了显著进展,它将多个任务统一到一个框架中,为了避免多个阶段造成的信息损失。通过这种方式,端到端驾驶框架也构建了一个完全可微分的学习系统,能够实现面向规划的优化。这种设计使得其在 open-loop(开环) 和 closed-loop(闭环) 规划任务中都展现出了不错的表现。
主流的端到端自动驾驶方法通常采用顺序式范式:先执行感知,再执行规划,如图1(a)所示。常见的做法是引入 Transformer 架构,使整个流程保持可微分。然而,仅仅依靠可微分性并不足以充分发挥端到端规划优化的优势。毕竟,端到端自动驾驶的目标是让所有前置模块都能更好地为规划服务。
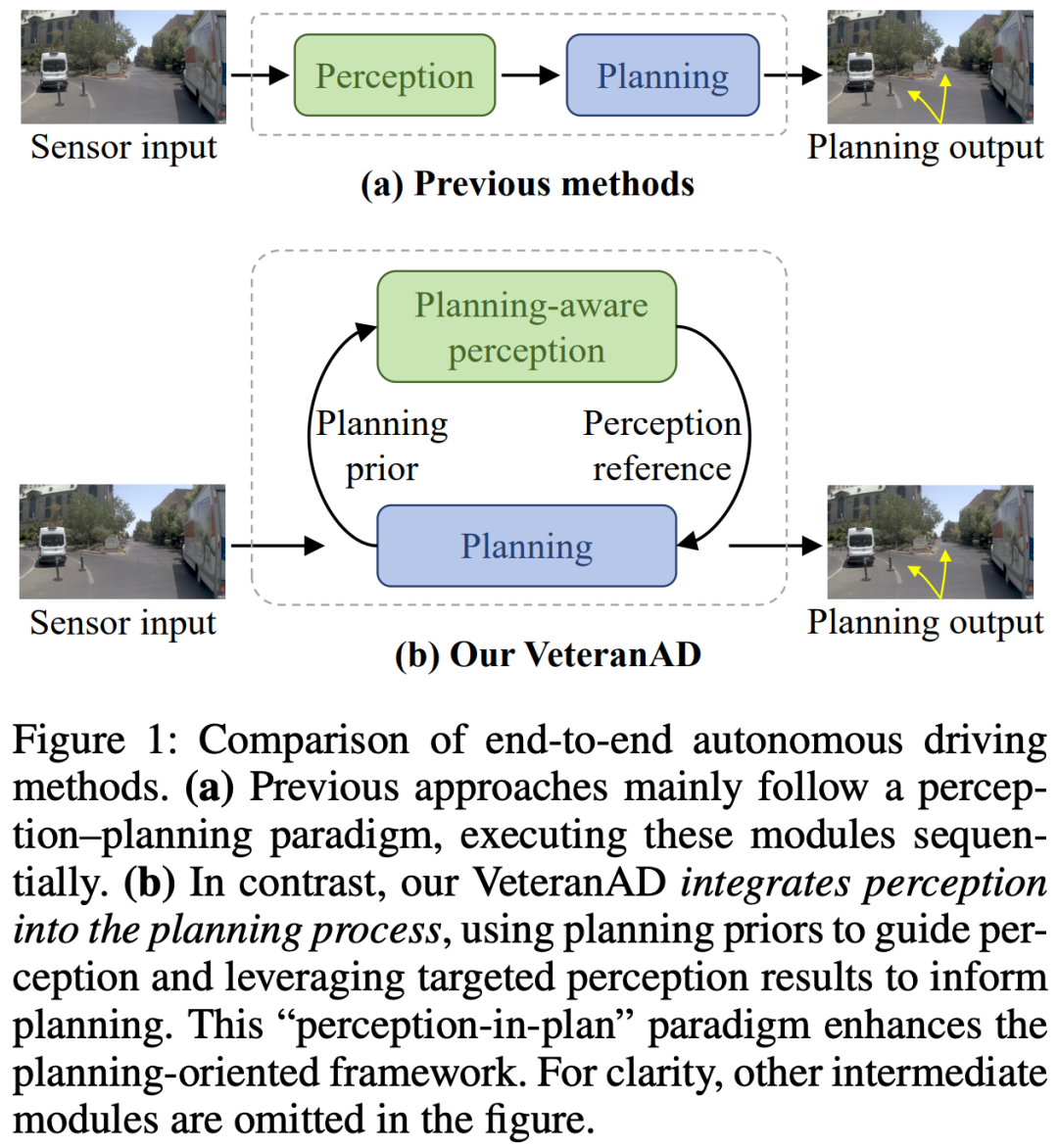
为了解决上述局限性,我们提出了一种 “perception-in-plan(感知融入规划)” 的新范式,它将感知过程直接嵌入到规划之中。这样,感知模块就能以更具针对性的方式运作,与规划需求保持一致。基于这一思路,我们设计了 VeteranAD 框架,如图1(b)所示。在该框架中,感知与规划紧密耦合。我们采用 多模态锚定轨迹(multi-mode anchored trajectories) 作为规划先验,用来引导感知模块在预测轨迹上感知关键交通元素,从而实现更全面、更有针对性的感知。
为了让感知能够真正服务于规划,我们进一步引入了一种自回归(autoregressive)策略:逐步生成未来轨迹。在每一个时间步,模型都会在规划先验的指引下,聚焦于相关区域进行针对性感知,并输出该时间步对应的规划结果。基于这一范式,我们设计了两个核心模块:
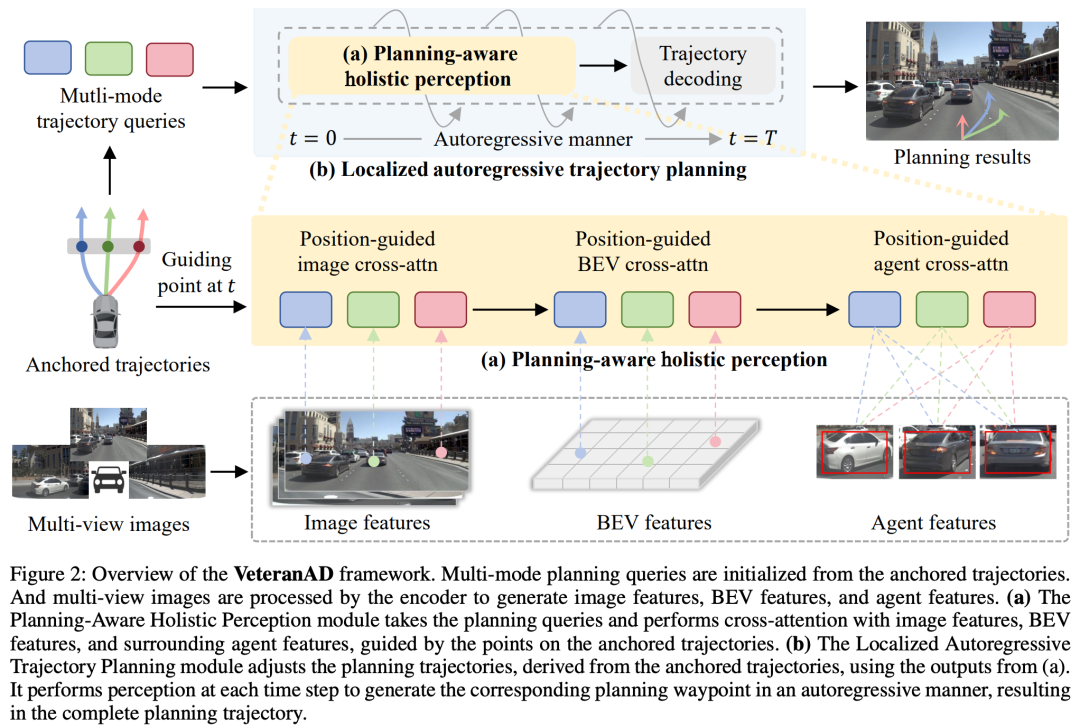
规划感知耦合的整体感知模块(Planning-Aware Holistic Perception):在图像特征、鸟瞰图(BEV)特征以及周围交通体特征三个维度上进行交互,从而实现对车辆、车道和障碍物等交通元素的全面理解。
局部自回归轨迹规划模块(Localized Autoregressive Trajectory Planning):以自回归的方式解码未来轨迹:从近到远逐步调整锚定轨迹,并结合感知结果不断优化,确保规划既具备上下文感知能力,又能逐步细化。
通过以上设计,VeteranAD 利用轨迹先验来实现聚焦式感知和渐进式规划,从而在端到端规划任务中表现出强大的性能。
总结来说,本文的主要贡献如下:
