



点击下方卡片,关注“大模型之心Tech”公众号
今天大模型之心Tech为大家分享一篇中科院自动化所的大模型相关新工作。本文聚焦于大型视觉语言模型(LVLMs)的高效集成问题,提出了一种名为内部特征调制注入(FMI) 的全新范式,并基于此开发了高效模型LaVi。如果您有相关工作需要分享,请在文末联系我们!
本文只做学术分享,如有侵权,联系删文
论文标题:LaVi: Efficient Large Vision-Language Models via Internal Feature Modulation
论文作者:Tongtian Yue等
论文链接:https://arxiv.org/pdf/2506.16691
研究动机:破解LVLM的集成困局
1.1 研究背景与现有技术局限
近年来,大型语言模型(LLMs)如GPT、LLaMA的突破推动了大型视觉语言模型(LVLMs)的发展,像LLaVA、BLIP等模型在视觉理解和认知推理任务中展现出强大能力。但当前LVLMs在视觉与语言的高效集成方面存在根本性瓶颈,主要体现在两种主流方法的缺陷上:
架构注入法:早期的视觉语言集成方法,如 Flamingo 模型采用的架构注入策略,通过在语言模型内部插入跨注意力层、前馈网络等额外模块,强制视觉特征与语言处理路径交互。这种方法如同在精密钟表内部添加非原厂零件,虽然能实现视觉信息的显式融合,却破坏了语言模型原有的架构连贯性与处理流程。其直接后果是预训练积累的语言理解能力受损,模型丢失了编码在语言模型中的丰富语义先验知识,就像一个精通多门语言的专家因脑部手术丧失了部分记忆。
上下文注入法:当前主流的上下文注入方法,如 LLaVA 系列采用的技术路线,将视觉特征转化为Token序列后直接拼接到文本输入中。这种方式看似保留了语言模型的架构完整性,却引发了严重的效率危机。以 CLIP 模型处理单张 336像素 图像为例,需生成 576 个视觉Token,而自注意力机制的二次复杂度特性(计算量随序列长度平方增长)导致模型在处理高分辨率图像或长视频时,计算量呈指数级飙升。就如同向只能处理小流量数据的管道中强行注入洪水,最终导致推理延迟剧增,无法满足实时应用需求。
1.2 理想集成策略的两大原则
通过分析现有方法,作者提出高效集成需满足的核心原则:
最小结构干扰:确保预训练语言知识的保留,支持连贯的文本生成和基于视觉的理解推理。这就好比对经典发动机进行升级时,需确保不改变其核心机械结构,以维持原有的动力性能。只有这样,模型才能在获得视觉能力的同时,保持连贯的文本生成与语言推理能力,避免 "捡了芝麻丢了西瓜" 的尴尬局面。
