



作者 | T-MAC 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/533907821
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『数据闭环』技术交流群
本文只做学术分享,如有侵权,联系删文
一. 简介:
在实际工作中,自动驾驶的数据是非常重要的, 如何高效低成本的获得高质量的数据集成为了自动驾驶企业的核心竞争力。
随着自动驾驶感知技术的不断发展, 对于标注的要求也越来越高,很多标注任务也越来越难。 Camera/Lidar 联合标注, 3d 语义分割,最近大火的 多Camera BEV, 如何向特斯拉那样,完成vector space 的自动化标注,目前也没有看到有哪个国内公司能做的。
自动标注算法(auto-labeling)其实就是高精度的真值生成算法,可以不受车端的算力限制,并且可以用全时序的数据来联合优化结果。因为是离线的,精度怎么高怎么来。 这么一套系统,除了可以做自动化的标注/预标注, 也有很多其他的作用, 例如可以挖掘corner case, 指导车端模型训练等。
我这边整理了一些论文和业界的方案,记录在这边和大家分享。本文主要讨论3d 空间下的标注,以激光雷达为主。 有错误或者理解不到位的情况,欢迎大家指正。
二. 业界的一些方案
Robesense RS-reference 系统:
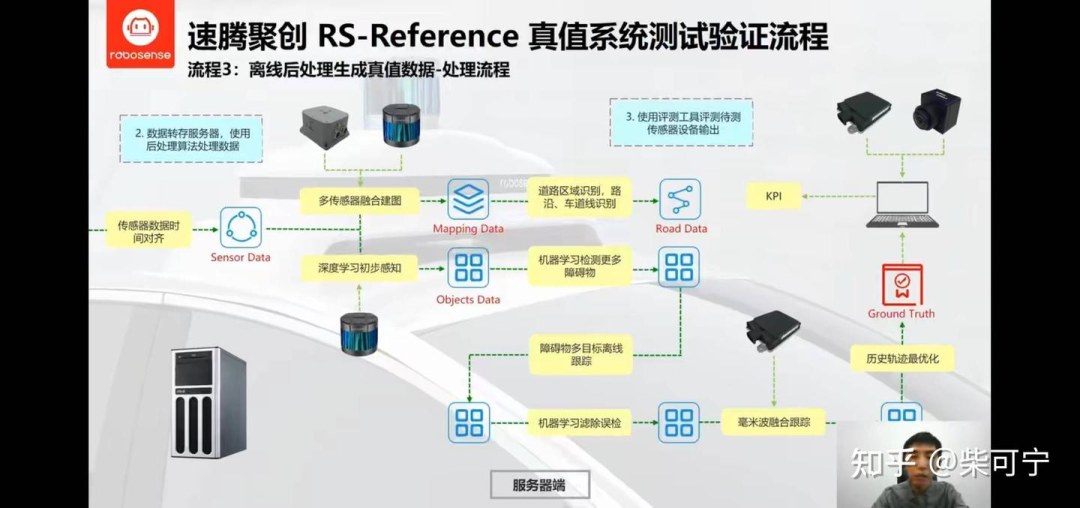
RoboSense 的 RS-Reference 系统, 有一个车顶模组 + 数采设备 + 离线工控机组成, 可以装在测试车上, 完成数据采集, 真值生成, 感知算法评价等功能, 从2018 到现在, 也经过了好几代系统的迭代, 这块的积累也比较深。
主要分为2块核心算法:
目标检测:
机器学习 + 深度学习 联合处理点云(corse - to - fine),完成更多检出,和消除误检。 (目前应该加入了多相机的前融合算法)
加入毫米波雷达(Conti 408), 如果毫米波数据 和 激光雷达检出匹配, 则优化目标的运动属性(速度+加速度等), 然后得到每个目标的全生命周期轨迹, 将全生命周期的整个轨迹作为考虑, 通过滤波/贴边等操作优化目标的属性
可行驶区域/路沿/车道线:
多传感器SLAM 建图(速腾这套设配可以配备惯导)
通过点云分隔网络(或其他)完成点云高精地图的静态元素检测
再将结果从点云地图反向转化为单帧的结果
