






点击下方卡片,关注“具身智能之心”公众号
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
获取大规模、多样且具具身性的机器人训练数据成本高昂,如收集真实世界人形机器人数据耗费大量人力和时间,单一人形硬件的数据量远不足以训练通用模型。同时,现有机器人学习社区尝试的跨实体学习,因机器人在硬件、传感器、控制模式等方面差异大,形成 “数据孤岛”,无法提供连贯、大规模的数据集。

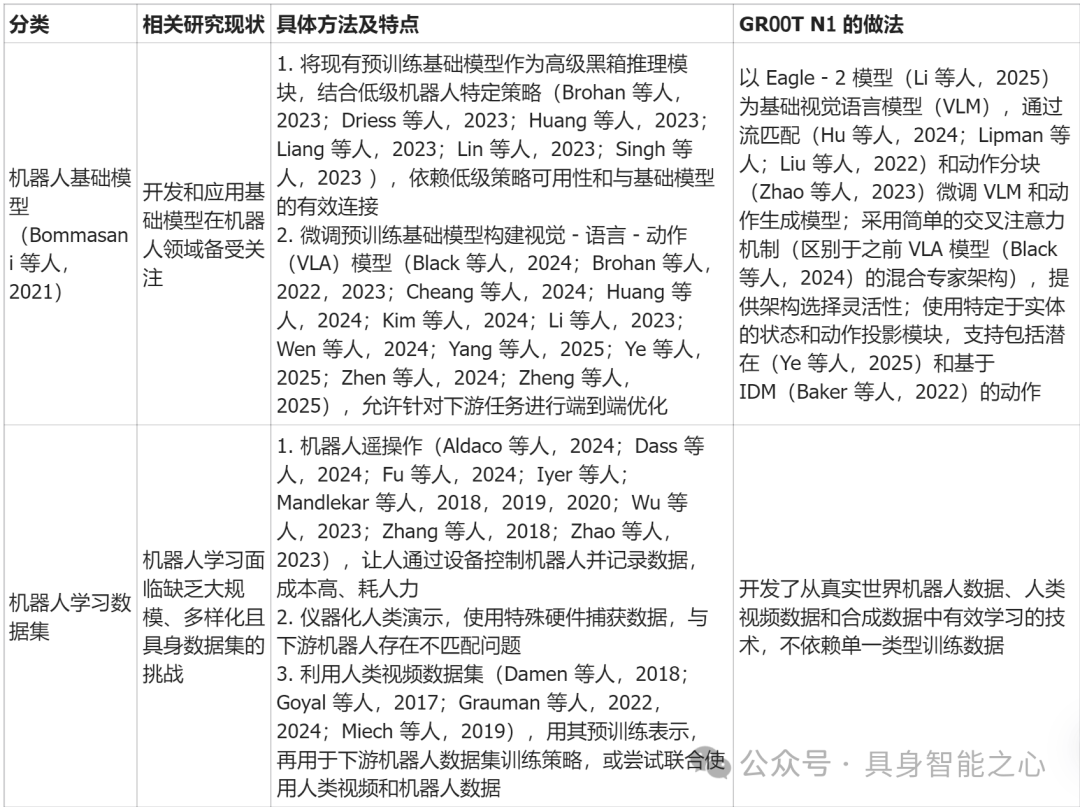
因此希望开发通用人形机器人模型,需使其具备强大的泛化能力,能在复杂多变的现实世界中理解任务、处理新情况并快速学习新任务。传统方法在实现这些能力上存在不足,例如将现有预训练基础模型作为高级推理模块结合低级机器人特定策略的方式,依赖低级策略的可用性和有效接口连接;而微调预训练基础模型构建视觉 - 语言 - 动作(VLA)模型时,部分模型架构在连接 VLM 规划和低级控制时不够灵活。
针对以上困难,NVIDIA 出手了!
