 基于RL的多模态大语言模型推理综述
基于RL的多模态大语言模型推理综述




作者 | 欠阿贝尔两块钱 来源 | AIGC面面观
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『多模态大模型』技术交流群
本文只做学术分享,如有侵权,联系删文
背景
本文提供了基于RL的MLLMs推理方法的全面和系统的回顾,提供了技术进步、方法论、实际应用和未来方向的结构化分析。涵盖了算法策略、奖励机制和基准评估。
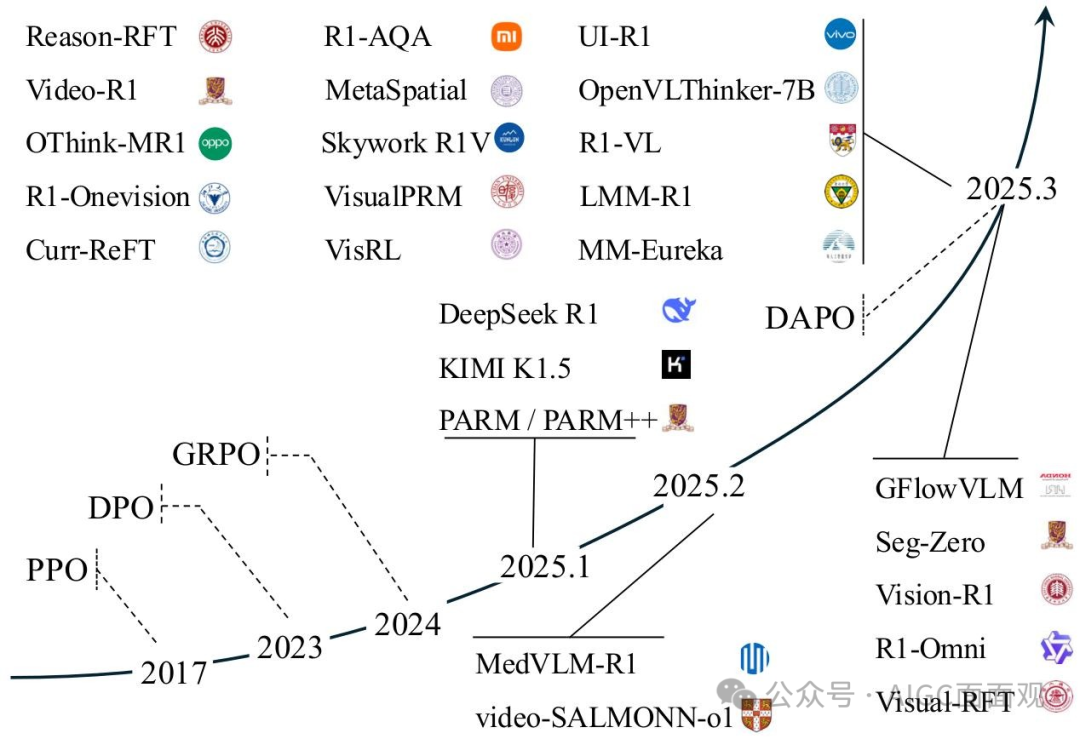
一、多模态大语言模型和强化学习
1.多模态大语言模型(MLLMS)
把llm和其他模态的模型图像、音频和视频等各种模型结合,处理多模态信息,利用 LLMs 作为核心认知引擎,通过其他模态的基础模型通过为非文本数据提供高质量表示,支持各种多模态任务。
2.多模态链式推理(MM-COT)
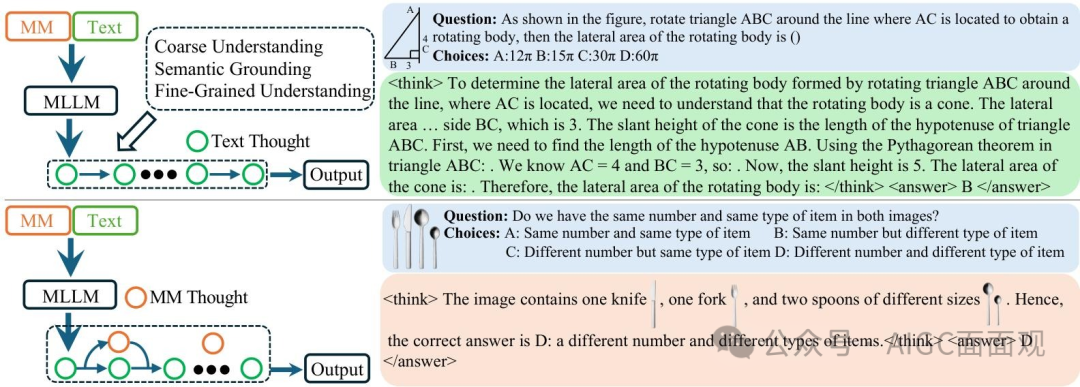
Chain-of-Thought:模型在得出最终答案 𝐴 之前生成中间推理步骤
。在多模态推理任务的背景下,给定一个提示
和查询
,每个推理步骤
从 MLLM M 中采样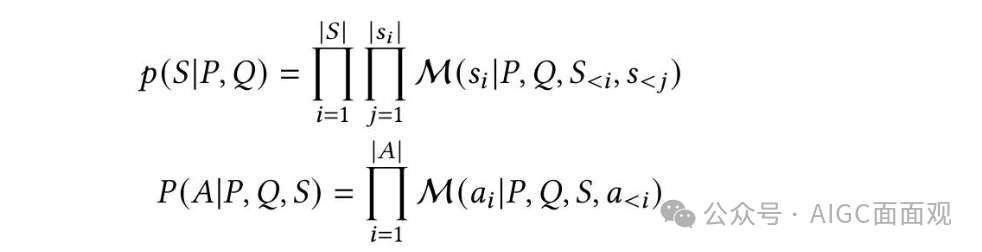
多模态CoT (MM-CoT) 在 , , 和 中不同程度地融入多模态信息
一种仅依赖语言信息
另一种则整合了超出文本内容的多模态信号
MM-CoT的目标:通过逐步推理解决复杂问题,同时在推理过程中融入多模态信息。
二、强化学习
1.策略优化
