







点击下方卡片,关注“自动驾驶之心”公众号
动机
激光雷达(LiDAR)因数据稀疏性,在检测如小物体或远距离目标时效果受限,而相机图像能提供丰富的纹理细节,二者优势互补。为此,我们提出 IAL(Image-Assists-LiDAR),实现高效的多模态3D全景分割。
核心亮点
🔥 端到端框架:无需复杂后处理,直接输出全景分割结果。 2. 🤖模态同步增强:首创通用的LiDAR与图像数据同步增强范式PieAug,提升训练效率与泛化性。
⚡精准特征融合:通过几何引导的 Token 融合 (GTF) 和先验驱动的 Query 生成 (PQG),实现 LiDAR-图像特征的精准对齐与互补。
🚀 更高精度:在nuScenes和SemanticKITTI上达到SOTA,性能远超同期方法
大会收录 | ICML 2025
论文标题 | How Do Images Align and Complement LiDAR? Towards a Harmonized Multi-modal 3D Panoptic Segmentation
论文链接 | https://arxiv.org/abs/2505.18956
工作单位|新加坡科技设计大学(SUTD)、新加坡科技研究局(A*STAR)
代码链接 | https://github.com/IMPL-Lab/IAL
方法创新
IAL三大核心技术突破:
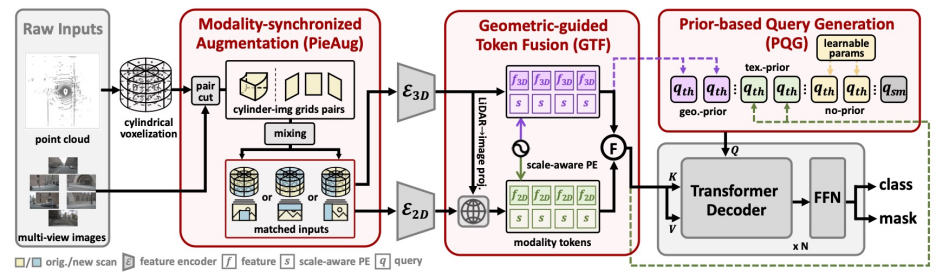
PieAug模态同步增强
问题与发现:现有多模态分割方法仍采用仅在LiDAR端进行数据增强的策略,导致增强后的LiDAR点云与相机图像数据出现严重不对齐,直接影响多模态特征融合效果。
解决方案
"切蛋糕"策略:将场景沿角度和高度轴切割为扇形切片,获得多组配对的点云和多视角图像单元
混合增强:通过不同组合模式混合原场景和新场景,组合模式包括实例级(图2(a))和场景级(图2(b&c))。
显著优势:PieAug策略很好地兼容如LaserMix/PolarMix等现有LiDAR-only的增强方法,同时实现跨模态对齐

GTF特征融合模块
通过物理点投影实现图像特征精准聚合,避免虚拟中心点导致的偏差
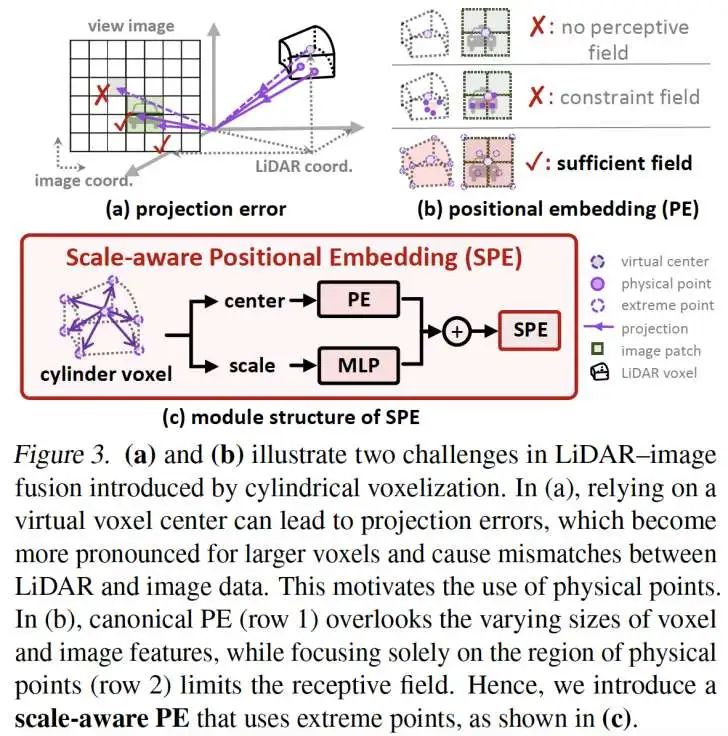