这不过这套设备也不便宜,财大气粗的OEM爸爸应该愿意买单,毕竟真的很有帮助。 在北美福特工作的时候,AVL也来present过这么一套系统,不过后面好像没听到啥消息了。
2019年的时候拜访速腾聚创,非常有幸和王博有过深入沟通, 感兴趣的同学可以看一下B站王博的介绍:
RS-Reference 2.0 海量真值数据的获取与感知系统的评测 | RoboSense(速腾聚创)线上分享会回顾_哔哩哔哩_bilibili
三. 3d 动态元素自动标注
3DAL - Waymo, 2021
Offboard 3D Object Detection from Point Cloud Sequences
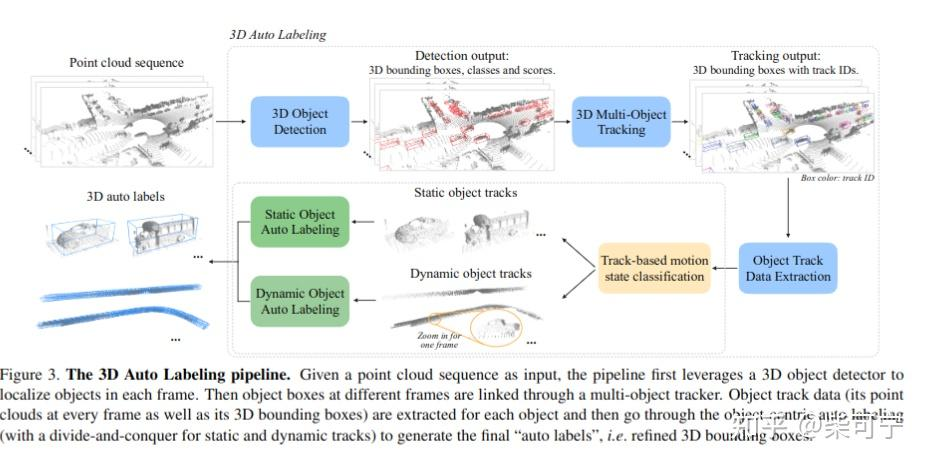
2021年, Waymo 放出来一篇自自己是如何做 offboard 3d object detection的工作, 由Charles R.Qi大神和 YinZhou大神带队。
整体的思路也遵循 Coarse-to-Fine 的操作 :
先通过一个离线的3d 目标检测 (MVF++) + 3d 跟踪算法 (Kalman Filter)完成Coarse 的目标检测, 通过这一个,可以得到每一个目标的整个轨迹序列
通过目标检测轨迹 + 原始点云, 将目标的点云从检测框里抠出来, 可以得到 Sequence Object Points + Sequence Objects Boxes, 用于下一阶段的进一步box refine
点云叠加后, 动态目标会形成一条轨迹,点云会形成拖影,静态目标会形成更加完整的目标, 因此, 使用了一个简单的静/动分类器来完成分类。
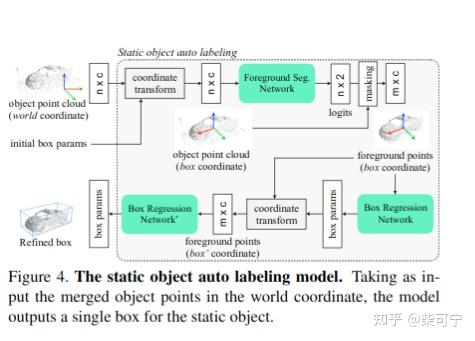
Static Object Auto Labeling 1. 将多帧点云从世界坐标系转化到目标中心坐标系 2. 用一个Pointnet 来分类点云的前景点和背景点, 然后将背景点去除
再用一个 Pointnet Variant 来回归物体中心点,heading, size和类别, 完成静态物体的refine
Dynamic Object Auto Labeling
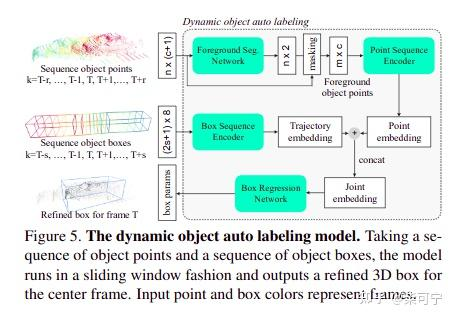
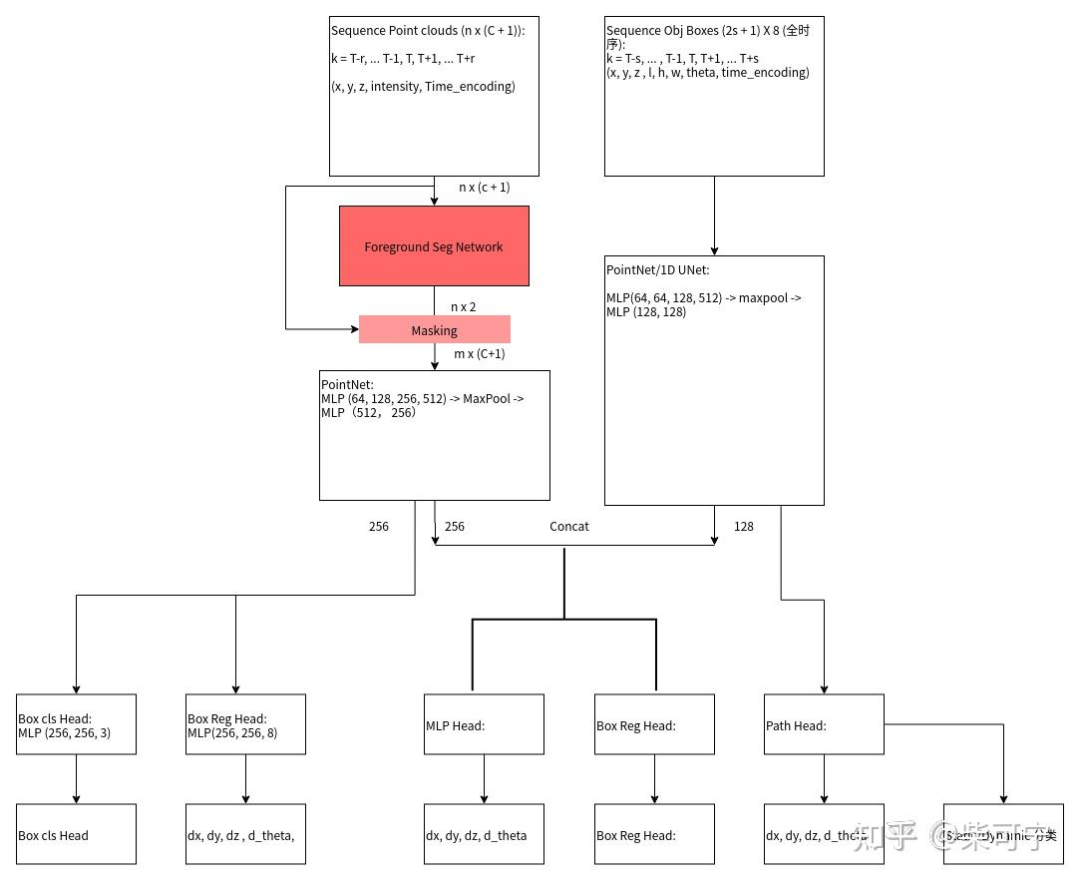
Foreground Seg Network, 额外加入了时间的encoding, 当前帧为0, 前后各取两帧数据, 共五帧数据, 每帧数据的点云降采样到1024个点, 然后总共有5120 points 进入分割网络
