



点击下方卡片,关注“自动驾驶之心”公众号
本周AAAI就要截稿了,最近arixv也逐渐放出来一些不错的工作。今天就为大家分享一些自动驾驶方向最新的工作,涉及OCC+3DGS、BEV+LLM、强化学习、协同感知等等,期待和大家一起学习交流~
GS-Occ3D
基于高斯泼溅的纯视觉自动驾驶3D占用重建
清华大学、奔驰等单位提出GS-Occ3D,首次实现纯视觉的大规模3D占用重建,在Waymo数据集上以0.56倒角距离(CD)刷新几何精度SOTA,训练效率达0.8小时,并实现零样本泛化性能超越激光雷达基线(Occ3D-nuScenes上IoU 33.4 vs. 31.4)。
论文标题:GS-Occ3D: Scaling Vision-only Occupancy Reconstruction for Autonomous Driving with Gaussian Splatting
论文链接:https://arxiv.org/abs/2507.19451
项目主页:https://gs-occ3d.github.io/
主要贡献:
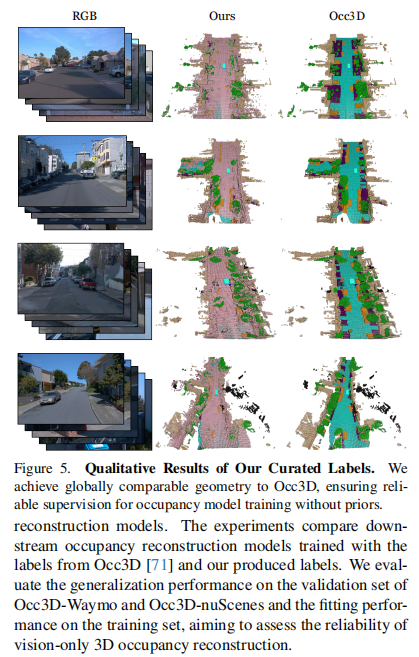
提出了可扩展的纯视觉占用标签生成管道,摆脱对 LiDAR 标注的依赖,支持利用大规模众包数据进行自监督标注,为下游占用感知模型提供支持。
实现了对地面、静态背景和动态物体的有效重建,性能超越现有方法,甚至优于 LiDAR 监督的基线模型,在长轨迹和复杂场景中保持高几何保真度。
首次采用纯视觉方法重建整个 Waymo 数据集,验证了其生成的标签在 Occ3D-Waymo 下游模型训练中的有效性,并在 Occ3D-nuScenes 上展现出更优的零样本泛化能力,凸显了大规模自动驾驶场景应用的可扩展性。