近端策略优化(PPO)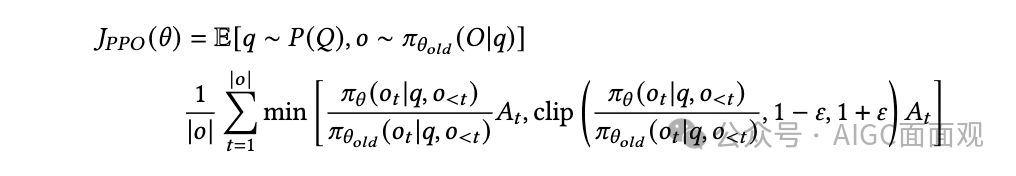
和 分别表示当前和旧的策略模型
和 分别表示从问题数据集中采样的问题和由旧策略 生成的输出。
超参数 通过引入剪裁机制在稳定训练中起着关键作用。
使用广义优势估计(GAE)计算,表示基于奖励模型 𝑅 和可学习的评论者模型的优势函数。
特点: PPO 中,策略模型和评估模型必须同时进行训练,当模型参数或 token 数量较大时,这会带来巨大的计算需求
REINFORCE Leave-One-Out (RLOO)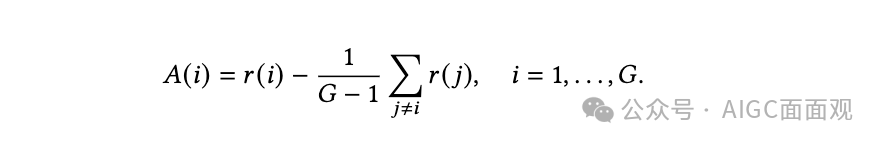 省略了 critic模型和GAE的使用,而是直接采用蒙特卡洛方法来计算基线。
省略了 critic模型和GAE的使用,而是直接采用蒙特卡洛方法来计算基线。
对于每个查询
,模型生成
个响应
并为每个响应计算一个得分
。RLOO 使用留一法基线来减少策略梯度估计中的方差。
特点:放弃了PPO中使用的token级奖励,而是完全依赖于序列级奖励。
Group Relative Policy Optimization (GRPO)
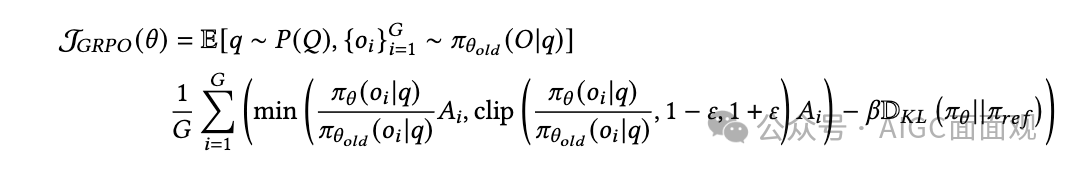
和 是超参数
是每个组内相对奖励得出的优势
是用于计算 KL 散度的参考模型。
GRPO 的核心思想是评估组内多个候选响应的相对质量。对于一个问题 ,GRPO 使用 生成 个不同的响应 ,并计算它们的奖励
特点:减少了对外部Criti模型的依赖,还提高了模型区分高质量和低质量输出的能力,缓解了生成长链自我反思和纠正(CoT)时的硬件限制。
2.奖励机制
结果奖励机制(ORM)