--> MLP (64, 128, 256, 512 ) -> MaxPool -> MLP(512, 256), 最后输出256维度的点云编码特征
Box Sequence encoder Network, 也编码成特殊的点云(c_x, c_y, c_z, length, width, height, theta, time_enocding), 基本用了所有的目标时序, 共计101帧数据
--> 用了一个额外的PointNet, 但是卷积可以换为 1D ConvNet, (Uber用了 1D Unet来编码),
--> Pointnet(64, 64, 128, 512, max-pooling, MLP(128, 128) , 最后输出 128-dim feature,我们叫做trajectory embedding
将 point embedding 和 trajectory embedding concatenated在一起, 得到Joint Embedding
Joint Embedding用MLP (128, 128, Linear层) 回归目标的尺寸
为了促进 两个分支的贡献, 用trajectory embedding 和 object embedding 加上两个额外的分支单独用来预测bbox
Auto4D - Uber, 2021
Auto4D: Learning to Label 4D Objects from Sequential Point Clouds
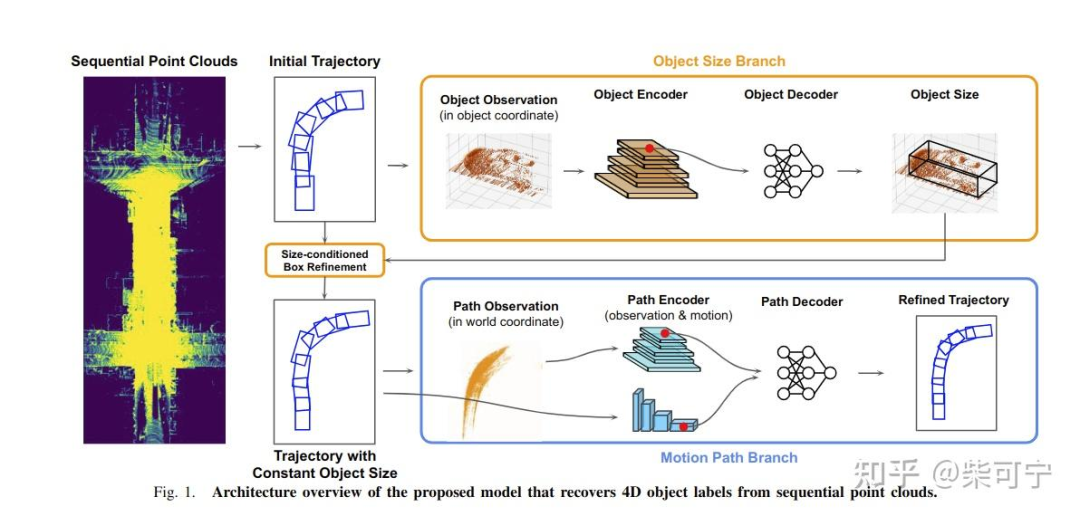
2021年1月, Uber首先放出来一篇自自己是如何做 auto - labeling的工作, 作者包括多伦多大学的 Bin Yang 大神和 后来创办Waabi 的 Raquel Urtasun
http://www.cs.toronto.edu/~byang/.
思路大体也是follow Coarse to Fine 的操作, 只不过和waymo 不同, 在refine的时候, 将目标的回归分为两个步骤, 一块是目标的不变属性,例如尺寸, 类型等, 一块是目标的运动变化属性(位置,heading等)
Object Size Branch
第一步也是通过uber自己的检测网络 + 跟踪算法 完成初步的 Init Trajectory 生成
将bbox 扩大1.1倍, 然后将点云抠出来放到局部物体坐标系内 (这个地方其实有个疑问,不管定位精度怎么高,将点云合起来后不可避免的肯定会出现点云的重影模糊问题,如果多帧点云是重影模糊的,如果回归正确的尺寸?)
