




点击下方卡片,关注“自动驾驶之心”公众号
ICCV的放榜啦,自动驾驶之心团队为大家梳理了自动驾驶相关方向的中稿文章,后续会持续更新,并在自动驾驶之心知识星球内部第一时间分享!欢迎加入我们~

多模态大模型 & VLA
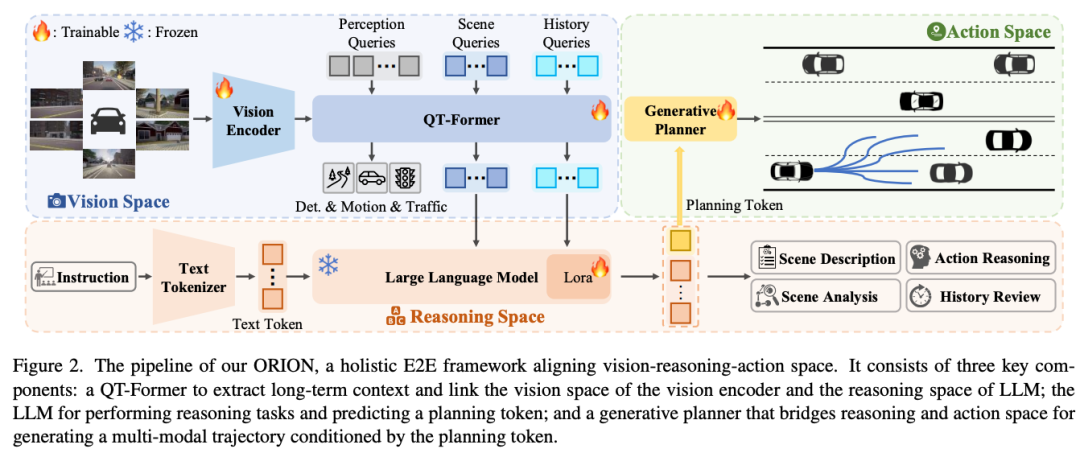
标题:ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
链接:https://arxiv.org/abs/2503.19755
主页:https://xiaomi-mlab.github.io/Orion/
单位:华科、小米
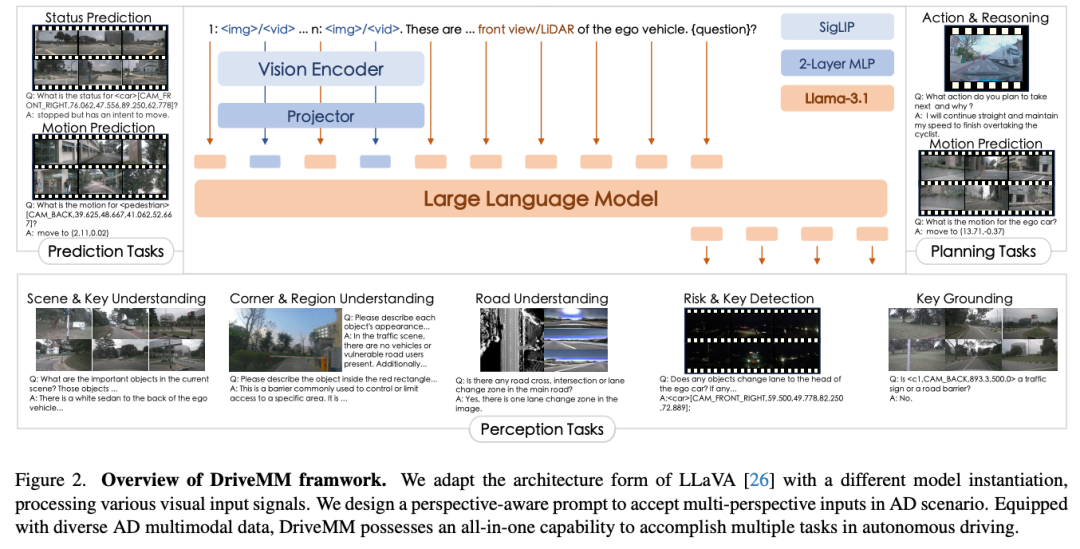
标题:All-in-One Large Multimodal Model for Autonomous Driving
链接:https://arxiv.org/abs/2412.07689
主页:https://zhijian11.github.io/DriveMM/
单位:中山&美团
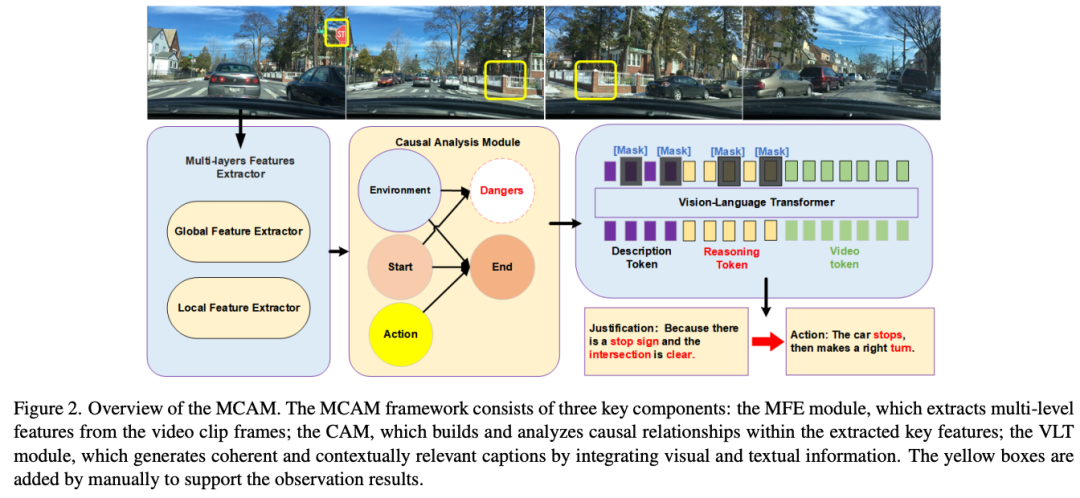
标题:MCAM: Multimodal Causal Analysis Model for Ego-Vehicle-Level Driving Video Understanding
链接:https://arxiv.org/abs/2507.06072
代码:https://github.com/SixCorePeach/MCAM
单位:重庆大学
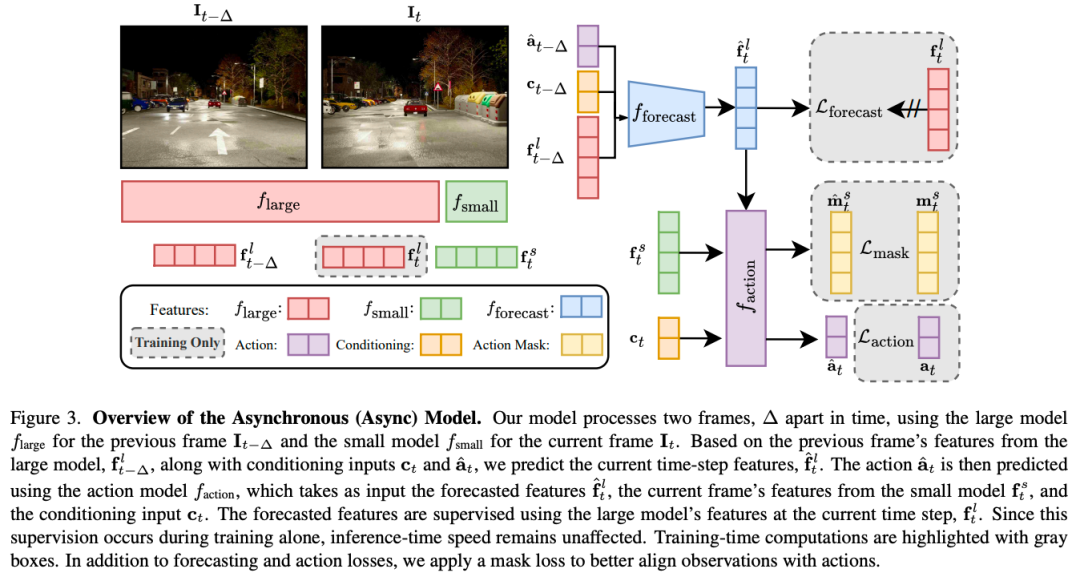
标题:AdaDrive: Self-Adaptive Slow-Fast System for Language-Grounded Autonomous Driving\
主页:https://github.com/ReaFly/AdaDrive
标题:VLDrive: Vision-Augmented Lightweight MLLMs for Efficient Language-grounded Autonomous Driving
主页:https://github.com/ReaFly/VLDrive
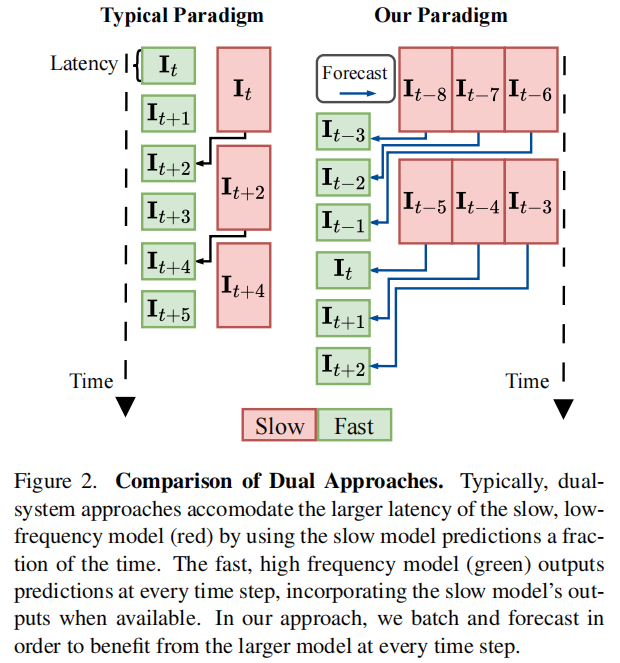
标题:ETA: Efficiency through Thinking Ahead, A Dual Approach to Self-Driving with Large Models