推出用于通用人形机器人的开源基础模型GR00T N1,它是一个VLA模型,采用双系统架构,通过融合真实机器人轨迹、人类视频和合成数据集进行训练。

创新的数据处理策略
构建数据金字塔:将训练语料库组织成数据金字塔,融合多源数据,使模型能学习通用知识并在真实执行中落地。
数据生成与标注创新:训练 VQ-VAE 和逆动力学模型标注无动作数据,利用视频生成模型和 DexMimicGen 生成神经和模拟轨迹,扩充并提升数据质量。
创新的模型架构设计
双系统架构:采用由基于 VLM 的推理模块和基于 DiT 的动作模块组成的双系统架构,紧密耦合、联合优化,促进推理和执行协调。
灵活的模块设计:用 MLP 适应不同机器人差异,Diffusion Transformer 模块结合视觉 - 语言令牌嵌入生成动作,采用简单交叉注意力机制增加架构灵活性。
创新的训练策略
统一的训练框架:通过流匹配损失端到端预训练,跨越数据金字塔多层,学习多样化操作行为。
多阶段训练:预训练后针对单实体微调,并在后训练中用神经轨迹增强数据,提升低数据场景学习能力。
如果您对VLA系列内容感兴趣,也欢迎学习我们的VLA算法与理论课程:国内首个系统面向工业与科研的具身智能VLA课程!(戳我)
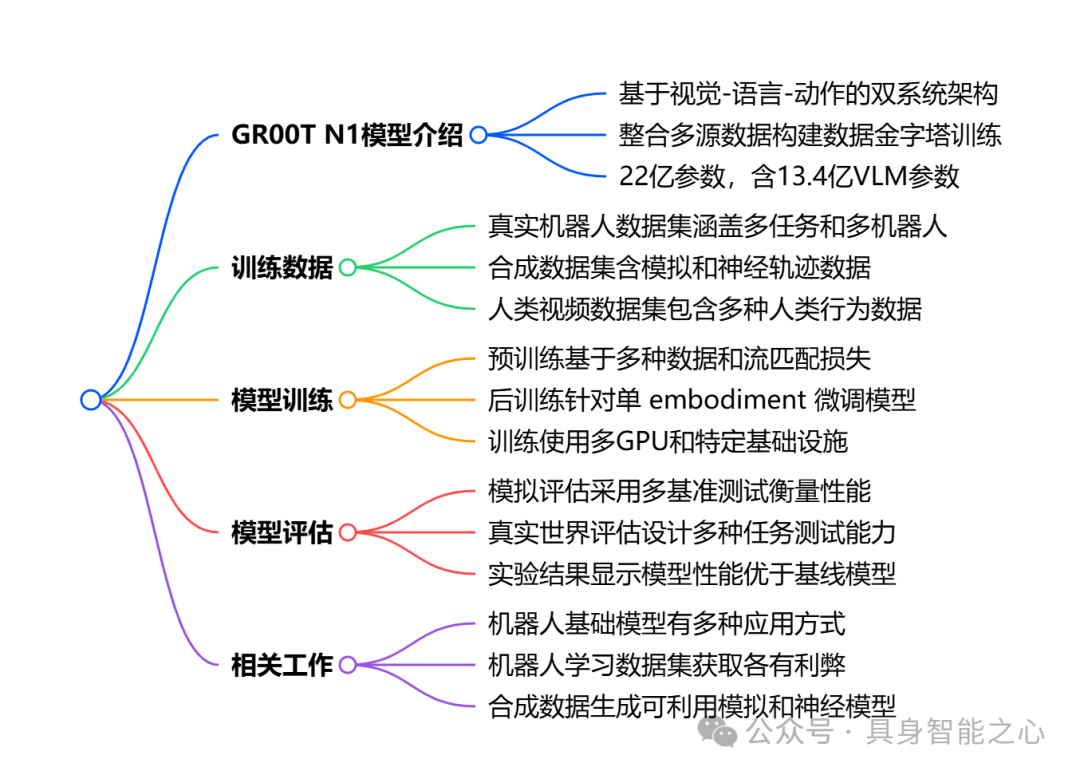
相关工作

模型架构
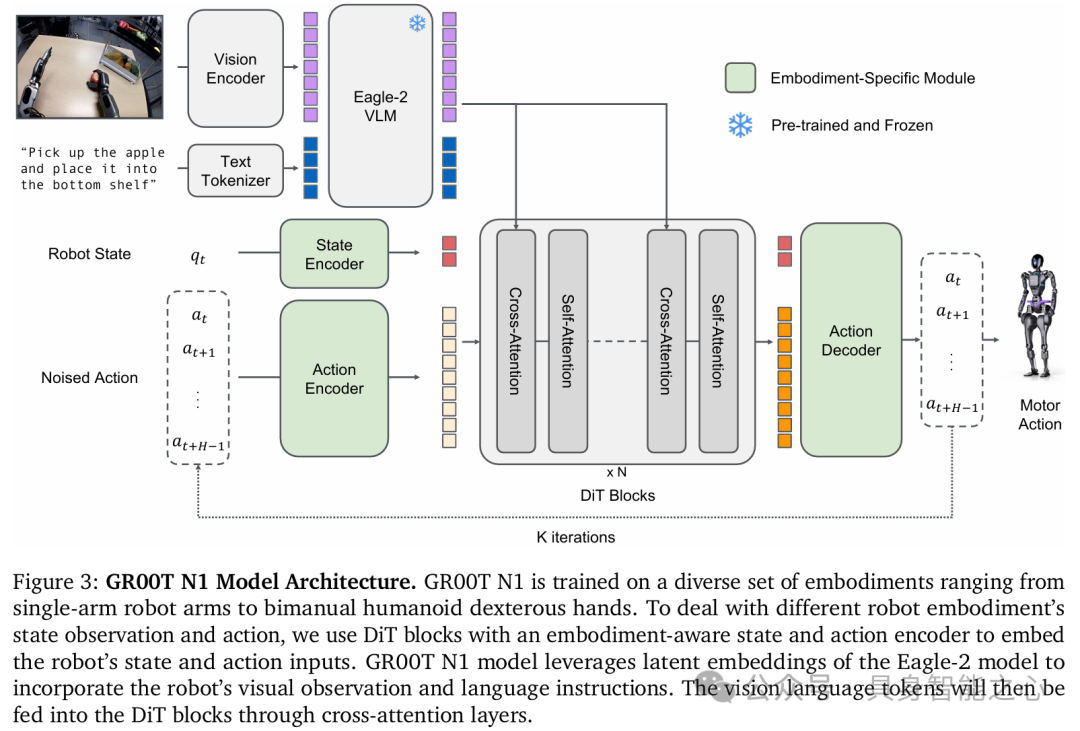
GR00T N1 是一个专为通用人形机器人设计的视觉 - 语言 - 动作(VLA)模型,其模型架构主要由状态和动作编码器、视觉 - 语言模块(System 2)、扩散Transformer模块(System 1)构成,各部分紧密协作,使机器人能根据视觉和语言输入生成合适动作。
状态和动作编码器:为处理不同机器人实体状态和动作的维度差异,模型针对每个实体使用 MLP 将其投影到共享嵌入维度,作为扩散Transformer(DiT)的输入。其中,动作编码器 MLP 会将扩散时间步与带噪动作向量一同编码。模型以带噪动作、机器人本体感受状态编码、图像令牌和文本令牌作为输入,按固定长度分块处理动作(文中设定长度H=16 )。