计算可扩展性:避免处理大量视觉Token时的二次复杂度问题,实现高效的视觉信息整合。传统方法中,视觉Token数量的增加会导致计算复杂度呈二次增长,如同老旧计算机无法处理高清视频。而理想的策略应具备线性或近似线性的计算复杂度,使模型能高效处理高分辨率图像与长视频序列,为自动驾驶、实时视频分析等对延迟敏感的场景提供技术可能。
LaVi核心贡献
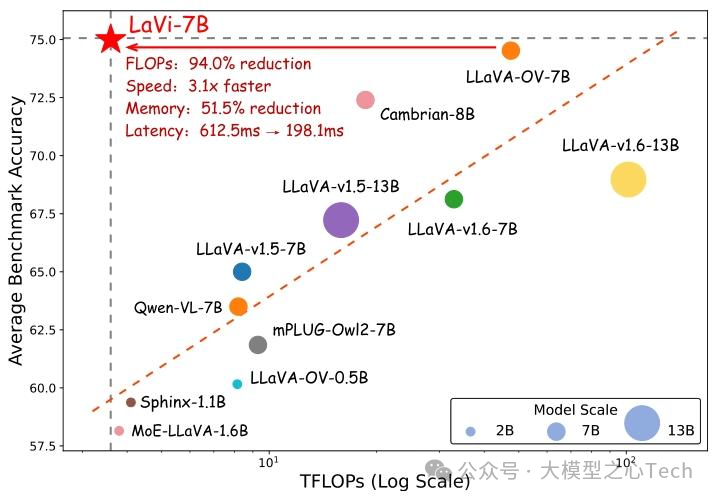
图1. 训练过程中使用和不使用我们的Ground-V数据集的LISA和PSALM模型的性能对比。纳入Ground-V始终能提升这两种模型在各基准上的性能,在六个基准上,就gIoU指标而言,LISA平均提升4.4%,PSALM平均提升7.9%。
提出全新集成范式
本文突破传统"外部拼接"或"结构修改"的思维定式,首次提出"内部特征调制注入(FMI)"的创新范式。这一思路摒弃了添加额外模块或扩展输入序列的做法,转而利用语言模型中基础组件的特性,从内部实现视觉信息对语言表征的动态调制,如同为模型安装了"智能调节系统",在不改变核心架构的前提下实现多模态融合。
设计轻量级模块ViLN
基于层归一化(LN)机制,研究者开发出"视觉注入层归一化(ViLN)"模块。该模块如同为LN装上"视觉传感器",通过视觉条件化的参数增量动态调整语言特征,既避免了传统方法中长序列带来的计算爆炸问题,又能细粒度地对齐视觉与语言表征。
构建高效模型LaVi
基于上述创新,研究者构建了LaVi模型,在15个图像与视频基准测试中实现"效率-性能"双突破:不仅达到当前最优性能(state-of-the-art),还在计算效率上大幅超越同类模型。例如,LaVi-7B在参数规模相同的情况下,FLOPs消耗比LLaVA-OV-7B减少94%,却能保持基准准确率持平甚至更高,为自动驾驶、实时视频分析等对延迟敏感的场景提供了切实可行的解决方案。

LaVi的方法论:从原理到架构设计
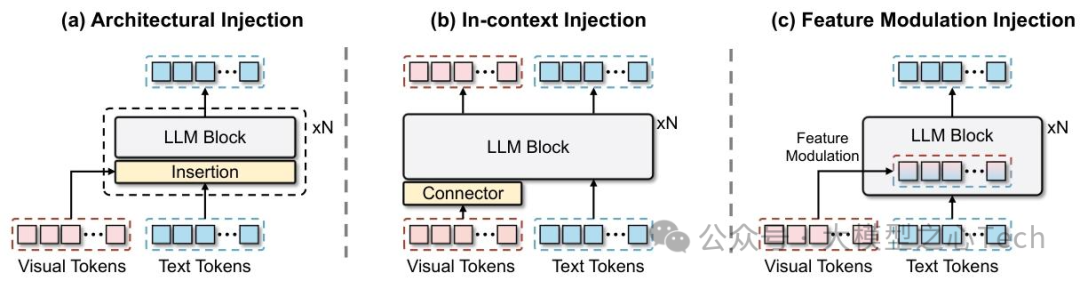
图2:大型视觉语言模型(LVLMs)中各种视觉集成技术的比较。(a)架构注入:在大型语言模型(LLM)中插入额外层以进行跨模态交互;(b)上下文注入:将视觉Token连接到文本序列之前作为初始上下文;(c)特征调制注入(我们的方法):内部隐藏状态通过视觉引导的仿射变换进行调制。