链接:https://arxiv.org/abs/2506.07725
主页:https://github.com/OpenDriveLab/ETA
单位:科奇大学、港大、OpenDriveLab
仿真 & 重建
标题:InvRGB+L: Inverse Rendering of Complex Scenes with Unified Color and LiDAR Reflectance Modeling
链接:https://arxiv.org/abs/2507.17613
单位:清华大学,伊利诺伊大学厄巴纳 - 香槟分校
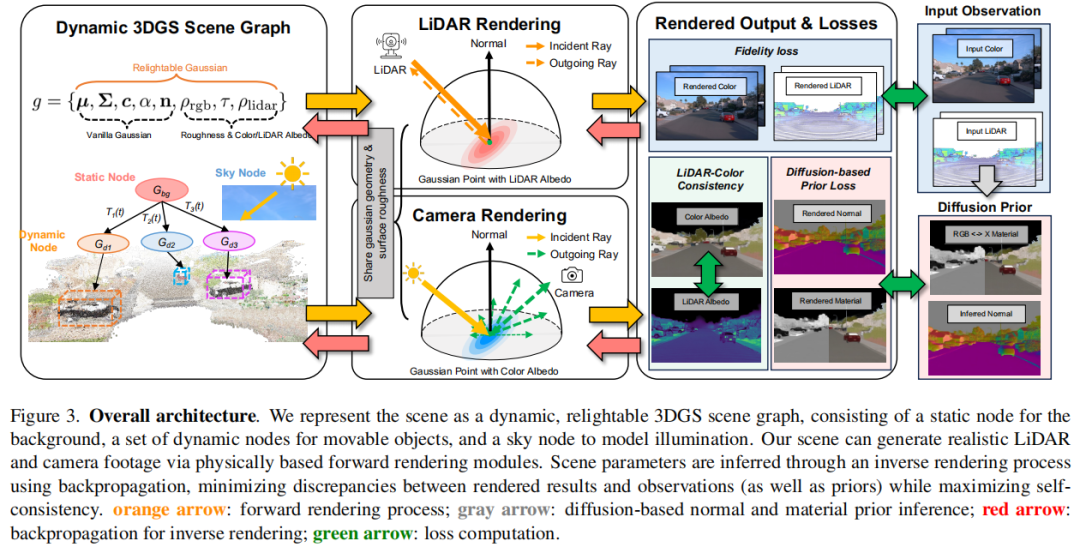
标题:AD-GS: Object-Aware B-Spline Gaussian Splatting for Self-Supervised Autonomous Driving
链接:https://arxiv.org/abs/2507.12137
主页:https://jiaweixu8.github.io/AD-GS-web/
单位:南开大学,伊利诺伊大学厄巴纳 - 香槟分校
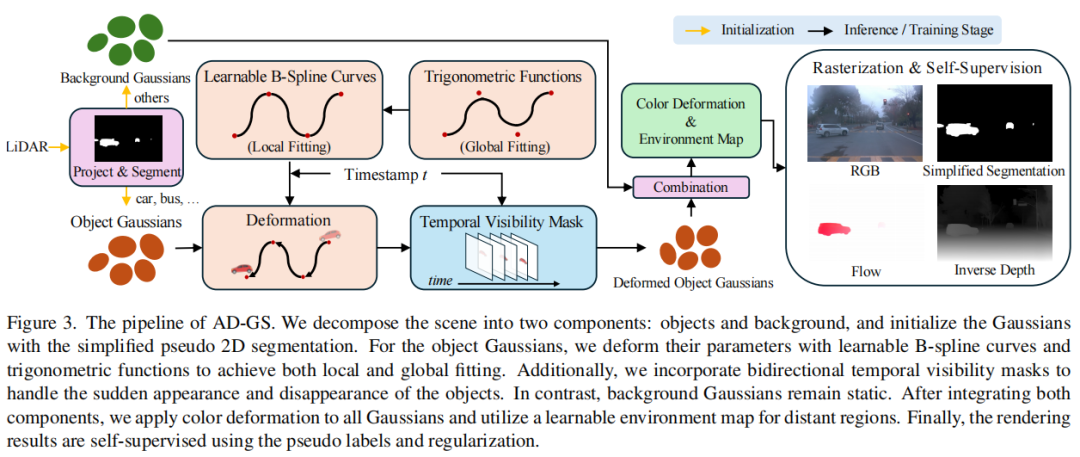
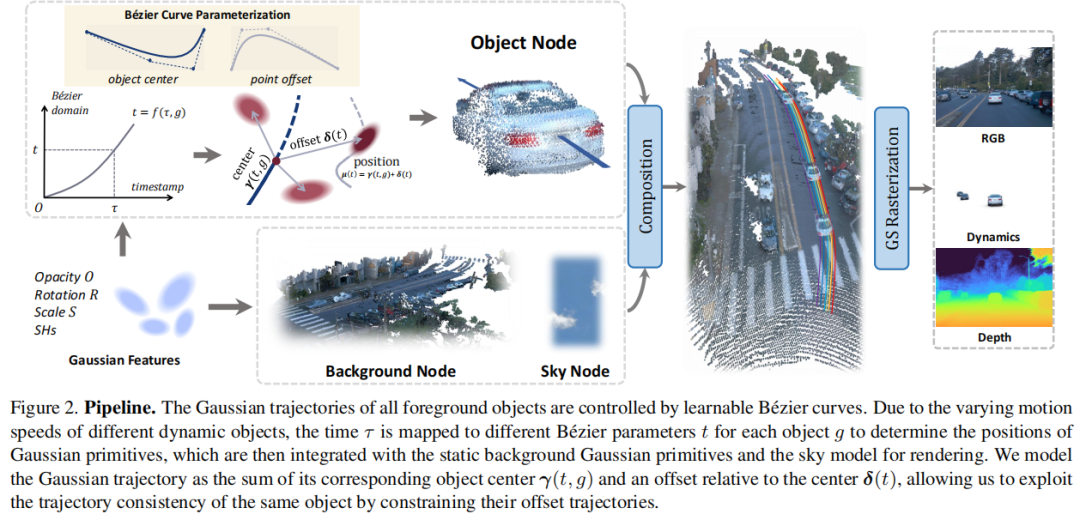
标题:BézierGS: Dynamic Urban Scene Reconstruction with Bézier Curve Gaussian Splatting
链接:https://arxiv.org/abs/2506.22099
主页:https://github.com/fudan-zvg/BezierGS
单位:复旦大学,上海创新研究院
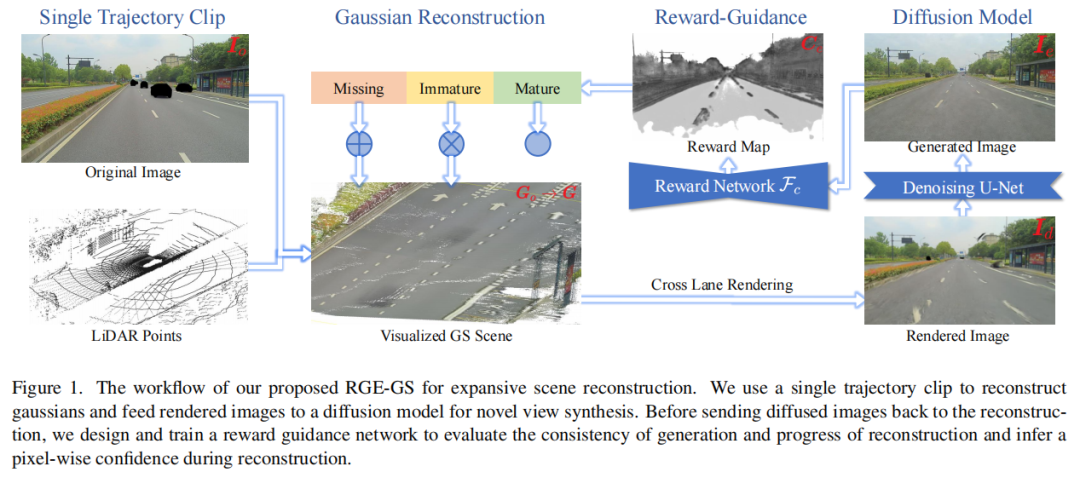
标题:RGE-GS: Reward-Guided Expansive Driving Scene Reconstruction via Diffusion Priors
链接:https://arxiv.org/abs/2506.22800
主页:https://github.com/CN-ADLab/RGE-GS
单位:清华大学,浙江大学,菜鸟网络
端到端 & 轨迹预测
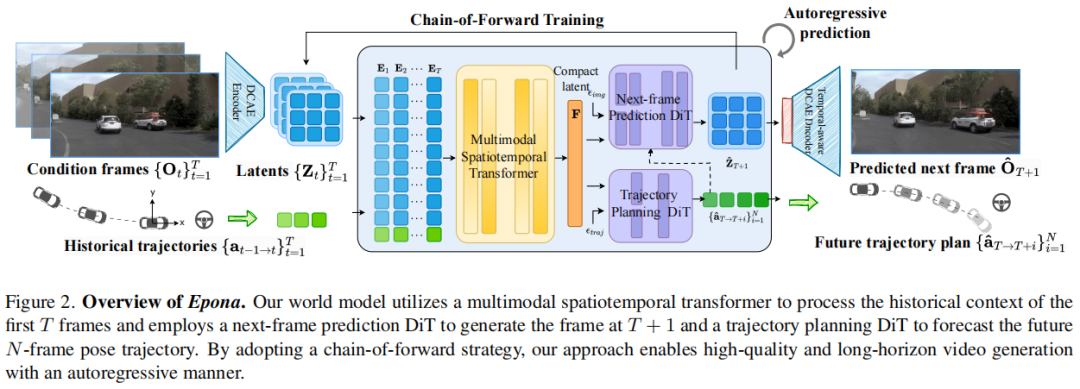
标题:Epona: Autoregressive Diffusion World Model for Autonomous Driving
