



点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型技术交流群
本文只做学术分享,如有侵权,联系删文
写在前面
当RLHF“卷入”计算机视觉,一场新的范式革命开始了。
在大语言模型(LLM)的江湖里,强化学习(RL),特别是带有人类反馈的强化学习(RLHF),早已不是什么新鲜词。正是它,如同一位内力深厚的宗师,为 GPT、Qwen、DeepSeek 等模型注入了“灵魂”,使其回答能够如此贴合人类的思维与价值观。这场由 RL 主导的革命,彻底改变了我们与AI的交互方式。
然而,当所有人都以为强化学习的舞台仅限于文字的方寸之间时,一股同样的浪潮,正以迅雷不及掩耳之势,“卷”向了另一个更为广阔的领域——计算机视觉(CV)。
想象一下,如果AI不仅能“看懂”世界,更能根据你的主观偏好(比如“我想要一张更有意境的山水画”)去创造和优化视觉内容;如果机器人不仅能识别物体,更能主动地、序列化地与环境交互以完成复杂任务(比如“帮我整理一下这个凌乱的房间”)。
这一切,正是强化学习与计算机视觉深度融合后,正在发生的新故事。它不再满足于让AI做一个被动的观察者,而是要将其训练成一个能够主动决策、与环境交互、并最终与人类意图对齐的“行动派”。
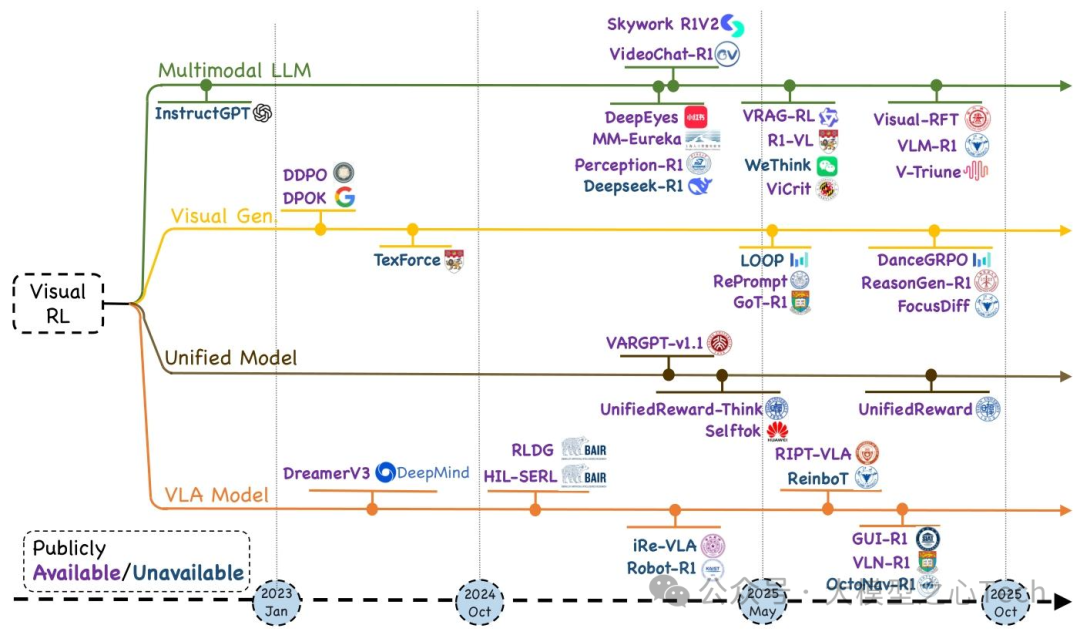
最近,一篇由新加坡国立大学、浙江大学、香港中文大学等机构研究者联合撰写的长篇综述 《Reinforcement Learning in Vision: A Survey》 ,旨在梳理强化学习(RL)与视觉智能交叉领域的最新进展、核心方法及未来方向。综述涵盖200余篇代表性研究,以“理论基础-领域分类-评估体系-挑战展望”为逻辑框架,为研究者和从业者提供了该快速发展领域的完整图谱。

以下从核心内容展开详细总结:
一、研究背景与综述定位
1.1 领域兴起动因
视觉强化学习的爆发源于强化学习在大语言模型(LLM)中的成功迁移。RL通过“人类反馈强化学习(RLHF)”“DeepSeek-R1”等范式,显著提升了LLM的人类偏好对齐与复杂推理能力(如InstructGPT)。受此启发,研究者将RL拓展至多模态大模型,涵盖:
视觉-语言模型(VLM,如Gemini 2.5):用RL对齐视觉-文本推理,提升语义连贯性;
视觉-语言-动作模型(VLA,如GUI自动化、机器人操纵模型):用RL优化序列决策,改善任务性能;
扩散型视觉生成模型(如文本-图像/视频生成):用RL提升生成质量与prompt对齐度;
统一多模态框架(如UniRL、Emu3):用RL实现“理解-生成”跨任务泛化。
1.2 核心挑战与综述目标
当前领域面临三大核心挑战:
①复杂奖励信号下的策略优化稳定性;
②高维、多样视觉输入的高效处理;
③长周期决策场景下可扩展奖励函数设计。
综述的核心目标是:
①形式化视觉RL问题,梳理策略优化从RLHF到可验证奖励、从PPO到GRPO的演进;
②将200+研究分为“多模态LLM、视觉生成、统一模型、VLA模型”四大支柱;
③分析各领域的算法设计、奖励工程与基准进展;④总结评估协议与开放挑战。