提出了 VeteranAD 框架,首次将 “perception-in-plan” 范式应用于端到端自动驾驶,将感知深度融入到规划过程中;
设计了两个关键模块:Planning-Aware Holistic Perception 和 Localized Autoregressive Trajectory Planning,实现感知与规划的紧密耦合,最大化发挥端到端优化的优势;
在 NAVSIM 和 Bench2Drive 两个数据集上的大量实验表明,VeteranAD 均取得了当前最优的性能表现。
相关工作回顾
端到端自动驾驶
在自动驾驶的早期阶段,基于规则的方法采用了模块化设计,将系统划分为独立的组件——感知、预测、规划和控制——并通过预定义规则相互连接。虽然这种架构具有可解释性,但它会受到误差传播和有限场景覆盖范围的影响。端到端规划方法逐渐用基于深度学习的子网络替代了诸如感知和规划等单独模块,同时保留必要的基于规则的约束。这种范式因其能够将感知、预测和规划统一到一个框架中,从而去掉手工设计的中间表示而受到关注。早期的工作通常会绕过感知和运动预测等中间任务。ST-P3 是第一个在基于环视相机的框架中引入显式中间表示的工作。UniAD 进一步通过基于 transformer 的 query 交互统一了感知、预测和规划,并在 nuScenes 基准上取得了很强的性能。最近的进展探索了多样化的表示方式和学习范式。VAD 提出了向量化场景表示,而 VADv2 引入了带有 4K 轨迹词表和冲突感知损失的概率化规划,在 CARLA Town05 上实现了最先进的闭环性能。SparseDrive 通过稀疏场景表示和并行运动规划器提升了效率。GenAD 采用生成式框架,将运动预测和规划统一起来,使用基于实例的场景表示和通过变分自编码器进行的结构化潜变量建模。最近,随着更具挑战性的真实世界基准和基于 CARLA 的闭环仿真基准的引入,越来越多的研究探索了端到端自动驾驶的不同方法,例如扩散策略、视觉语言模型、纯 transformer 架构、强化学习、闭环仿真、视觉-语言-动作模型、双系统、专家混合、流匹配、测试时训练、弥合开环训练与闭环部署之间的差距、轨迹选择、迭代规划和世界模型。这些现有方法主要遵循 “感知–规划” 范式,旨在通过分别增强感知和规划能力来提升性能。相比之下,我们提出的 VeteranAD 采用了 perception-in-plan” 范式,将感知直接整合到规划过程中,从而实现更有效的、面向规划的优化。
闭环与开环基准