将抠出来的点云 做一个 refine, 这边确认了 corner align 要优于center align
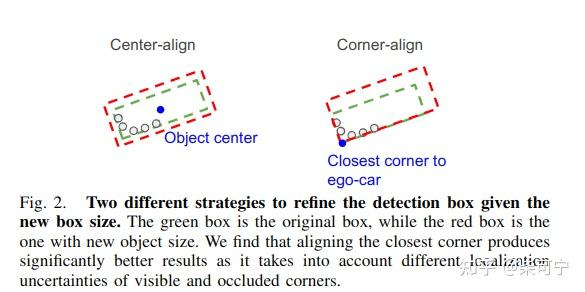
然后将目标点云投影到BEV 视角下, 使用uber 自己的 2D CNN Detector 提取特征,回归size, 类别这类不变的属性。
Motion Path Branch:
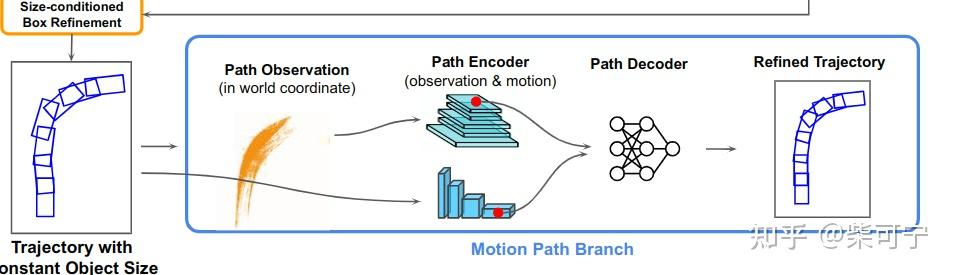
整个Motion branch的操作,都在世界坐标系下完成。
Path Observation:
世界坐标系的时序点云,但是没有将时间信息保存在点云里面
Path Encoder:
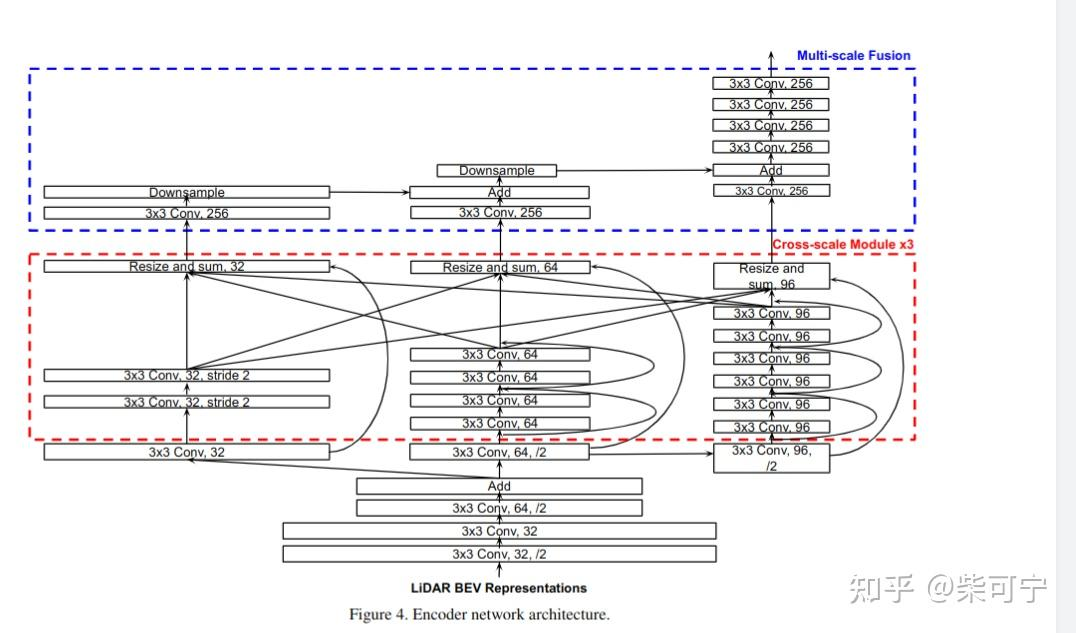
每一帧点云使用2D CNN 提取multi-scale feature maps
然后提取两帧之间的差,motion wise feature
将多帧的运动特征信息cat在一起,然后用一个1D-CNN 提取运动特征 (1D UNet)
个人更加认同Uber 的思路, 先确定目标是什么类型, 固定好全时序的尺寸。 然后将问题转化为size-fixed motion refine problem,但是确定尺寸的时候不一定要全都移到目标的中心坐标系。 在waymo 和 Uber的方法中, 各有优劣式,组合一下可能会更好。
MPPNet - MMlab-CUHK/MPI-INF, 2022
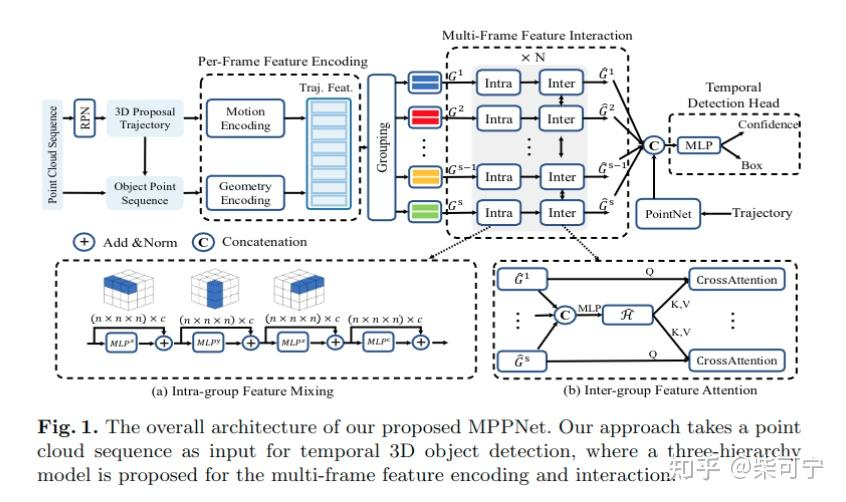
CUHK 的mmalb 和 马普所的史少帅大神, 最近也发了一篇利用多帧来优化检测结果的, 虽然不是autolabeling的方法, 但是在2阶段refine上也waymo/Uber 的思路也很类似,并且可以作为端到端优化, 而不像waymo + Uber要经过多次操作, 很新颖的提出Proxy - Point(代理点) 来表示一个目标, 并且在时序的操作上加入了MLP-Mixer, group feature attention等技术, 更好的处理时序的数据。
加入全时序的信息, 就可以拓展成auto-label的方法 。
整体操作如下:
1. 使用一个single - frame proposal network 来获得初始的 3d proposal trajectories.
利用已有的 centerpoint/pointpillars, 采用4帧点云聚合作为输入。
为了关联目标, 使用了一个speed prediction head , 和centerpoint 预测xy 的速度不同, 本文使得速度方向和heading方向一致, 通过速度去预测目标位置, 然后通过IOU 匹配
经过第一阶段后: 得到T-frame 的 3d proposal 和 时序的3d points region pooled from each frame t , 作为2阶段的输入
2. 构建 proxy points, 在每个时刻t, 均匀在3d框内均匀采样N * N * N 个 proxy point, 这些点保持了和轨迹盒相同的位移
