




点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享清华联合华为诺亚方舟实验室最新的工作!NuGrounding:面向自动驾驶的环视3D视觉定位框架!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『多模态大模型』技术交流群
论文作者 | Fuhao Li等
编辑 | 自动驾驶之心
写在前面
多视角3D视觉定位对于自动驾驶车辆理解自然语言并定位复杂环境中的目标物体至关重要。然而,现有的数据集和方法受限于粗粒度的语言指令,且未能充分集成3D几何推理与语言理解能力。为此,我们提出了NuGrounding,这是首个面向自动驾驶的多视角3D视觉定位大规模基准数据集。为了构建NuGrounding,我们提出了一种层次化构建(HoG)方法,生成分层的多级指令,确保覆盖人类语言模式。为了解决这一挑战性数据集,我们提出了一种新颖的范式,巧妙地将多模态大语言模型的指令理解能力与专有检测模型的精确定位能力结合起来。我们的方法引入了两个解耦的任务token和一个上下文query,用以聚合3D几何信息和语义指令,随后通过融合解码器精炼空间-语义特征,从而实现精确定位。实验表明我们的方法在精度和召回率上分别达到了0.59和0.64,相较于适配后的主流3D场景理解模型,分别提高了50.8%和54.7%。
领域介绍
多视角3D视觉定位在自动驾驶车辆通过自然语言指令理解驾驶环境方面发挥着重要的作用。这一过程涉及将多视角图像和文本指令分析集成到统一的3D物体定位框架中,架起了人类意图与机器感知之间的桥梁。通过促进以人为中心的场景理解,它为更安全、更直观的人车交互开辟了道路。
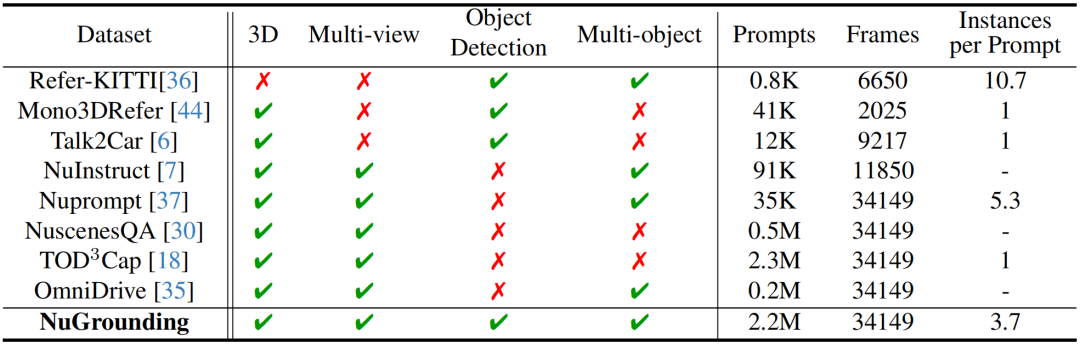