根据任务的最终状态或整个过程中累积的总奖励来评估策略的表现。
奖励仅基于答案的正确性,而不考虑模型的中间推理行为。问题:奖励信号的稀疏性和延迟性可能导致训练过程中的样本效率低下和梯度更新不稳定。过程奖励机制(PRM)
PRM 重视在推理过程中评估模型的中间行为,从而鼓励逐步形成连贯且逻辑合理的 CoT。
特点:过程级别的机制提供更细粒度的监督,有助于更有效地调试和对齐模型行为。然而,过程奖励的设计高度依赖于中间推理步骤的准确评估。
3.训练效率
课程强化学习:通过引入结构化的任务进程,从较简单的子任务开始,逐步过渡到更复杂的任务。实现更快的收敛和在挑战性任务上的性能提升。数据高效学习:旨在以最少的数据最大化性能。通过优先采样 和选取高质量样本。减少不必要的计算开销的同时更有效地学习。
三、RL算法在LLMs/MLLMs中的关键设计与优化
1.Value-Free
通过消除价值模型计算,无价值函数的强化学习,在如长推理(long-CoT)等复杂任务中高度成功。可能会遇到熵塌陷和奖励噪声的问题。GRPO(Group Relative Policy Optimization)核心思想:通过比较生成的响应组来优化模型,避免了复杂的价值模型训练。
挑战:熵崩溃和奖励噪声,可能导致模型生成低质量的输出。
优化策略:引入动态采样机制,避免梯度信号消失;采用token-level策略梯度损失,确保长序列中的每个token都能公平地贡献梯度。DAPO(Dynamic Asymmetric Policy Optimization)\
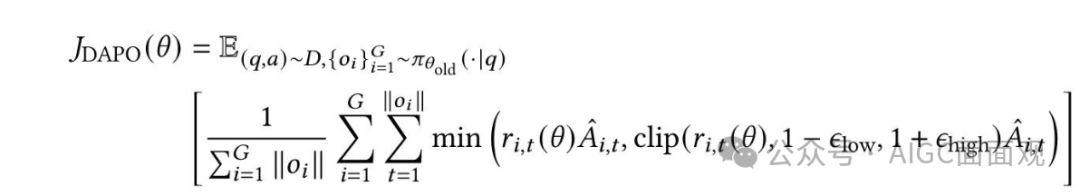 Clip-Higher策略:将裁剪边界解耦为
和