算法框架:
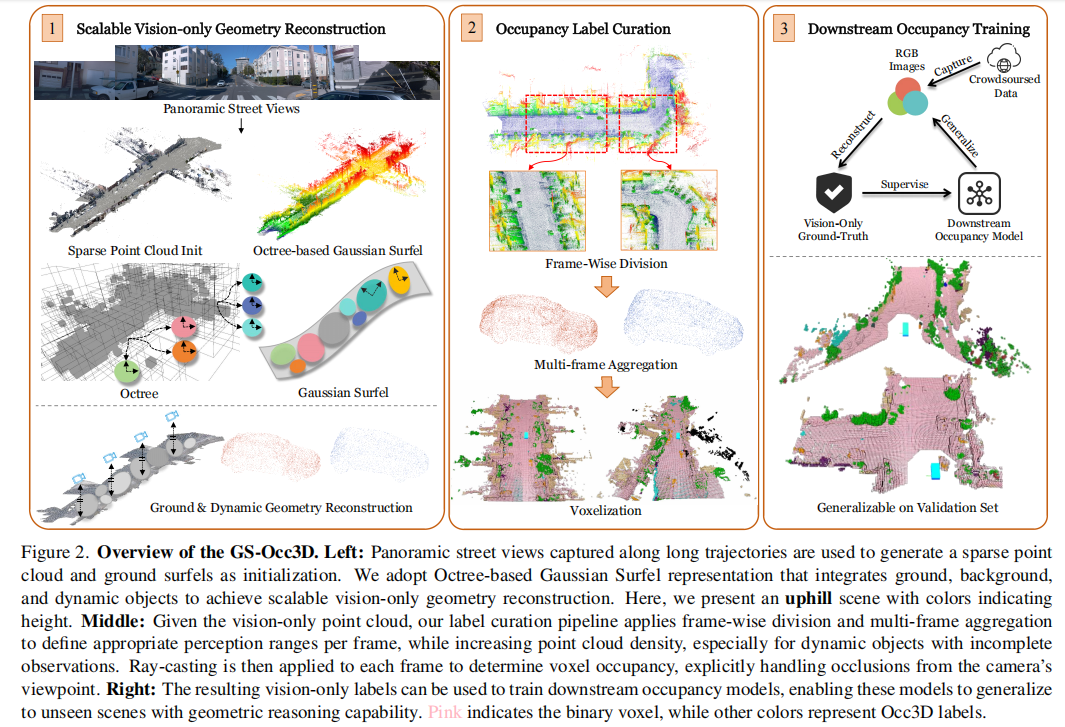
实验结果:
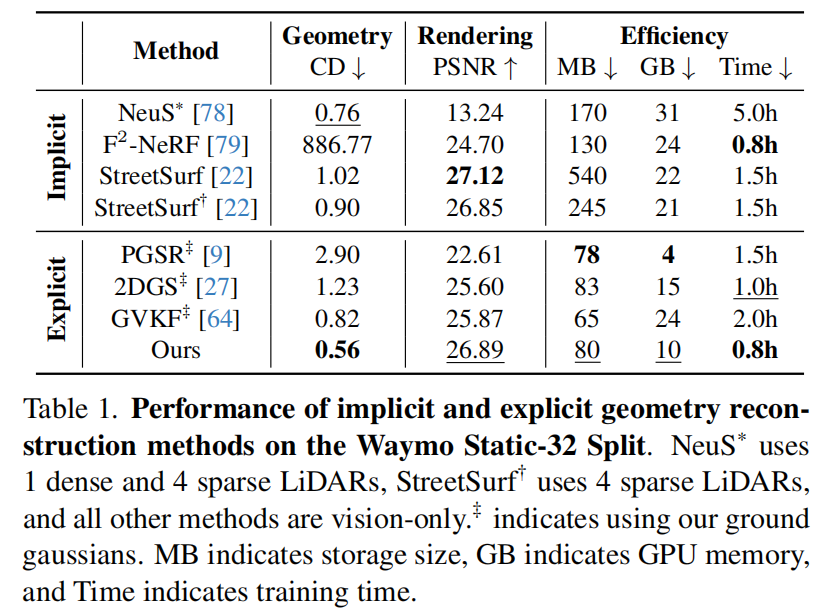
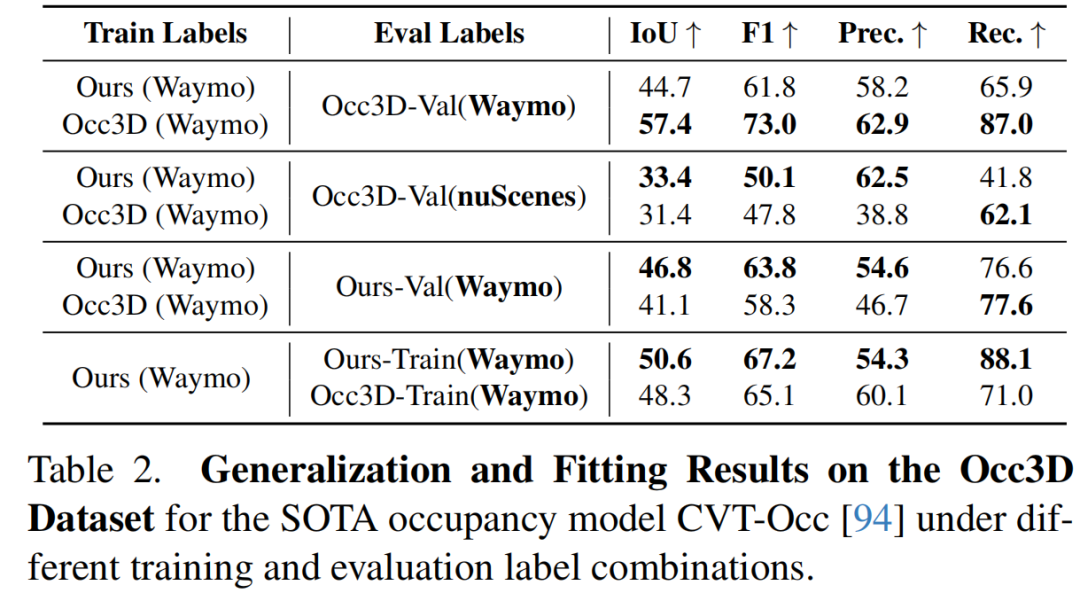
可视化:
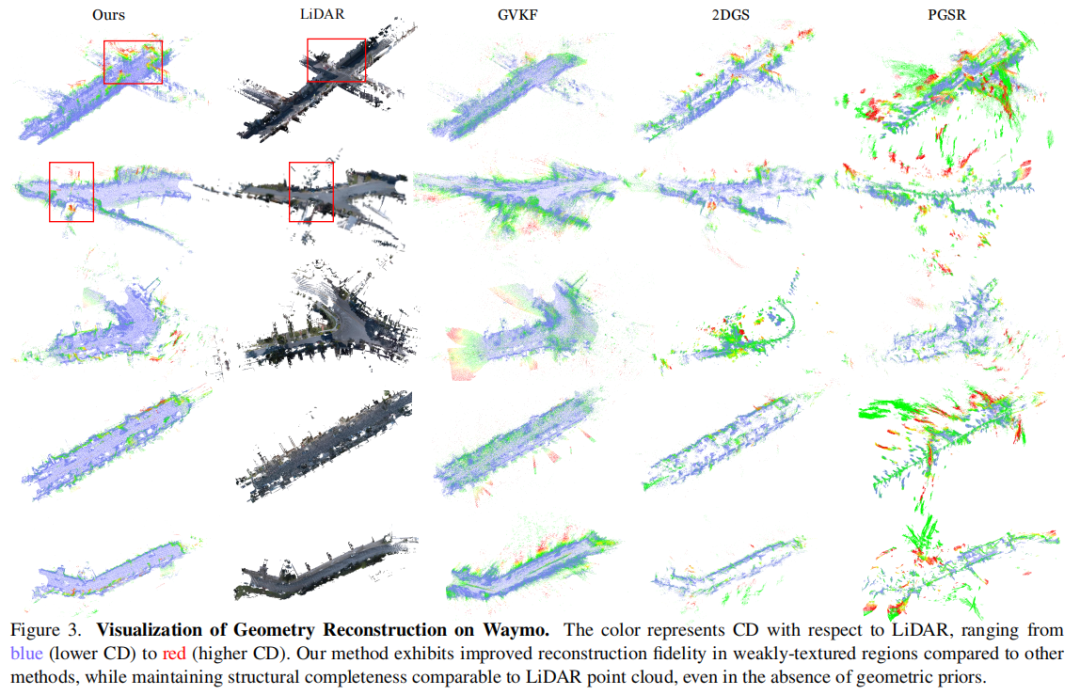
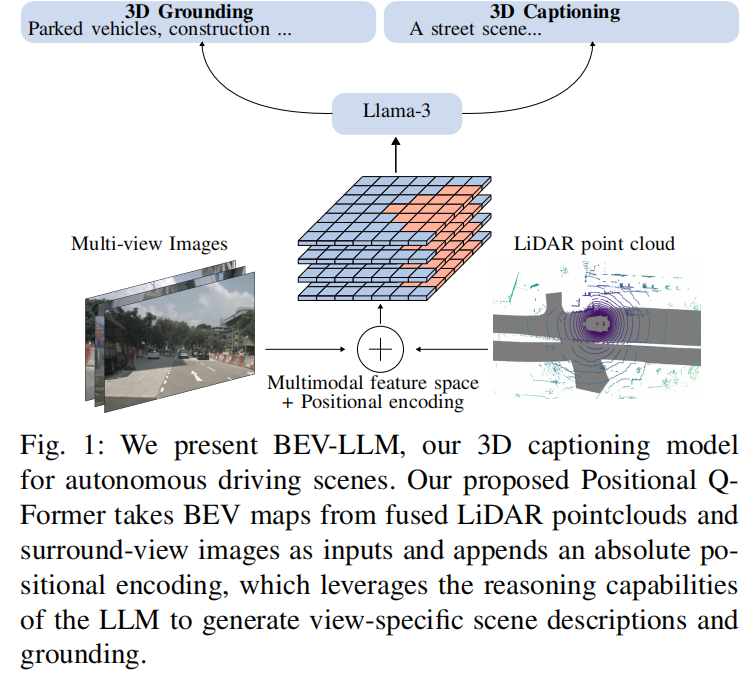
BEV-LLM
基于多模态BEV融合的自动驾驶场景描述生成新框架
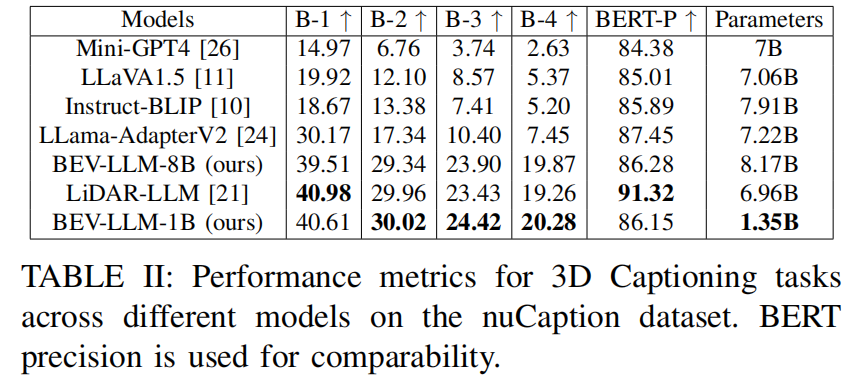