本文首发于大模型之心Tech知识星球,硬核资料在星球置顶:加入后可以获取大模型视频课程、代码学习资料及各细分领域学习路线~

二、视觉强化学习的理论基础
综述首先夯实视觉RL的理论框架,包括问题形式化、对齐范式与策略优化算法,为后续领域分析奠定基础。
2.1 问题形式化:马尔可夫决策过程(MDP)建模
研究者将文本/图像/视频生成转化为“episodic MDP”,核心符号与定义如下(表1总结关键符号):
状态(s_t):初始状态s₀为用户prompt(p),t时刻状态为“prompt+已生成动作”,即s_t=(p, a₁,...,a_{t-1});
动作(a_t): autoregressively从策略采样的token(文本)、像素块(图像)或扩散噪声(生成模型);
轨迹(y):完整动作序列(a₁,...,a_T),策略π_θ(a_t|s_t)定义动作采样概率;
奖励与参考模型:人类偏好蒸馏为序列级奖励模型R_φ(p,y),固定参考模型π_ref(如监督微调模型π_SFT)用于KL正则,避免策略漂移。
这一建模方式统一了文本与视觉生成的RL框架,使LLM的RL方法可迁移至视觉领域。
2.2 三大核心对齐范式:从主观偏好到客观验证
对齐范式的核心是“如何用反馈信号引导策略优化”,综述提出三类主流范式:
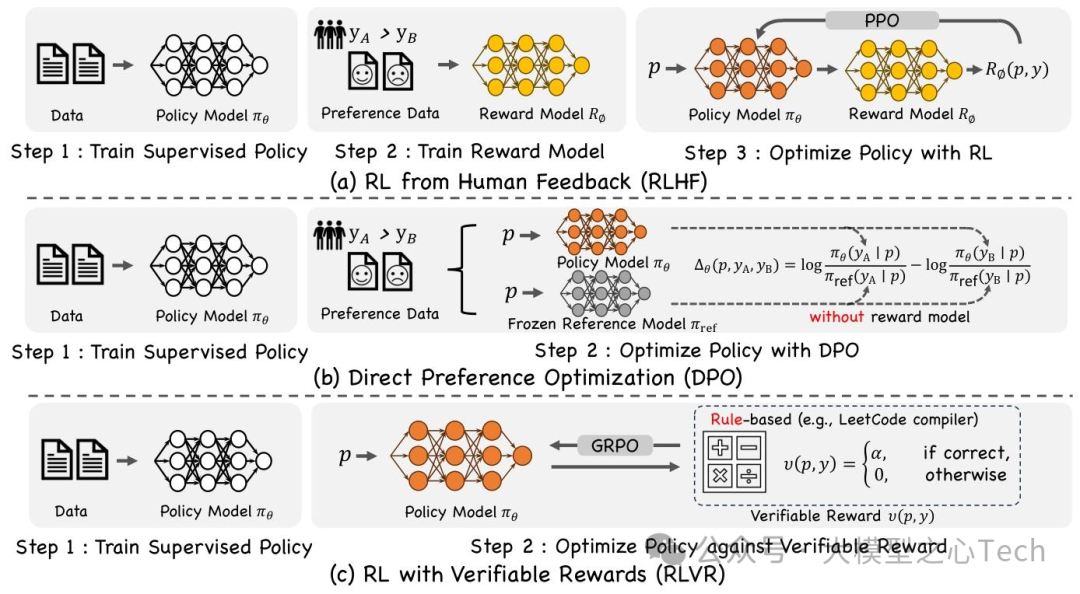
(1)基于人类反馈的强化学习(RLHF)
RLHF是视觉RL中最成熟的范式,采用三阶段流程(图2a):
阶段1:监督策略预训练:用标注数据训练初始策略π_SFT;
阶段2:奖励模型训练:收集人类偏好数据(p, y_A, y_B)(y_A为偏好续贯),通过“Bradley-Terry likelihood”训练 scalar奖励模型R_φ,目标函数为:其中σ为sigmoid函数,R_φ输出反映人类偏好的稠密奖励;
阶段3:PPO策略优化:最大化“奖励-RL惩罚+预训练对数似然”,目标函数为:其中β控制KL惩罚强度(防止策略偏离π_SFT),γ平衡预训练性能保留。
视觉领域中,RLHF的典型应用包括:ImageReward(文本-图像生成的人类偏好奖励)、HPS(人类美学分数)引导扩散模型优化,显著提升生成质量与prompt对齐度。
(2)直接偏好优化(DPO)
DPO针对RLHF“奖励模型训练繁琐”的痛点,移除中间奖励模型,直接用偏好数据优化策略(图2b):
输入数据:与RLHF一致的偏好三元组(p, y_A, y_B)(y_A偏好于y_B);
核心目标:优化“策略与参考模型π_ref的对数优势差”,目标函数为:其中Δ_θ为“策略对数比-参考模型对数比”,即Δ_θ=log(π_θ(y_A|p)/π_ref(y_A|p)) - log(π_θ(y_B|p)/π_ref(y_B|p)),β为温度超参;
优势:无需奖励模型、价值网络或重要性采样,仅用监督梯度训练,效率更高(如DiffusionDPO用于图像生成对齐)。
(3)带可验证奖励的强化学习(RLVR)
RLVR用确定性、可编程验证的奖励替代主观人类偏好,解决RLHF数据成本高、DPO依赖偏好数据的问题(图2c):