链接:https://arxiv.org/pdf/2506.24113
主页:https://github.com/Kevin-thu/Epona
单位:清华大学,地平线,北京大学
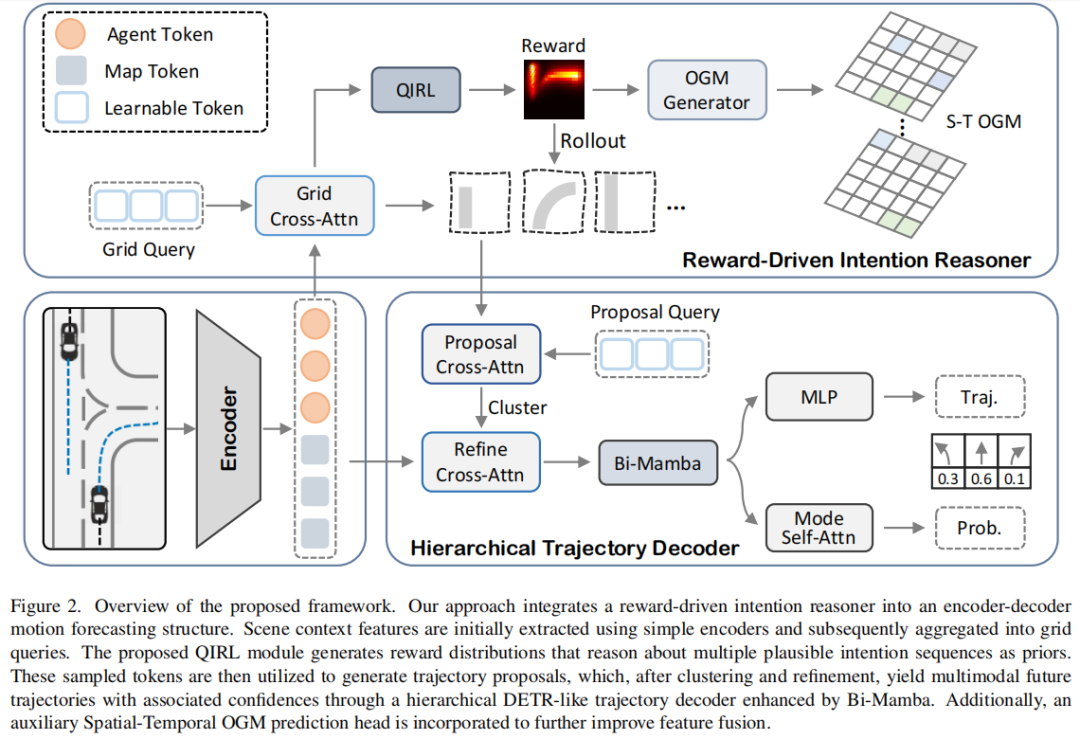
标题:Foresight in Motion: Reinforcing Trajectory Prediction with Reward Heuristics
链接:https://arxiv.org/abs/2507.12083
单位:香港科技大学,滴滴,卓驭科技
世界模型
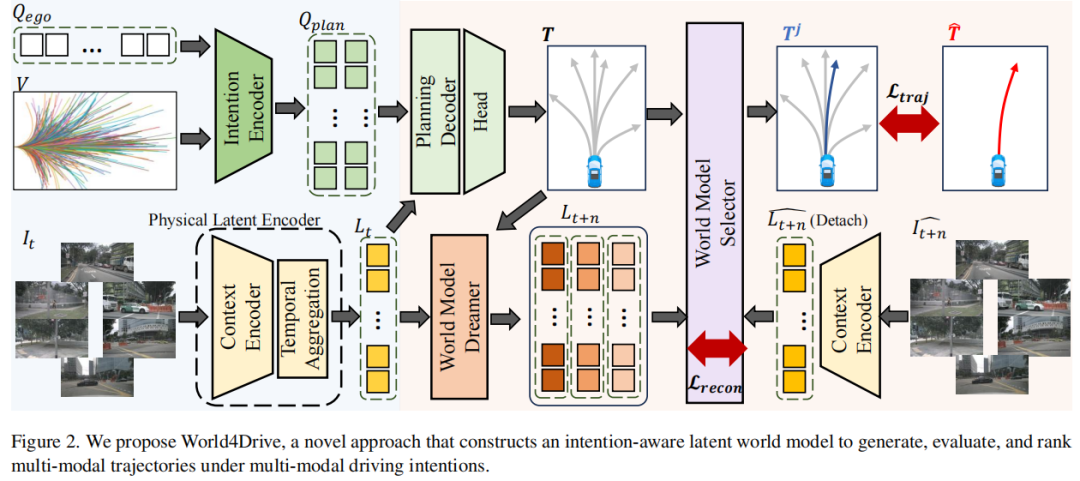
标题:World4Drive: End-to-End Autonomous Driving via Intention-aware Physical Latent World Model
链接:https://arxiv.org/abs/2507.00603
主页:https://github.com/ucaszyp/World4Drive
单位:中国科学院自动化研究所,理想,新加坡国立大学等
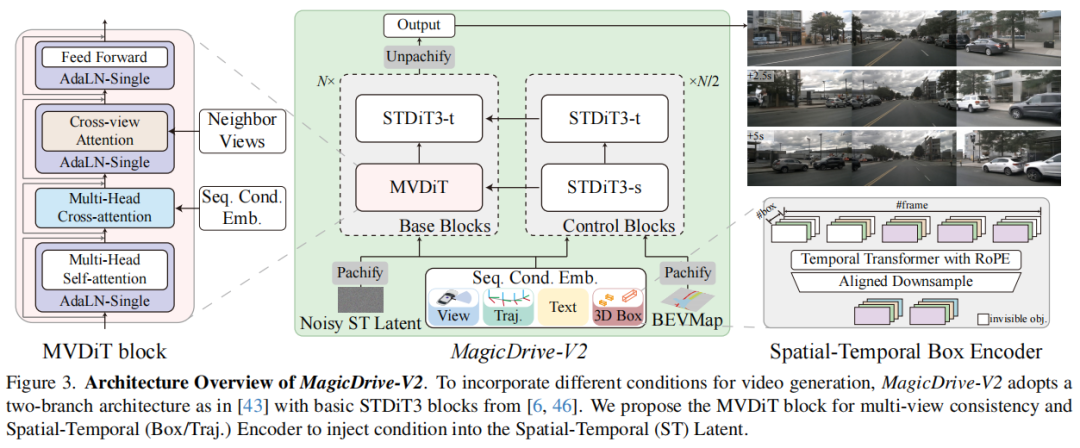
标题:MagicDrive-V2: High-Resolution Long Video Generation for Autonomous Driving with Adaptive Control
链接:https://arxiv.org/abs/2411.13807
主页:https://github.com/flymin/MagicDrive-V2
单位:香港中文大学,华为诺亚方舟实验室等
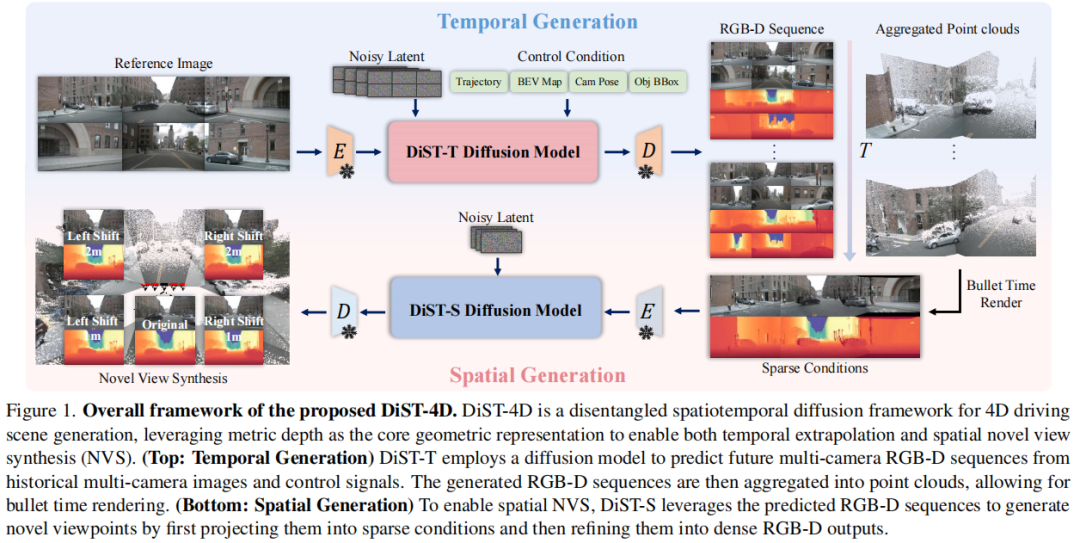
标题:DiST-4D: Disentangled Spatiotemporal Diffusion with Metric Depth for 4D Driving Scene Generation
链接:https://arxiv.org/pdf/2503.15208
主页:https://github.com/royalmelon0505/dist4d
单位:清华大学,旷视科技等
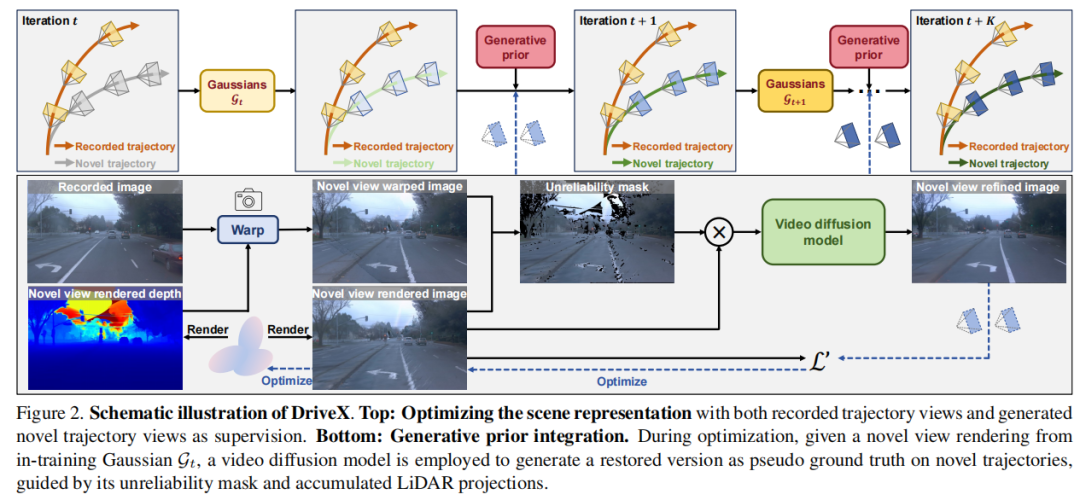
标题:Driving View Synthesis on Free-form Trajectories with Generative Prior
链接:https://arxiv.org/abs/2412.01717