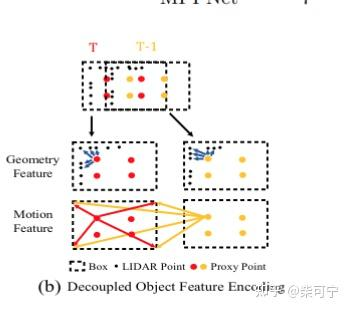
3. Decoupled per-frame feature encoding , 将Trajectory 通过motion encoding 和 Geometry encoding 提取特征并且相加, 获得每一个trajectory 的特征。
将目标点 和 proposal box 相减, 得到difference between each object and 8corner+1center, 得到目标当前坐标系的值
然后通过 set abstraction 在点云中提取局部特征
为了提取目标的运动信息, 将每一帧的prixy point, 减去第一帧的目标的9个点(目标中心 + 8个角点)
在运动信息里加入了一维度的time offset embedding e^t
将目标的geometry features 和 motion features相加起来, 最后的特征 可以表示成:
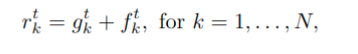
4. Grouping for multi-frame feature interaction
由于巨大的计算成本和GPU内存, 在所有帧之间建立密集连接还是比较难负担的。 所以将较长的轨迹划分成成少数几个不重叠的组, 每个组包含一个较短的子轨迹 (由于整个模型还是需要很大的显存, 如果可以将之前一阶段的网络训练好,冻结权重, 可能后面的操作会容易点? )
5. 时序特征聚合
Intra-group feature mixing
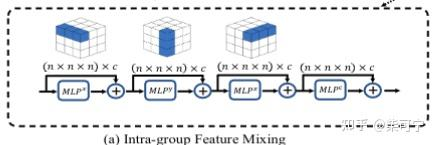
参考了视觉的MLP-Mixer , 来进行不同帧的proxy points的特征聚合。
后续实验也证明了MLP mixing 要比attention mechanism 能更好的实现组内特性交互。
Inter-group feature attention
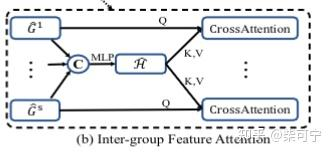
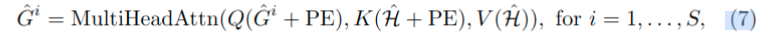
Inter group feature attention 可以有效的编码特征 和 传播全局全序列信息, 提高局部的组间表示。 上述组内特征混合 和 组间交叉注意力多次反复叠加, 可以让轨迹逐渐意识到全局和局部上下文, 从而从轨迹提取出更加精确的3d bbox 框
6. 3D temporal detection head with transformer
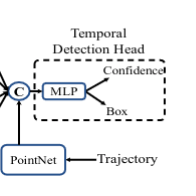
利用 transformer layer 来解码, 构建了一个learnable feature embedding E = R (1 * D) as query, 从 每一个 group feature Gi中 使用 multi - head attention