基于圆柱体素的8个极值点构建尺度感知位置编码(Scale-aware Positional Embedding,如图3(c)所示)
基于体素级的投影会导致点云和图像表示存在显著的位置偏差,尤其在大尺寸体素情况下这个偏差会导致错误的语义表达(如图3(a)所示)
传统方法忽视不同传感器数据的感受野差异,严重制约特征表达能力(如图3(b)所示)
问题与发现
解决方案
PQG查询初始化
传统可学习query容易陷入“简单样本”局部最优,对于远距小目标物体的召回率低。
单一传感器先验难以覆盖复杂场景需求
问题与发现
解决方案 - 三重查询生成机制:
几何先验query:对于3D特征显著的物体,通过BEV热力图预测其中心位置
纹理先验query:通过2D VFM (Grounding-DINO和SAM)生成2D掩码,提升小物体召回率
无先验query:我们认为那些没有明显3D和2D先验特征的物体,其特征表达遵循一定潜在规律,因此可以使用可学习参数的query来补充,实现困难样本检测。
实验结果
模型性能
IAL在nuScenes-Panoptic 官方榜单第一,刷新户外 3D 全景分割纪录。
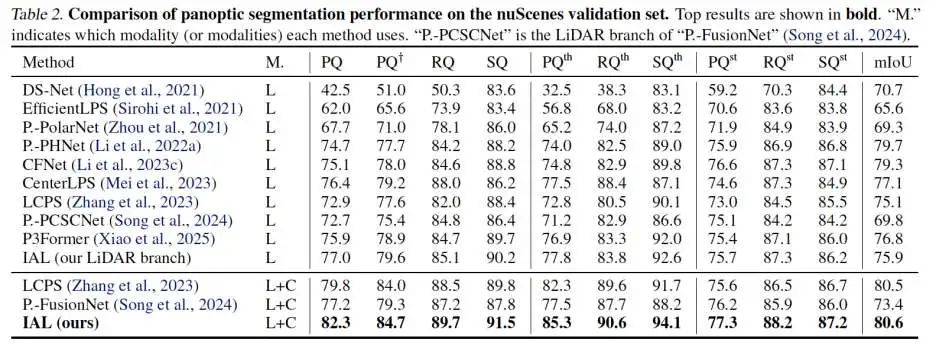
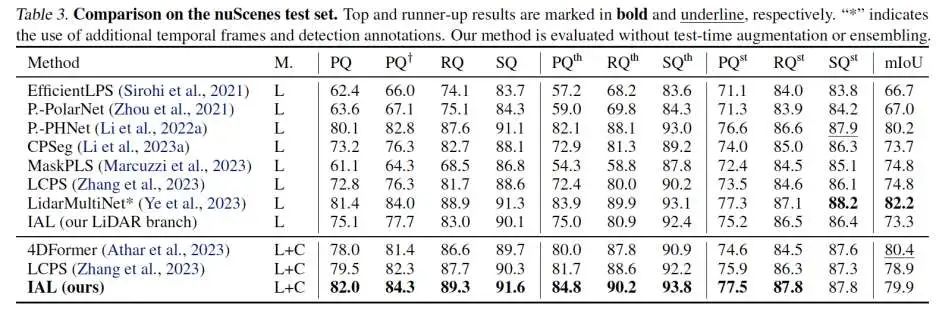
验证集 SOTA:在 nuScenes 与 SemanticKITTI 验证集同时取得当前最高 PQ。
对比近期代表性方法 LCPS 与 Panoptic-FusionNet,PQ 最高提升 5.1%。
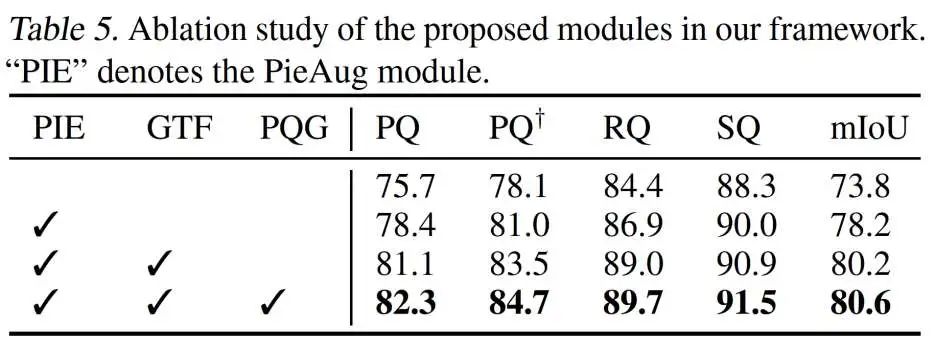
关键模块消融实验
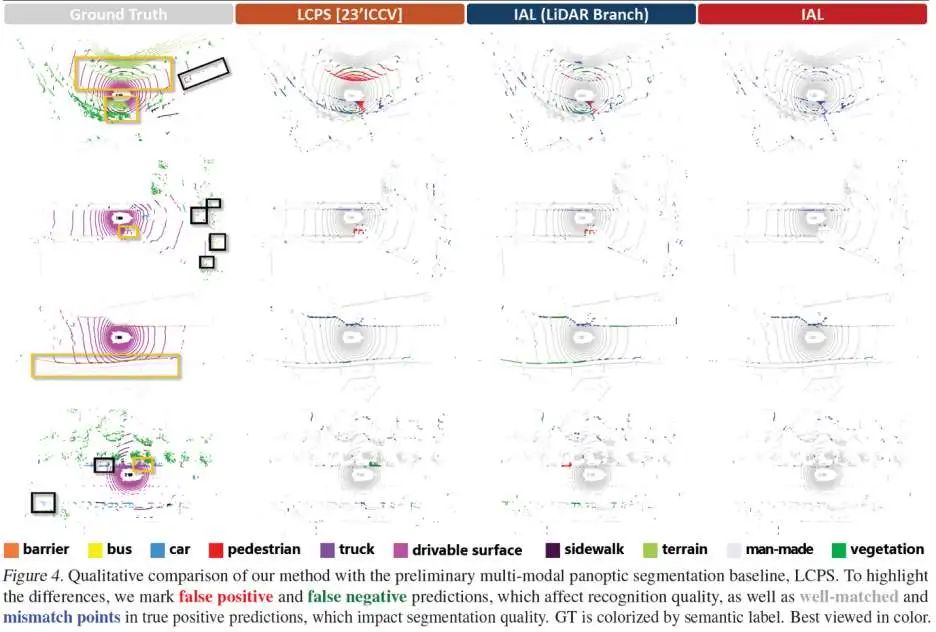
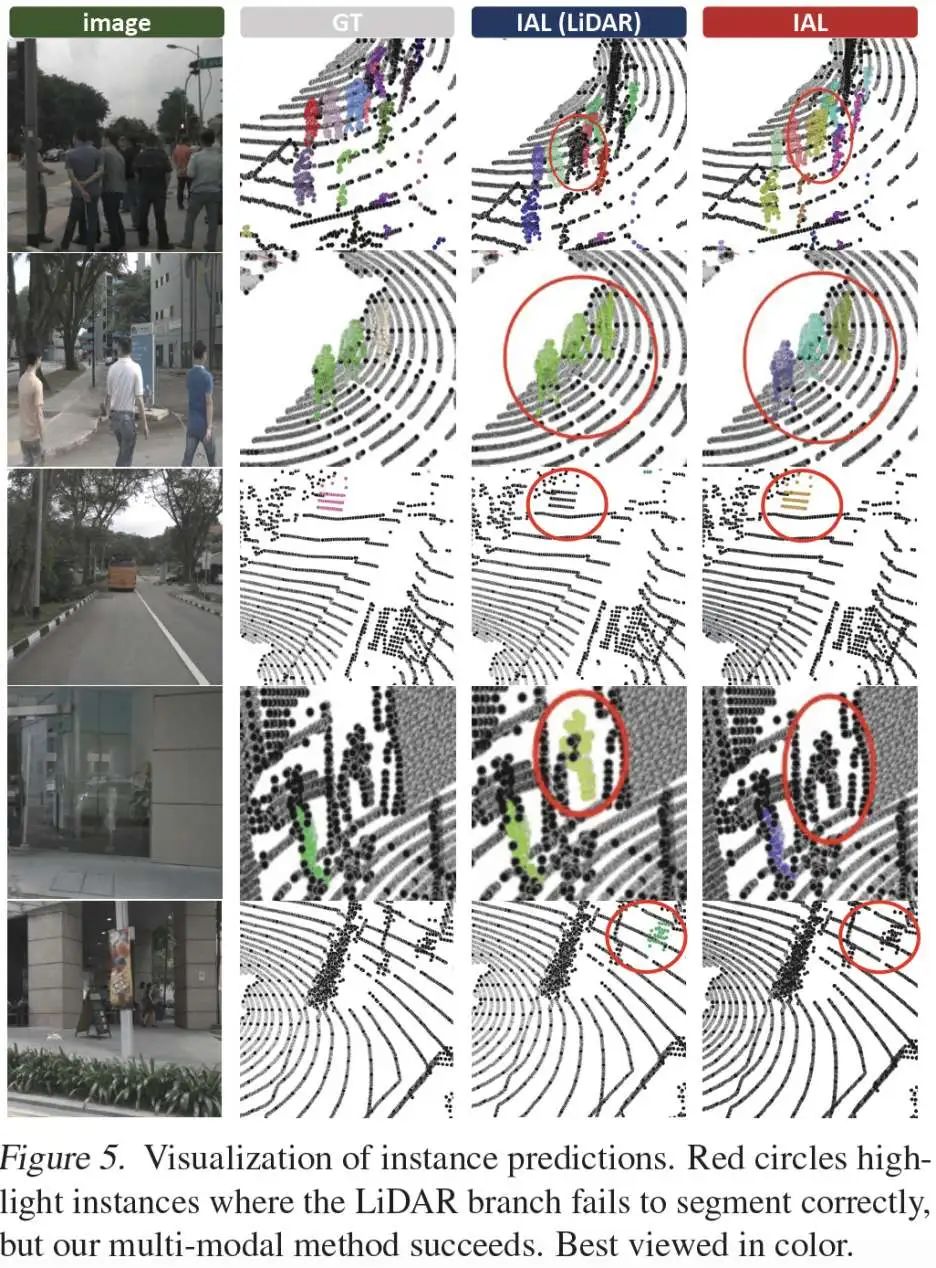
可视化结果:图4为全景分割误差图,图5为结果可视化。IAL 在以下方面表现出显著提升:
区分紧邻目标;
检测远距目标;
识别假阳性(FP)和假阴性(FN)目标。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









