 BAGEL:统一多模态推理大模型的创新突破
BAGEL:统一多模态推理大模型的创新突破




作者 | 欠阿贝尔两块钱 来源 | AIGC面面观
原文链接:https://mp.weixin.qq.com/s/lVTu0s4oDitArV4eqvwRMg
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『多模态大模型』技术交流群
本文只做学术分享,如有侵权,联系删文
paper:https://arxiv.org/pdf/2505.14683
code:https://github.com/bytedance-seed/BAGEL主要贡献
1.开源统一多模态基础模型:BAGEL作为首个支持多模态理解与生成的开源统一模型,通过大规模交错多模态数据(文本、图像、视频、网页)预训练,展示了复杂推理的涌现能力。
2.架构创新:采用全新的混合专家架构(Mixture-of-Transformer-Experts, MoT),通过共享自注意力机制实现长上下文多模态交互,显著提升了生成与理解的协同能力。
3.涌现能力:首次在多模态统一模型中观察到涌现特性(如自由形式图像编辑、长上下文推理),并通过IntelligentBench量化评估这些能力。
当前痛点
1.数据局限:现有统一模型主要依赖图文配对数据,缺乏结构化多模态交错数据(如视频、网页),导致复杂推理能力不足。
2.架构瓶颈:传统模型通过外部扩散模块或量化自回归方法引入生成与理解模块间的信息瓶颈,限制长上下文交互能力。
3. 评估不足:传统基准(如MME、MMBench)无法有效评估复杂多模态推理任务(如自由形式图像编辑、世界导航)。
核心方法
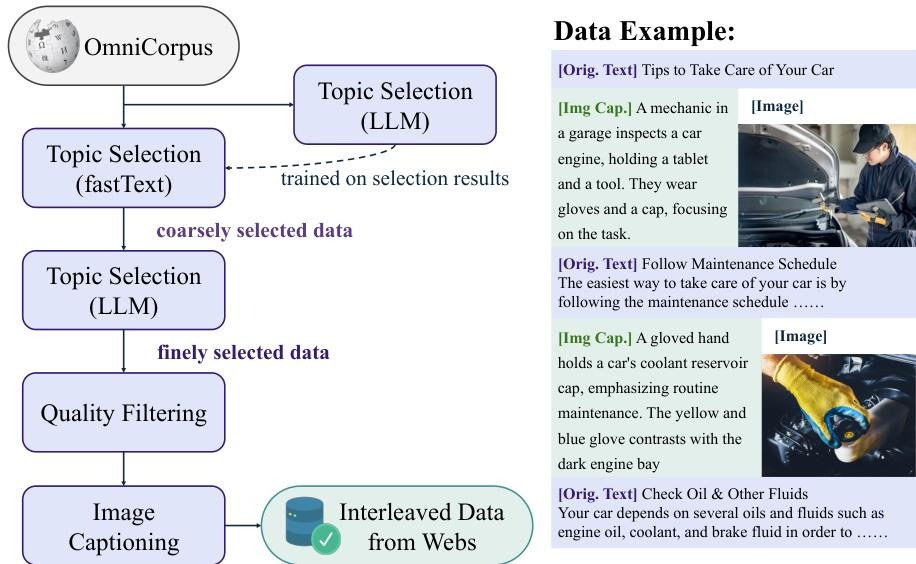
1.数据构建策略:
多源数据整合:融合视频(Koala36M、MVImgNet2.0)和网页(OmniCorpus)数据,覆盖时空动态与跨模态交互信号。
交错数据构建:通过视频帧间描述生成和网页“描述优先”策略(caption-first)增强局部语义对齐,优化生成一致性。
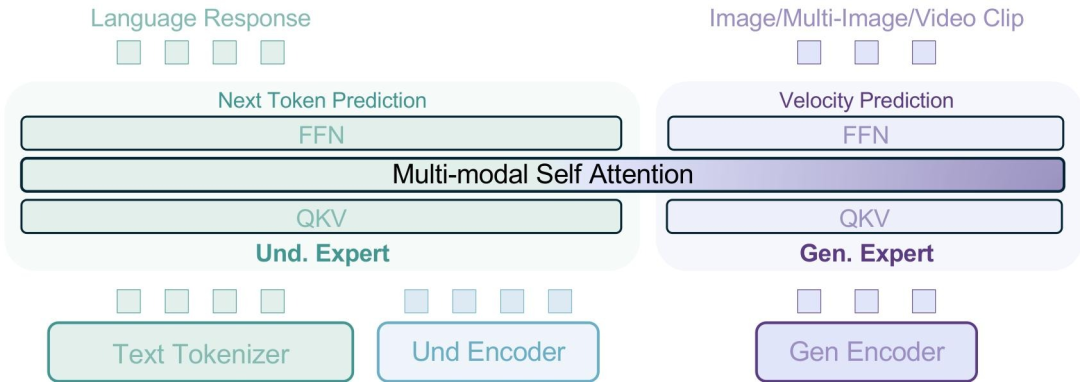
2.混合专家架构设计(MoT)
共享机制
采用Mixture-of-Transformers(MoT)架构,包含独立的多模态理解专家(Handling text & ViT tokens)和生成专家(Handling VAE tokens)。两者通过共享自注意力层实现上下文交互,但在前馈网络(FFN)和参数空间完全解耦。
采用两个不同的编码器,分别捕获语义内容和低级像素信息,用于图像理解和生成任务
视觉编码双通道