可验证奖励信号:如代码测试通过率(LeetCode编译器)、图像分割IoU≥0.9、数学答案精确匹配,奖励函数r(p,y)=v(p,y)∈{0,1}(1为“通过验证”);
训练流程:两阶段——①监督预训练π_SFT;②用GRPO/PPO优化策略,结合少量SFT更新稳定训练(如DeepSeekMath用数学答案精确匹配奖励,GRPO训练);
优势:无主观偏差、数据成本低,适用于“结果可量化验证”的任务(如3D生成的几何一致性、GUI自动化的动作正确性)。
2.3 两大策略优化算法:PPO与GRPO
策略优化算法是“如何根据奖励更新策略”的核心,综述重点分析两种适用于视觉任务的算法:
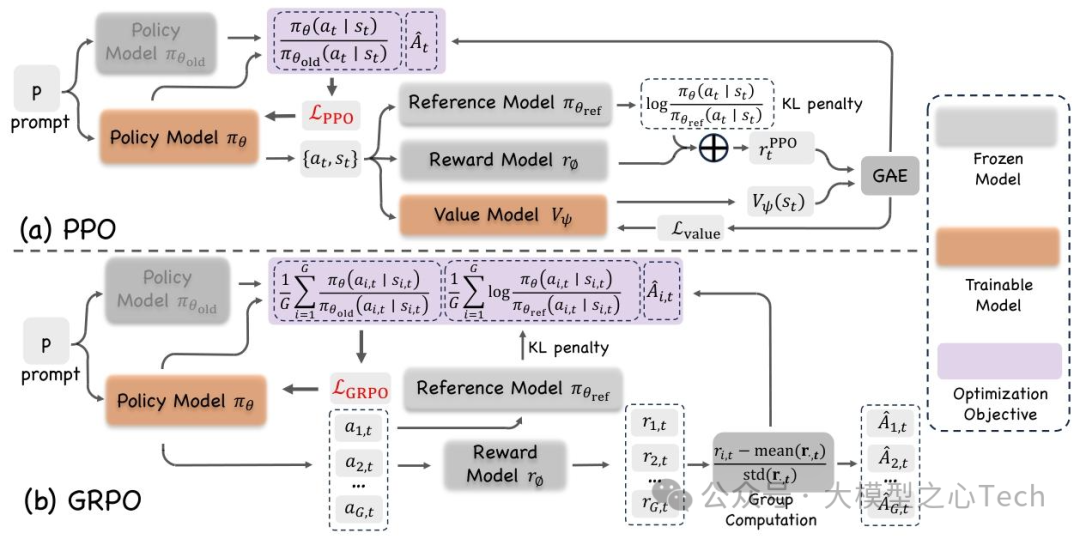
(1)近邻策略优化(PPO)
PPO是RLHF的默认优化算法,属于一阶信任域方法,核心是“限制策略更新幅度以保证稳定”(图3a):
关键组件:
① 重要性采样比ρ_t(θ)=π_θ(a_t|s_t)/π_θ_old(a_t|s_t):将行为策略(π_θ_old)的梯度权重调整为目标策略(π_θ);
② 价值网络V_ψ(s_t):预测状态s_t的未来回报,用于计算GAE(广义优势估计)优势值Â_t=GAE(r_t^{PPO}, V_ψ);
③ KL正则:奖励中加入KL项r_t^{PPO}=r_φ(s_t,a_t) - β log(π_θ/π_ref),防止策略偏离π_ref;目标函数(裁剪 surrogate):其中ε控制信任域宽度(通常0.1~0.2)。
(2)组相对策略优化(GRPO)
GRPO针对视觉任务“高维输入导致内存紧张”的问题,移除PPO的价值网络,用“组相对基线”降低方差(图3b):
核心设计:
① 组采样:对每个prompt p,采样G个续贯(a₁,...,a_G),形成组O={a_i}{i=1}^G;
② 组相对优势:奖励标准化为Â{i,t}=(r_{i,t}-mean(r_{·,t}))/std(r_{·,t}),无需价值网络;
③ prompt级KL惩罚:单独计算prompt层面的KL估计D_KL(p)(token平均KL),而非融入奖励(公式13);目标函数:
优势:内存占用减半(无critic)、超参更少,适用于视频生成、3D生成等内存密集型任务(如DanceGRPO用于视频时序一致性优化)。
三、视觉强化学习的四大核心应用领域
综述将视觉RL研究分为“多模态LLM、视觉生成、统一模型、VLA模型”四大支柱,每个领域下细分任务并分析代表性工作。
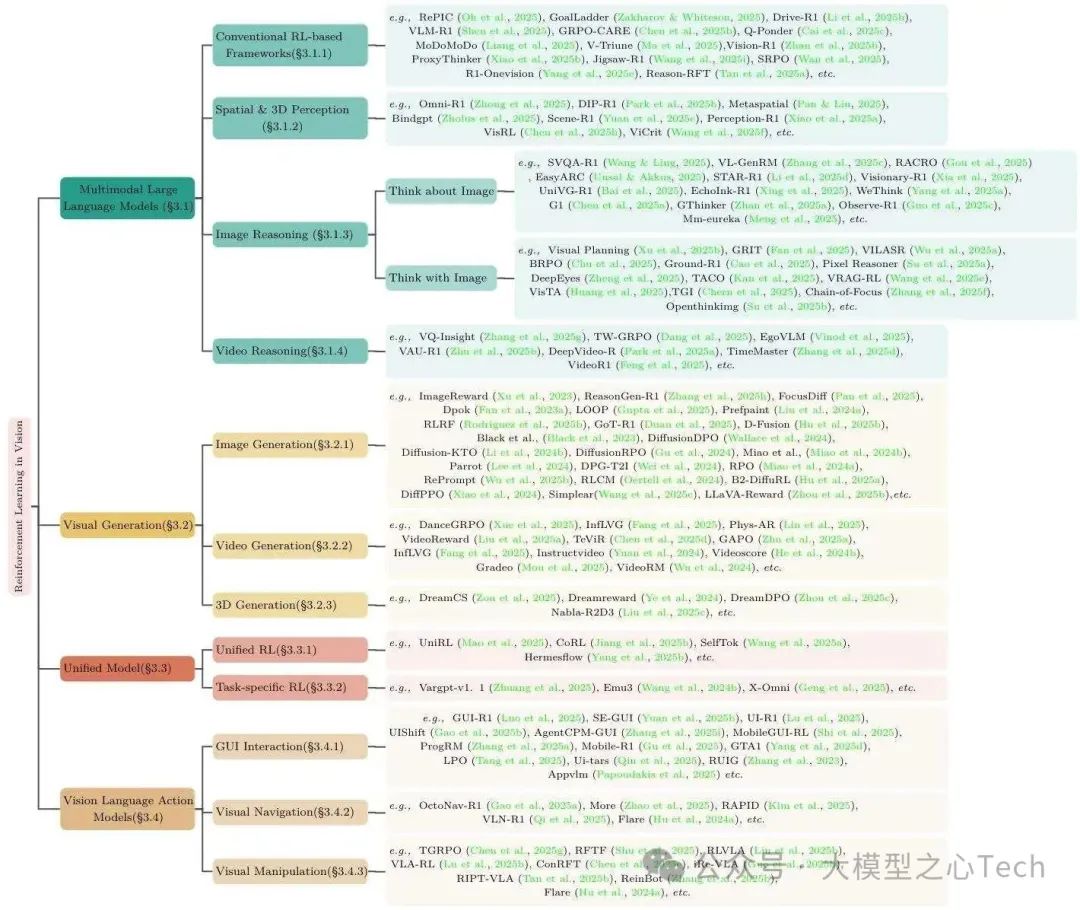
3.1 多模态大语言模型(MLLM)
MLLM的RL目标是“对齐视觉-语言推理与人类需求”,分四类研究方向:
(1)常规RL驱动型MLLM
这类模型用可验证奖励优化VLM骨干,不涉及复杂链式推理:
代表性工作:
① RePIC(Oh et al., 2025)、GoalLadder(Zakharov & Whiteson, 2025):用精确匹配、IoU等可验证奖励,GRPO优化,提升零样本鲁棒性;
② GRPO-CARE(Chen et al., 2025b):引入“一致性感知组归一化”,降低奖励方差;
③ Q-Ponder(Cai et al., 2025c):加入“思考控制器”,动态调整推理步数;