主页:https://github.com/fudan-zvg/DriveX
单位:复旦大学,萨里大学
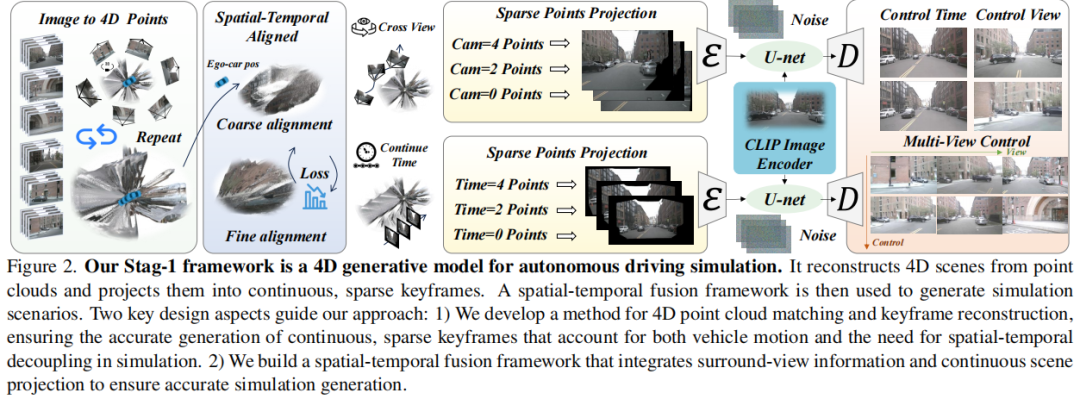
标题:Stag-1: Towards Realistic 4D Driving Simulation with Video Generation Model
链接:https://arxiv.org/abs/2412.05280
主页:https://github.com/wzzheng/Stag
单位:北京大学,清华大学,北京航空航天大学
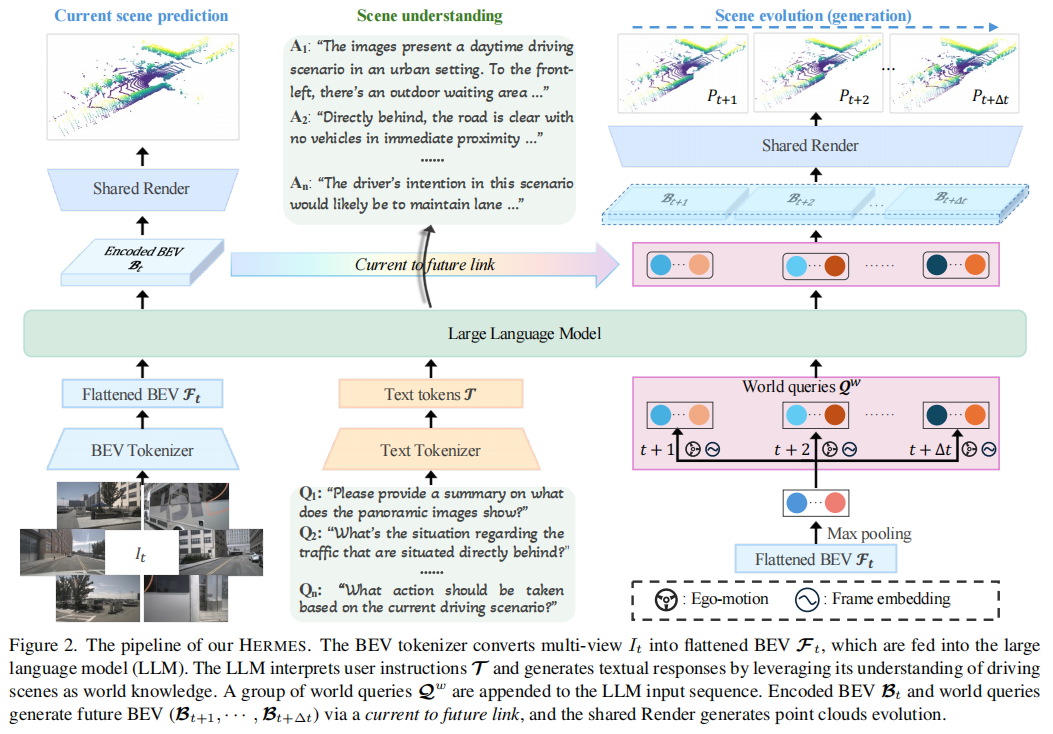
标题:HERMES: A Unified Self-Driving World Model for Simultaneous 3D Scene Understanding and Generation
链接:https://arxiv.org/abs/2501.14729
主页:https://github.com/LMD0311/HERMES
单位:华中科技大学,香港大学等
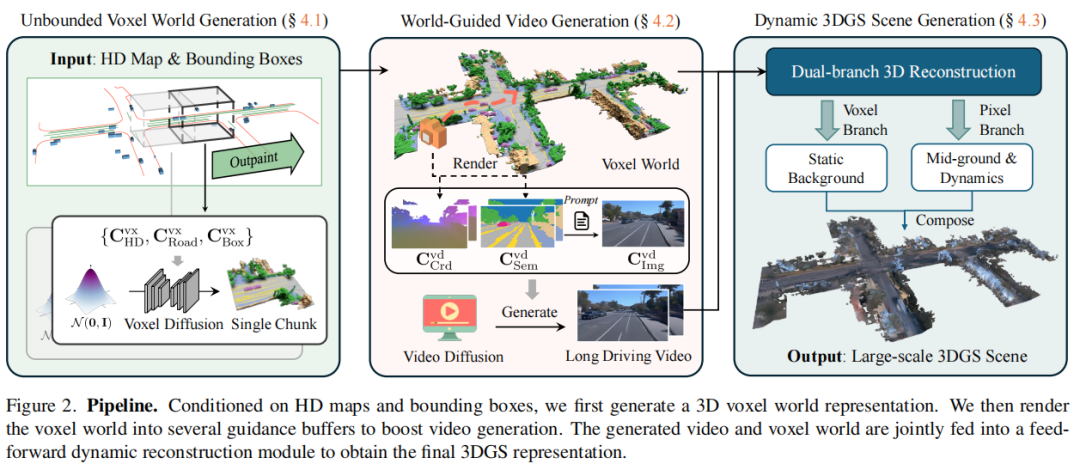
标题:InfiniCube: Unbounded and Controllable Dynamic 3D Driving Scene Generation with World-Guided Video Models
链接:https://arxiv.org/abs/2412.03934
主页:https://github.com/nv-tlabs/InfiniCube
单位:NVIDIA,上海交通大学,多伦多大学
占用网络
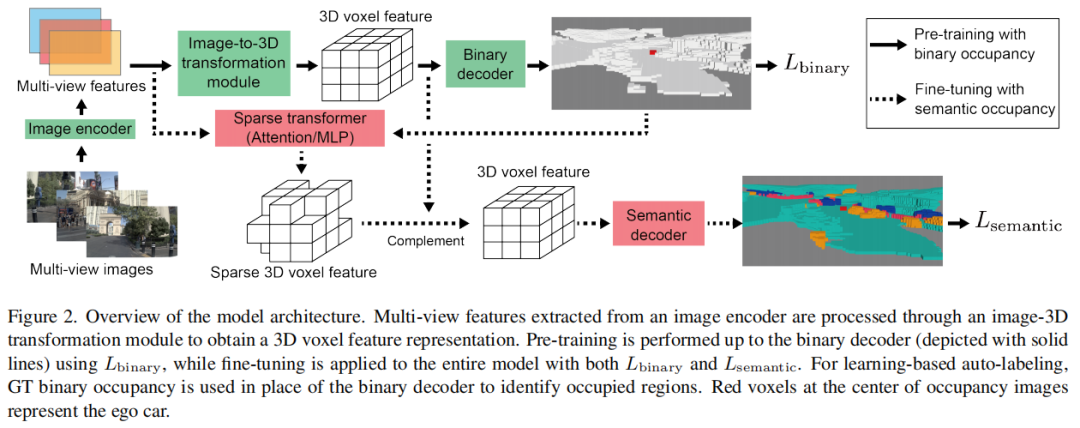
标题:From Binary to Semantic: Utilizing Large-Scale Binary Occupancy Data for 3D Semantic Occupancy Prediction
链接:https://arxiv.org/abs/2507.13387
主页:https://github.com/ToyotaInfoTech/b2s-occupancy
单位:丰田汽车公司
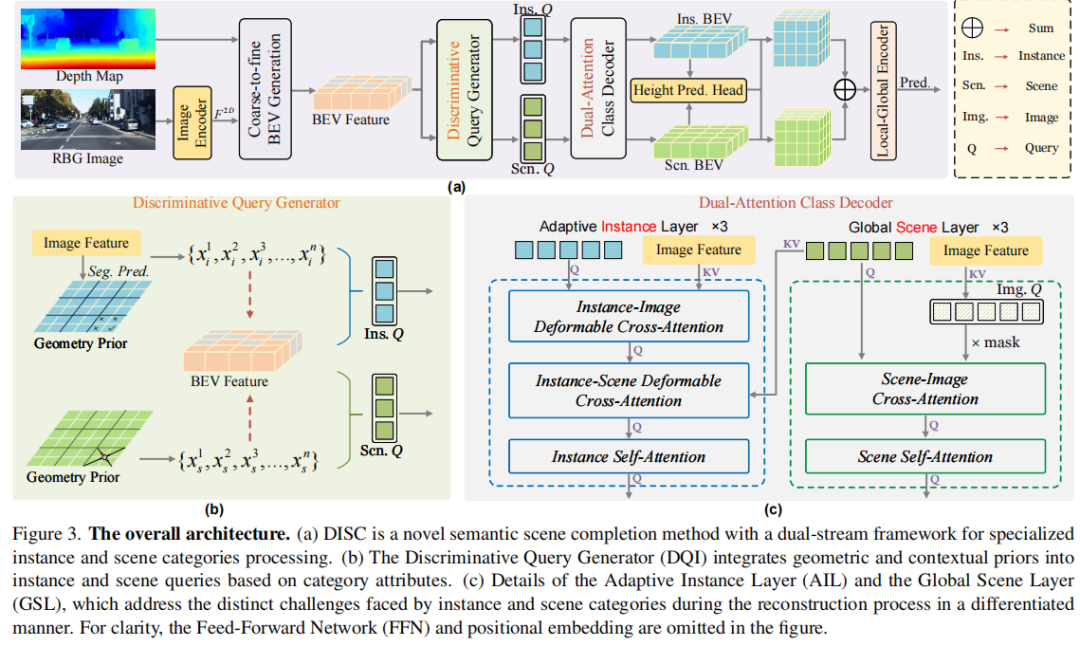
标题:Disentangling Instance and Scene Contexts for 3D Semantic Scene Completion