参考了 Offborad Object detection , 将目标的proposal 轨迹通过一个 PointNet sub-network 来完成目标轨迹的特征提取。
因此,检测头集成了group - wise feauter {E1,…, ES},通过特征拼接,分别从对象点和bbox的embedding ,进行最终置信度预测和框回归。
作者说后来应该会在Openpcdet 开源, 蹲守一波,等开源了学习一下。
四. 3d 静态场景元素自动标注
我理解静态场景重建的自动标注, 其实可以转化为建立高精地图的工作。 需要标注的元素包括: 车道线,路沿, 斑马线,停止线,红绿灯等。 如果需要做语义定位的话,还需要做一些类似灯杆,标识牌等元素的识别和矢量化。
感兴趣的同学可以看一下这篇综述, 知乎上也有解析:
High-Definition Map Generation Technologies ForAutonomous Driving: A Review
黄浴:自动驾驶的高清地图生成技术综述
SLAM 建图 / 大规模点云语义分割:
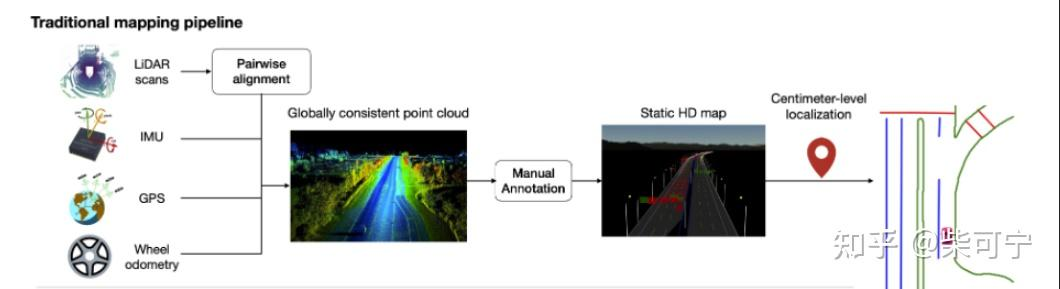
其中的一种方式可以通过 多传感器slam 建图,然后通过点云地图的自动/人工标注, 构建局部的高精地图。
优点: 精度比较高,步骤较为流程化。 然后模型识别不准的,人工在点云地图上做一些修正。
缺点: 想训练一个大规模的语义分割的网络,前期还是需要一定量的数据集, 且分割的性能不一定能保证
另外一个点是从语义分割后的点云,想得到矢量化的场景元素, 也需要比较繁琐的后处理操作, 这块在某一些场景下可能会引入较大误差。
自动化的步骤可以大概分为如下:
通过多传感器SLAM 建图:
--> 可以构建点云 intensity based 的地图 (LOAM, Lego-Loam)
--> 或者通过Camera + Lidar fusion 构建rgb based 的彩色点云地图
过一个目标检测网络, 去除动态的障碍物, 构建更加干净的点云
然后可以将高精地图切块,类似于做成比如50m * 50m的点云方块, 训练一个大规模的城市场景语义分割的大模型来做点云的语义分割(RandLA-Net, KPConv等)
再通过一些后处理的方法,将场景元素提取成矢量元素
人工做一些质检,来确保地图和元素的生成质量。

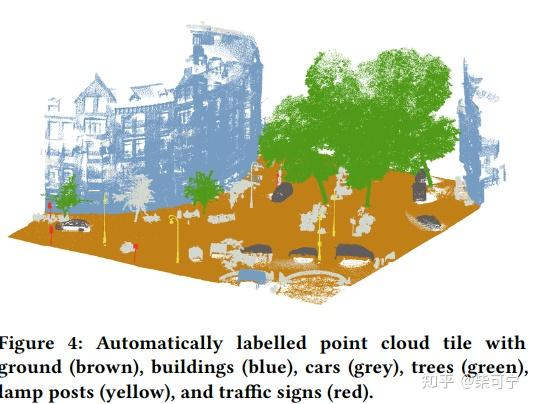
HDMAPNet - 清华Mars Lab
得益于最新的多相机BEV 的检测方法发展, Mars Lab提出了连续两篇自动化在车端实时构建高精地图的工作。
HdMapnet 和 VectorMapNet(升级版)
HDMapnet 将点云和HdMapNet做融合, 构建了BEV 特征之后, 搭了3个检测头(Semantic Segmentation 分支,Direction Prediction 分支, Instance embedding 分支 , 然后通过后处理再将矢量结果构建出来。
是一个提出端到端构建高精地图的,虽然精度可能没有办法用于auto-labeling, 后处理也比较重,但是却提供了一个非常好的思路.
