




点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享复旦大学、萨里大学、帝国理工学院最新的工作!LMAD框架:多机制协同显著提升自动驾驶视觉语言模型推理性能!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群加入,也欢迎添加小助理微信AIDriver005
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Nan Song等
编辑 | 自动驾驶之心
概述
随着自动驾驶技术的快速发展,场景理解与行为可解释性成为核心研究方向。大型视觉语言模型(VLMs)在连接视觉与语言信息、解释驾驶行为方面展现出潜力,但现有方法多通过微调VLMs处理车载多视图图像和场景推理文本,存在整体场景识别不足、空间感知薄弱等问题,难以应对复杂驾驶场景。
为此,本文提出LMAD框架一种专为自动驾驶设计的视觉语言框架。其借鉴现代端到端驾驶范式,通过引入初步场景交互(Preliminary Interaction,PI)机制和任务专用专家适配器,增强VLMs与自动驾驶场景的对齐性,同时兼容现有VLMs并无缝集成规划导向的驾驶系统。在DriveLM和nuScenes-QA数据集上的实验表明,LMAD显著提升了现有VLMs在驾驶推理任务中的性能,树立了可解释自动驾驶的新标准。
核心挑战与创新
现有方法的局限性
现有基于VLMs的自动驾驶方法存在两点关键缺陷:
场景理解碎片化:依赖驾驶系统的中间结果或简单视觉表征,难以捕捉交通元素间的关系,无法形成整体场景认知(figure 1a)。
空间与运动感知薄弱:在定位和运动估计上表现不足,推理过程中易积累误差,导致驾驶任务性能不佳。
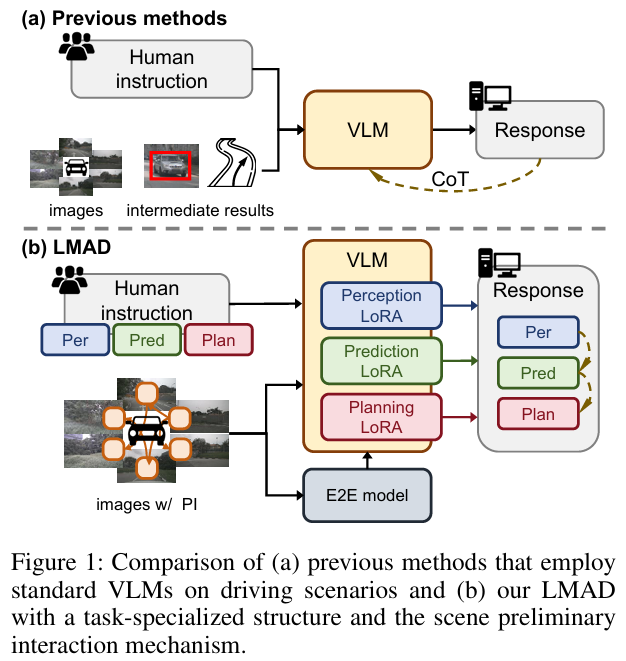
LMAD的创新设计
针对上述问题,LMAD的核心创新包括:
初步场景交互(PI)机制:建模交通参与者的初步关系,降低VLMs的学习复杂度。
任务专用专家结构:通过并行LoRA(P-LoRA)模块,使VLMs专注于感知、预测、规划等特定任务,获取任务专属知识。
端到端系统集成:融合端到端驾驶系统的先验知识,补充VLMs的空间和运动信息,增强推理能力(figure 1b)。
方法细节
整体框架
LMAD整合端到端驾驶流水线与视觉语言模型,由三部分构成:
视觉语言模型:含视觉编码器(提取图像tokens)、分词器(编码文本tokens)、语言解码器(生成响应)。
PI编码器:处理多视图图像,建模场景关系。
并行LoRA模块:整合任务专用知识,适配不同驾驶任务(figure 2)。
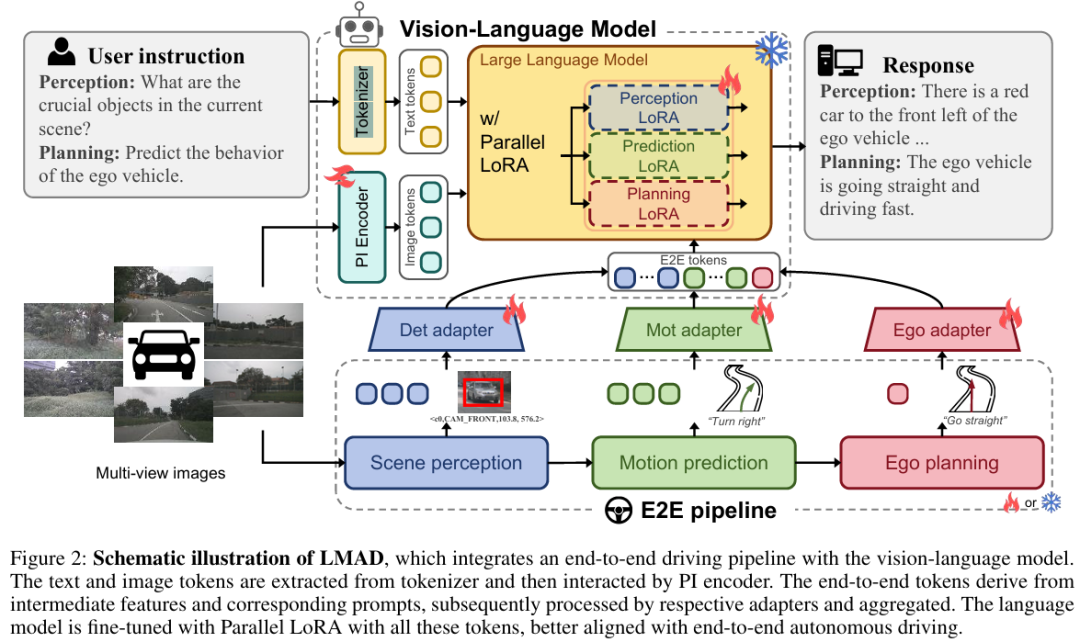
关键模块设计
1. 初步场景交互(PI)编码器
多视图图像独立处理易产生冗余跨视图tokens,增加空间关系学习负担。PI编码器通过解耦查询和交替注意力机制解决这一问题(figure 3a):
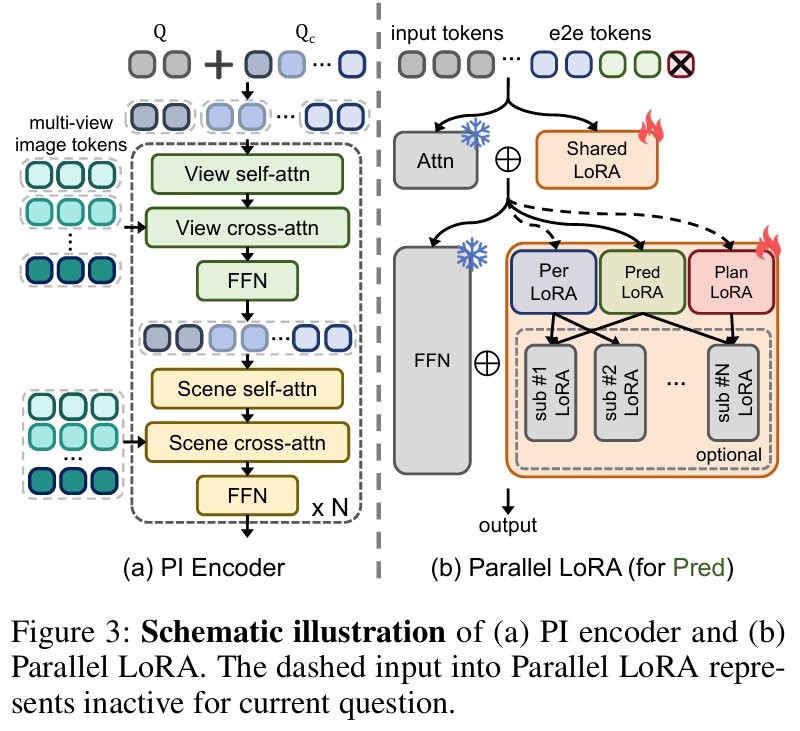
解耦查询:包含 个通用视觉查询 (捕捉图像上下文)和 个相机查询 (标识相机视角,辅助空间关系构建)。
交替注意力:奇数块中,查询按相机分组,仅组内及与对应图像特征交互,保留单视图信息;偶数块中,所有查询联合进行场景级自注意力和交叉注意力,整合多视图信息。
2. 并行LoRA(P-LoRA)微调
为使VLMs适配多样化驾驶任务,P-LoRA在FFN块中替换传统LoRA为多个并行分支,每个分支对应感知、预测或规划任务(figure 3b):
注意力块中的LoRA保持共享,保留通用驾驶知识。
推理时结合Chain-of-Thought(CoT)技术,按端到端方法逐步输出结果。
与端到端驾驶系统的集成
端到端驾驶系统的感知、预测、规划特征可为VLMs提供丰富的位置和运动先验,具体集成方式如下:
特征提取:收集感知( )、预测( )、规划( )的输出特征,结合数值和文本提示增强可理解性。
其中 表示 或 , 为语言模型输入嵌入编码的原始文本特征, 为用于聚合文本信息的可学习查询。
数值提示:通过MLP将预测轨迹 和 ego 规划轨迹 投影为高维特征 和 。
文本提示:基于转向和速度变化生成描述(如“直行,加速”),经多头注意力(MHA)生成文本特征 和 。 公式表示为:
特征整合:通过适配器处理三类特征并对齐语言上下文,拼接为端到端tokens :
其中 为语言模型特征维度, ( 为选定目标数量)。
训练策略
单分支微调:冻结端到端驾驶分支,仅微调语言分支,采用自回归交叉熵损失 。
联合训练:激活语言分支到端到端分支的梯度流,同时优化文本生成和端到端任务,损失函数为:其中 为平衡因子, 包含检测、运动预测和规划损失(按端到端模型默认权重聚合)。
实验验证
实验设置
数据集:采用DriveLM(377,956个QA对,涵盖感知到规划的渐进式任务)和nuScenes-QA(约460k个QA对,聚焦感知任务)。
基线模型:LLaMA-Adapter、LLaVA-1.5、InternVL2,端到端框架采用VAD-base。
训练细节:使用AdamW优化器(权重衰减0.01),余弦学习率调度(预热比0.03),8张A6000 GPU上以 batch size 16训练2个epoch。
主要结果
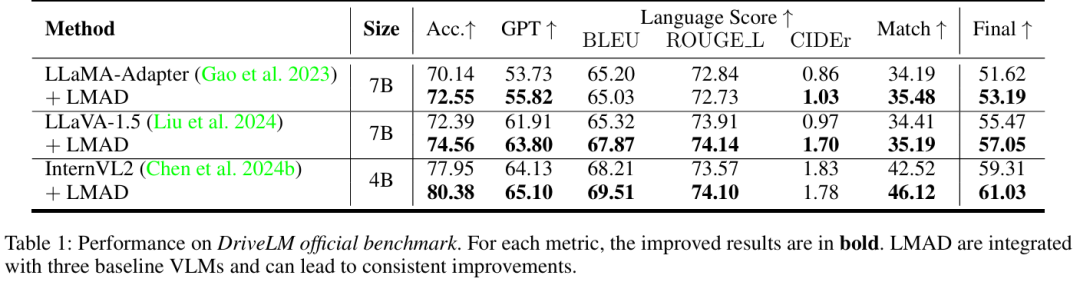
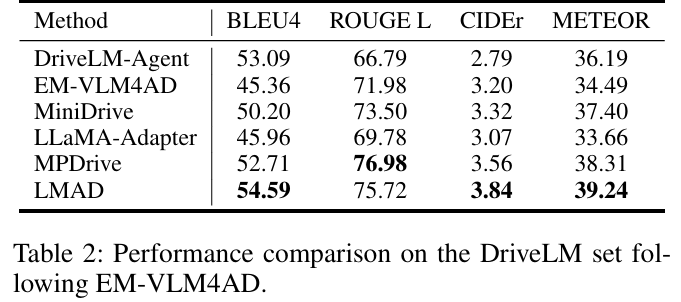
DriveLM基准测试:LMAD显著提升所有基线VLMs的性能。例如,LLaMA-Adapter的准确率提升3.44%,GPT得分提升3.89%;即使是强基线InternVL2,整体指标仍有改善(table 1)。与现有方法相比,LMAD在BLEU4、ROUGE L等指标上表现最优(table 2)。
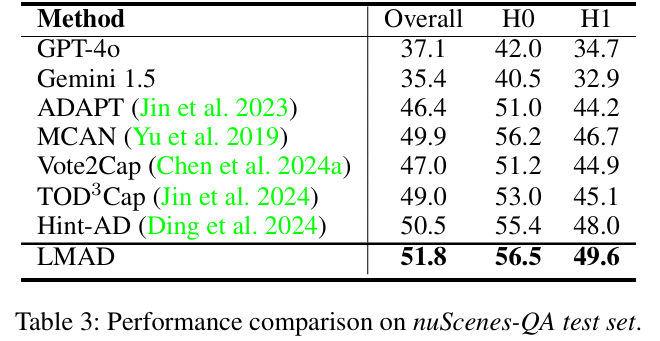