尽管基于语言的自动驾驶系统已经取得了显著进展,现有的数据集由于指令过于简化、规模有限以及任务粗粒度,无法满足多视角3D视觉定位的需求。如表1所示,先前的视觉定位数据集仅关注2D像素级的物体定位,缺乏3D几何表示;而其他数据集则集中于单视角图像,忽视了整体的多视角场景理解。此外,这些数据集在指令的多样性和数量上也存在不足,无法涵盖广泛的场景。最近的研究主要解决了场景级任务(如视觉问答)或单物体描述任务(如稠密标注),但无法应对实例级的多物体定位任务。
为填补这些空白,我们引入了NuGrounding数据集,这是首个面向自动驾驶的多视角3D视觉定位大规模基准数据集。与先前的工作不同,NuGrounding支持多物体、实例级定位,并在文本指令的复杂性和数量上达到平衡。为构建该数据集,我们通过自动标注和少量人工验证,从NuScenes中收集了物体属性。接着,我们提出了层次化构建(HoG)方法,用以生成分层的多级文本指令。
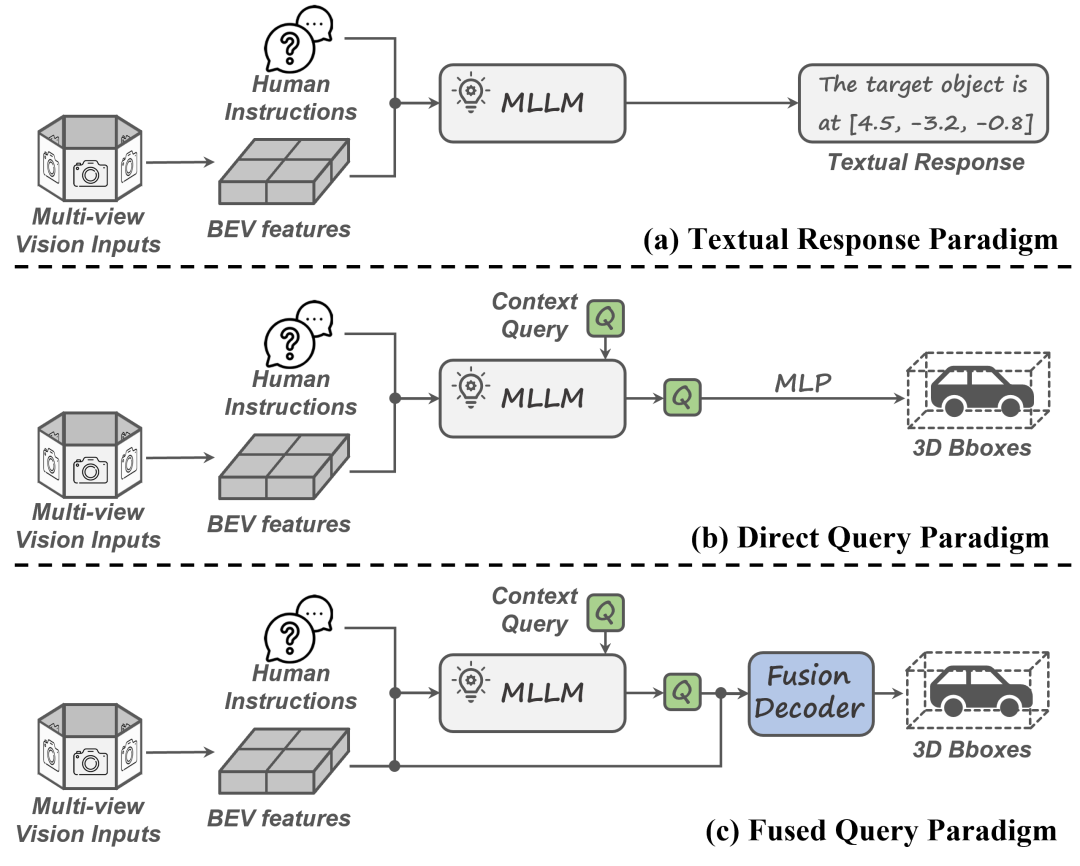
多视角3D视觉定位任务需要同时具备复杂的人类指令理解和精细的场景理解。如图1(a)所示,先前的研究通常将多视角图像编码为BEV特征,并将3D空间推理能力集成到多模态大语言模型中。然而,这些方法主要关注于生成文本,限制了其在精准定位物体的效果。如图1(b)所示,最近的方法尝试通过3Dquery将LLM的隐藏层向量解码为3D框回归任务。然而,这些3Dquery位于语义向量空间中,缺乏细粒度的3D几何细节,从而阻碍了精确的3D定位。
为此,我们提出了一种多视角3D视觉定位框架,这是一种新颖的范式,巧妙地将多模态大模型的指令理解能力与专有检测模型的精准物体定位能力结合起来,如图1(c)所示。具体来说,我们首先采用基于BEV的检测器提取稠密的BEV特征,并生成带有3D几何先验的实例级物体query。其次,我们将单一任务token解耦为文本提示token和下游嵌入token,帮助我们预定义的上下文query聚合3D几何信息和语义指令。最后,我们引入了融合解码器,将语义信息与3D空间细节进行整合,从而预测物体边界框。该框架实现了复杂人类指令理解与多视角场景感知来进行精确的物体定位。