理解编码器:基于SigLIP2-so400m/14的ViT编码器,支持原生分辨率输入(最高980×980)和动态长宽比处理(NaViT技术)。生成编码器:冻结的FLUX VAE编码器,将图像映射到潜在空间(下采样率8×8),并通过2×2 patch嵌入对齐LLM隐空间维度。
多阶段训练策略
四阶段优化
对齐阶段:固定ViT和LLM,仅训练MLP连接器,使用固定分辨率图像-文本对进行图像描述学习。预训练阶段:引入QK-Norm稳定训练,混合文本、图像-文本对、网页及视频交错数据(共2.5T tokens),采用原生分辨率策略。持续训练阶段:提升视觉分辨率至1024×1024,增加交错数据比例至40%,强化跨模态推理能力(2.6T tokens)。监督微调阶段:构建高质量生成/理解子集(72.7B tokens),应用动态噪声调度(timestep 1.0→4.0)适配高分辨率生成。
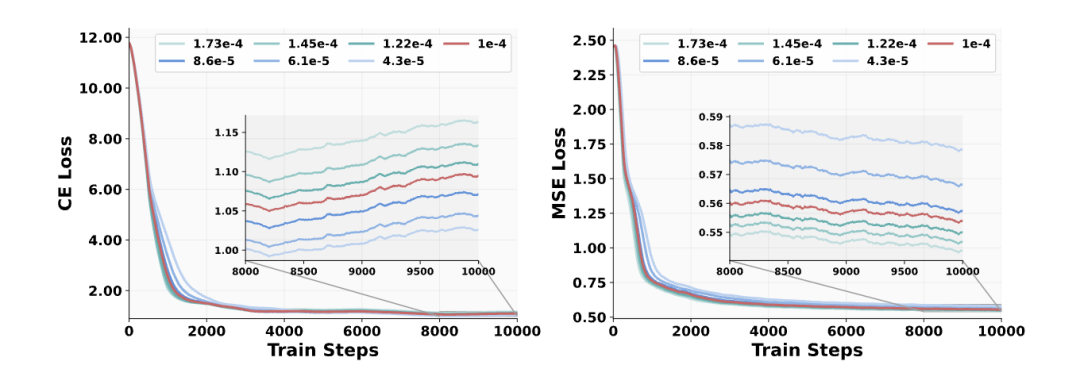
动态平衡策略数据采样:生成数据采样比例优化至80%(vs理解数据20%),通过损失曲线分析确定最优混合比例(图5)。
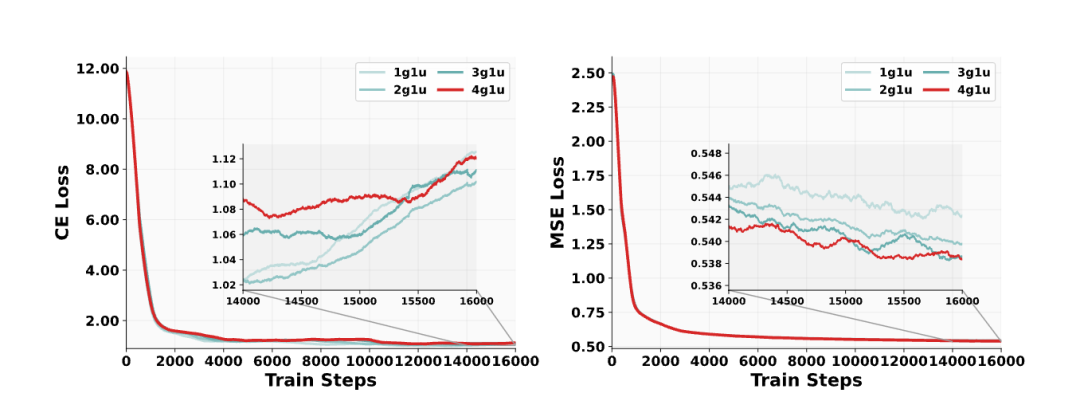
学习率调度:分离MSE(生成)和CE(理解)损失权重,使用分层学习率(生成任务lr=3e-5,理解任务lr=1e-5)缓解优化冲突。
