



点击下方卡片,关注“自动驾驶之心”公众号
Toward Real-world BEV Perception
论文标题:Toward Real-world BEV Perception: Depth Uncertainty Estimation via Gaussian Splatting
论文链接:https://arxiv.org/abs/2504.01957
项目主页:https://hcis-lab.github.io/GaussianLSS/

核心创新点:
1. 深度不确定性建模
提出基于概率深度分布的方差计算方法,显式建模深度估计的不确定性。通过预测深度分布的均值(μ)与标准差(σ),构建动态深度范围[μ−kσ, μ+kσ],量化深度估计的置信度,解决传统LSS方法对精确深度敏感的问题。
2. 3D高斯表示与光栅化
将2D图像特征通过相机参数反投影至3D空间,生成具有协方差矩阵(Σ)的3D高斯分布。结合高斯泼溅(Gaussian Splatting)技术,通过alpha混合实现不确定性感知的BEV特征聚合,提升远距离目标与边界模糊区域的表征鲁棒性。
3. 多尺度BEV渲染策略
设计多分辨率(50×50/100×100/200×200)特征融合机制,缓解相邻像素深度均值不一致导致的BEV特征畸变问题,增强场景的空间层次表达能力。
4. 效率与精度平衡
相比投影类方法(如BEVFormer),在nuScenes数据集上实现2.5倍推理加速(80.2 FPS)与0.3倍内存占用(0.33 GiB),同时保持车辆分割IoU仅下降0.4%(38.3 vs. 38.7),验证了方法在实际部署中的高效性。
MinkOcc
论文标题:MinkOcc: Towards real-time label-efficient semantic occupancy prediction
论文链接:https://arxiv.org/abs/2504.02270
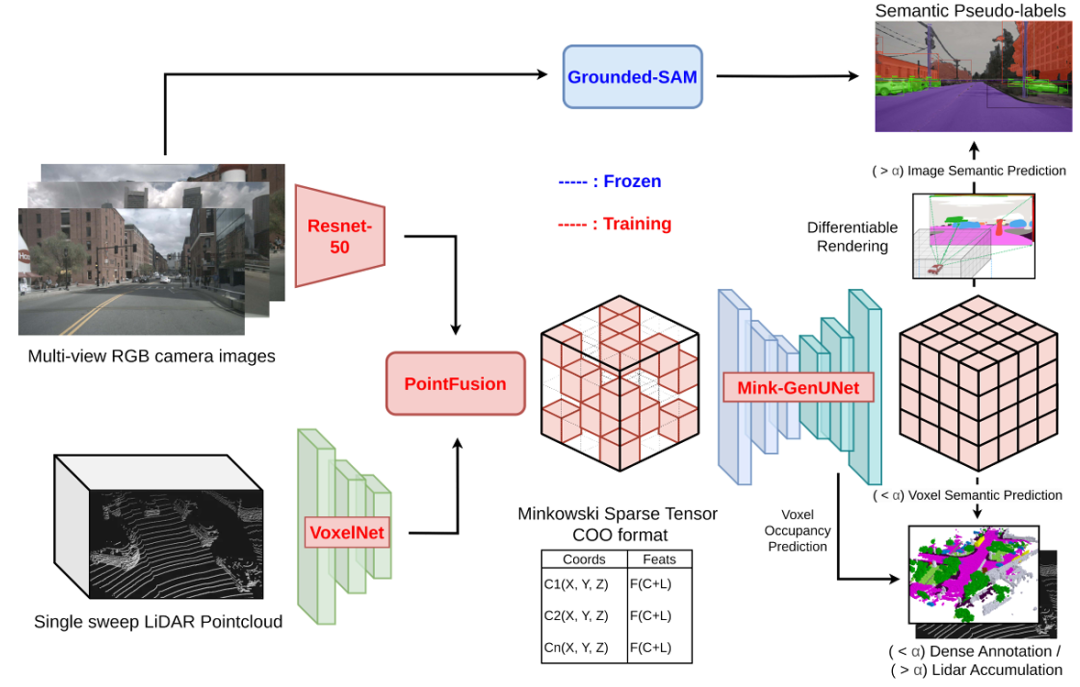
核心创新点:
1. 半监督训练范式创新
提出两阶段半监督训练框架:① 使用10%的密集3D标注数据进行预热启动;② 通过累积LiDAR扫描(LiDAR-accumulated sweeps)和基于视觉基础模型(Grounding-DINO/SAM)生成的2D语义伪标签进行后续训练,将3D标注依赖降低90%。
2. 多模态稀疏融合架构
早期融合机制 :通过LiDAR点云的空间锚定投影与多视角相机特征采样,构建稀疏多模态特征体素网格
稀疏卷积 backbone :基于Minkowski Engine实现全稀疏特征处理,结合生成式UNet(Mink-GenUNet)完成稀疏到稠密的场景补全
3. 可微分渲染优化
采用Pulsar球体渲染引擎实现:
体素到球体的几何参数化建模(位置/半径/不透明度)
深度感知加权函数(式2)实现多视角一致性优化
与2D伪标签的端到端可微分训练
4. 实时性突破
在Occ3D-nuScenes验证集上实现44.69ms单帧推理延迟(23 FPS)
相较TensorRT优化的FastOcc提速2倍,内存占用仅1.65GB
通过稀疏张量运算与生成式上采样策略,在0.4m体素分辨率下平衡精度与效率(RayIoU 40.90/mIoU 44.85)
XLRS-Bench
论文标题:XLRS-Bench: Could Your Multimodal LLMs Understand Extremely Large Ultra-High-Resolution Remote Sensing Imagery?