慕尼黑应用技术大学提出轻量级多模态场景描述模型 BEV-LLM,通过融合 LiDAR 点云与多视角图像生成 3D 场景描述,在 nuCaption 数据集上以 BLEU-4 分数 20.28% 超越 SOTA 模型 5%,同时发布环境感知数据集 nuView(205k 样本)和对象定位数据集 GroundView(7.4k 样本)。
论文标题:BEV-LLM: Leveraging Multimodal BEV Maps for Scene Captioning in Autonomous Driving
论文链接:https://arxiv.org/abs/2507.19370
主要贡献:
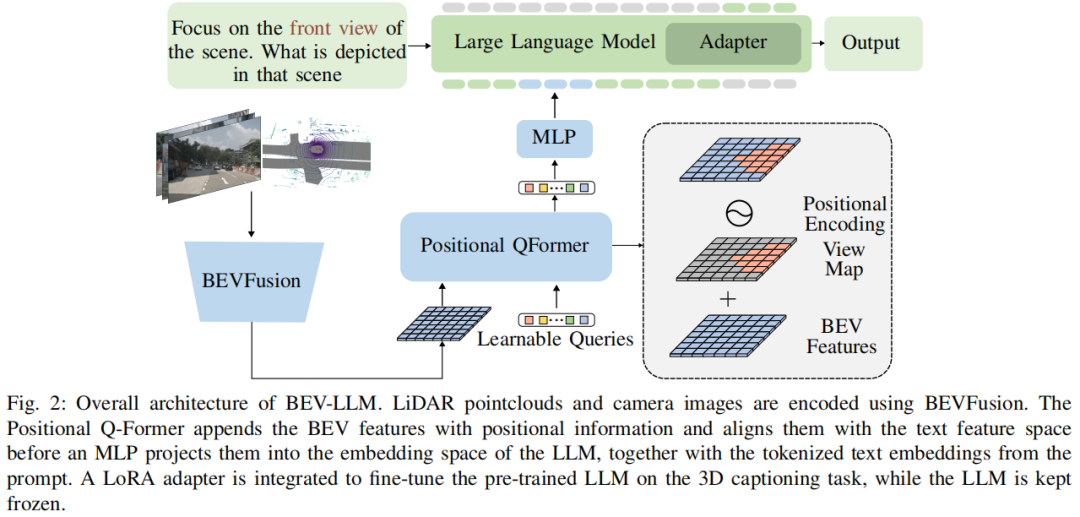