代码中, 点云只采用了当前帧的数据, 相机采用了过去几帧数据(通过ego_motion 将多帧camera 的特征通过grid_sampler给cat在一起 )。 如果不考虑实车, 将前后多帧点云/图像特征拼接, 我觉得可能精度能提升一个水平。
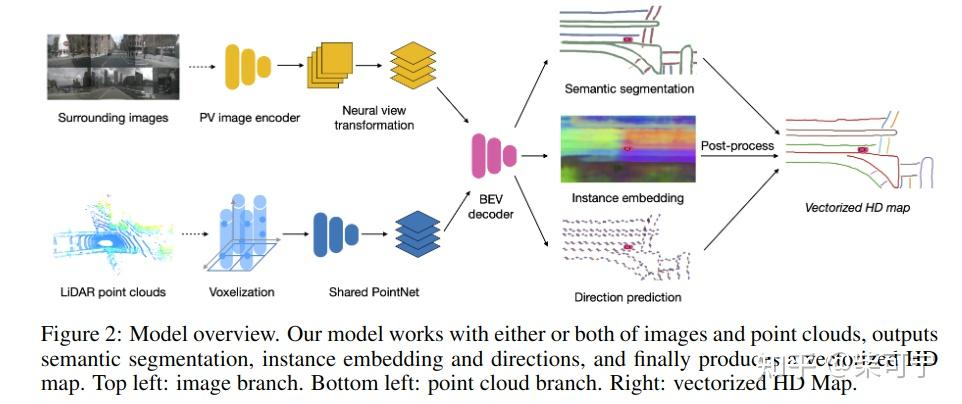
Fusion BEV Encoding:

Decoder:
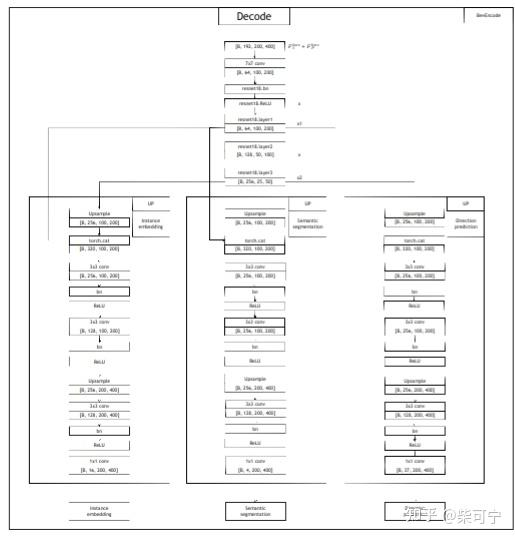
VectorMapNet - 清华大学Mars Lab
希望能端到端的输出矢量地图, 又有了升级版本 VectorMapnet.
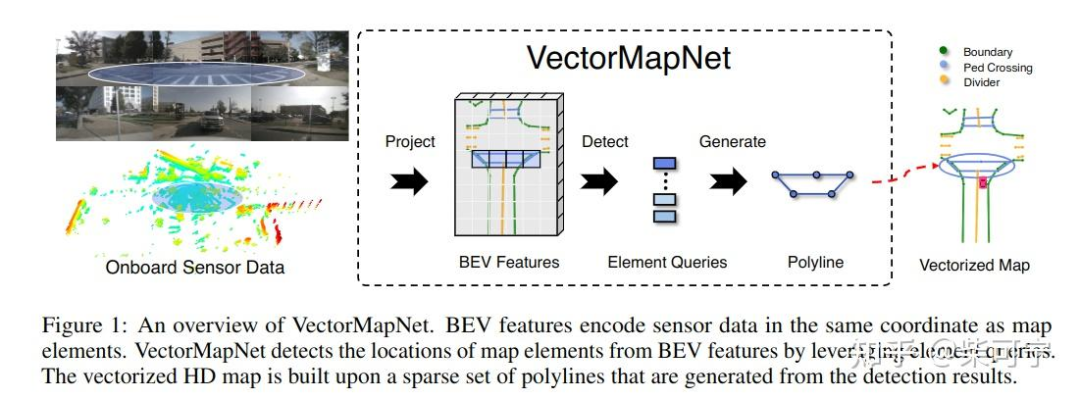
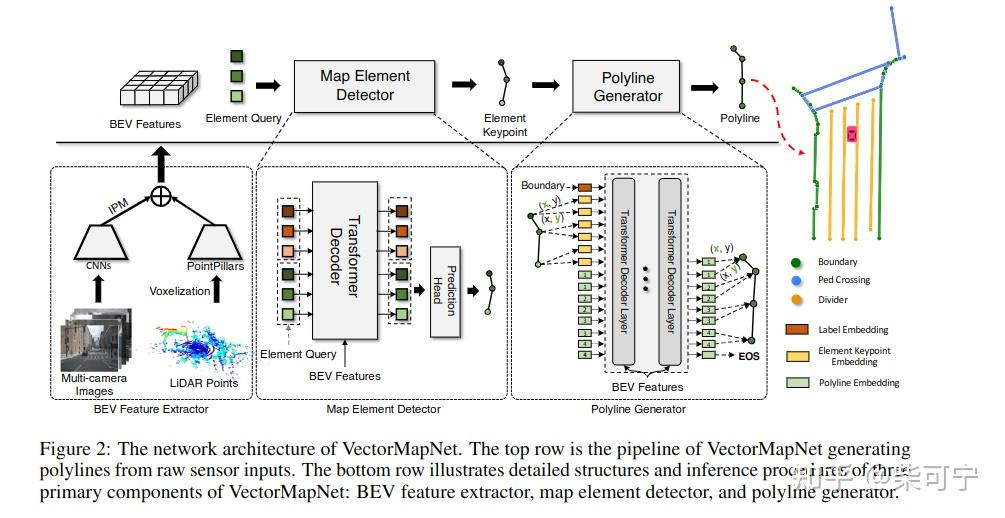
VectorMapNet是一种端到端的高清语义地图学习方法。与以往的工作不同,它使用折线(polyline)来表示地图元素,并直接预测传感器观测的矢量化输出,而不需要地图光栅化或后处理
联合建模地图元素和每个地图元素的几何之间的拓扑关系是一项具有挑战性的工作。利用折线作为基元来建模复杂的地图元素,并通过将该联合模块分离为两个部分来缓解这一困难:地图元素检测器和折线生成器
VectorMapnet 在nuscenes 上达到sota, 超过hdmapnet 14.2 MAP
论文细节分析我就不写太多, 知乎上已经有一些细节论文分析, 供大家参考:
wanghy:VectorMapNet: 端到端的矢量化高精地图学习
https://github.com/Mrmoore98/VectorMapNet_code
本文的重点是提出了用polyline 来作为地图的基础元素,其实在人工标注的时候也是用的这种点集的形式。
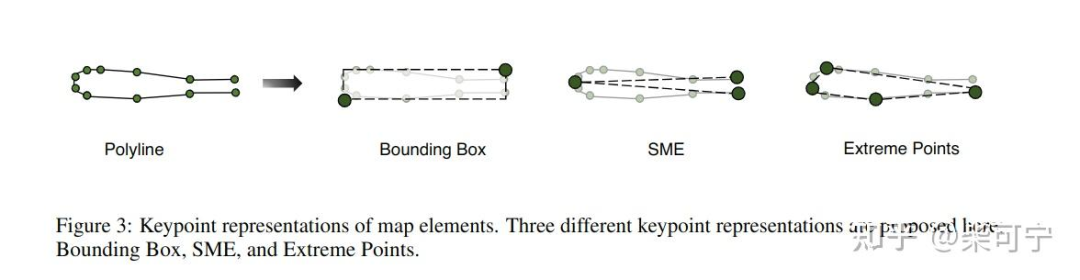
这个思路真的非常受启发:
不光点/anchor 可以作为query 来和BEV feature 做交互, 任何内容都可以作为query 和bev 特征做attention, 例如(折线, 圆,点集等), 相当于在网络中加入了基础检测元素的先验, 非常有利于端到端的检测和sparse的检测。
VectorMapNet 留了一个未来改进项, 时序信息的加入 和多帧之间的输出consistency, 我觉得如果能解决这个问题, 那真的可以作为场景重建的auto- labeling 的重要模块, 等代码开源了好好学习一下。
五. 在没有激光雷达的情况下, 多相机 BEV 如何进行准确的3d 标注?
来到这个章节, 也是得益于特斯拉的带动 和 最近 多相机BEV的火爆。
学术界关心如何刷点,如何构建更加准确地bev 特征, nuscene/waymo都提供了高质量的数据集。
然而在工业界,当老板问你是否能做多相机 BEV 的开发, 我们有那么多ADAS 量产项目,相机数据回传后能否用?