链接:https://arxiv.org/abs/2507.08555
主页:https://github.com/Enyu-Liu/DISC
单位:华中科技大学
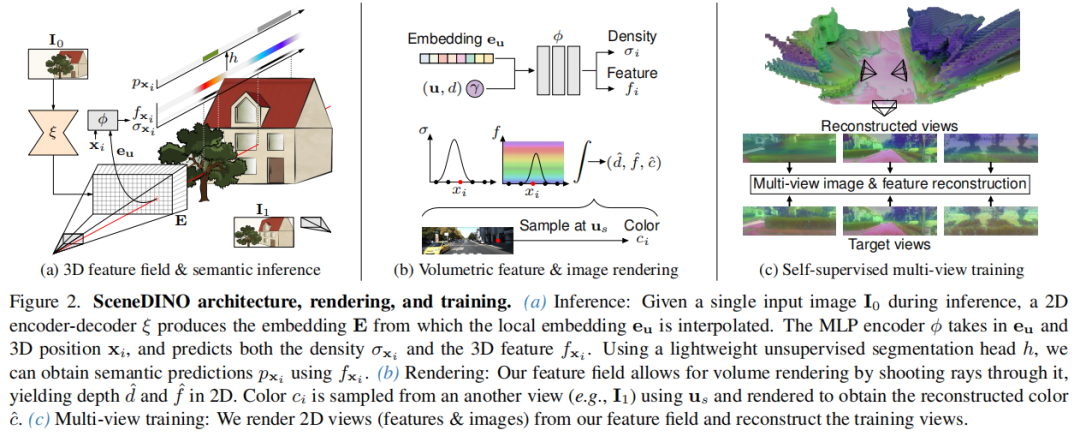
标题:Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion
链接:https://arxiv.org/abs/2507.06230
主页:https://visinf.github.io/scenedino
单位:慕尼黑工业大学,牛津大学等
标题:GaussRender: Learning 3D Occupancy with Gaussian Rendering
链接:https://arxiv.org/abs/2502.05040
主页:https://github.com/valeoai/GaussRender
单位:Valeo AI,索邦大学
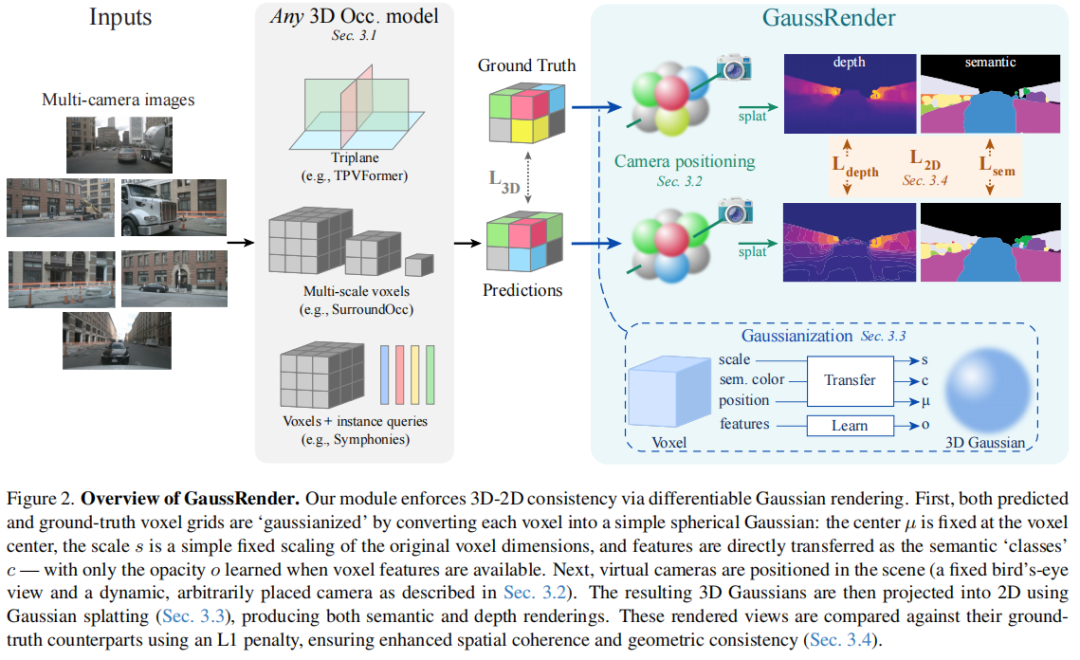
标题:GaussianOcc: Fully Self-supervised and Efficient 3D Occupancy Estimation with Gaussian Splatting
链接:https://arxiv.org/abs/2408.11447
主页:https://ganwanshui.github.io/GaussianOcc/
单位:东京大学,华南理工大学等
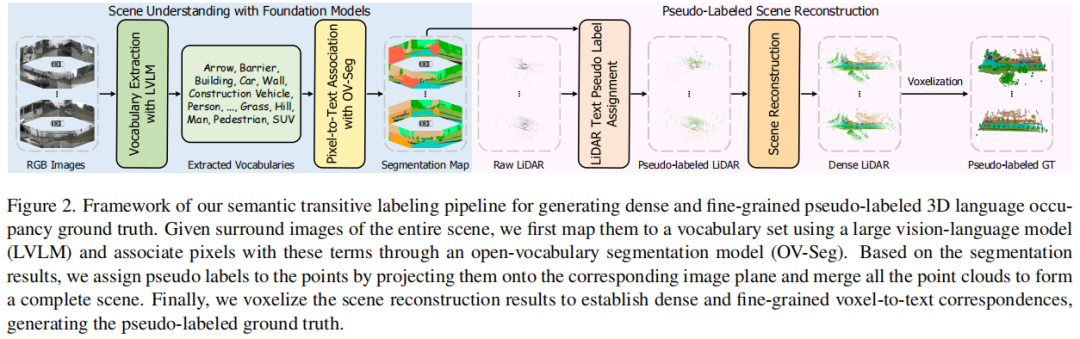
标题:Language Driven Occupancy Prediction
链接:https://arxiv.org/abs/2411.16072
主页:https://github.com/pkqbajng/LOcc
单位:浙江大学、菜鸟网络等
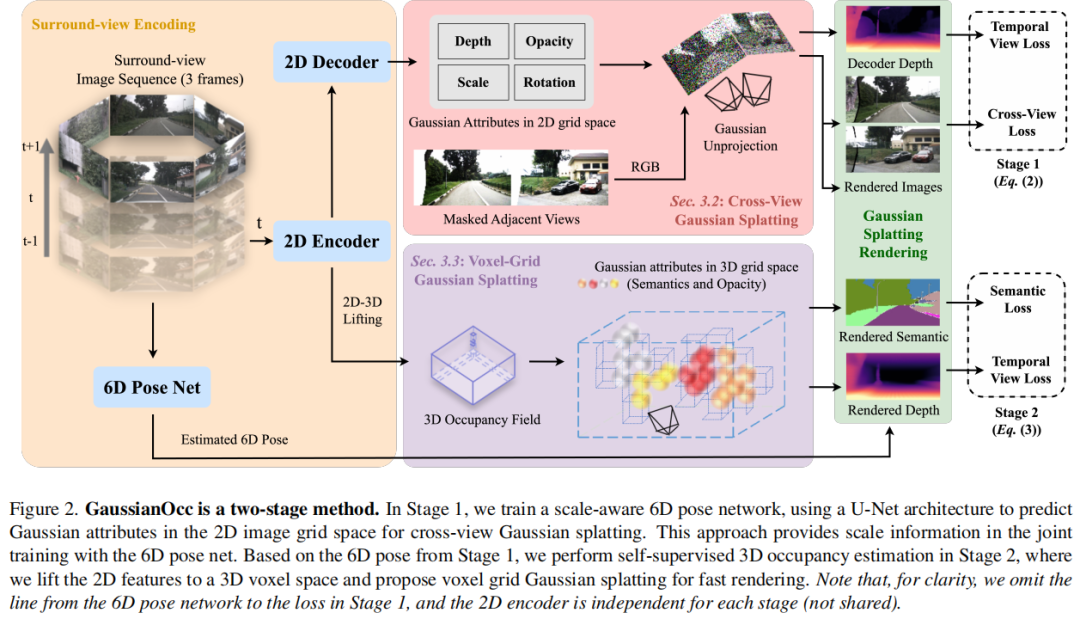
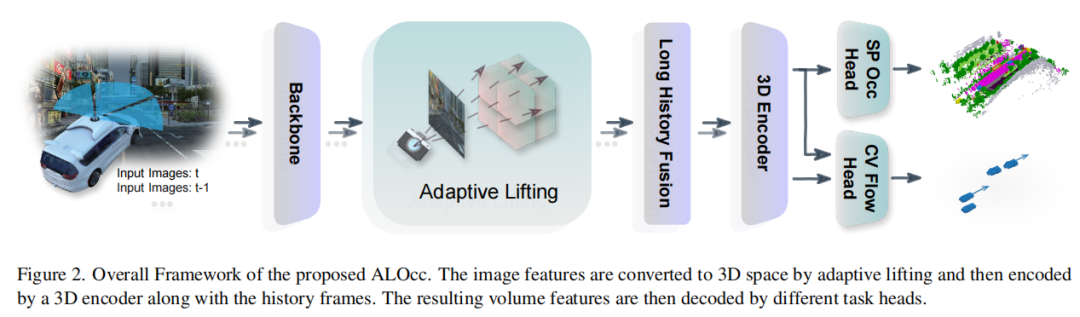
标题:ALOcc: Adaptive Lifting-based 3D Semantic Occupancy and Cost Volume-based Flow Prediction
链接:https://arxiv.org/abs/2411.07725
主页:https://github.com/cdb342/ALOcc
单位:澳门大学,阿卜杜拉国王科技大学
目标检测
标题:Perspective-Invariant 3D Object Detection
