



点击下方卡片,关注“具身智能之心”公众号
作者丨Enshen Zhou等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
研究背景与问题提出
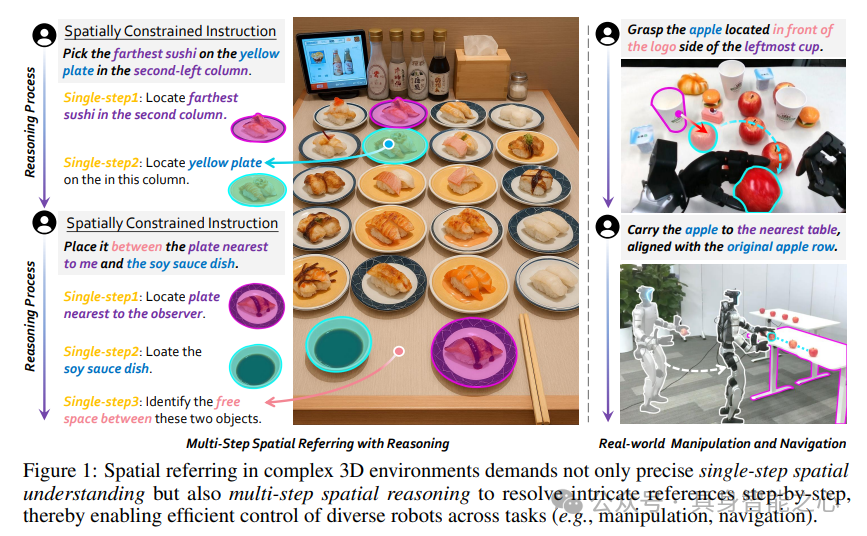
在机器人与三维物理世界的交互中,空间指代表达(Spatial Referring)是实现智能操控的核心能力。机器人需要理解如"抓取位于最左侧杯子标志面正前方的苹果"这类包含复杂空间约束的指令,并在动态场景中定位目标位置。尽管预训练视觉语言模型(VLMs)已展现出强大的跨模态理解能力,但现有方法在处理三维场景时仍存在两大局限:一是缺乏对深度信息的有效整合,二是难以应对多步空间推理任务。
当前多数研究集中于单步空间理解,如识别物体的相对位置或距离,但对"先定位最近的桌子,再将苹果沿原行列对齐放置"这类需要多阶段推理的任务支持不足。此外,现有模型在处理三维输入时面临两难:要么依赖昂贵的多视图三维重建导致模态差异,要么将深度作为RGB类似输入处理,造成模态干扰。同时,缺乏大规模多步推理数据集和专用评估基准,严重制约了模型在复杂空间任务中的发展。
核心方法与模型设计
RoboRefer架构创新
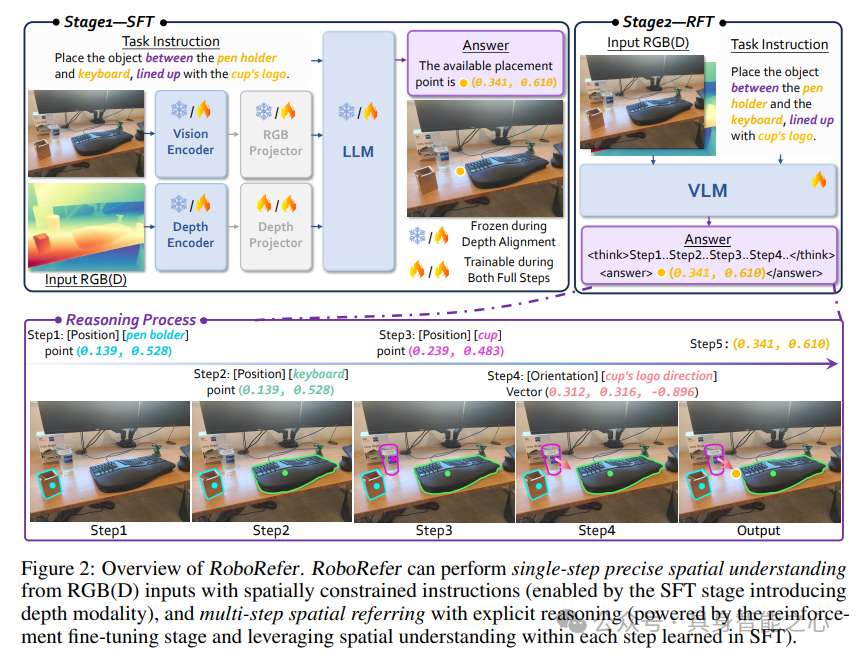
RoboRefer作为首个支持三维感知与多步推理的VLM,其架构设计突破传统模型局限:
双模态独立编码器
采用分离的RGB和深度编码器,避免共享编码器导致的模态干扰。深度编码器基于SigLIP模型初始化,专门处理深度图中的距离、远近关系等三维线索,在保留RGB编码器预训练能力的同时,增强三维空间感知精度。这种设计确保深度信息不会干扰RGB分支的视觉理解,同时通过独立优化提升三维线索的提取能力。
SFT+RFT两阶段训练
监督微调(SFT):首先通过深度对齐训练投影层,将深度特征映射至语言空间,确保深度模态与语言空间的语义一致性;再利用RefSpatial数据集联合优化RGB和深度分支,提升单步空间理解能力。这一阶段着重让模型掌握基础的空间感知能力。
强化微调(RFT):引入组相对策略优化(GRPO),设计度量敏感的过程奖励函数,引导模型分解复杂任务为有序推理步骤。通过强化学习,模型能够学习如何将多步空间推理任务拆解为可处理的中间步骤,逐步提升推理能力。
点预测任务formulation