1. 视觉-语言集成策略的对比与选择
现有集成方法的形式化分析
架构注入:如公式所示,通过插入跨模态交互模块Φₗ,在LLM的每一层处理中显式融合视觉特征v和文本隐藏状态Hₗ:
这种方法破坏了原LLM的前向传播流程,导致语言能力退化。
上下文注入:将视觉Tokenv与文本序列t拼接作为初始输入,依赖LLM的自注意力处理跨模态交互:
但自注意力的二次复杂度(O(L²),L为序列长度)使视觉Token激增时计算量爆炸。
特征调制注入(FMI)的优势
FMI的核心是利用LN模块的仿射变换特性,将视觉信息转化为LN参数的增量。标准LN的计算式为:
其中α和β是可学习的仿射参数。FMI在此基础上引入视觉条件化增量Δαᵥ和Δβᵥ,得到ViLN:
这种设计有两大优势:
轻量级集成:无需添加新层或扩展序列,仅通过参数增量调制现有隐藏状态。
语言先验保留:初始时Δαᵥ和Δβᵥ为零,保证训练初期模型行为与原LLM一致,避免语言能力损失。
2. LaVi的整体架构与关键模块

图3:整体模型架构示意图。对于配备ViLN的LLM模块,视觉和文本特征被输入到条件模块中以获取Token级的视觉条件。这些条件通过轻量级MLP转换为缩放和平移参数,用于调制LLM的内部语言特征。
架构概览
LaVi的核心是将LLM中的部分LN层替换为ViLN模块,并通过条件模块生成视觉条件。整体流程如下:
视觉特征v经编码器提取后,与文本Tokent一同输入条件模块。
条件模块生成每个文本Token对应的视觉条件,通过轻量级MLP映射为Δαᵥ和Δβᵥ。
ViLN利用这些增量调整LN的仿射参数,实现视觉对语言表征的动态调制。
条件模块的三种实现方式
条件模块需为每个文本Token生成专属的视觉条件,我们设计了三种灵活实现:
MLP-based Conditioning:受MLP-Mixer启发,通过Token混合MLP和通道混合MLP处理文本-视觉拼接序列,提取Token级视觉信息。
Conv-based Conditioning:将拼接序列视为1D信号,通过深度卷积和点卷积混合空间与通道信息,适合捕捉局部视觉关联。
Attention-based Conditioning:以文本Token为查询,视觉Token为键和值,通过交叉注意力直接聚合相关视觉上下文,默认采用此方法以平衡效率与性能。
可扩展视觉输入处理
针对高分辨率图像和视频,LaVi采用策略:
高分辨率图像:分块编码,将图像划分为非重叠块,各块独立编码后拼接Token。
视频处理:均匀采样k帧,每帧编码后经2×2自适应池化,添加时间位置编码以捕捉时序动态。
3. FMI的数学本质与优势分析
FMI通过乘法(Δαᵥ)和加法(Δβᵥ)操作调制隐藏状态,本质是在特征空间中对语言表征进行视觉引导的自适应变换。与现有方法相比:
计算复杂度:不增加自注意力序列长度,计算量与视觉Token数量解耦,避免O(L²)问题。
表征对齐:直接在LLM内部特征层实现视觉-语言对齐,比架构注入更贴近语言处理核心路径。
训练稳定性:零初始化的增量映射确保模型可从纯语言能力平滑过渡到多模态能力。
实验
一、实验设置与模型训练细节
模型配置:
为验证LaVi的有效性,研究团队训练了三种模型变体:基础图像理解模型LaVi-Image、支持高分辨率图像的LaVi-Image(HD),以及同时处理图像和视频的全能模型LaVi。
视觉编码器与LLM骨干的搭配参考LLaVA系列:LaVi-Image采用CLIP ViT-L/336px与Vicuna-7B;LaVi与LaVi-Image(HD)则使用SigLIP ViT-SO400M和Qwen2-7B,确保对比实验的公平性。
训练流程:
采用两阶段训练范式:先预训练条件模块,再进行指令微调。
数据集方面,预训练使用CC12M中的800万高分辨率图像,微调分别采用LLaVA-665K、LLaVA-760K等指令数据集。
评估基准:
覆盖9个图像理解任务(如VQA-v2、GQA、ScienceQA等)和6个视频理解任务(包括EgoSchema、MVBench、Video-ChatGPT等)。
性能指标同时关注计算效率(FLOPs、延迟)和任务准确率。
二、图像理解任务实验结果
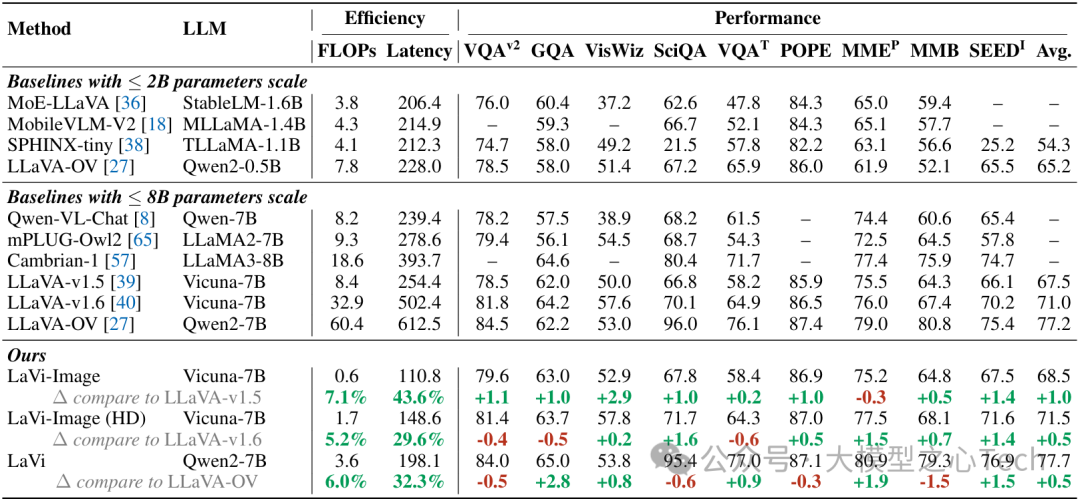
表1:9个基于图像的基准测试的性能,包括VQA-v2、GQA、VisWiz、ScienceQA、TextVQA、POPE、MME、MMBench和(SEED ^{I})。对于(MME^{P}),分数以百分比表示。除了效率和准确性,我们还报告了每个基线的LLM主干。
效率与性能平衡:
与同参数规模的LLaVA系列模型相比,LaVi的FLOPs消耗降低14-19倍:LaVi-Image相比LLaVA-v1.5减少92.9%的FLOPs,推理延迟从254.4ms降至110.8ms。