总体而言,我们的贡献可以总结为以下几点:
我们引入了NuGrounding数据集,这是首个面向自动驾驶的多视角3D视觉定位大规模数据集。为确保数据集的多样性、可扩展性和泛化能力,我们提出了层次化构建(HoG)方法来构建NuGrounding。
我们提出了多视角3D视觉定位框架,这是一种新颖的范式,巧妙地将多模态大模型的指令理解能力与专有检测模型的精确物体定位能力结合起来。
我们将现有的主流方法适配到NuGrounding数据集上并进行了评估,建立了一个全面的基准。实验结果表明,我们的方法显著超越了改编的基线,精度提高了50.8%,召回率提高了54.7%。
NuGrounding数据集
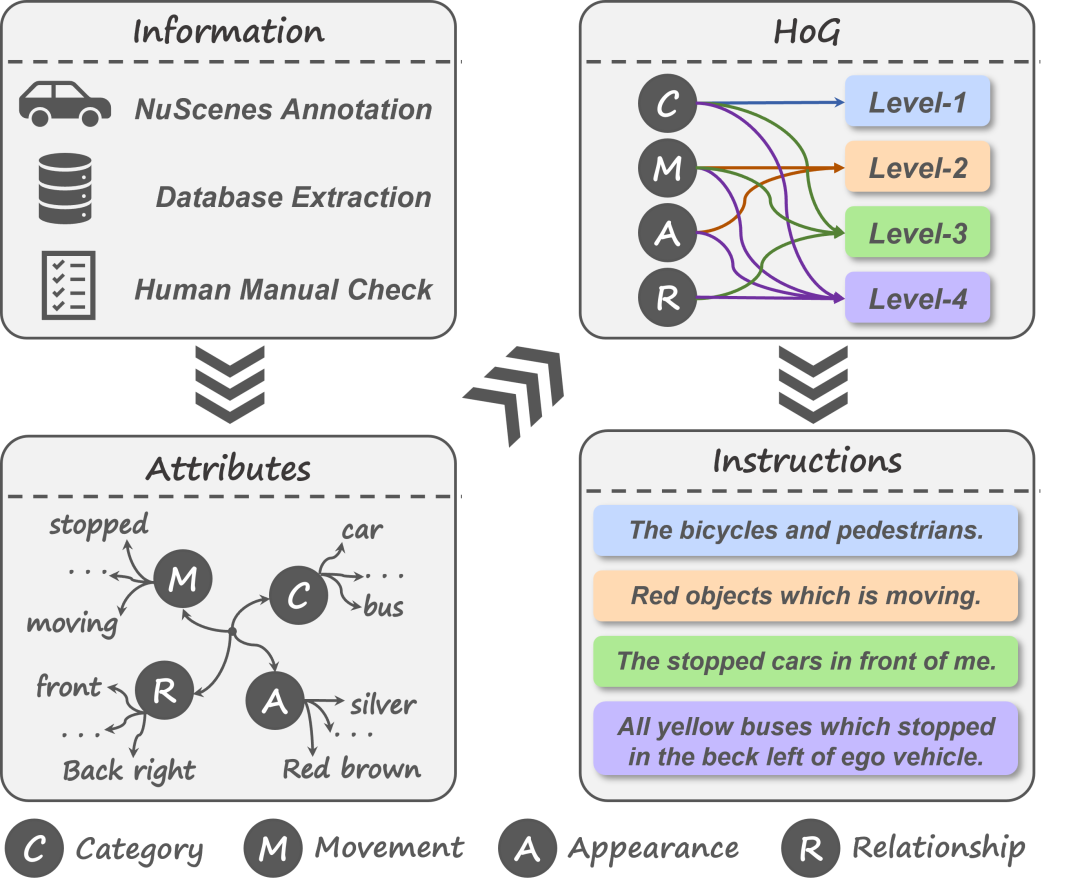
现有的驾驶视觉理解数据集由于提示过于简化、规模有限以及任务粗粒度,不适合用于多视角3D视觉定位。为了解决这些问题,我们提出了首个多视角3D视觉定位数据集NuGrounding,该数据集基于NuScenes构建。此外,我们还提出了层次化构建(HoG)方法,用于生成分层的多级文本提示。具体如图2所示,我们首先为每个物体注释多种的常见属性。然后,将这些属性填入HoG方法中,以获得文本指令。
物体属性采集
在用自然语言描述特定物体时,人们通常关注物体的固有属性:类别、外观、运动状态和相对于自车的空间关系。因此,我们对这四种属性类型进行了实例级标注。类别:我们采用了NuScenes中十个常见的物体类别。外观:NuPrompt手动注释了视频序列中的颜色信息,TOD3Cap则使用预训练的标注模型进行自动化的颜色提取。我们将这两个数据集中的颜色标注合并,并对不一致的标注进行细致的人工验证。运动属性:我们通过计算帧间位移来估计物体的速度,并使用0.3 m/s的阈值将运动状态分为移动和静止。空间关系:我们遵循NuScenesQA的做法,定义了六种关系,分别对应六个相机视角。每种关系在鸟瞰图平面内涵盖一个60°的视场角,以确保唯一性。