利用 BEVFusion 将 360 度环视图像与 LiDAR 点云融合为统一的 BEV 表示,融合图像的环境上下文与 LiDAR 的精确空间细节,优于 LiDAR-LLM 等单模态方法。
提出正弦 - 余弦位置嵌入,基于输入图像将特征空间划分为六个视图,结合用户输入可灵活聚焦特定视图或全场景,性能优于简单掩码技术。
基于轻量级 1B 参数模型的 BEV-LLM 在 nuCaption 数据集上实现竞争性能,BLEU-2、3、4 分数超过现有技术(BLEU-4 达 20.28%);同时发布 nuView(聚焦环境条件与视角)和 GroundView(聚焦目标接地)两个新数据集及基准结果。
算法框架:
实验结果:
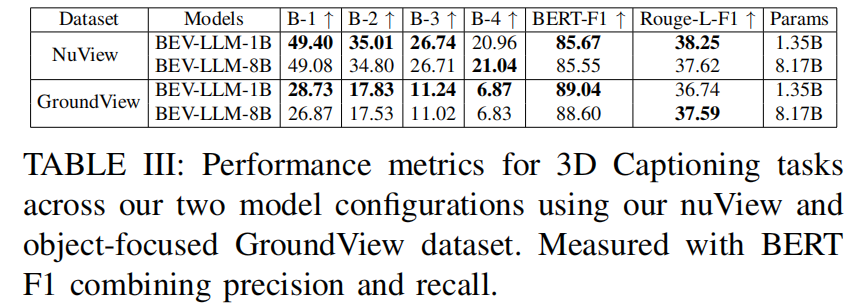
可视化:


CoopTrack
面向高效车路协同时序感知的可学习实例关联端到端框架