尽管计算量大幅减少,LaVi在图像基准上的平均准确率仍实现1.0%~1.4%的提升,如LaVi-Image在VQA-v2上达到79.6%,超越LLaVA-v1.5的78.5%。
高分辨率扩展性:
LaVi-Image(HD)处理高分辨率图像时,FLOPs仅为LLaVA-v1.6的5.2%,但平均准确率达到71.5%,接近LLaVA-v1.6的71.0%。
这表明LaVi通过动态分块策略,有效解决了高分辨率图像带来的计算瓶颈问题。
三、视频理解任务实验结果
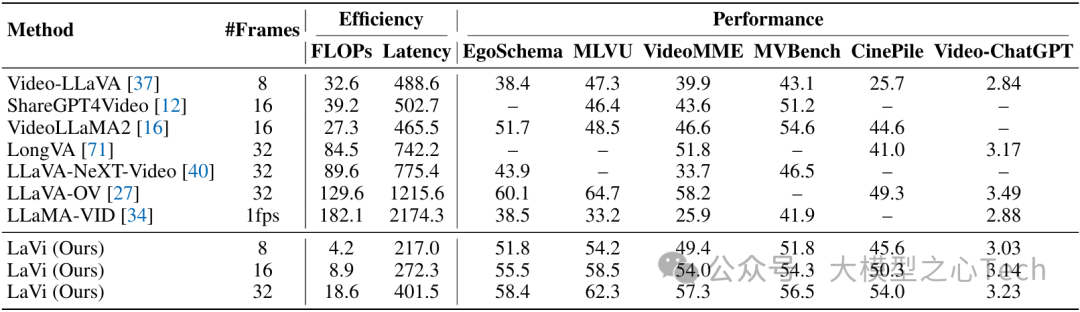
表2:6个基于视频的基准测试的性能,包括EgoSchema、MLVU、VideoMME、MVBench、CinePile和Video-ChatGPT。除了计算效率和准确性指标外,我们还报告了每个视频的采样帧数。
长视频处理优势:
在32帧视频输入下,LaVi的FLOPs仅为LLaVA-OV的14.4%(18.6T vs 129.6T),延迟从1215.6ms降至401.5ms,同时在VideoMME等任务上准确率提升3-5个百分点。
当处理128帧长视频时,LaVi相比Video-LLaVA节省92.0%的FLOPs和61.1%的内存,展现出对长时间序列的卓越可扩展性。
多帧采样鲁棒性:
即使仅采样8帧,LaVi在EgoSchema任务上的准确率(51.8%)也超越了Video-LLaVA在8帧下的表现(38.4%),证明其能高效利用有限视觉信息完成推理。
四、消融实验与机制分析
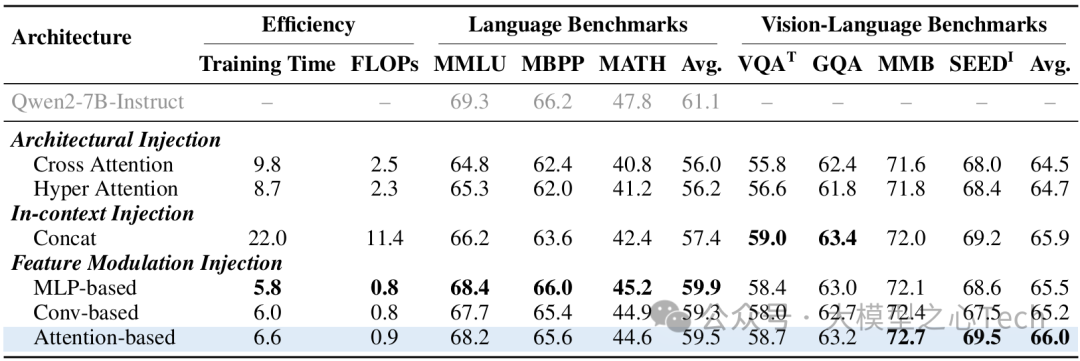
表4:在相同数据和主干设置下集成技术的比较。我们呈现了总训练时长(时间)、推理期间的浮点运算次数(FLOPs),以及三个纯语言基准和四个视觉-语言任务的准确性结果。
集成策略对比:
通过与架构注入(交叉注意力)、上下文注入(拼接视觉Token)对比,发现LaVi的特征调制注入(FMI)在语言保留能力上优势显著:在MMLU语言基准上,FMI的性能(59.5%)比上下文注入(57.4%)高2.1个百分点,且训练时间减少70%。
可视化结果显示,LaVi的隐藏状态与原始LLM的余弦距离最小,证明其对语言先验的破坏最小。
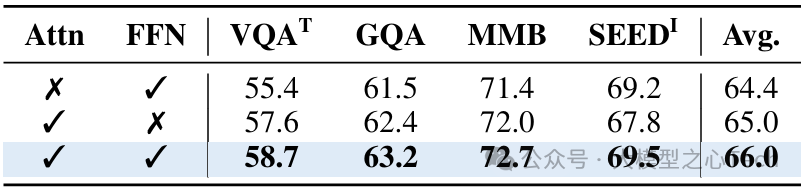
表3:调制不同子层的效果。
将视觉信息注入到两个子层时可获得最佳结果。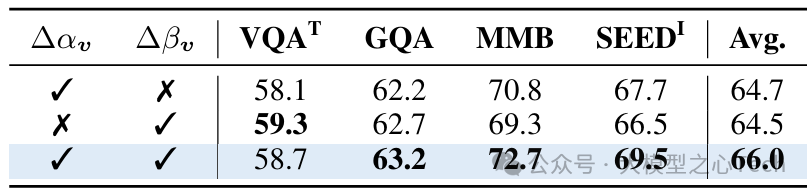