视觉 - 语言模块(System 2):选用经互联网规模数据预训练的 Eagle-2 视觉语言模型来编码视觉和语言输入。该模型由 SmolLM2 和 SigLIP-2 图像编码器微调而来,先将 224×224 分辨率的图像编码并经像素洗牌操作,得到每帧 64 个图像令牌嵌入,再与文本一起由 Eagle-2 VLM 的 LLM 组件进一步编码。在策略训练时,任务文本描述和图像以聊天格式输入 VLM,模型从 LLM 的中间层(GR00T-N1-2B 使用第 12 层)提取视觉 - 语言特征,这样能实现更快推理速度和更高下游策略成功率。
扩散Transformer模块(System 1):采用 DiT 的变体对动作进行建模,该变体通过自适应层归一化实现去噪步长条件,标记为 V_theta 。它包含交替的交叉注意力和自注意力块,自注意力块作用于带噪动作令牌嵌入和状态嵌入,交叉注意力块则依据 VLM 输出的视觉 - 语言令牌嵌入进行条件设定。在最后一个 DiT 块之后,使用特定于实体的动作解码器(另一个 MLP)对最后 H 个令牌进行处理,以预测动作。模型训练时通过最小化流匹配损失,使预测目标逼近去噪向量场;推理时采用 K 步去噪(实践中K = 4效果良好),从随机采样开始,利用前向欧拉积分迭代生成动作块。
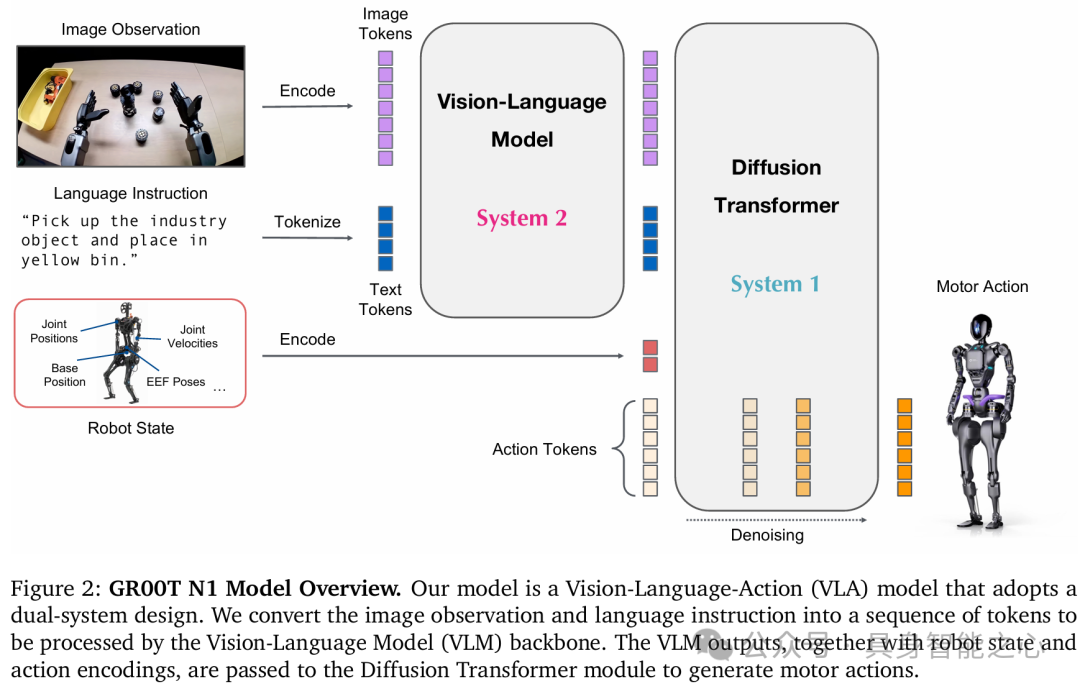
图 3 呈现了GR00T N1 模型从输入到输出的完整处理流程以及各模块间的协作关系,具体如下:
输入模块:模型输入包含视觉信息、文本指令和机器人状态。视觉信息经 Embodiment-Specific Module 处理,文本指令经 Tokenizer 转化为文本 Tokens。机器人状态通过 State Encoder 编码为q_t,为后续动作生成提供基础信息。
核心处理模块:Eagle-2 VLM 作为预训练且冻结的组件,接收视觉和文本 Tokens,融合并处理信息,输出包含环境和任务理解的特征。这些特征与机器人状态编码q_t一同进入 DiT Blocks。DiT Blocks 由多个交替的 Cross-Attention 和 Self-Attention 块组成,通过对输入信息的交互和处理,捕捉关键信息,为动作生成提供支持。
