



点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型技术交流群
本文只做学术分享,如有侵权,联系删文

写在前面
还记得当年AlexNet在ImageNet上的一鸣惊人吗?
它点燃了深度学习的浪潮,但背后是海量人工标注的心血——千万张图片,被逐一打上标签。自此,“数据饥渴”和“标注成本”如同两座大山,压在计算机视觉发展的道路上。
研究者们一直在追寻一个梦想:能否让模型像人类婴儿一样,仅通过“观察”世界就能学习强大的视觉理解能力,彻底摆脱对人工标注的依赖? 这就是自监督学习(SSL) 的终极目标。
这条路上星光熠熠:
MAE(Masked Autoencoders) :如同BERT之于文本,让模型通过“猜”被遮盖的图像块来学习,展现了强大的潜力。
MoCo/SimCLR:通过对比不同视角下的同一图像,让模型理解“什么看起来应该相似”。
DINO系列 (特别是DINOv2):带来了真正的突破!它不仅能学到优秀的全局图像特征(用于分类、检索),其冻结(Frozen) 的骨干网络提取的密集(Dense)特征(理解局部细节、像素级信息)在分割、深度估计等任务上表现惊艳,无需微调就能媲美甚至超越许多需要标注的模型。DINOv2证明了:一个强大的、通用的、冻结的视觉编码器,是可能的!
然而,挑战依然存在:
规模魔咒:当模型(如超过3亿参数的ViT-Large)和训练时间进一步增大时,DINOv2的密集特征质量会神秘地下降(特征退化)。
数据利用:如何高效地从海量无约束、无标注的图片中淘金?
通用性极限:能否让一个模型真正通吃自然图像、卫星图、医学影像等不同领域?
现在,Meta AI Research携最新力作DINOv3震撼登场。

这份技术报告不仅宣告了自监督视觉模型的新高度,更是在解决上述核心挑战上取得了里程碑式的突破。
一、解决SSL三大痛点,DINOv3的核心目标
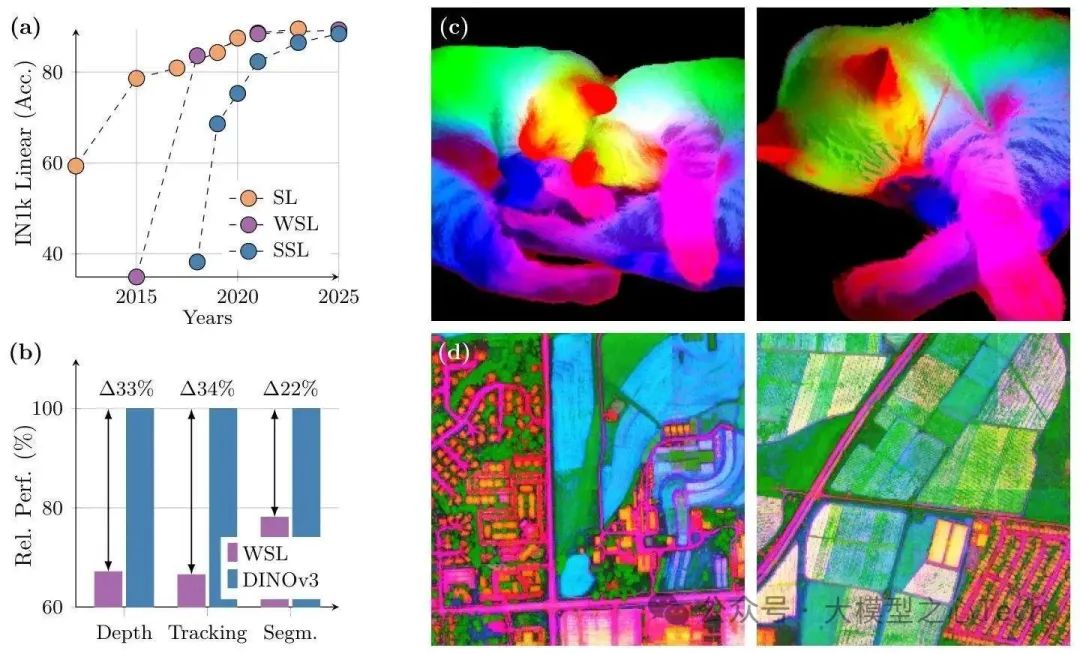