④ MoDoMoDo(Liang et al., 2025):多领域混合优化,预测奖励分布并选择最优训练课程。
(2)空间与3D感知
聚焦“用RL提升MLLM的空间理解能力”,分2D与3D任务:
2D感知:
① Omni-R1(Zhong et al., 2025):双系统(全局-局部)GRPO,用规则化指标(如情感识别准确率)验证预测;
② DIP-R1(Park et al., 2025b):“inspect→observe→act” step-wise循环,每步用IoU或计数奖励优化细粒度检测;
③ VisRL(Chen et al., 2025h):将“意图引导的焦点选择”建模为RL子策略,无需昂贵区域标注;3D感知:
① MetaSpatial(Pan & Liu, 2025):用渲染深度/IoU奖励,优化AR/VR场景生成的空间推理;
② Scene-R1(Yuan et al., 2025c):视频接地片段选择+两阶段接地策略,无点云标注学习3D场景结构;
③ BindGPT(Zholus et al., 2025):将原子放置视为序列动作,用结合亲和力估计作为奖励,实现3D分子设计。
(3)图像推理
分“基于图像思考(Think about Image)”与“用图像思考(Think with Image)”两类:
Think about Image:仅用语言描述图像观察,不修改视觉内容:
① SVQA-R1(Wang & Ling, 2025)、STAR-R1(Li et al., 2025d):用视图一致性奖励优化空间VQA;
② WeThink(Yang et al., 2025a)、GThinker(Zhan et al., 2025a):课程学习逐步提升任务复杂度,培养结构化推理;
③ EchoInk-R1(Xing et al., 2025):融入音视频同步性奖励,GRPO优化多模态推理;Think with Image:将图像作为“外部工作空间”,生成/编辑视觉标记辅助推理:
① GRIT(Fan et al., 2025):将边界框token与语言交织,GRPO优化“答案正确性+框精度”;
② Ground-R1(Cao et al., 2025):两阶段流程——先通过IoU奖励高亮证据区域,再进行语言推理;
③ Pixel Reasoner(Su et al., 2025a):动作空间加入“裁剪、擦除、绘制”原语,用好奇心驱动奖励平衡探索;
④ DeepEyes(Zheng et al., 2025):端到端RL自发诱导“视觉思考行为”,无需监督启发。
(4)视频推理
针对“时序动态理解”,RL用于对齐文本推理与视频证据:
VQ-Insight(Zhang et al., 2025g):分层奖励设计+自一致性投票,优化长视频QA;
TW-GRPO(Dang et al., 2025):token级信用分配+GRPO,提升文本推理与视频时序对齐;
EgoVLM(Vinod et al., 2025)、VAU-R1(Zhu et al., 2025b):第一视角视频推理,用视觉记忆与效用奖励优化;