作为算法工程师的我们在角落瑟瑟发抖, view transformer 如何部署? BEV 真值从何而来? 传感器时空标定精度是否足够?云端服务器8卡A100完全不够大家开发? 一大堆问题迎面而来。
非常欢迎大家关注这个问题,多贡献自己的想法。
自动驾驶BEV感知的下一步是什么?
我也提出我自己的一些想法吧, 也是对于特斯拉的一些分析:
对于前期, 可以在量产项目的测试车辆上撘高线束的激光雷达, 然后给量产视觉提供真值, 可以看到几家公司,小鹏,蔚来,momenta, 百度, 地平线都是这么做的。 每天都能看到这些公司的车顶着128线的lidar 到处跑。
等测试车辆有了一定的 3d 真值数据量, 需要做的就是训练一些大模型了,包括像素深度估计,Structure from Motion, 光流 , pseudo Lidar等, 这块我觉得PerceptionX 实验室的文章分析的很全面:
PerceptionX:Tesla AI DAY 深度分析 硬核!EP3 Auto Labeling
Vidar - Toyota Research
TRI 在2021 CVPR WAD 中分享了一些他们在3d 视觉中场景重建,自监督, 深度估计的一些工作,感兴趣的同学可以去看一下Adrien Gaidon的分享:
包括可以follow 一些他们的工作:
Full Surround Monodepth from Multiple Cameras, 2022
Multi-Frame Self-Supervised Depth Estimation with Transformers ,2022
3D Packing for Self-Supervised Monocular Depth Estimation, 2020
Autolabeling 3D Objects With Differentiable Rendering of SDF Shape Priors (CVPR 2020 oral)
https://github.com/TRI-ML/vidar
BEV-Depth - 旷视
待更新..
六. 半监督 & 弱标注 & MAE
待更新...
Group-RCNN / Point-Teaching
MAE/Voxel-MAE
七. NERF
AutoRF: Learning 3D Object Radiance Fields from Single View Observations
Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
Urban Radiance Fields
这里也推荐下自动驾驶之心的《自动驾驶4D标注算法就业小班课》,全面梳理自动化标注涉及的核心算法,课程大纲如下:

早鸟优惠中,扫码学习课程

自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