在DINOv3之前,自监督视觉模型的规模化发展面临三大关键瓶颈:
数据质量难把控:无标注数据中混杂噪声与冗余,直接训练反而拖累模型性能,如何筛选出“有用”的数据成为难题;
密集特征易退化:当模型参数量超ViT-L(300M)、训练轮次超20万时,局部特征图会逐渐“变糊”,空间定位能力下降,严重影响分割、深度估计等任务;
适配场景太局限:多数SSL模型只能在固定分辨率下推理,且难以兼顾轻量化部署与图文对齐能力,实用性大打折扣。
针对这些痛点,DINOv3的目标非常明确:打造一款“全能型”自监督基础模型——既能用冻结的 backbone 直接应对多任务,又能提供高质量密集特征,还能适配从边缘设备到卫星图像处理的全场景需求。
本文首发于大模型之心Tech知识星球,硬核资料在星球置顶:加入后可以获取大模型视频课程、代码学习资料及各细分领域学习路线~

二、三大技术突破,撑起7B参数的“全能”实力
为实现上述目标,DINOv3在数据构建、训练策略、特征优化三大层面进行了颠覆性创新。
1. 数据:16.89亿张图像的“分层筛选+混合采样”
数据是自监督模型的“燃料”,但“多”不代表“好”。DINOv3团队从170亿张经过内容审核的Instagram图像中,通过三层筛选构建了高质量训练集:
第一层:聚类选“多样”:用DINOv2特征做5级分层k-means聚类(最终聚为25k类),筛选出16.89亿张覆盖全面视觉概念的图像(LVD-1689M),保证数据多样性;
第二层:检索补“相关”:从数据池中检索与ImageNet等种子数据集相似的图像,强化任务相关特征,避免模型“学偏”;
第三层:公开数据提“精度”:补充ImageNet1k/22k、Mapillary等标注数据集,进一步优化基础任务性能。
采样时,团队还设计了“10%纯+90%混”的策略:10%批次用纯ImageNet1k数据(提升任务精度),90%批次混合LVD-1689M、检索数据与公开数据(保证通用性)。实验证明,这种混合数据在IN1k线性探测(87.2%)、ObjectNet(72.8%)等任务上,全面超越纯聚类、纯检索或原始数据。