动作生成模块:在 DiT Blocks 处理后,信息传递给 Action Decoder。Action Decoder 根据接收到的信息,结合模型学习到的知识和策略,输出最终的 Motor Action,即机器人执行任务所需的动作。
训练反馈模块:训练过程中,模型会根据输入和真实动作计算损失。这里的 Noised Action Encoder 对动作添加噪声后参与计算,通过调整模型参数使损失最小化,优化模型性能,以提高动作生成的准确性和适应性。
数据来源
为训练 GR00T N1 模型,构建了一个数据金字塔,涵盖多种来源的数据。
真实世界数据集:包括 GR00T N1 Humanoid Pre-Training Dataset、Open X-Embodiment、AgiBot-Alpha 等。这些数据集包含了不同机器人在真实环境中执行各种任务的轨迹,如操作物体、导航等。

合成数据集:
模拟轨迹:使用 DexMimicGen 在 RoboCasa 框架下生成。通过少量人类演示,自动扩展生成大规模模拟轨迹数据,补充真实机器人数据的不足。
神经轨迹:利用微调后的开源图像到视频生成模型生成。将内部收集的 88 小时遥操作轨迹扩充到 827 小时,增加了数据的多样性和数量。

人类视频数据集:如 Ego4D、Ego-Exo4D 等多个数据集。

图 4 展示的是数据生成的流程。例如,对于人类视频数据,先通过 VQ-VAE 模型提取潜在动作,再利用逆动力学模型推断伪动作,从而将其转化为可用于训练的带动作标注的数据。对于合成数据,展示了如何通过 DexMimicGen 生成模拟轨迹以及利用图像到视频生成模型生成神经轨迹的过程。

训练流程
预训练:在预训练阶段,模型在多种来源的数据上进行训练,包括标注的视频数据集、合成生成的数据集和真实机器人轨迹。通过流匹配损失(flow matching loss)对模型进行端到端的训练,使模型能够学习到多样化的操作行为。预训练过程跨越数据金字塔的不同数据层,以实现对不同类型数据的有效利用。