论文链接:https://arxiv.org/abs/2503.23771
项目主页:https://xlrs-bench.github.io/
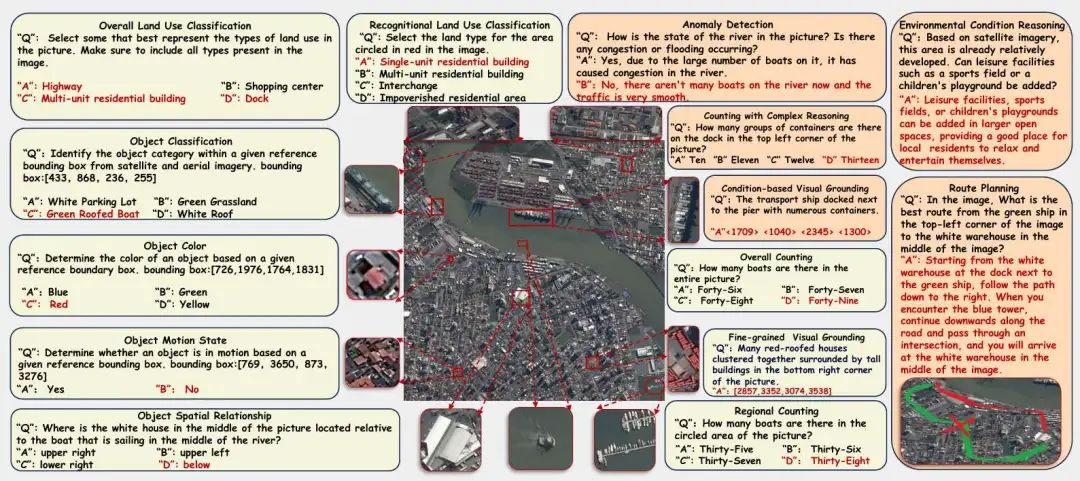
核心创新点:
1. 超大规模高分遥感基准构建
首创XLRS-Bench基准,包含1,400张平均分辨率8,500×8,500像素的超大遥感影像,覆盖检测(DOTA-v2)与分割(MiniFrance)数据源
45位专家标注45,942条多模态标注,含32,389组视觉问答(VQA)、12,619个视觉定位(Visual Grounding)实例及934条细粒度图像描述
支持中英双语,超越现有遥感基准的单语限制
2. 多维度认知评估体系
设计3级评估框架(感知/推理能力),包含16个子任务:
感知维度:目标分类、颜色识别、运动状态检测、区域定位等
推理维度:环境条件推理、复杂计数推理、时空变化检测等
异常检测等高级认知任务
3. 模型性能突破性发现
揭示现有MLLMs(如Qwen2-VL、LLaVA)在超高分场景的关键瓶颈:
分辨率敏感性:高分辨率输入模型(Qwen2-VL)显著优于CLIP-based模型
推理局限性:复杂场景的抽象推理(如区域级变化检测)准确率低于60%
语义鸿沟:GPT-4o在遥感场景描述中出现31%的推理误差
4. 方法论创新
提出半自动化标注流水线,实现细粒度描述扩展
采用"红圈标注法"进行区域级标注,增强人机交互标注精度
开源多模态评估协议,支持模型横向对比(已集成20+主流模型)
Advances and Challenges in Foundation Agents
论文标题:Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
论文链接:https://arxiv.org/abs/2504.01990
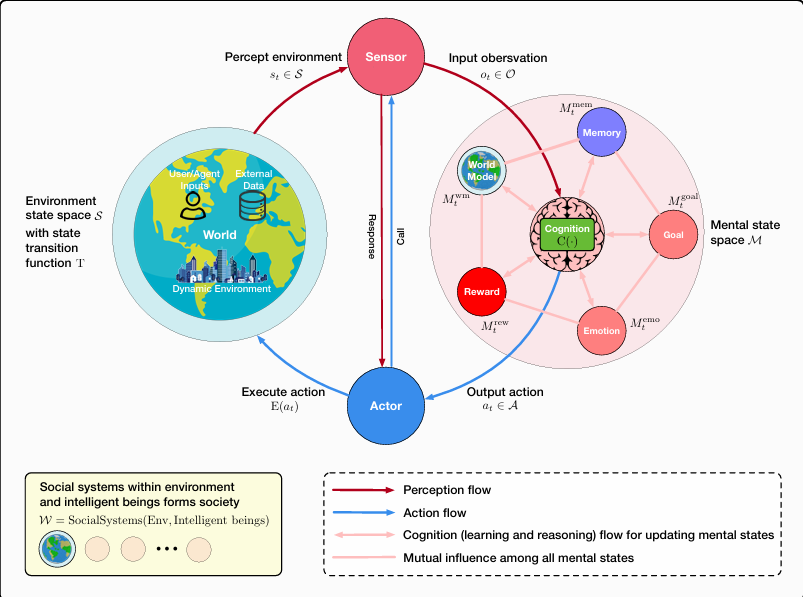
核心创新点:
1. 结构化经验评估与优化循环(Structured Experience Evaluation)
动态知识适应框架 :提出"Chain-of-Knowledge"机制,通过动态整合异构知识源(如科学文献、代码库)提升LLM的推理可靠性
迭代式自我进化 :Mobile-Agent-E框架实现移动助手在复杂任务中的自主进化能力,结合RLHF(Reinforcement Learning from Human Feedback)与ReFT(Reasoning Fine-Tuning)技术