链接:https://arxiv.org/abs/2507.17665
主页:https://pi3det.github.io
单位:新加坡国立大学,复旦大学,中国科学院大学
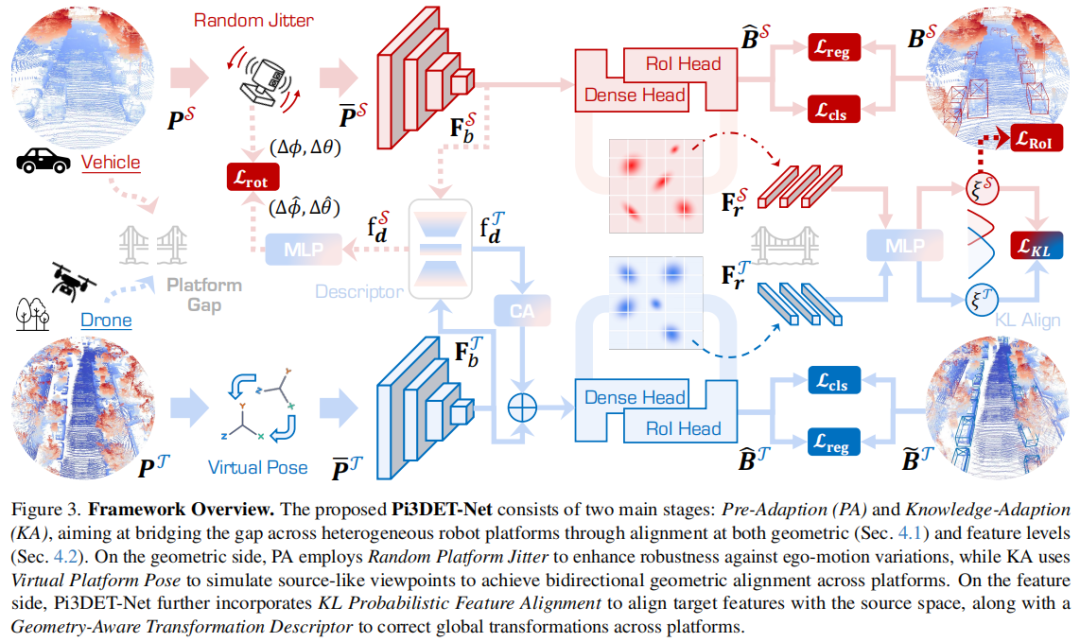
标题:SFUOD: Source-Free Unknown Object Detection
链接:https://arxiv.org/abs/2507.17373
主页:https://github.com/KU-VGI/SFUOD
单位:韩国庆熙大学,韩国高丽大学
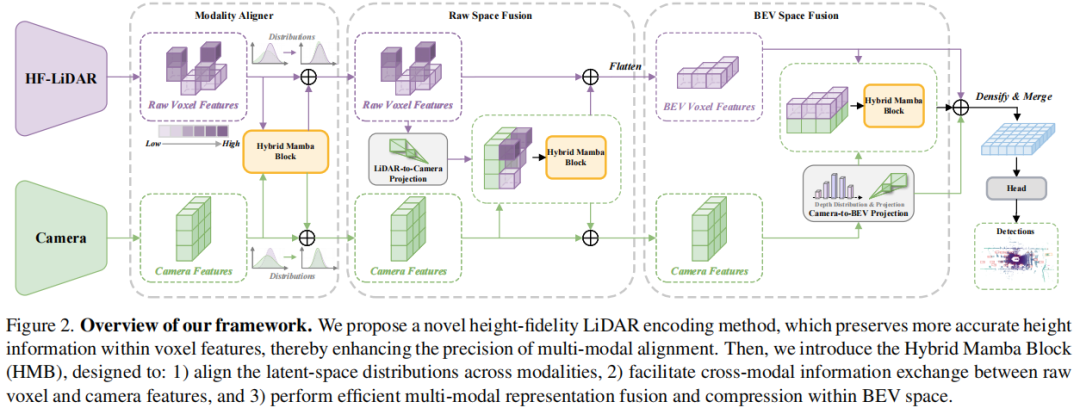
标题:MambaFusion: Height-Fidelity Dense Global Fusion for Multi-modal 3D Object Detection
链接:https://arxiv.org/abs/2507.04369
主页:https://github.com/AutoLab-SAI-SJTU/MambaFusion
单位:中国科学院自动化研究所、中国科学院大学、上海交通大学
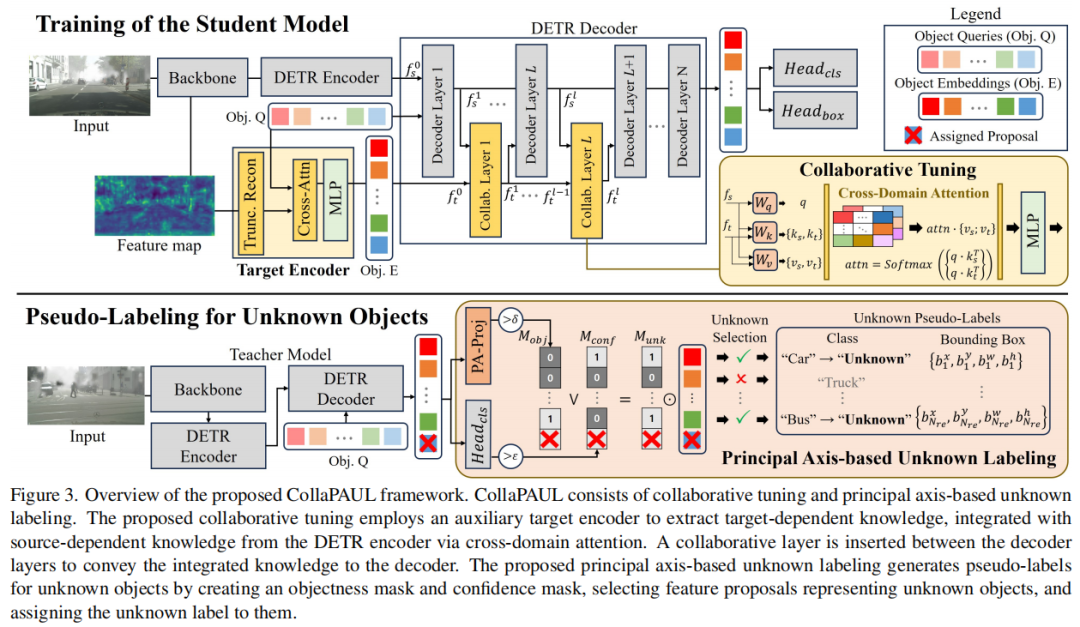
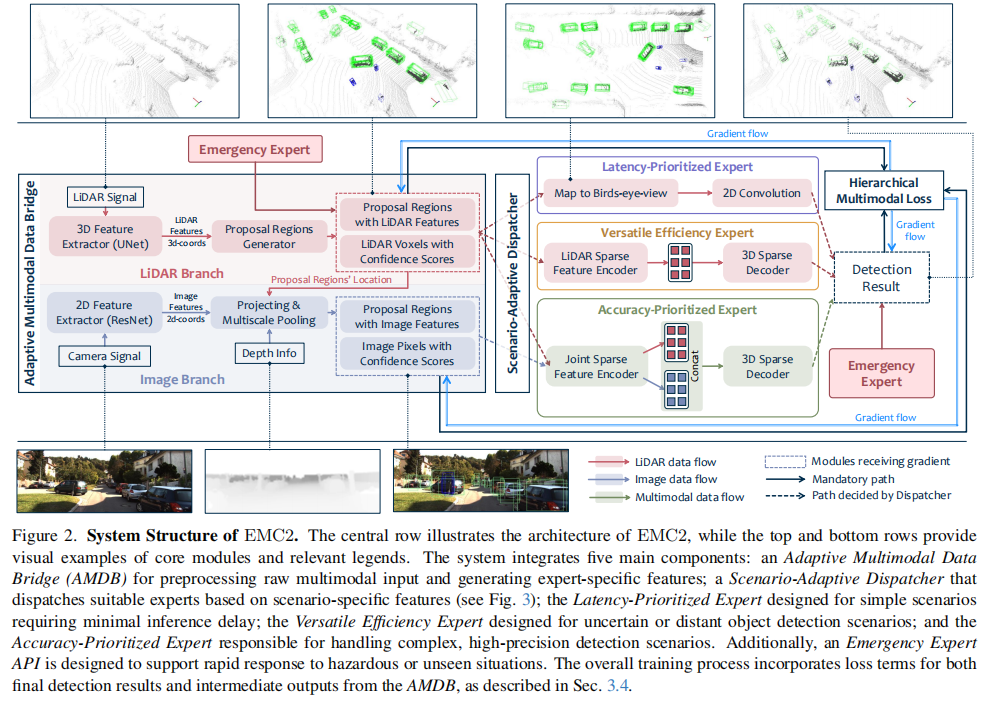
标题:Towards Accurate and Efficient 3D Object Detection for Autonomous Driving: A Mixture of Experts Computing System on Edge
链接:https://arxiv.org/abs/2507.04123
主页:https://github.com/LinshenLiu622/EMC2
单位:约翰霍普金斯大学,杜克大学,香港科技大学
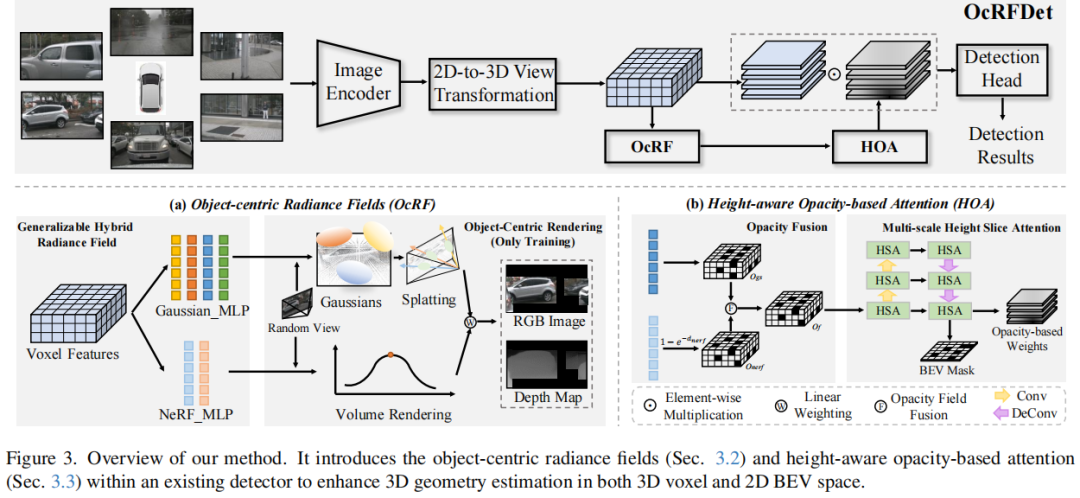
标题:OcRFDet: Object-Centric Radiance Fields for Multi-View 3D Object Detection in Autonomous Driving
链接:https://arxiv.org/abs/2506.23565
主页:https://github.com/Mingqj/OcRFDet
单位:南京理工大学
数据集
标题:ROADWork Dataset: Learning to Recognize, Observe, Analyze and Drive Through Work Zones