2. 训练:固定超参数+7B ViT,打破“调度依赖”
以往SSL模型训练时,需要动态调整学习率、权重衰减等超参数(如余弦调度),但这会限制模型的规模化——谁也不知道“最优调度”该如何适配10亿级数据。
DINOv3反其道而行之:全程用固定超参数训练100万轮。具体来说:
学习率固定为0.0004(仅前10万轮线性预热),权重衰减0.04,教师EMA动量0.999;
模型架构升级为7B参数ViT(ViT-7B),嵌入维度从1536提升至4096,采用16像素patch+轴向RoPE编码,提升对分辨率、尺度的鲁棒性;
损失函数融合DINO全局损失、iBOT补丁重建损失与Koleo正则化,既保证全局判别性,又强化局部特征一致性。
这种“简单粗暴”的训练方式,不仅让模型能持续从海量数据中学习,还避免了因“调度不当”导致的性能瓶颈——ViT-7B的全局性能随训练轮次稳步提升,为后续修复密集特征打下基础。
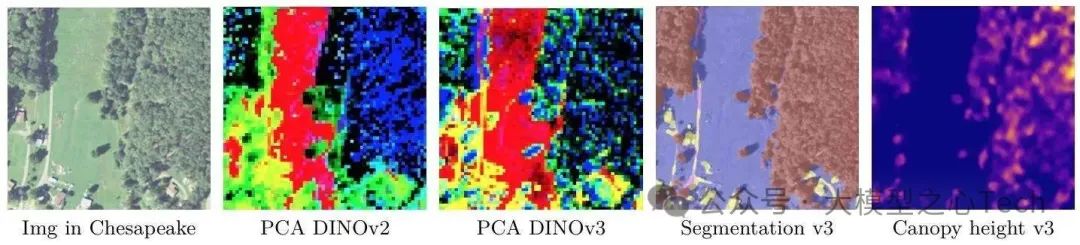
3. 特征:Gram Anchoring,让退化的密集特征“重生”
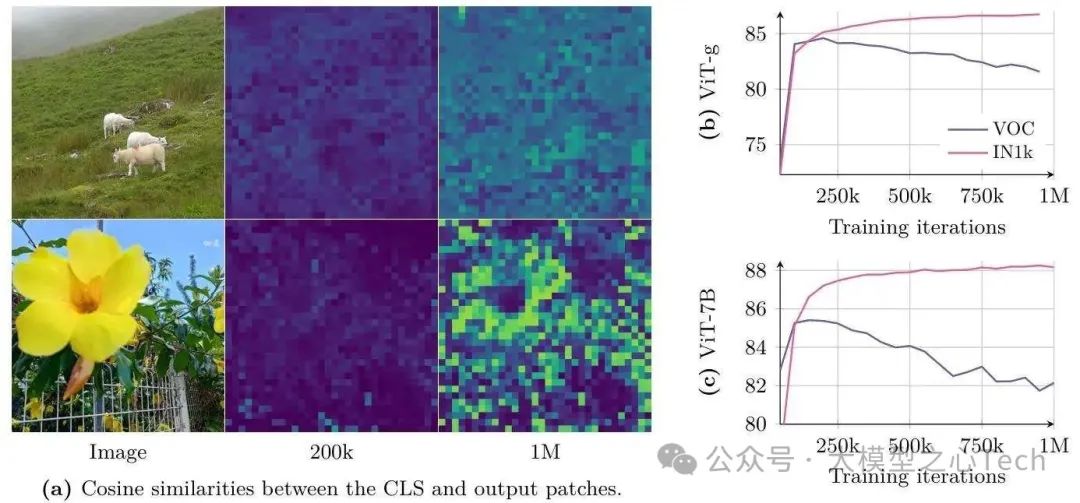
这是DINOv3最核心的创新。团队发现,长时间训练后,CLS token与补丁特征的相似度会逐渐升高(如图5a),导致局部特征“被全局化”,失去空间特异性——这就是密集特征退化的根源。
为解决这个问题,他们提出Gram Anchoring(Gram锚定) 策略:
核心思路:让当前模型(学生)的补丁特征“模仿”训练早期(20万轮左右)模型(Gram教师)的相似度结构。具体来说,通过最小化学生与教师的Gram矩阵(补丁特征的 pairwise 点积矩阵)差异,强制保留局部特征的空间关系;
优化细节:将Gram教师的输入分辨率提升至2倍(如512×512),生成特征图后下采样至学生分辨率,用高分辨率信息“蒸馏”平滑特征;