TimeMaster(Zhang et al., 2025d):课程学习构建时序抽象,VideoR1(Feng et al., 2025):跨领域视频QA的可扩展RL框架。
3.2 视觉生成
视觉生成的RL核心是“平衡生成质量、prompt对齐与多样性”,分图像、视频、3D三类任务:
(1)图像生成
提出三大奖励范式(图5),覆盖不同优化目标:
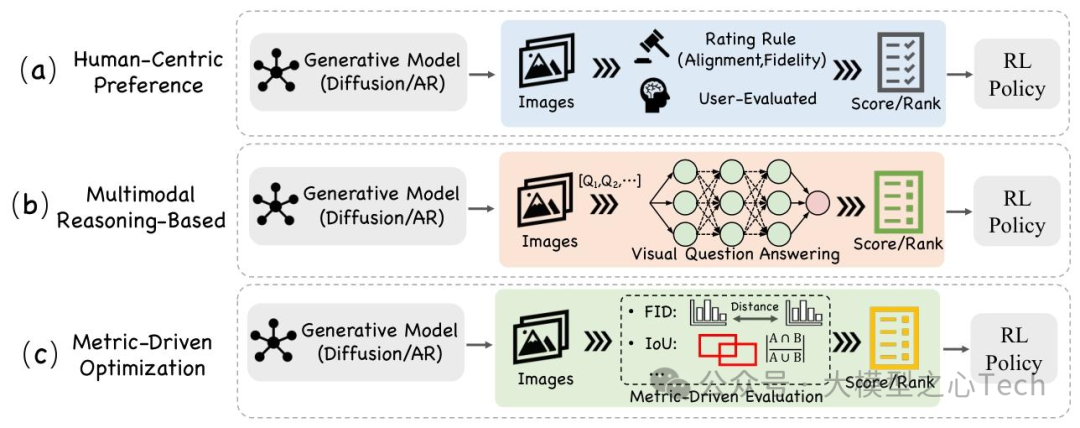
人类中心偏好优化:用人类美学/偏好分数引导,如ImageReward(Xu et al., 2023)、HPS(Wu et al., 2023b),DiffPPO(Xiao et al., 2024)用其优化扩散模型;
多模态推理对齐:用MLLM评估“生成图像与文本的推理一致性”,如UnifiedReward(Wang et al., 2025h)、PARM(Zhang et al., 2025e);
Metric驱动优化:最小化任务特定指标(如FID、IoU),如DDPO(Black et al., 2023)、Diffusion-KTO(Li et al., 2024b);
代表性工作:
① ReasonGen-R1(Zhang et al., 2025h):先生成文本计划,再用RL强化生成器的场景连贯性;
② PrefPaint(Liu et al., 2024a):多目标奖励(美学、多样性)优化图像修复;
③ B²-DiffuRL(Hu et al., 2025a): scarce参考图像下,用主题保真度奖励实现个性化生成。
(2)视频生成
核心挑战是“时序一致性、运动自然性”,RL解决方案包括:
偏好模型优化:InstructVideo(Yuan et al., 2024)复用图像评分器,PPO优化短片段;VideoReward(Liu et al., 2025a)训练专用偏好模型,评估序列平滑度与prompt对齐;
组相对优化:DanceGRPO(Xue et al., 2025)用组归一化回报,稳定长周期优化,提升视频美学分数;
领域特定奖励:GAPO(Zhu et al., 2025a)用“差距感知排序”优化动漫视频;Phys-AR(Lin et al., 2025)惩罚物理定律违反,生成合理运动轨迹。
(3)3D生成
RL需处理“ volumetric结构评估成本高”的问题,关键工作包括:
DreamCS(Zou et al., 2025):文本-网格生成为MDP,扩散模型提粗形状,策略优化顶点位置,奖励融合轮廓IoU、CLIP对齐与网格平滑度;
DreamReward(Ye et al., 2024):大规模3D人类偏好数据集,训练几何感知奖励模型,PPO优化文本-形状模型;
DreamDPO(Zhou et al., 2025c):将DPO扩展到NeRF与网格扩散模型,无需价值网络实现prompt保真度对齐;
Nabla-R2D3(Liu et al., 2025c):交互式3D场景编辑,用实时渲染视图与空间关系验证奖励,GRPO稳定训练。
3.3 统一模型
统一模型的RL目标是“用单一策略优化多视觉-语言任务”,分两类设计思路:
(1)统一RL(Unified RL)