生成架构创新
Rectified Flow生成器替代传统扩散模型,采用ODE-based的直线轨迹建模,通过单步噪声预测实现高效采样(NFE=1)。VAE潜在空间嵌入扩散时间步编码,直接注入初始隐状态而非AdaLN模块。
广义因果注意力机制使用FlexAttention实现动态KV缓存:生成时允许后续模态关注VAE/ViT tokens,而屏蔽噪声VAE tokens。
关键实验
多模态理解:
在MMMU和MM-Vet上分别以14.3和17.1分超越Janus-Pro,显示MoT设计在任务冲突缓解上的优势。
图像生成:
GenEval得分88%,优于FLUX-1-dev(82%)和SD3-Medium(74%);WISE基准表现接近GPT-4o。
图像编辑:
GEdit-Bench得分与专业编辑模型Step1X-Edit持平,IntelligentBench得分44.9,显著优于开源模型。
涌现能力验证:
训练至3.5T tokens后,Intelligent Editing得分从15提升至45,显示复杂推理能力的涌现。
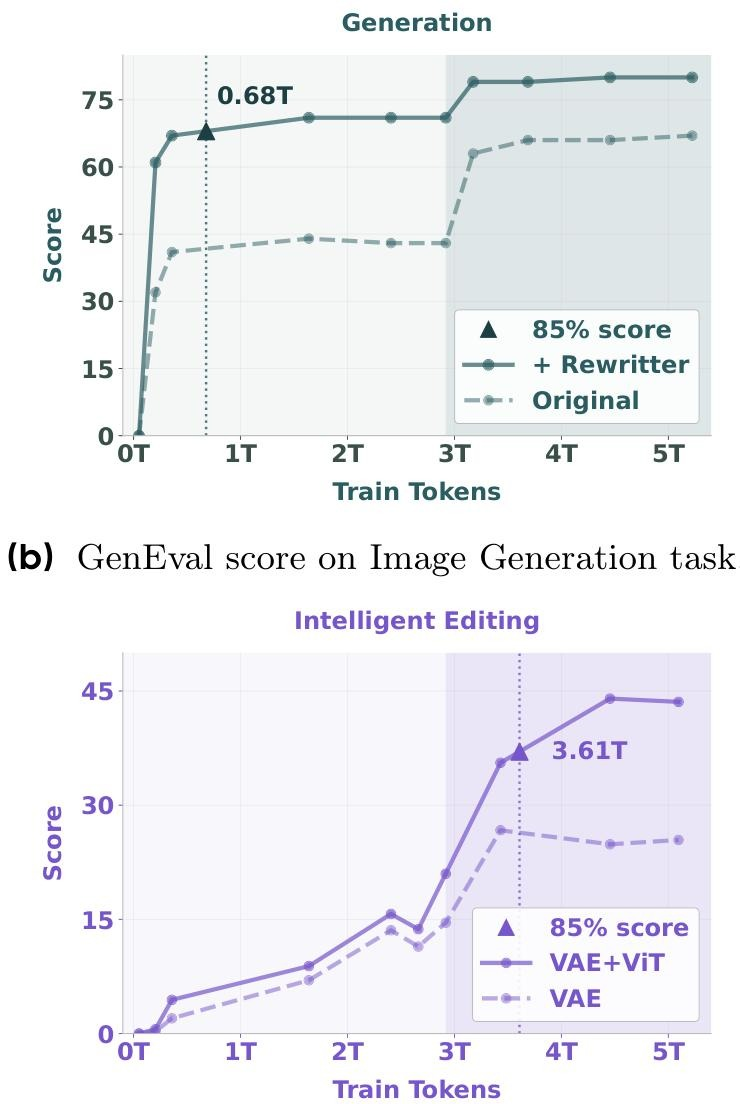
BAGEL 在不同任务上的预训练性能曲线。较浅的区域表示低分辨率预训练阶段,较暗的区域表示高分辨率 CT 阶段。随着训练 token 数量的增加,BAGEL 表现出持续的性能提升 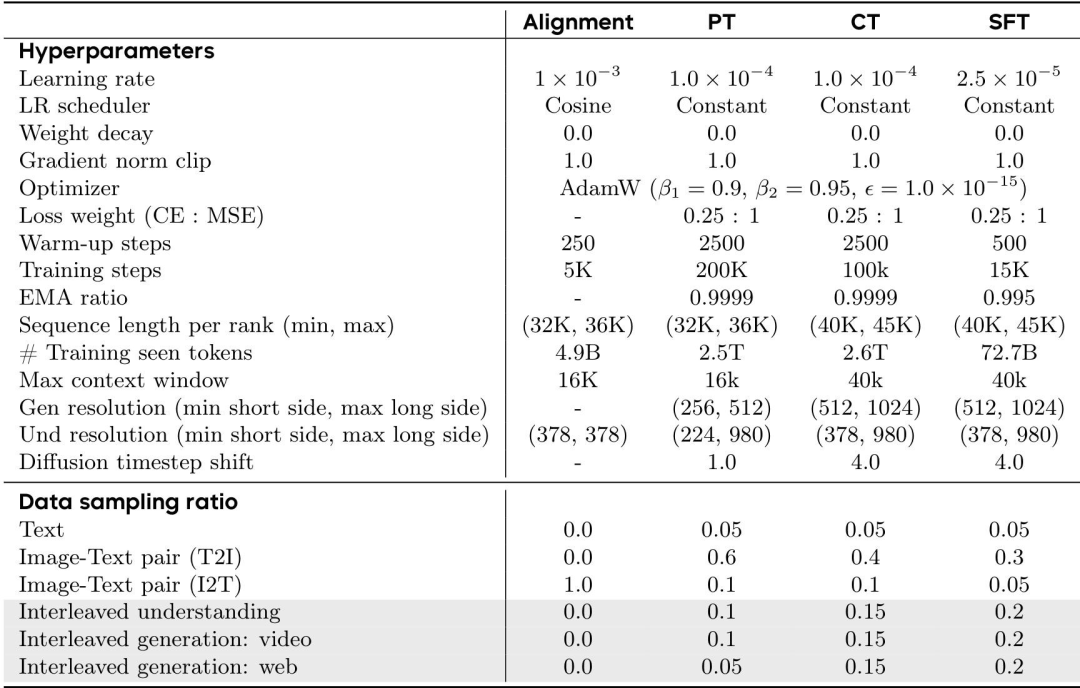