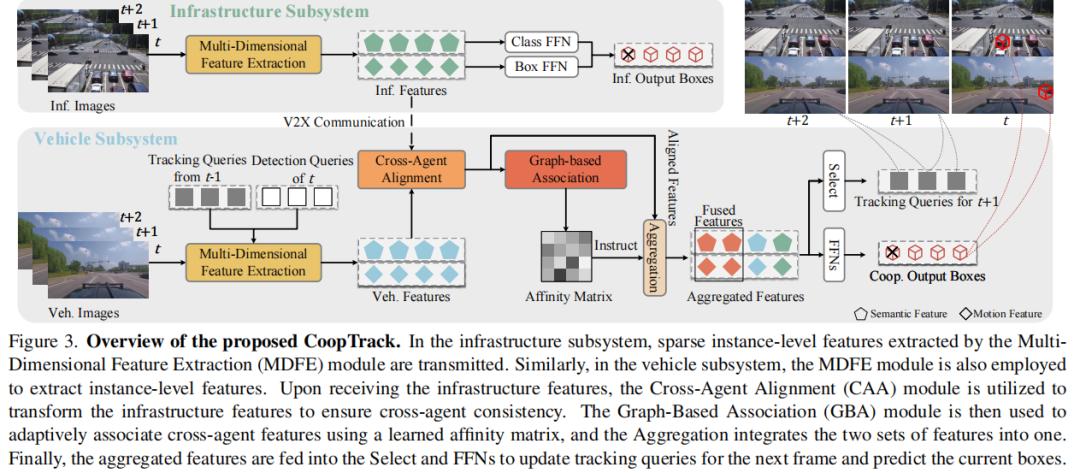
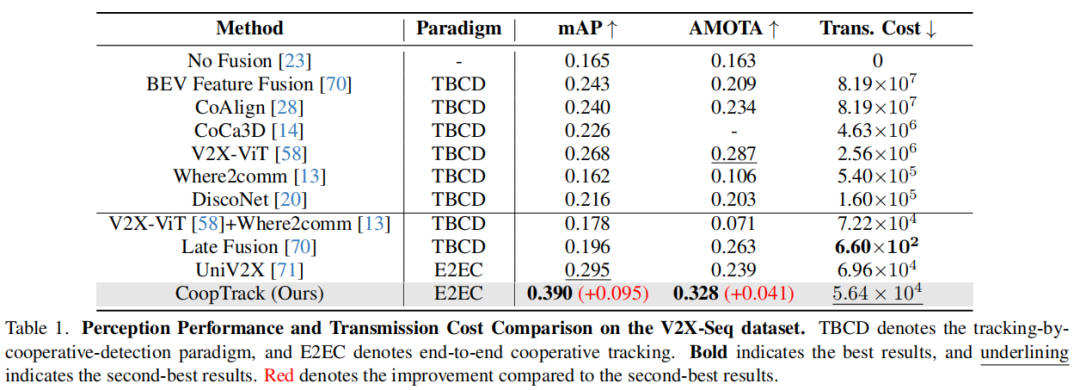
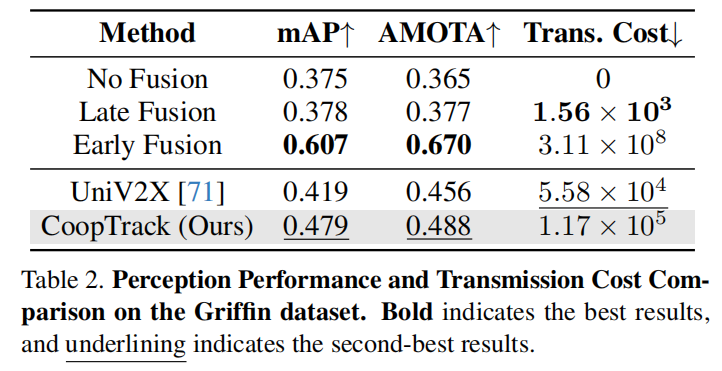
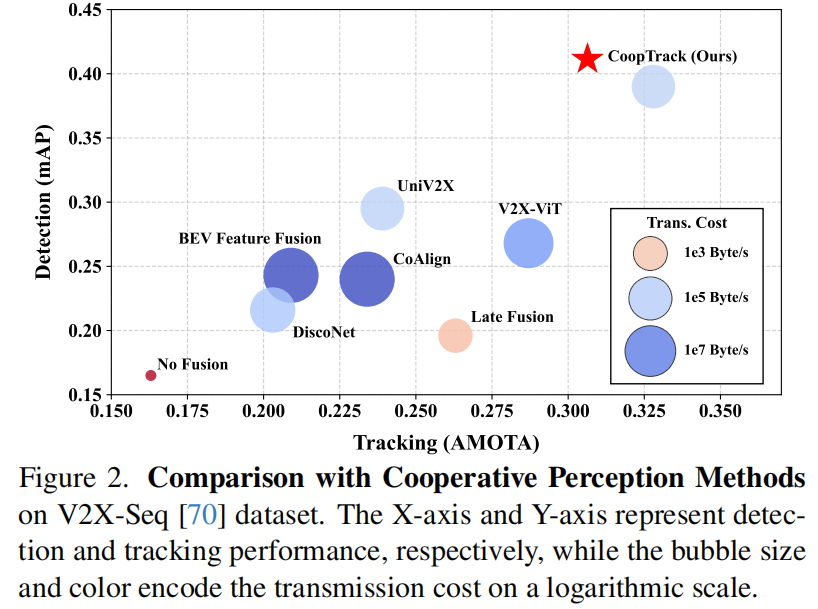
清华大学(AIR研究院)、香港大学、百度联合团队ICCV'25中稿的工作,本文提出端到端协同感知框架CoopTrack,通过可学习实例关联与解码后融合技术,在V2X-Seq数据集实现39.0% mAP与32.8% AMOTA的SOTA性能,传输成本降低至V2X-ViT的2.2%。
论文标题:CoopTrack: Exploring End-to-End Learning for Efficient Cooperative Sequential Perception