闭环和开环基准是两种用于评估自动驾驶系统的方式。闭环评估会模拟完整的反馈回路——从传感器输入到控制执行——使用的工具包括 nuPlan、Waymax、CARLA、Bench2Drive 和 MetaDrive。这些模拟器可以用于衡量驾驶指标,例如碰撞率和乘坐舒适度。然而,模拟逼真的交通行为和传感器数据仍然是一个挑战。基于图形的渲染会引入域间差距,而基于数据驱动的传感器模拟则存在视觉质量有限的问题。开环评估则是在离线数据集(如 nuScenes)上测试轨迹预测,不与环境进行交互。
VeteranAD算法详解
一些先验知识
任务表述
端到端自动驾驶以传感器数据(如视觉和激光雷达)作为输入,并生成未来的规划轨迹作为输出。规划任务通常涉及生成多模态轨迹,以表示多种可能的未来行驶方案。辅助任务,例如检测、地图分割,以及对周围交通参与者的运动预测,也会被整合到端到端模型中,以帮助模型更好地学习场景特征,从而获得安全的规划结果。
框架概览
VeteranAD 框架如图2所示。它由三个主要部分组成:图像编码器(image encoder)、规划感知整体感知模块(Planning-Aware Holistic Perception) 和 局部自回归轨迹规划模块(Localized Autoregressive Trajectory Planning)。
首先,图像编码器从多视角图像中提取特征,生成图像特征、BEV 特征以及周围交通体特征。接着,多模态轨迹查询由锚定轨迹(anchored trajectories)初始化。规划感知整体感知模块会在轨迹查询与图像特征、BEV 特征和交通体特征之间进行位置引导的交互。随后,局部自回归轨迹规划模块以自回归的方式运作,在每个时间步执行感知并调整锚定轨迹点,最终生成完整的规划输出。
图像编码
给定多视角图像 ,其中 表示视觉视角数量,图像编码器首先提取多视角图像特征,记为 。然后,使用 LSS 方法从图像特征中生成鸟瞰图特征 。接着,通过一个简单的多层感知机 (MLP) 解码器将 BEV 特征解码为 BEV 分割图,并使用真实标签分割图进行监督。周围交通体特征 被初始化后,会通过 Transformer 块与 BEV 特征交互。最后,一个简单的 MLP 解码器将交通体特征解码为 bounding box,并通过真实的交通体 bounding box 进行监督。过程如下:
在得到这些特征之后,多模态轨迹查询
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