BAGEL 的训练方法。多模态交错数据以灰色突出显示 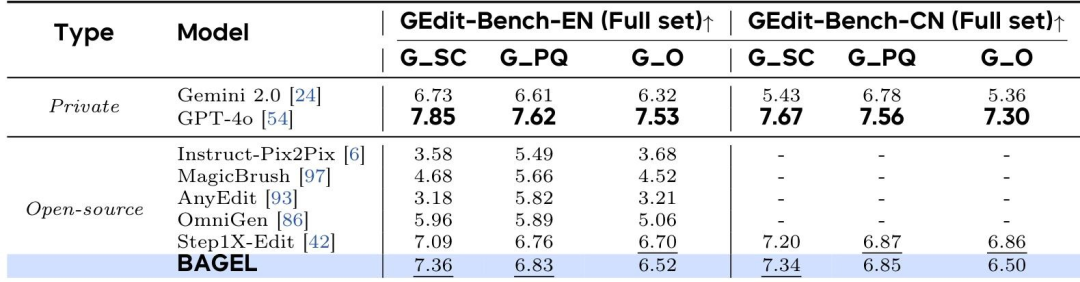
在 GEdit-Bench 上进行比较。所有指标均报告为“越高越好”(↑)。G_SC、G_PQ 和 G_O 指的是 GPT-4.1 评估的指标。 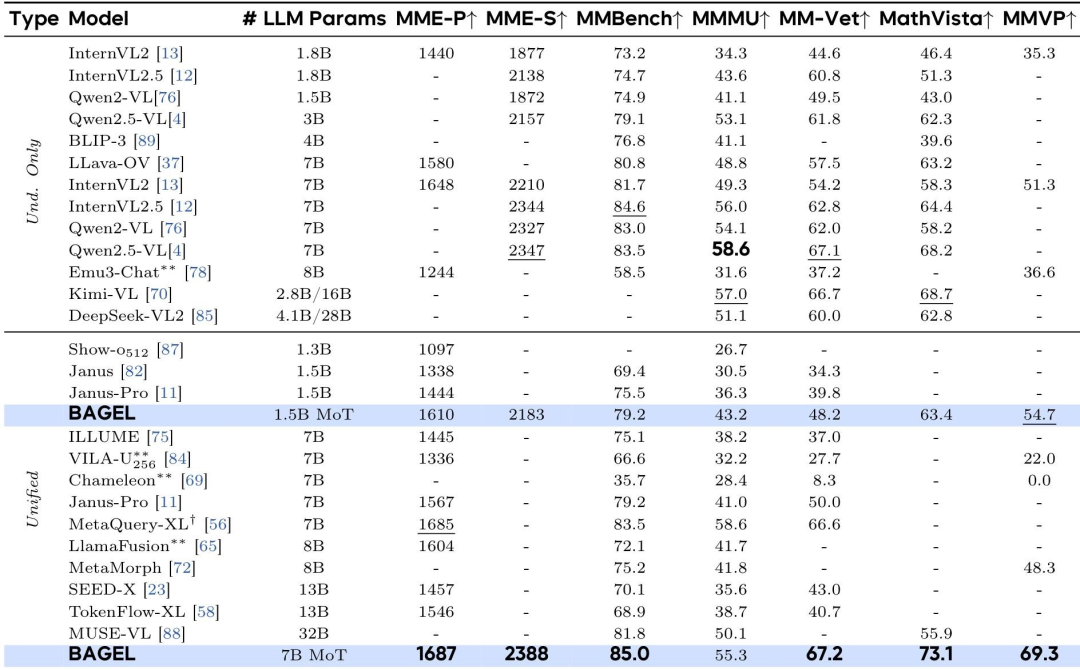
与视觉理解基准的最新成果进行比较。MME-S 是对 MME-P 和 MME-C 的总结 结论
统一预训练的有效性:通过交错多模态数据与MoT架构,BAGEL在理解和生成任务上实现协同优化,并涌现出世界建模与长上下文推理能力。
扩展潜力:模型规模(1.5B→7B)与数据规模(3.5T→6T tokens)的进一步扩展可释放更强涌现能力。
既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,下次再见自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1564
1564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