。这种非对称的裁剪策略显著
Clip-Higher策略:将裁剪边界解耦为
和
。这种非对称的裁剪策略显著增强了低概率token的探索,同时避免了高概率token的过度压缩。动态采样:过滤掉准确率为0或1的样本,该策略确保每个批次都包含具有有效梯度信号的样本。Token-Level策略梯度损失:确保较长序列中的 tokens 贡献的梯度更加公平,从而避免对质量较低的长样本过度惩罚。过长奖励塑形:Overlong Reward Shaping 策略实施了一个渐进的长度依赖惩罚系统,该系统在调整截断输出的奖励的同时,通过与响应长度成比例的惩罚来抑制过度冗长。特点:显著减少了奖励噪声的影响,稳定了训练过程。核心思想:在GRPO的基础上,引入非对称裁剪策略、动态采样机制、token-level策略梯度损失和过长奖励塑形(overlong reward shaping)。Dr.GRPO(Debiased Group Relative Policy Optimization)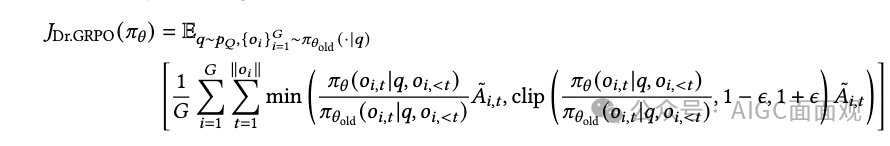 移除长度归一化:移除了归一化项
,这避免了
移除长度归一化:移除了归一化项
,这避免了对较长错误响应的偏好,并防止模型生成越来越长的错误。移除标准差归一化:消除了归一化项
,这样去除了问题难度偏差,确保了在优化过程中不同难度的问题具有相同的权重。核心思想:通过移除GRPO中的长度偏差和问题难度偏差,提高模型权重分配的公平性和稳定性。CPPO(Completion Pruning Policy Optimization)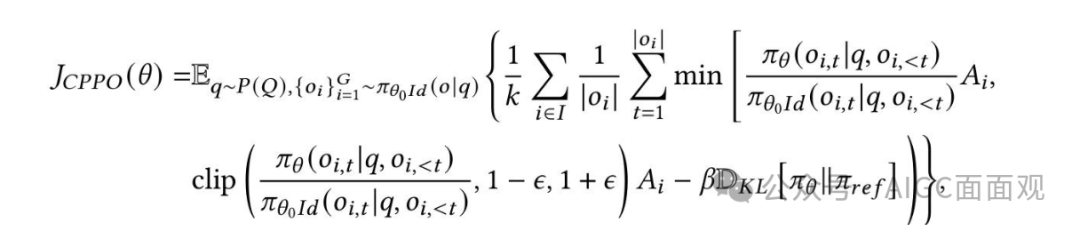 ,意味着只有具有最高绝对优势值的前