将空间指认转化为图像空间的2D点预测(x,y),相比传统边界框方法更适合机器人操控。该设计可自然映射至三维坐标,支持导航、抓取等下游任务,为机器人的精准操作提供了基础。
RefSpatial数据集与基准构建
为支撑模型训练与评估,研究团队构建了:
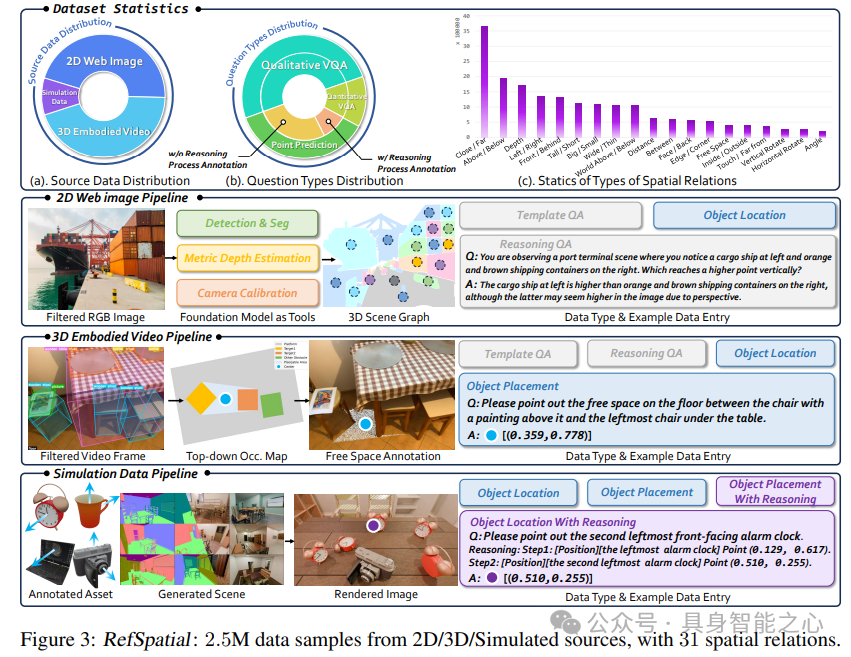
大规模多源数据集RefSpatial
规模:250万样本,2000万问答对,较之前数据集翻倍,为模型训练提供了充足的数据支撑。
多样性:包含31种空间关系(如前后、远近、旋转角度),支持最多5步推理过程,覆盖了机器人在实际应用中可能遇到的各种空间关系场景。
数据来源:
2D网络图像:通过伪三维场景图生成空间概念,帮助模型建立初步的空间认知。
3D具身视频:从CA-1M提取精细室内空间关系,提升模型对真实室内环境的理解。
模拟场景:使用Infinigen生成可控推理数据,便于设计复杂的多步推理任务。
多步推理基准RefSpatial-Bench
包含200张真实场景图像,70%样本需3-5步推理,标注有精确掩码。其中77个样本包含训练中未见的空间关系组合,专门测试模型泛化能力,填补了多步空间推理评估的空白。
强化学习与奖励机制设计
在RFT阶段,通过四类奖励函数引导推理过程,确保模型能够逐步优化推理步骤:
结果奖励
格式奖励(R_OF):要求推理步骤遵循"感知类型"格式,确保输出结构化,便于模型学习正确的推理流程和表达方式。
点L1奖励(R_P):预测点与真实点距离<50像素时获满分,量化定位精度,直接衡量模型的空间定位能力。
过程奖励
精度奖励(R_Acc):对关键步骤的位置(L1距离)、方向(余弦相似度>0.8)、尺寸(±15%误差)进行度量,确保模型在每一步推理中都能保持较高的精度。
流程奖励(R_PF):强制中间结果包含感知类型标注,如"Position: (0.341, 0.610)",帮助模型明确推理过程中的每一步操作和目标。
组合奖励函数为 ,通过组内奖励归一化计算相对优势,避免梯度偏差,使模型能够在训练过程中不断优化推理策略。
实验结果与性能分析
单步空间理解能力
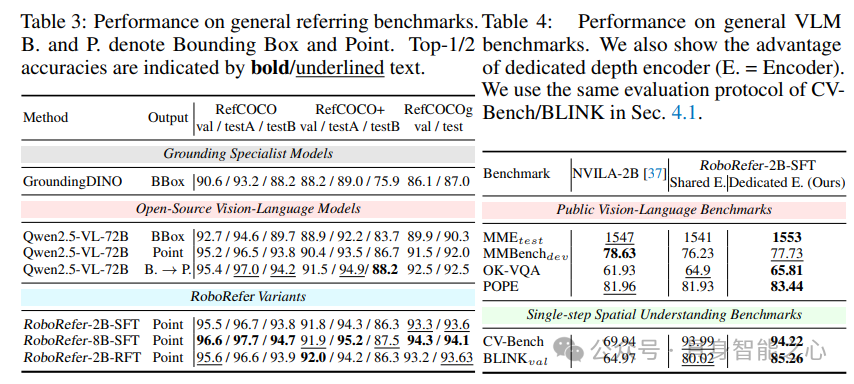
在CV-Bench、BLINK等基准测试中,RoboRefer-SFT展现出显著优势,证明了其在基础空间感知任务上的强大能力:

深度信息增益:使用RGB-D输入时,3D深度任务准确率提升7.33%,证明独立深度编码器的有效性。深度信息的加入显著提升了模型对三维空间的理解能力,使其能够更准确地处理与深度相关的任务。
模型规模优势:8B参数模型较2B版本在复杂任务上平均提升3.2%,体现参数量对空间推理的增益。更大的模型规模能够捕捉更复杂的空间特征和关系,进一步提升模型性能。
多步空间推理性能
在RefSpatial-Bench上,RoboRefer-RFT大幅超越基线模型,展示了其在多步推理任务中的卓越能力:
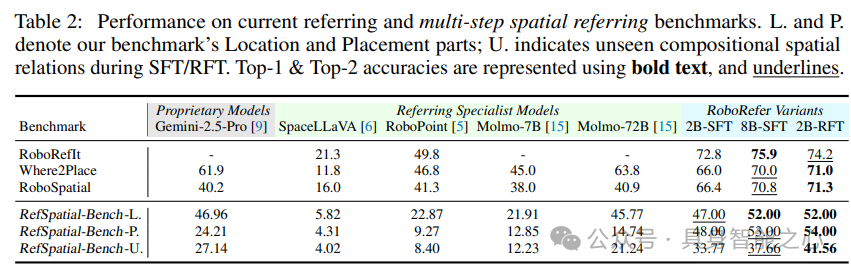
推理步骤优势:在5步推理任务中,RFT模型比SFT版本提升9.1%,证明强化学习对多阶段推理的有效性。通过强化学习,模型能够更好地处理多步骤、复杂的空间推理任务,逐步逼近正确结果。
泛化能力验证:对训练中未见过的空间关系组合,2B-RFT模型准确率达41.56%,超出Gemini-14.4%。这表明模型具有较强的泛化能力,能够应对训练中未接触过的新场景和关系组合。

真实机器人应用
RoboRefer在模拟器与实体机器人上展现实用价值,为其实际应用奠定了基础:
模拟环境表现
在Open6DOR V2基准中,RoboRefer成功率达79.2%,较SoFar提升6.8%,且执行时间缩短27.5%,证明模型效率优势。这意味着模型不仅能够准确完成任务,还能在效率上满足实际应用的需求。
实体机器人实验
UR5机械臂:完成"拾取离相机最近杯子附近的汉堡并放置在泰迪熊前"任务,成功率80%。该实验展示了模型在实际机械臂操控中的应用能力,能够指导机械臂完成复杂的抓取和放置任务。
G1人形机器人:在动态环境中执行"沿苹果原行列对齐放置"任务,支持移动操作与环境适应。这表明模型能够适应不同类型的机器人,并在动态环境中保持良好的性能。
参考
[1] RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics
论文辅导计划

具身智能干货社区
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1500人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、VLA、VLN、具身大脑、具身小脑、大模型、视觉语言模型、强化学习、Diffusion Policy、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近30+学习路线、40+开源项目、近60+具身智能相关数据集。

全栈技术交流群
具身智能之心是国内首个面向具身智能领域的开发者社区,聚焦大模型、视觉语言导航、VLA、机械臂抓取、Diffusion Policy、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、机器人仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