后训练:预训练后,针对每个单实体(single-embodiment)数据集对预训练模型进行微调(post-training)。在后训练中,还探索了使用神经轨迹增强数据的方法,为每个下游任务生成神经轨迹,并根据任务需求调整视频模型生成多视图或长视野轨迹,以提高模型在低数据场景下的学习能力。训练过程中使用了 NVIDIA OSMO 管理的集群和多 GPU,以提高训练效率。
实验如何进行的
通过模拟评估和真实世界评估两方面来衡量 GR00T N1 模型的性能。模拟评估在虚拟环境中进行,以量化模型在不同任务和场景下的表现;真实世界评估则在实际的机器人硬件上执行任务,检验模型的实际应用能力。
评估基准
模拟基准测试:
RoboCasa Kitchen:模拟家庭厨房环境,包含多种与厨房相关的任务,如打开橱柜、拿取餐具等,用于评估模型在复杂环境中执行多步骤任务的能力。
DexMimicGen Cross-Embodiment Suite:该基准测试专注于评估模型在不同机器人实体(embodiment)之间的泛化能力,通过在多种模拟机器人上执行相同或相似任务来测试。
GR-1 Tabletop Tasks:设置了一系列桌面操作任务,如摆放物体、操作开关等,以评估模型对精细操作的掌握程度。
真实世界基准测试:设计了多种真实世界的桌面操作任务,包括开门、使用工具、摆放物品等,在真实的类人机器人上进行测试,检验模型在实际环境中的执行能力和适应性。
评估结果
模拟评估结果:GR00T N1 模型在多个模拟基准测试中表现优于基线模型。例如在 RoboCasa Kitchen 任务中,GR00T N1 能够更高效、准确地完成多步骤任务,成功率明显高于 BC-Transformer 和 Diffusion Policy;在 DexMimicGen Cross-Embodiment Suite 基准测试中,GR00T N1 展现出更好的跨实体泛化能力。

真实世界评估结果:在真实世界的桌面操作任务中,GR00T N1 模型也取得了较好的成绩。它能够更稳定地执行各种任务,对环境的适应性更强,部分任务的完成质量和效率超过了基线模型。此外,实验还表明,使用神经轨迹增强训练数据可以进一步提升 GR00T N1 模型在低数据场景下的学习能力和任务执行性能。