nuScenes-QA测试:在相同基线(LLaMA-Adapter)下,LMAD的整体准确率提升2.57%,H0(零跳推理)和H1(单跳推理)指标分别提升1.99%和3.75%(table 3)。
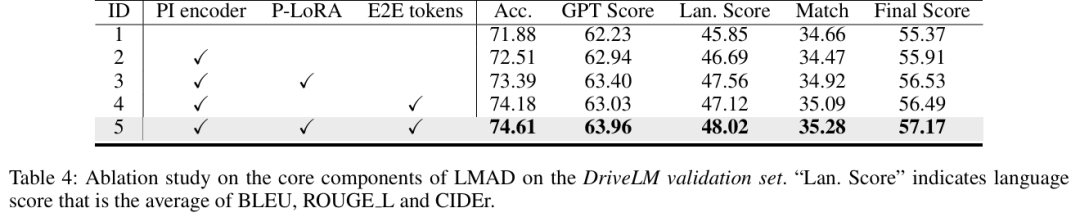
消融研究
组件有效性:PI编码器、P-LoRA和端到端tokens的协同作用显著提升性能,全组件配置(ID5)的最终得分最高(57.17)(table 4)。
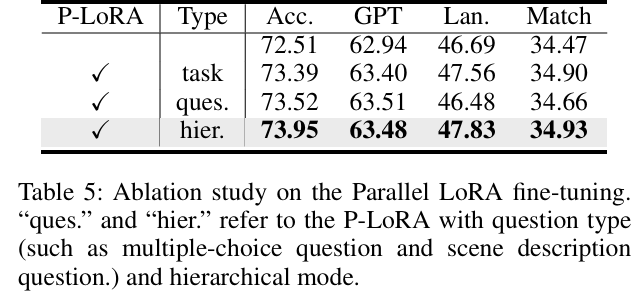
P-LoRA设计:任务导向的P-LoRA(感知、预测、规划分支)在各项指标上表现均衡,优于问题导向和分层模式(table 5)。
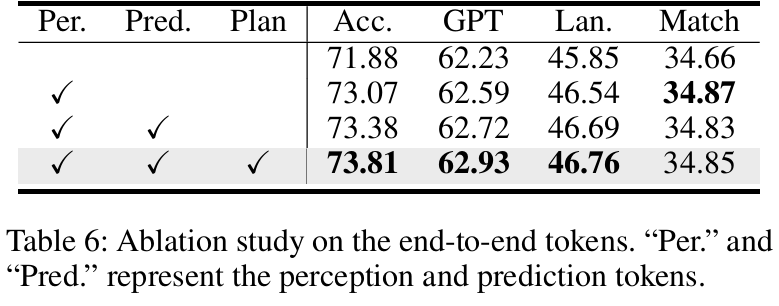
端到端tokens作用:感知tokens对行为解释最关键,加入预测和规划tokens后,准确性和交互关系建模进一步提升(table 6)。
定性分析
感知任务:借助规划结果中的位置先验,LMAD能准确识别多数关键目标,但对“禁止进入”等不明显标识仍有困难。
预测任务:聚焦对ego行为影响大的目标(如交通标志),即使预测目标与真值不同,仍能合理影响后续规划。
规划任务:结合历史上下文和端到端结果,输出符合当前环境的驾驶行为(figure 4)。

参考
[1]LMAD: Integrated End-to-End Vision-Language Model for Explainable Autonomous Driving
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频学习官网:www.zdjszx.com

















 4503
4503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