个完成被保留用于梯度更新 CPPO 的目标函数在 GRPO 的基础上加入了剪枝条件。剪枝策略:仅保留绝对优势值最高的前 𝑘 个完成用于梯度更新,剪枝其余部分以减少冗余计算。动态分配策略:CPPO将
,意味着只有具有最高绝对优势值的前
个完成被保留用于梯度更新 CPPO 的目标函数在 GRPO 的基础上加入了剪枝条件。剪枝策略:仅保留绝对优势值最高的前 𝑘 个完成用于梯度更新,剪枝其余部分以减少冗余计算。动态分配策略:CPPO将剩余的剪枝完成与新查询的高质量完成相结合,填充GPU处理管道。提高GPU的利用率。核心思想:通过剪枝策略减少计算开销,动态分配计算资源。
2.Value-Based
与基于蒙特卡洛估计的无价值方法不同,基于价值的方法提供了低方差的逐标记估计,并通过泛化实现了更好的样本效率。
PPO(Proximal Policy Optimization)
1.Open-Reasoner-Zero:使用原始的 PPO 算法结合 和简单的基于规则的奖励函数。显著提高响应长度和基准性能。
2.VC-PPO:为了使传统的强化学习算法如 PPO 能够处理长链思考(CoT)任务,引入价值初始化偏差和 Decoupled-GAE。价值初始化偏差:通过在固定策略下离线训练值模型,并使用广义优势估计(GAE)且 𝜆= 1.0 以确保无偏的回报,值模型能够实现对预期奖励的更准确估计。
Decoupled-GAE:通过解耦策略和价值优化的𝜆值来解决RLHF中不同的方差减少需求价值模型以减少偏差的方式估计预期回报,而策略模型通过减少方差来加速收敛。
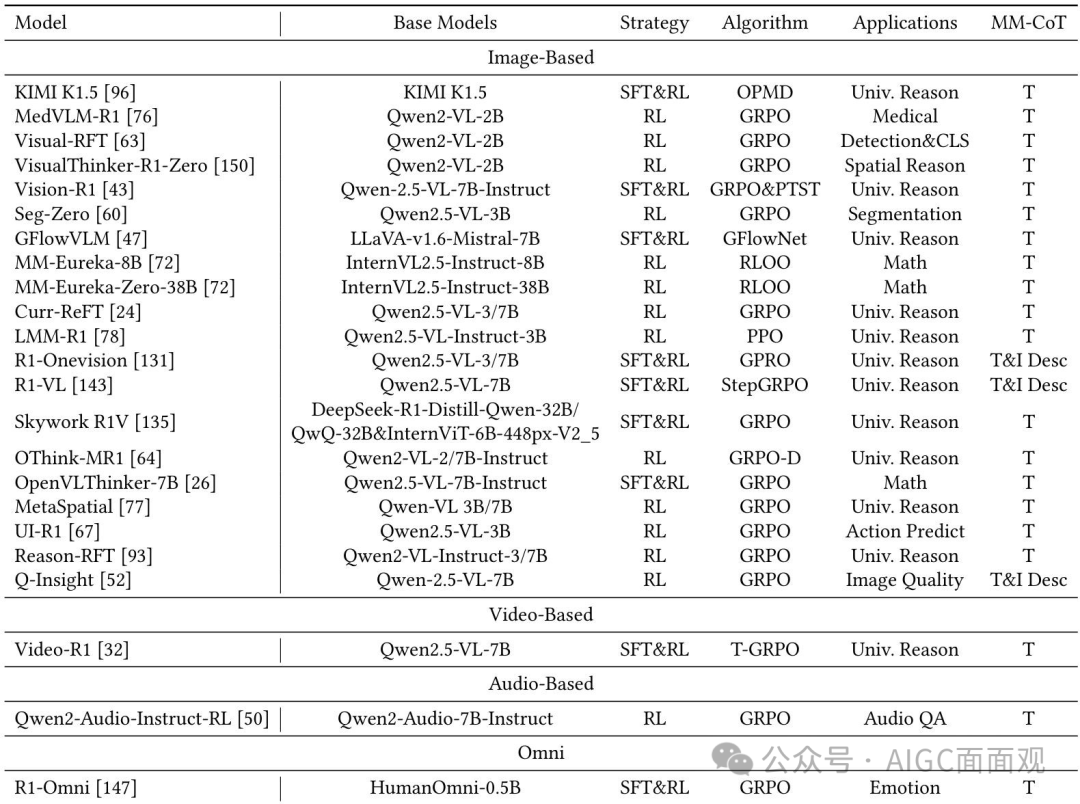