2. 工具增强的推理范式(Tool-Augmented Reasoning)
神经符号系统集成 :CREATOR框架通过四阶段生命周期(Creation-Decision-Execution-Rectification)实现工具多样性与错误恢复机制,分离抽象/具象推理过程
定制化工具蒸馏 :CRAFT框架采用离线范式将领域数据蒸馏为原子工具集(如目标颜色检测),支持跨模态任务
3. 多智能体协作机制(Multi-Agent Collaboration)
分层决策架构 :StraGo框架引入战略引导优化(Strategic Guidance),通过状态驱动工作流(State-Driven Workflow)提升任务求解效率
群体辩论优化 :GroupDebate框架实现多智能体辩论中的动态角色分配(验证者/参与者),结合信息熵阈值控制提升决策鲁棒性
4. 科学发现自动化(Automated Scientific Discovery)
自主实验系统 :ChemOS 2.0与AlabOS框架集成LLM与机器人实验平台,实现化学空间的高效探索
假设生成验证 :SciAgents采用多智能体图推理机制,结合LSTM-GNN混合架构加速材料发现
5. 安全强化技术(Safety Enhancement)
对抗样本防御 :提出CRINGE损失函数(Cringe Loss)与对抗性文档阻断(Blocker Documents)技术,抵御RAG系统的知识投毒攻击
认知边界约束 :通过内省式记忆编码(ExpeL)与选择性注意力机制(Selective Attention Agent)限制LLM的推理风险
6. 评估基准创新(Benchmark Development)
抽象推理评估 :ARC Challenge验证LLM的归纳推理能力,GPT-4o仅达19%准确率,凸显小样本学习瓶颈
科学任务基准 :ScienceAgentBench包含102项跨学科任务,揭示当前LLM在数据驱动科学发现中的局限性
本文均出出自『自动驾驶之心知识星球』硬核资料在星球置顶链接,加入即可获取:
行业招聘信息&独家内推;
自驾学习视频&资料;
前沿技术每日更新;




















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