链接:https://arxiv.org/abs/2406.07661
主页:https://www.cs.cmu.edu/~ILIM/roadwork_dataset/
单位:卡内基梅隆大学

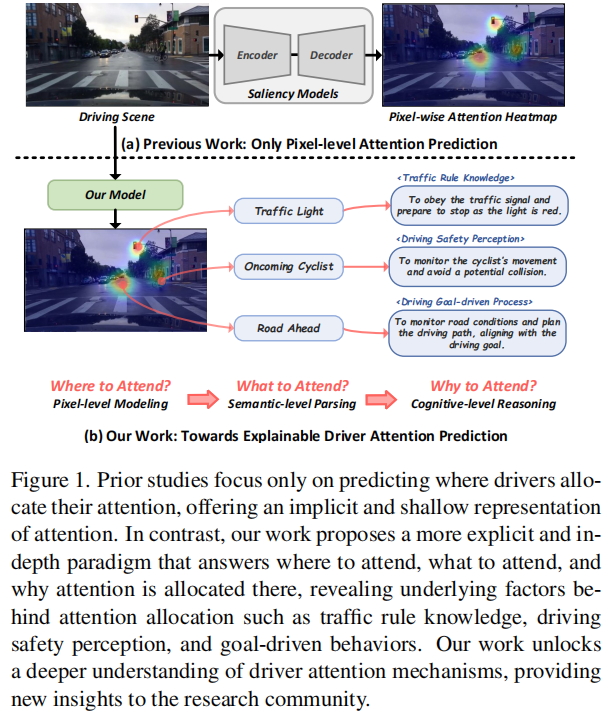
标题:Where, What, Why: Towards Explainable Driver Attention Prediction
链接:https://arxiv.org/abs/2506.23088
主页:ttps://github.com/yuchen2199/Explainable-Driver-Attention-Prediction
单位:中山大学,新加坡国立大学
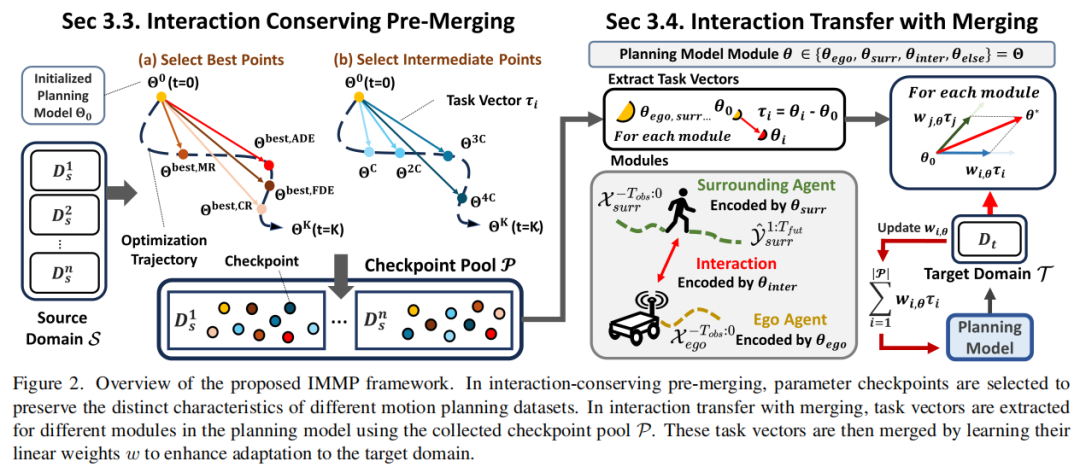
标题:Interaction-Merged Motion Planning: Effectively Leveraging Diverse Motion Datasets for Robust Planning
链接:https://arxiv.org/abs/2507.04790
单位:韩国科学技术院,DGIST
标题:ETA: Efficiency through Thinking Ahead, A Dual Approach to Self-Driving with Large Models
链接:https://arxiv.org/abs/2506.07725
主页:https://github.com/opendrivelab/ETA
单位:科奇大学,香港大学(中国)等
标题:Fine-Grained Evaluation of Large Vision-Language Models in Autonomous Driving
链接:https://arxiv.org/pdf/2503.21505
主页:https://github.com/Depth2World/VLADBench
单位:中国科学技术大学,华为诺亚方舟实验室,加州大学伯克利分校
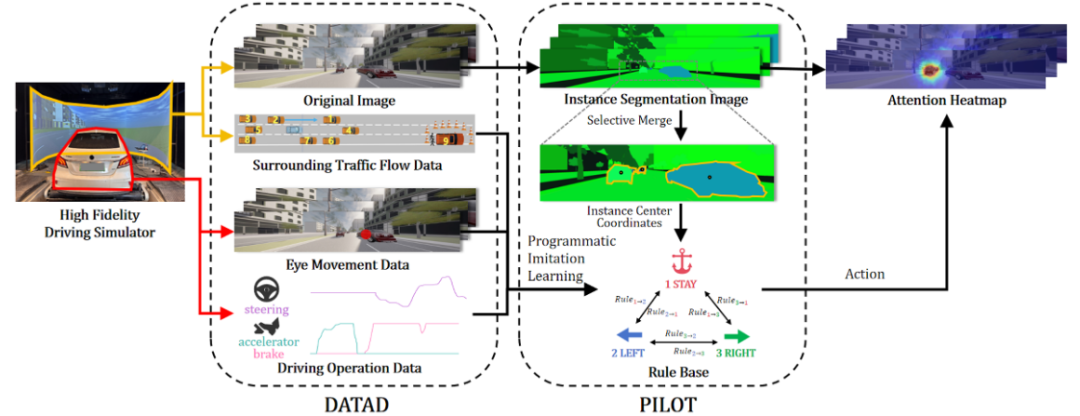
标题:DATAD: Driver Attention in Takeover of Autonomous Driving
主页:https://github.com/OOPartsfili/DATAD-driver-attention-in-takeover-of-autonomous-driving