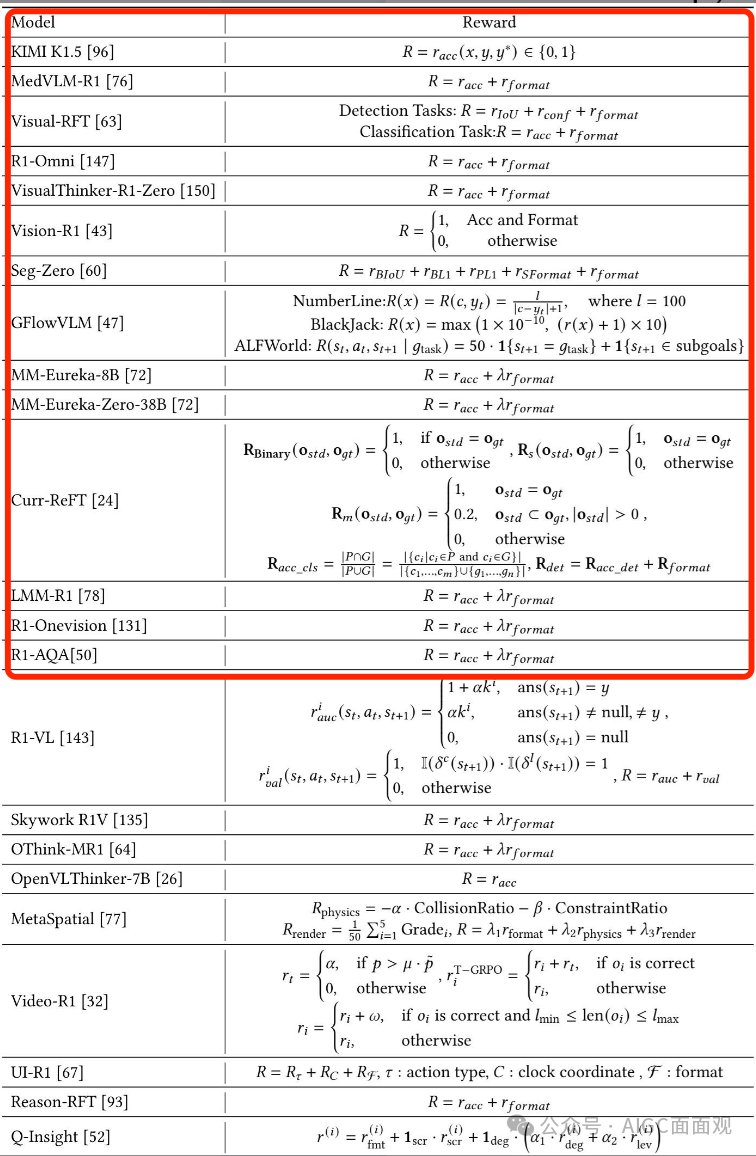
四、基于RL的MLLM推理
系统地回顾了将R1训练范式从LLMs适应到MLLMs的最近尝试,并分析了其中的关键挑战和解决方案。
1.RL 训练范式:从 LLM 到 MLLM
标准化的R1训练范式:Kimi K1.5:采用在线策略镜像下降(OPMD)算法,将强化学习应用于多模态语言模型(MLLMs),增强其在多模态领域的推理能力。DeepSeek R1:通过验证强化学习与可验证奖励Reinforcement Learning with Verifiable Reward (RLVR)足以有效激发大型语言模型(LLMs)的推理能力。
在有限的训练数据下显著提升模型性能。此外,通过避免复杂的奖励模型训练,RLVR 有效缓解了奖励劫持问题。PRM(Process Reward Mechanism)和ORM(Outcome Reward Mechanism)
机制类型 | 评估焦点 | 适用场景 | 优势 | 局限性 |
|---|---|---|---|---|
| ORM | 最终输出正确性 | 数学计算/代码生成 | 结果导向明确 | 奖励信号稀疏+延迟 |
| PRM | 推理过程步骤 | 逻辑推理/知识问答 | 提升中间步骤可靠性 | 需设计复杂评估体系 |
参考
Reinforced MLLM: A Survey on RL-Based Reasoning in Multimodal Large Language Models
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