用共享奖励与策略联合优化“理解+生成”任务,实现跨任务泛化:
UniRL(Mao et al., 2025):VLM骨干先指令微调,再用“文本正确性+CLIP对齐+美学质量”混合奖励,联合优化VQA、captioning与图像生成;
CoRL(Jiang et al., 2025b):GRPO步骤中交替“协同理解”与“协同生成”批次,提升跨任务一致性;
SelfTok(Wang et al., 2025a):将多模态动作离散为“自进化token集”,单RL头实现检索、接地与生成,参数增量少;
HermesFlow(Yang et al., 2025b): autoregressive文本模块+整流流图像解码器,跨任务奖励统一扩散与语言策略。
(2)任务特定RL(Task-specific RL)
仅对单一任务(通常是生成) 应用RL,保留其他任务的监督微调:
VARGPT-v1.1(Zhuang et al., 2025):VLM骨干支持理解与生成,但RL仅优化视觉生成(DPO);
Emu3(Wang et al., 2024b):RL仅用于图像生成分支(人类偏好对齐),captioning、VQA等理解任务用SFT。
3.4 视觉-语言-动作模型(VLA)
VLA模型的RL目标是“实现‘感知-决策-动作’闭环”,覆盖GUI自动化、视觉导航、视觉操纵三类任务:
(1)GUI自动化
RL用于“屏幕理解与动作预测”,分桌面与移动场景:
桌面/网页GUI:
① GUI-R1(Luo et al., 2025):R1规则集将“点击成功、文本输入有效”映射为稠密奖励;
② UI-R1(Lu et al., 2025):GRPO+动作特定KL项,稳定长周期计划;
③ UIShift(Gao et al., 2025b):逆动力学目标从无标注GUI对学习动作,RL精炼;移动GUI:
① AgentCPM-GUI(Zhang et al., 2025i):压缩动作空间,GRPO微调适配移动设备;
② MobileGUI-RL(Shi et al., 2025):在线RL+任务级奖励,解决内存有限下的探索问题;
③ GTA1(Yang et al., 2025d):采样多动作候选, judge模型选择最优,提升成功率。
(2)视觉导航
RL用于“具身智能的长周期导航决策”:
OctoNav-R1(Gao et al., 2025a):“思考再行动”VLA pipeline,将第一视角帧转化为低阶动作;
VLN-R1(Qi et al., 2025):端到端导航器,时间衰减奖励处理连续轨迹;
Flare(Hu et al., 2024a):大规模仿真RL微调多任务机器人策略,实现真实家居场景泛化;
More(Zhao et al., 2025):全向输入+记忆引导策略蒸馏,RAPID(Kim et al., 2025):融合位姿先验加速未知布局收敛。
(3)视觉操纵
RL用于“机器人复杂物体操纵与长周期规划”:
TGRPO(Chen et al., 2025g):任务接地奖励+组归一化更新,稳定开放域物体操纵;
RFTF(Shu et al., 2025):规则化奖励支持交互式桌面任务,最小化人类监督;