启动时机:在100万轮后启动Gram损失,既能保留全局性能,又能快速修复退化的密集特征。
效果立竿见影:引入Gram损失后,VOC分割mIoU在10万轮内提升3+,1024×1024图像的余弦相似度图噪声显著减少,局部特征的定位精度大幅回升。
三、后训练优化:从4K推理到手机部署,全场景适配
光有强大的基础模型还不够,DINOv3团队还通过三项后训练技术,让模型能适配不同场景需求:
1. 分辨率适配:支持4096×4096超高清推理


多数模型训练时用256×256分辨率,推理时放大图像会导致特征失真。DINOv3新增高分辨率适配阶段:用512-768像素全局裁剪、112-336像素局部裁剪训练1万轮,同时保留Gram损失,确保特征在高分辨率下仍保持一致性。
实验显示,适配后的模型在768×768分辨率下,IN1k精度提升0.5%,ADE20k分割mIoU提升2.1%,甚至能处理4096×4096分辨率的图像(特征图仍清晰,如图4),为卫星图像、医疗影像等大尺寸场景提供可能。
2. 模型蒸馏:840M参数学生模型,性能接近7B教师
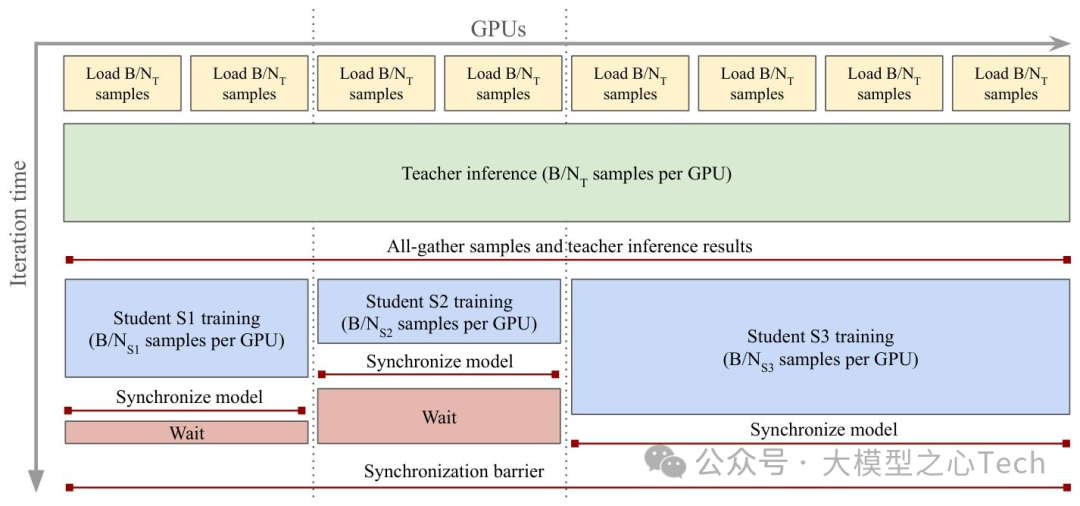
7B参数模型虽强,但部署成本太高。团队提出单教师-多学生并行蒸馏:以7B模型为固定教师,同时训练ViT(S/B/L/H+)与ConvNeXt(T/S/B/L)系列学生模型,通过共享教师推理计算,大幅降低蒸馏成本。
其中,ViT-H+(840M参数)表现最惊艳:在IN1k(90.3%)、ADE20k(54.8%)等任务上,性能接近7B教师(仅差1-2个百分点),但推理速度快5倍,可轻松部署在中端GPU上;ConvNeXt-L更适合移动端,512分辨率下IN-ReAL精度达89.4%,超监督ConvNeXt-L 1.6%。
3. 文本对齐:冻结视觉 encoder,实现零样本图文匹配
为让DINOv3具备多模态能力,团队参考LiT范式:冻结视觉 encoder,训练文本 encoder,将CLS token与补丁特征均值池化拼接作为视觉输出,用对比损失优化图文相似度。