表5:调制参数的效果。每个参数通过相应的操作增强视觉信息集成。
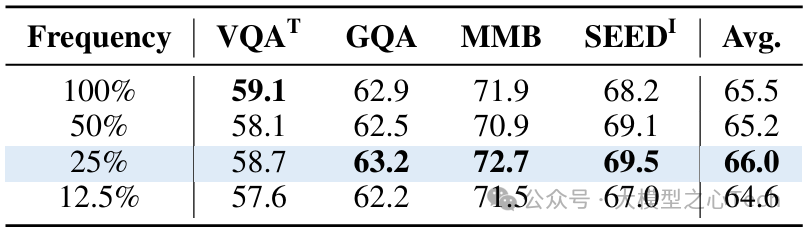
表6:调制频率的影响。以中等频率应用ViLN可获得最佳平均性能。
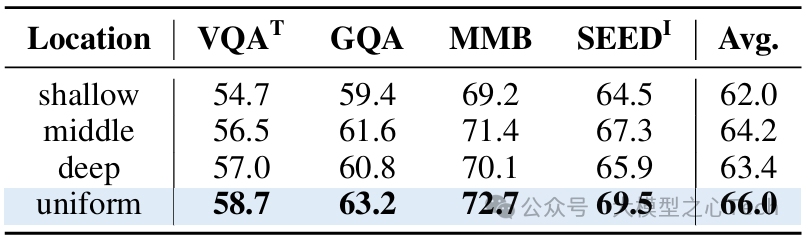
表7:调制位置的影响。将ViLN均匀分布在各层可实现更有效的多模态集成。
调制机制优化:
子层影响:同时调制自注意力和前馈子层时性能最优,其中自注意力子层的调制对跨模态对齐影响更大(单独调制自注意力时平均准确率达65.0%)。
调制频率与位置:选择25%的层进行均匀调制效果最佳,过度调制(100%层)反而导致性能下降1.5%。
参数重要性:缩放参数Δα和偏移参数Δβ对性能提升贡献相当,同时使用时平均准确率比单独使用高1.5%-2.0%。
五、可视化与深层分析
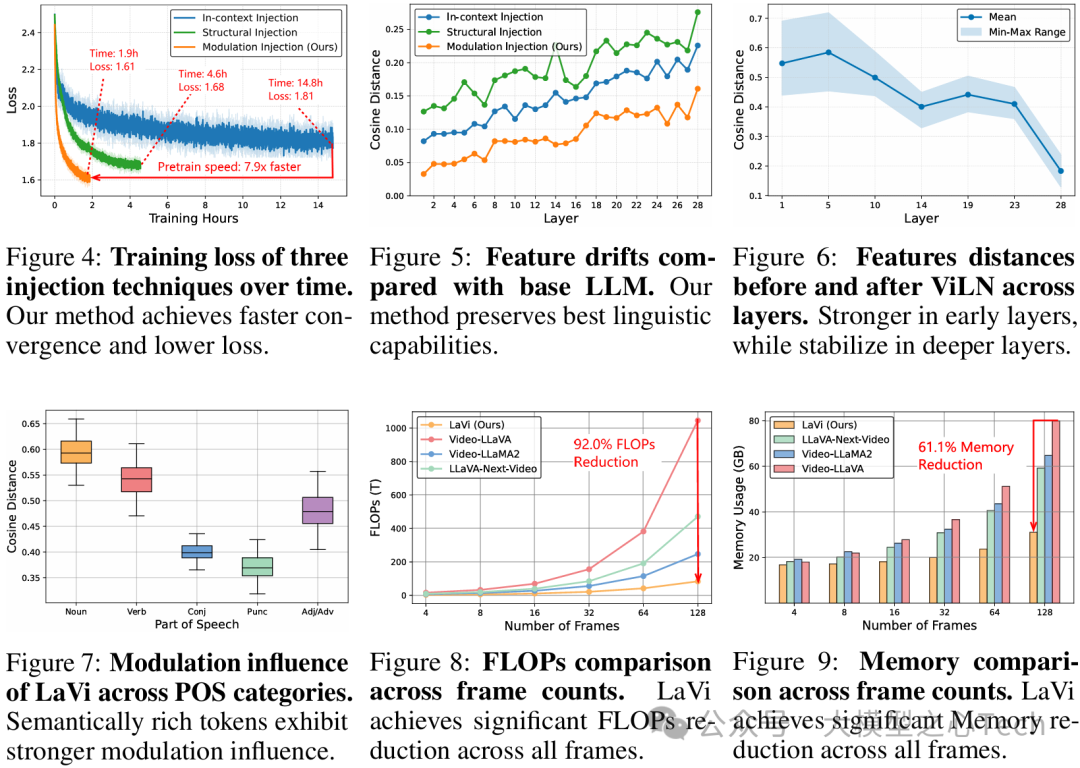
语言能力保留验证:
通过对比隐藏状态与原始LLM的特征漂移(图5),LaVi的余弦距离始终低于架构注入和上下文注入方法,证明其"最小结构干扰"设计的有效性。
调制影响分布:
早期LLM层的调制影响更强(图6),浅层特征的余弦距离变化达0.5,而深层趋于稳定,表明模型在早期层完成跨模态对齐,深层进行语义整合。
语义丰富的词汇(名词、动词)受到的调制更强(图7),如名词的余弦距离比标点符号高0.2,符合"视觉信息优先对齐关键语义"的直觉。
序列长度扩展性:
随着视频帧数增加,LaVi的FLOPs增长呈近似线性(图8),而基线模型呈二次增长,当处理128帧时,LaVi的计算量仅为Video-LLaVA的8.0%。
总结
在这项工作中,作者为LVLM提出了一种新颖的内部特征调制注入范式,通过避免过度的上下文扩展来确保最小的结构干扰和卓越的计算可扩展性。基于此范式,开发了LaVi,一种高效的LVLM,利用视觉注入层归一化(ViLN)实现精确的视觉-语言对齐,同时大幅降低计算成本。与LLaVA风格的模型相比,LaVi的浮点运算量(FLOP)减少了94.0%,运行速度快3.1倍,延迟显著降低,使其成为视觉-语言集成的高效替代方案。
知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,欢迎扫码加入一起学习一起卷!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