表 2 主要呈现了 GR00T N1 模型在不同实验设置下,于模拟基准测试中的详细性能数据。在这些模拟基准测试中,GR00T N1 模型的表现优于两个基线模型(BC-Transformer 和 Diffusion Policy)。特别是在 GR-1 任务中,GR00T N1 模型的优势更为明显,其成功率比基线模型高出了超过 17% 。这表明 GR00T N1 模型在模拟环境下执行任务时,相较于其他对比模型,能够更稳定、高效地完成任务,尤其是在 GR-1 任务所代表的特定类型任务中,展现出了显著的性能优势。
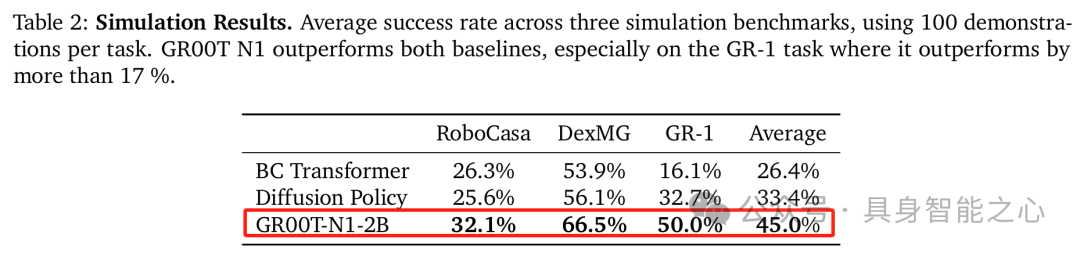
表 3 中的数据是关于真实世界任务的结果。在真实世界任务中,GR00T N1 模型的表现击败了扩散策略(Diffusion Policy)这一基线模型。并且,即使在数据量非常少的情况下,GR00T N1 模型依然展现出了强劲的结果。这表明 GR00T N1 模型在实际的类人机器人操作场景中,相较于扩散策略基线模型,能够更可靠地完成任务,同时也体现了该模型在数据稀缺条件下良好的学习能力和适应性,即不需要大量的真实世界数据就能取得较好的任务执行效果。
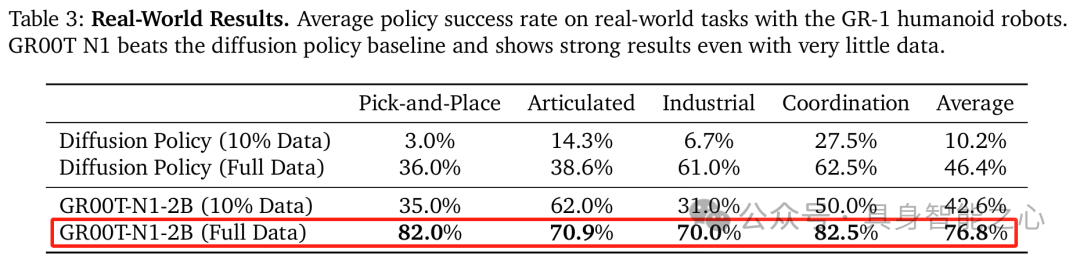
图 9 综合展示了 GR00T N1 模型在模拟和真实世界环境中的性能,表明该模型在不同数据量条件下均优于基线模型,具有较高的数据效率,即使在数据稀缺时也能表现出色。同时,强调了神经轨迹增强训练数据以及合适的动作标注方式对提升模型性能的重要性,为进一步优化模型和应用于实际场景提供了有价值的参考。
回顾一下亮点
文章是如何解决“人形机器人训练数据缺失”这个难题的?
文章通过多种方式解决人形机器人训练数据缺失难题。构建数据金字塔,融合网络数据、人类视频、合成数据和真实世界数据,提供丰富先验并保证真实应用。利用 VQ-VAE 模型生成潜在动作标注,微调视频生成模型得到神经轨迹,使用 DexMimicGen 生成模拟轨迹,扩充数据。采用统一训练框架,通过流匹配损失端到端预训练,结合多阶段训练,预训练后针对单实体微调,利用神经轨迹增强数据,提升低数据场景学习能力,有效缓解了数据缺失问题。
在训练数据不足的情况下,GR00T N1 如何提高性能?