最终,文本对齐后的DINOv3 ViT-L在ImageNet1k零样本分类达82.3%,ADE20k开放词汇分割mIoU 24.7%(超同类模型dino.txt 5.5),Cityscapes达36.9%(超PE模型15.5),无需微调就能应对图文检索、开放词汇分割等任务。
四、性能碾压:从分类到卫星图像,全任务SOTA

DINOv3在全局任务、密集任务、跨领域场景三大维度,均展现出“碾压级”实力,部分结果甚至超越监督模型。
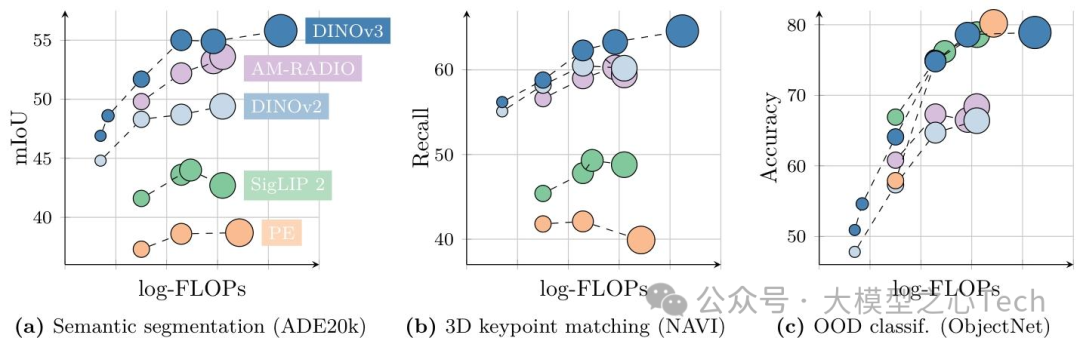
1. 密集任务:刷新自监督模型上限
密集任务(分割、深度估计、3D匹配)是SSL的传统短板,但DINOv3彻底改变了这一局面:
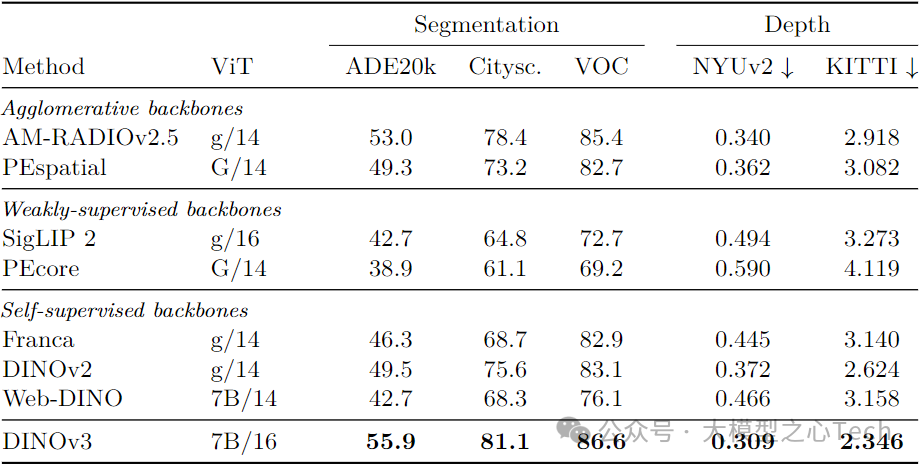
语义分割:在线性探测设置下,ADE20k mIoU 55.9(超DINOv2 6.4、SigLIP 2 13.2);结合Mask2Former解码器(冻结backbone),mIoU达63.0,与监督SOTA ONE-PEACE持平;
深度估计:NYUv2 RMSE 0.309(超DINOv2 0.063),结合Depth Anything V2后,ARel 4.3、δ₁ 98.0(新SOTA),ETH3D ARel 5.4(超Marigold 1.1);
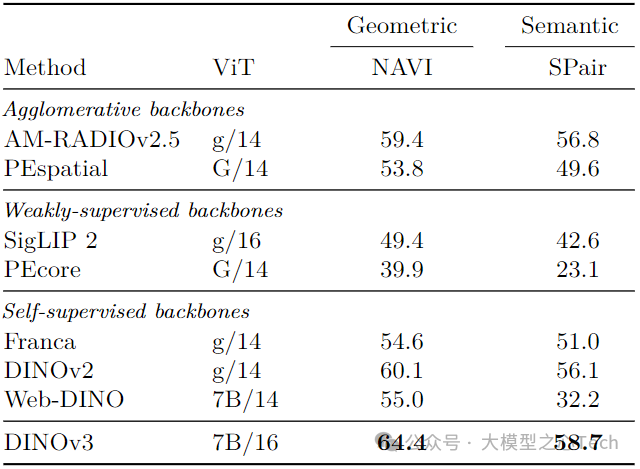
3D关键点匹配:NAVI几何匹配召回率64.4(超DINOv2 4.3),SPair语义匹配58.7(超AM-RADIOv2.5 1.9),是唯一超越监督蒸馏模型(PEspatial)的自监督模型;
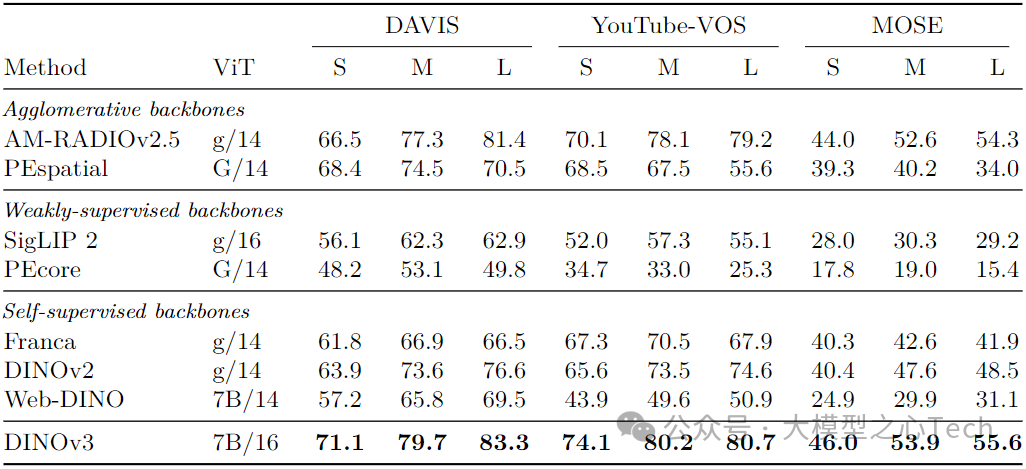
视频跟踪:DAVIS数据集1440分辨率J&F 83.3(超DINOv2 6.7、PEspatial 12.8),且性能随分辨率提升持续增长(其他模型多饱和或下降)。