文本分层构建
在采集了实例级属性之后,我们结合这些属性,通过提出的层次化构建方法(HoG)生成场景级文本提示。HoG方法不仅能够涵盖各种人类指令,还能有效防止归纳偏差,如下两点所述。
首先,人们往往通过共享属性描述一组物体(我周围的行人),但通过独特的属性组合来定位特定物体(我左前方正在移动的红色轿车)。属性组合的数量与指示的特定性和提示的复杂性相关。这启发了我们采用分层提示生成策略,通过控制堆叠属性的数量,生成多个难度级别的提示,从而更全面地覆盖人类描述模式。
其次,若没有层次结构地结合所有四种属性类型,可能会导致归纳偏差。例如,在只有一辆车的场景中,“我左前方正在移动的红色轿车”和“那辆车”指的是同一物体。如果在大量此类样本上进行训练,可能会引导模型只关注类别属性,而忽视其他属性,从而导致偏差学习。这强调了属性解耦和多层次层次化构建的重要性。
具体而言,我们通过选择不同的属性组合生成了 种模板。选择 个属性类型的模板称为 -级提示。然后,我们遍历当前场景中物体的所有选择属性,并将它们填入模板中,生成语义表达,如图2所示。
数据统计
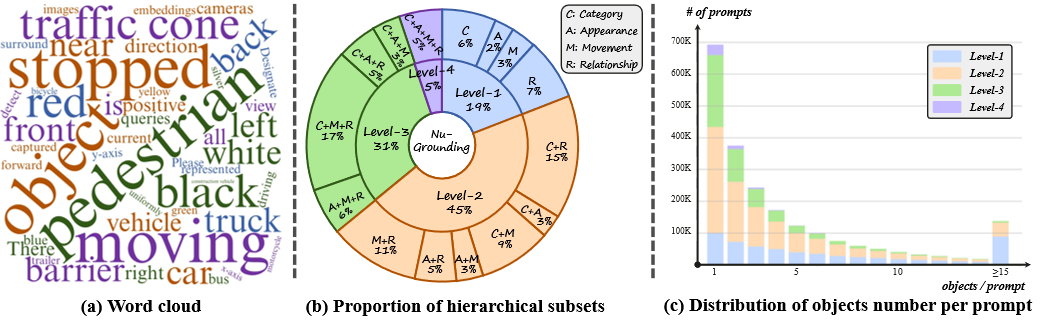
NuGrounding从NuScenes中的850个视频中提取了34,149个关键帧,生成了220万个文本提示(每帧63.7个提示)。数据集分为180万个用于训练的提示和40万个用于测试的提示。值得注意的是,NuGrounding通过分层生成具有不同属性组合的提示,以平衡难度级别。如图3(b)所示,每个层的子集保持大致相等的比例,提高泛化能力并防止模型采用文本捷径。此外,NuGrounding支持每个提示多物体引用,每个提示平均引用3.7个物体,如图3(c)所示。
方法论