RLVLA(Liu et al., 2025b)、VLA-RL(Lu et al., 2025b):课程式RL,提升机器人在多样重排环境的成功率;
ReinBot(Zhang et al., 2025b):多模态rollout+偏好更新,提升真实世界操纵鲁棒性。
四、评估指标与基准体系
综述提出“粒度分层”的评估框架,并梳理各领域专用基准,确保视觉RL研究的可复现与可比性。
4.1 评估指标的三大粒度(图6)
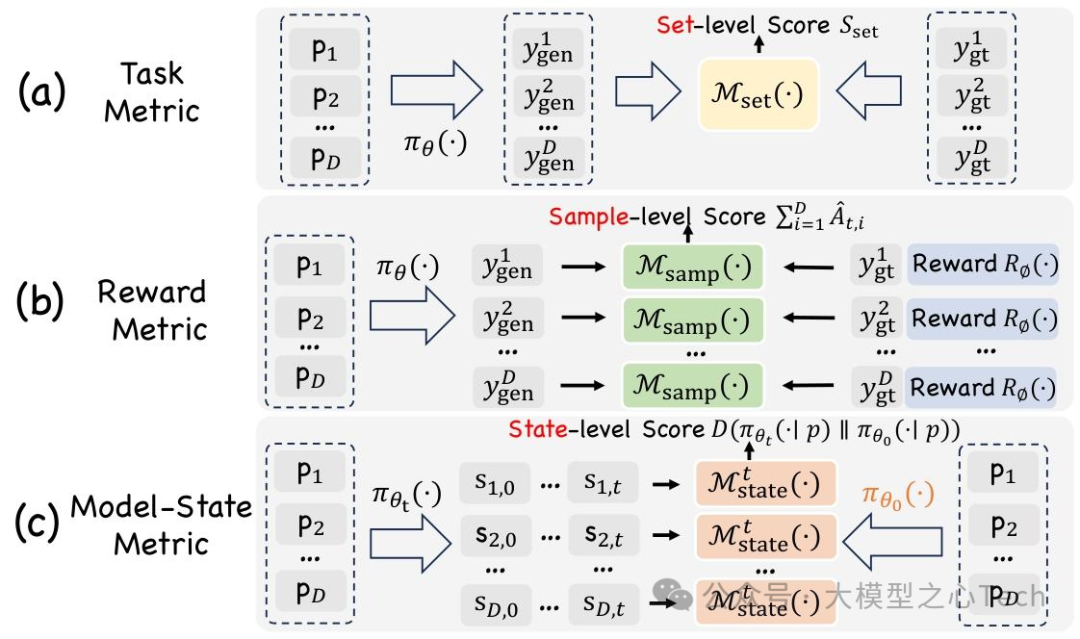
(1)Set-level(集合级)
评估整个prompt集的生成分布质量,用于最终性能报告:
定义:对测试prompt集P_test,比较生成分布Y_gen与参考分布Y_gt(如ground truth),公式为:
常用指标:图像生成的FID、Inception Score;视频生成的FVD、Video IS;VQA的准确率。
(2)Sample-level(样本级)
为单个输入-输出对提供奖励,驱动RL策略更新:
定义:对每个(p_i, y_gen^i),奖励函数M_samp(y_gen^i, p_i)=R_φ(y_gen^i,p_i)(无参考)或R_φ(y_gen^i,y_gt^i,p_i)(有参考),转化为step-wise优势Â_{i,t};
常用指标:人类偏好分数(ImageReward、HPS)、可验证指标(IoU、代码通过率)、模型偏好分数(CriticGPT、VideoPrefer)。
(3)State-level(状态级)
监控训练过程中的策略动态,早期检测异常:
核心指标:KL散度D(π_θ_t || π_θ_0)(衡量策略漂移)、输出长度漂移(防止重复/冗长)、扩散模型的去噪轨迹方差;
应用:如UniRL监控“生成-理解奖励不平衡”,HermesFlow监控共享策略的KL漂移。
4.2 各领域专用基准
综述整理了三类核心基准(表3、4、5),覆盖数据、奖励信号与评估任务:
(1)MLLM基准
聚焦“视觉推理与偏好对齐”:
SEED-Bench-R1(Chen et al., 2025c):50k视频QA对,人类偏好奖励模型;
Ego-R1(Tian et al., 2025):25k第一视角轨迹,7步链式工具调用奖励;
VisuLogic(Xu et al., 2025a):1k视觉推理谜题,精确匹配奖励。
(2)视觉生成基准
提供“人类偏好数据或可验证指标”:
ImageReward(Xu et al., 2023):人类排序的文本-图像对, scalar奖励;
Pick-a-Pic(Kirstain et al., 2023):用户偏好的文本-图像排序,用于DPO/PPO训练;
VideoReward(Liu et al., 2025a):人类排序视频对,评估质量、运动与对齐。
(3)VLA模型基准
提供“动作轨迹与环境仿真”:
GUI-R1-3K(Luo et al., 2025):3k+跨平台(Windows、Android、Web)GUI轨迹,R1稠密奖励;
Habitat(Puig et al., 2023):具身AI场景,人类与机器人交互奖励;