2. 全局任务:媲美弱监督/监督模型
在分类、检索等全局任务上,DINOv3也打破了“自监督不如弱监督”的偏见:
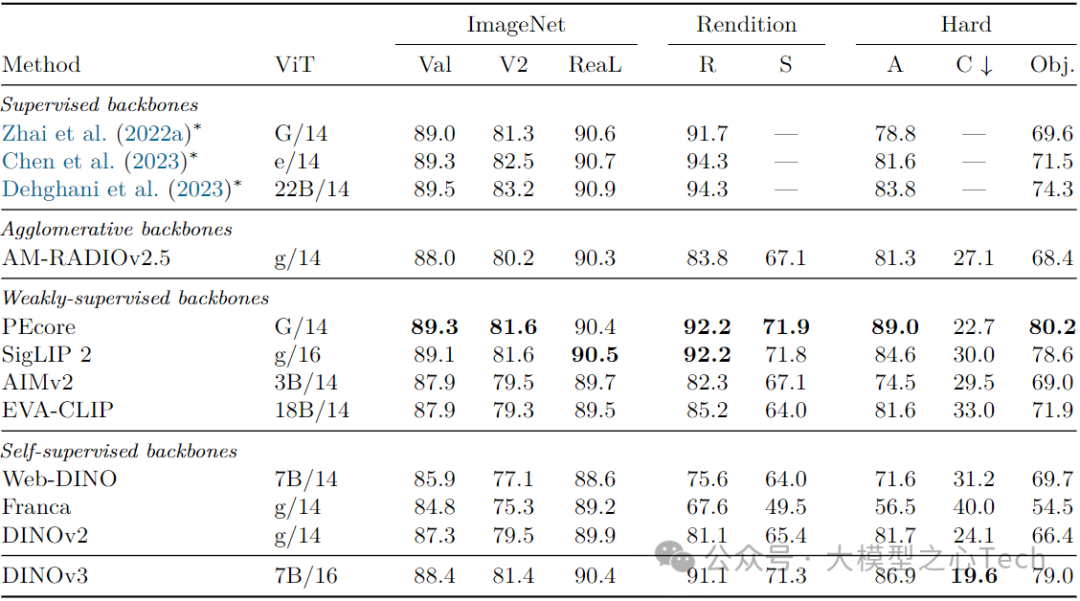
ImageNet分类:线性探测精度88.4%(仅低于PEcore 0.9%、SigLIP 2 0.7%),IN-ReAL(90.4%)、IN-V2(81.4%)与弱监督模型持平,IN-C(19.6%)抗干扰能力全模型最优;
分布外泛化:ObjectNet 79.0(超DINOv2 12.6、SigLIP 2 0.4),IN-Rendition 91.1(超DINOv2 10.0),证明模型对“奇怪”图像的适应能力;
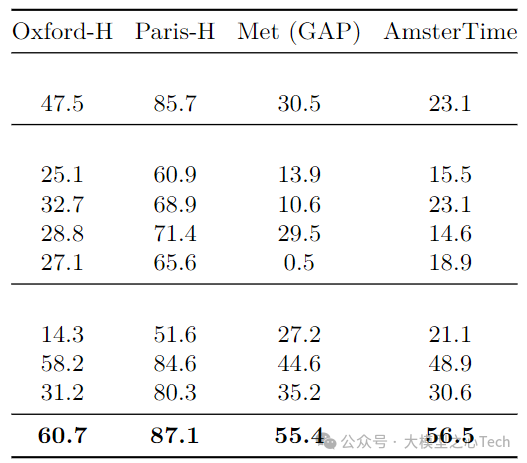
实例检索:Oxford-H mAP 60.7(超DINOv2 2.5)、Met GAP 55.4(超DINOv2 10.8),弱监督模型(如SigLIP 2)在该任务上差距显著(Oxford-H仅23.0)。
3. 跨领域:卫星图像专用模型,RGB输入超越多光谱
DINOv3的通用性还体现在跨领域适配——团队基于4.93亿张Maxar卫星图像(0.6米分辨率),预训练了DINOv3-Sat专用模型,在地理任务中表现惊艳:
树冠高度估计:Open-Canopy数据集MAE 2.02(超Tolan et al. 0.4),SatLidar1M测试集MAE 3.2(超DINOv3-Web 0.4);
GEO-Bench任务:分类任务平均81.6(超Prithvi-v2 2.0),分割任务平均75.9(超DOFA 7.6),且仅用RGB输入就超越了多光谱输入的模型;
高分辨率遥感任务:LoveDA分割mIoU 55.3(超BillionFM 0.9),DIOR检测mAP 76.6(超SkySense V2 2.9)。
五、模型家族与应用:从手机到卫星,全场景覆盖
为满足不同部署需求,DINOv3团队推出了完整的模型家族,涵盖多参数规模、多架构:
ViT系列:ViT-S(21M)、ViT-B(86M)、ViT-L(300M)、ViT-H+(840M)、ViT-7B(6.7B),适配从边缘设备到高性能计算的场景;
ConvNeXt系列:ConvNeXt-T(29M)、ConvNeXt-S(50M)、ConvNeXt-B(89M)、ConvNeXt-L(198M),适合移动端与嵌入式设备,且量化性能优异。
这些模型的应用场景极为广泛:
工业检测:用ViT-L处理高分辨率产品图像,实现缺陷分割;
自动驾驶:用ConvNeXt-B实时输出道路语义分割结果;
卫星遥感:用DINOv3-Sat分析4K卫星图像,监测森林覆盖变化;
医疗影像:基于高质量密集特征,辅助病理切片细胞检测。

总结:自监督视觉模型,终于走向“实用”
DINOv3的发布,不仅刷新了自监督视觉模型的性能上限,更重要的是,它解决了SSL长期存在的“实用性”问题——无需微调即可部署、适配全场景、兼顾性能与效率。
从技术层面看,Gram Anchoring为大规模SSL模型的密集特征优化提供了新范式,而“分层筛选+混合采样”的数据策略,也为无标注数据的利用提供了参考。从应用层面看,DINOv3家族覆盖的多场景适配能力,让自监督模型真正走进工业、遥感、医疗等领域。
未来,随着数据规模的进一步扩大与模型架构的持续优化,自监督视觉模型或许会彻底取代传统监督模型,成为计算机视觉的“基础设施”。而DINOv3,无疑是这一进程中的关键里程碑。
参考
论文标题:DINOv3
论文链接:https://arxiv.org/pdf/2508.10104
开源链接:https://github.com/facebookresearch/dinov3
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!


















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