在自动驾驶场景中的3D视觉定位任务要求具备以下综合能力:多视角场景感知、复杂人类指令理解、精确的3D物体定位。然而,现有的3D检测模型缺乏理解人类指令的能力,而多模态大语言模型在物体定位的精度上存在不足。为此,本文提出了一种新颖的框架,将多模态大模型的指令理解能力与专业检测模型的精确物体定位能力相结合。该框架能够同时实现复杂的人类指令理解和准确的物体定位。
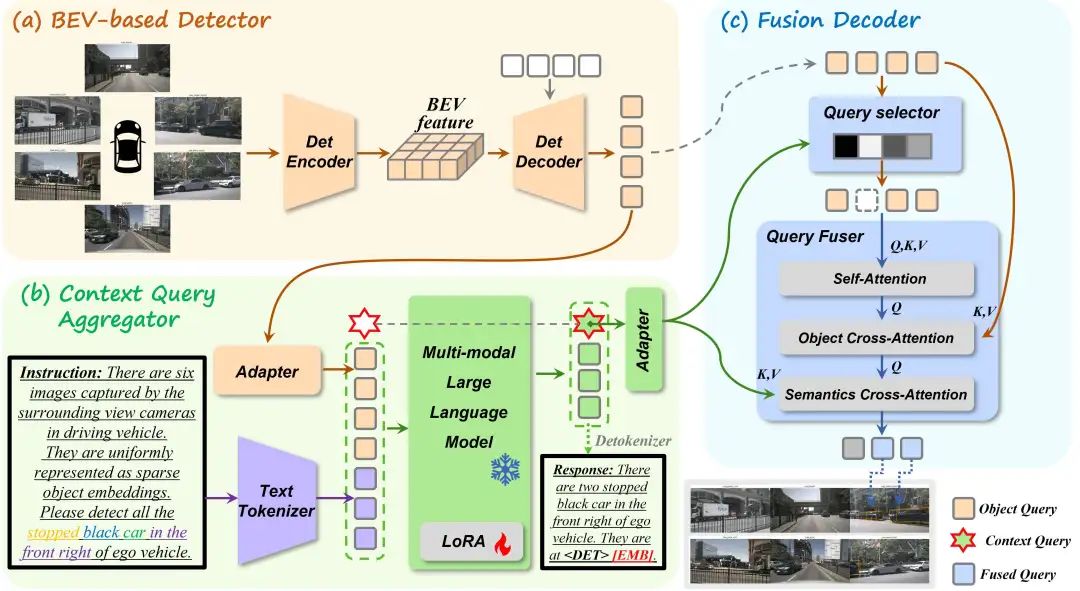
整体结构
我们方法的架构如图4所示。首先,在基于BEV的检测器中,采用了专用的检测编码器,从多视角图像中提取稠密的BEV特征,随后通过基于query的检测解码器,利用提取的特征生成稀疏的实例级物体query。其次,在上下文query聚合器中,物体query作为稀疏的场景表示,连同文本指令一起输入到多模态大语言模型中。此外,我们引入了两个独立的任务token与一个可学习的上下文query。在生成文本响应时,MLLM依据任务token将3D场景信息和文本指令聚合到该上下文query中。最后,在融合解码器中,物体query根据其与上下文query的相关性进行过滤,以消除语义无关的实例级噪声。选定的query通过与所有物体query交互增强其空间信息,并通过与上下文query交互整合语义信息,最终生成融合后的query。最终,这些融合query通过专用目标解码器进行解码。
基于BEV的检测器
根据多视角三维检测方法,基于BEV的检测器通过构建BEV特征提取多视角图像信息,并将其转化为实例级的物体query。
检测编码器。 首先,将多视角图像输入到图像主干网络 中,以提取图像特征。随后,根据相机的投影矩阵,将图像特征转换到网格状的BEV平面,从而构建BEV特征。
检测解码器。 我们初始化一组可学习的三维锚点作为物体query
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