其他
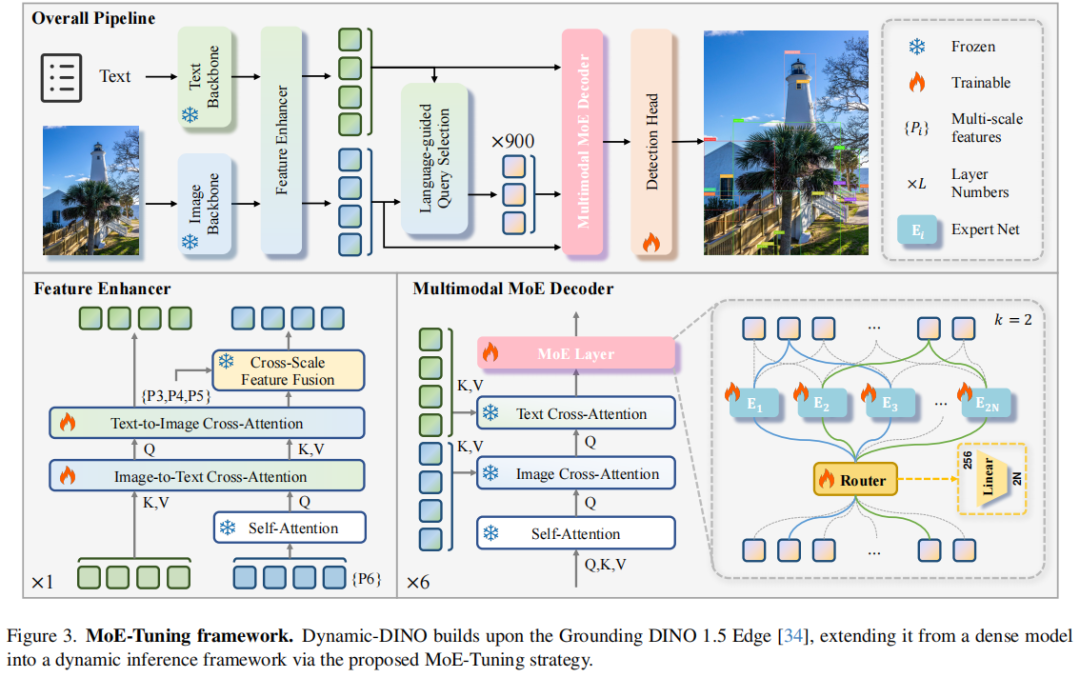
标题:Dynamic-DINO: Fine-Grained Mixture of Experts Tuning for Real-time Open-Vocabulary Object Detection
链接:https://arxiv.org/abs/2507.17436
单位:浙江大学,中兴通讯
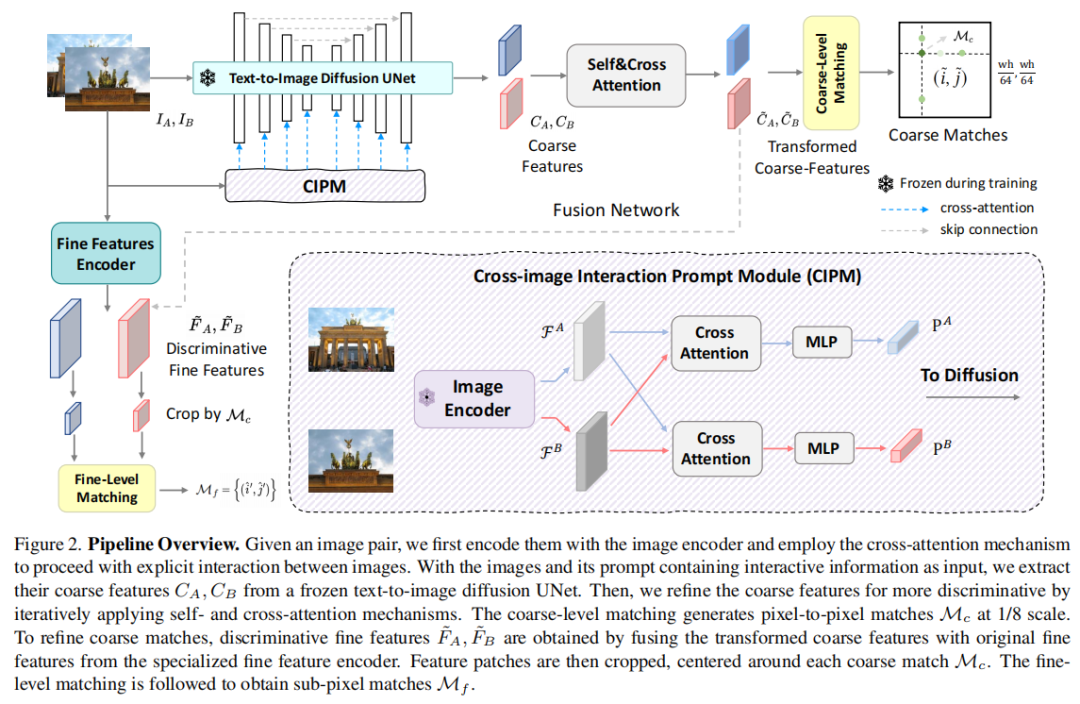
标题:Mind the Gap: Aligning Vision Foundation Models to Image Feature Matching
链接:https://arxiv.org/abs/2507.10318
单位:西安交通大学
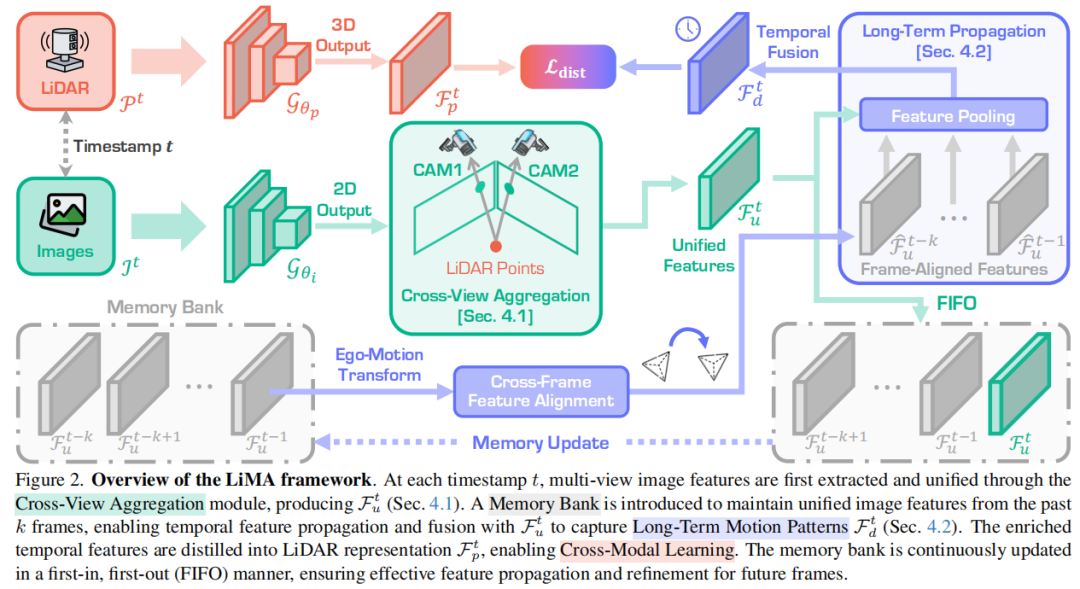
标题:Beyond One Shot, Beyond One Perspective: Cross-View and Long-Horizon Distillation for Better LiDAR Representations
链接:https://arxiv.org/abs/2507.05260
主页:http://github.com/Xiangxu-0103/LiMA
单位:新加坡国立大学&南京航空航天大学&浙大&南邮
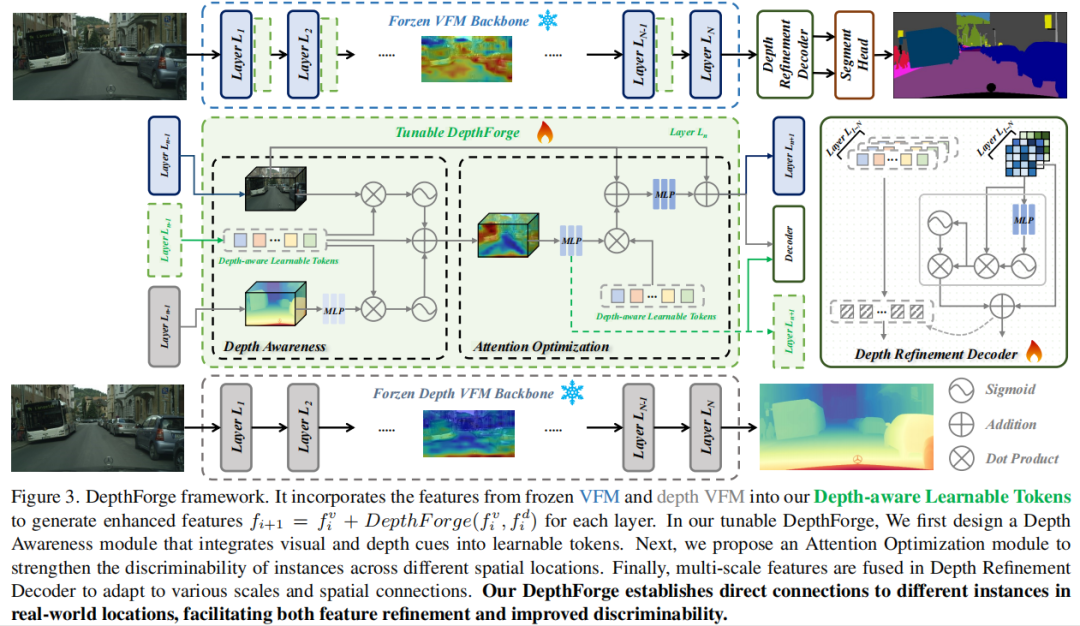
标题:Stronger, Steadier & Superior: Geometric Consistency in Depth VFM Forges Domain Generalized Semantic Segmentation
链接:https://arxiv.org/abs/2504.12753
主页:https://github.com/anonymouse-xzrptkvyqc/DepthForge
单位:集美大学,中山大学,西安电子科技大学等
更多内容欢迎加入自动驾驶之心知识星球,前沿技术、行业动态、求职问答!自动驾驶之心知识星球,作为国内最大的自驾技术社区,一直在给行业和个人输送各类人才、产业学术信息。目前累积了国内外几乎所有主流自驾公司和大多数知名研究机构。如果您需要第一时间了解产业、求职和行业痛点,欢迎加入我们。


















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