RLBench(James et al., 2020):多任务机器人操纵,仿真环境奖励。
五、开放挑战与未来方向
综述基于现有研究痛点,提出四大核心挑战与解决方案:
5.1 有效推理:平衡深度与效率
挑战:过长推理链导致 latency与误差累积,过短则丢失关键信息;
未来方向:
① 自适应周期策略:训练“终止评判器”,联合优化答案质量与计算成本;
② 元推理与少样本自评估:用冻结VLM critique部分推理链,决定是否继续思考;
③ 新基准:同时报告“成功率”与“推理效率”(步数、FLOPs、 latency)。
5.2 VLA的长周期RL
挑战:VLA任务需数十步原子动作(如GUI点击、机器人抓取),端任务奖励稀疏,GRPO/PPO效果有限;
未来方向:
① 内在子目标发现:通过状态变化检测或语言聚类分割轨迹,为子目标分配稠密奖励;
② 效用评判器学习:训练对比VLM评分“动作-目标距离”,无需人工标注提供塑造奖励;
③ 分层RL:高层语言规划器提出语义子任务,低层策略用离线RL或决策Transformer微调。
5.3 基于视觉思考的RL
挑战:“用图像思考”(如裁剪、绘制)的动作空间设计、信用分配与数据效率问题;
未来方向:
① 混合动作空间:可微提议策略+策略梯度精炼连续动作(如裁剪坐标);
② step-wise代理奖励:如“裁剪后CLIP相似度提升”“信念状态熵降低”,实现分层RL;
③ 样本高效方法:模型基想象(如Pixel Reasoner)、不确定性感知规划。
5.4 视觉生成的奖励模型设计
挑战:现有奖励(如FID、ImageReward)与人类感知弱相关,易导致“奖励攻击”(如高对比度 artifacts);
未来方向:
① 多信号融合:整合低阶信号(一致性、物理、几何)与高阶人类偏好;
② 跨模态泛化:设计适用于图像、视频、3D的通用奖励模型;
③ 抗攻击与动态更新:奖励模型需鲁棒于策略漏洞,且能随用户偏好演变更新。
六、结论
视觉强化学习已从“孤立验证”发展为“融合视觉、语言、动作的研究前沿”,核心驱动力包括:①奖励监督从RLHF向“组相对+可验证”升级;②统一架构实现“感知-推理-生成”联合优化;③基准体系覆盖“偏好对齐+策略稳定”多维度。
然而,领域仍面临“数据效率低、泛化能力有限、长周期奖励设计缺乏指导、评估标准待完善”等挑战。未来需更紧密结合“模型基规划、自监督视觉预训练、自适应课程、安全优化”,推动视觉RL走向“样本高效、可靠、社会对齐”的实际应用。
参考
论文标题:Reinforcement Learning in Vision: A Survey
论文链接:https://arxiv.org/pdf/2508.08189
项目主页:https://github.com/weijiawu/Awesome-Visual-Reinforcement-Learning
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!


















 203
203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