在训练数据不足时,GR00T N1 通过多种方式提高性能。利用数据金字塔结构,从多种数据源获取数据;使用神经轨迹增强训练数据,如在 post-training 阶段生成神经轨迹扩充数据;采用预训练和微调策略,在预训练阶段学习通用知识,后训练针对特定任务微调,提高模型适应性。
GR00T N1 模型的创新点有哪些?
GR00T N1 模型的创新点包括采用双系统架构,将基于 VLM 的推理模块和基于 Diffusion Transformer 的动作模块统一学习;构建数据金字塔,融合多种数据进行训练;利用视频生成模型和自动化轨迹合成系统生成大规模数据,增强模型泛化能力。
与其他机器人基础模型相比,GR00T N1 的优势体现在哪里?
与其他模型相比,GR00T N1 优势明显。它采用简单的交叉注意力机制连接 VLM 和动作生成模型,更具灵活性;使用 embodiment-specific 的状态和动作投影模块,支持多种机器人 embodiment;在模拟和真实世界实验中,性能优于 BC-Transformer 和 Diffusion Policy 等基线模型,数据效率更高。
参考文献
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
https://arxiv.org/pdf/2503.14734

“具身智能之心”公众号持续推送具身智能领域热点:
往期 · 推荐
机械臂操作
优于现有SOTA!PointVLA:如何将3D数据融入VLA模型?
北京大学最新!HybridVLA:打通协同训练,各种任务中均SOTA~
北京大学最新 | 成功率极高!DexGraspVLA:首个用于灵巧抓取的分层VLA框架
ICLR'25 | VLAS:将语音集成到模型中,新颖的端到端VLA模型(西湖大学&浙大)
清华大学最新!UniAct:消除异质性,跨域跨具身泛化,性能超越14倍参数量的OpenVLA
港大最新!RoboTwin:结合现实与合成数据的双臂机器人基准
伯克利最新!CrossFormer:一个模型同时控制单臂/双臂/轮式/四足等多类机器人
四足或人形机器人
Fourier ActionNet:傅利叶开源全尺寸人形机器人数据集&发布全球首个全流程工具链
斯坦福大学 | ToddlerBot:到真实世界的零样本迁移,低成本、开源的人形机器人平台
TeleAI&港科大最新!离线学习+在线对齐,扩散模型驱动的四足机器人运动
Robust Robot Walker:跨越微小陷阱,行动更加稳健!
斯坦福大学最新!Helpful DoggyBot:四足机器人和VLM在开放世界中取回任意物体
机器人学习
视觉强化微调!DeepSeek R1技术成功迁移到多模态领域,全面开源
UC伯克利最新!Beyond Sight: 零样本微调异构传感器的通用机器人策略
CoRL 2024 | 通过语言优化实现策略适应:实现少样本模仿学习
NeurIPS 2024 | BAKU:一种高效的多任务Policy学习Transformer
人形机器人专场!有LLM加持能有多厉害?看HYPERmotion显身手
NeurIPS 2024 | 大规模无动作视频学习可执行的离散扩散策略
波士顿动力最新!可泛化的扩散策略:能有效操控不同几何形状、尺寸和物理特性的物体
RSS 2024 | OK-Robot:在机器人领域集成开放知识模型时,真正重要的是什么?
MIT最新!还在用URDF?URDF+:一种针对机器人的具有运动环路的增强型URDF
VisionPAD:3DGS预训练新范式!三大感知任务全部暴力涨点
NeurIPS 2024 | VLMimic:5个人类视频,无需额外学习就能提升泛化性?
纽约大学最新!SeeDo:通过视觉语言模型将人类演示视频转化为机器人行动计划
CMU最新!SplatSim: 基于3DGS的RGB操作策略零样本Sim2Real迁移
LLM最大能力密度100天翻一倍!清华刘知远团队提出Densing Law
机器人干活总有意外?Code-as-Monitor 轻松在开放世界实时精确检测错误,确保没意外
斯坦福大学最新!具身智能接口:具身决策中语言大模型的基准测试
机器人控制
简单灵活,便于部署 | Diffusion-VLA:通过统一扩散与自回归方法扩展机器人基础模型
RoboMatrix:一种以技能为中心的机器人任务规划与执行的可扩展层级框架
港大DexDiffuser揭秘!机器人能拥有像人类一样灵巧的手吗?
TPAMI 2024 | OoD-Control:泛化未见环境中的鲁棒控制(一览无人机上的效果)
VLA
上海AI Lab最新!Dita:扩展Diffusion Transformer以实现通用视觉-语言-动作策略
北大最新 | RoboMamba:端到端VLA模型!推理速度提升3倍,仅需调整0.1%的参数
英伟达最新!NaVILA: 用于导航的足式机器人视觉-语言-动作模型
其他(抓取,VLN等)
TPAMI2025 | NavCoT:中山大学具身导航参数高效训练!
CVPR2025 | 长程VLN平台与数据集:迈向复杂环境中的智能机器人
CVPR2025满分作文!TSP3D:高效3D视觉定位,性能和推理速度均SOTA(清华大学)
模拟和真实环境SOTA!MapNav:基于VLM的端到端VLN模型,赋能端到端智能体决策
场面混乱听不清指令怎么执行任务?实体灵巧抓取系统EDGS指出了一条明路
北京大学与智元机器人联合实验室发布OmniManip:显著提升机器人3D操作能力
动态 3D 场景理解要理解什么?Embodied VideoAgent来揭秘!
NeurIPS 2024 | HA-VLN:具备人类感知能力的具身导航智能体
博世最新!Depth Any Camera:任意相机的零样本度量深度估计
真机数据白采了?银河通用具身大模型已充分泛化,基于仿真数据!
港科大最新!GaussianProperty:无需训练,VLM+3DGS完成零样本物体材质重建与抓取
VinT-6D:用于机器人手部操作的大规模多模态6D姿态估计数据集
机器人有触觉吗?中科大《NSR》柔性光栅结构色触觉感知揭秘!
波士顿动力最新SOTA!ThinkGrasp:通过GPT-4o完成杂乱环境中的抓取工作
LLM+Zero-shot!基于场景图的零样本物体目标导航(清华大学博士分享)
PoliFormer: 使用Transformer扩展On-Policy强化学习,卓越的导航器
具身硬核梳理
Diffusion Policy在机器人操作任务上有哪些主流的方法?
强化学习中 Sim-to-Real 方法综述:基础模型的进展、前景和挑战
墨尔本&湖南大学 | 具身智能在三维理解中的应用:三维场景问答最新综述
十五校联合出品!人形机器人运动与操控:控制、规划与学习的最新突破与挑战
扩散模型也能推理时Scaling,谢赛宁团队研究可能带来文生图新范式
全面梳理视觉语言模型对齐方法:对比学习、自回归、注意力机制、强化学习等
基础模型如何更好应用在具身智能中?美的集团最新研究成果揭秘!
关于具身智能Vision-Language-Action的一些思考
具身仿真×自动驾驶
视频模型For具身智能:Video Prediction Policy论文思考分析
性能爆拉30%!DreamDrive:时空一致下的生成重建大一统
真机数据白采了?银河通用具身大模型已充分泛化,基于仿真数据!
高度逼真3D场景!UNREALZOO:扩展具身智能的高真实感虚拟世界
MMLab最新FreeSim:一种用于自动驾驶的相机仿真方法
麻省理工学院!GENSIM: 通过大型语言模型生成机器人仿真任务
EmbodiedCity:清华发布首个真实开放环境具身智能平台与测试集!
华盛顿大学 | Manipulate-Anything:操控一切! 使用VLM实现真实世界机器人自动化
东京大学最新!CoVLA:用于自动驾驶的综合视觉-语言-动作数据集
ECCV 2024 Oral | DVLO:具有双向结构对齐功能的融合网络,助力视觉/激光雷达里程计新突破


















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