论文链接:https://arxiv.org/abs/2507.19239
主要贡献:
提出 CoopTrack,一种实例级端到端协作序列感知框架,其特点是可学习的实例关联和新颖的 “融合后解码” 流程,实现了协作与跟踪的无缝集成。
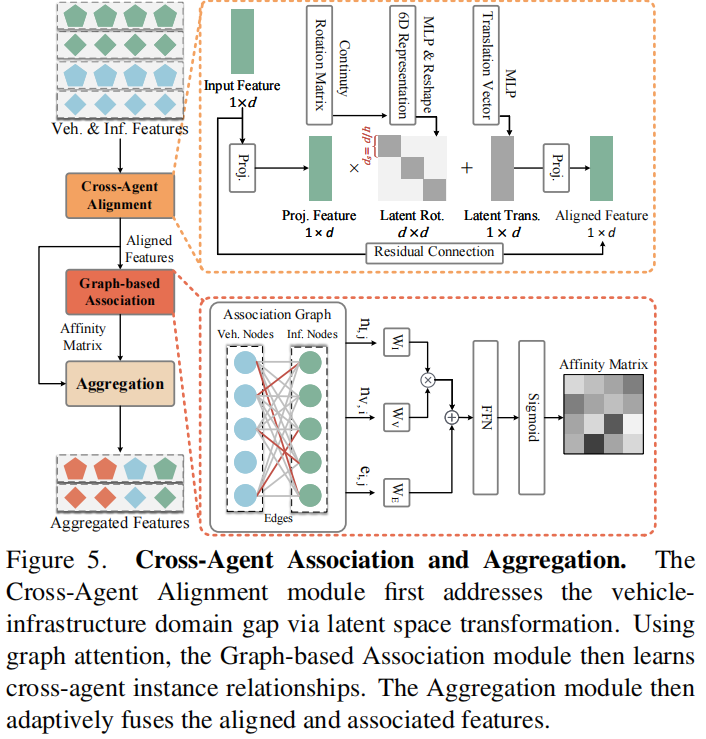
引入可学习的基于图的实例关联模块和实例级特征提取模块,通过捕捉语义和运动特征,增强跨代理关联学习能力。
该方法超越所有现有协作感知方法,在 V2X-Seq 数据集上建立了新的最先进(SOTA)性能。
算法框架:
实验结果:
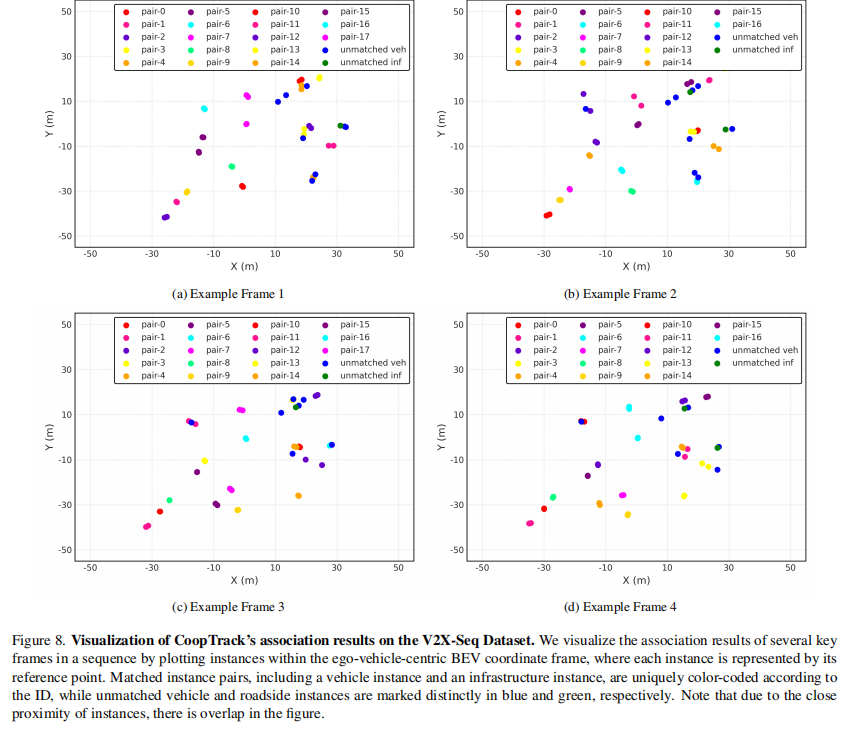
可视化:
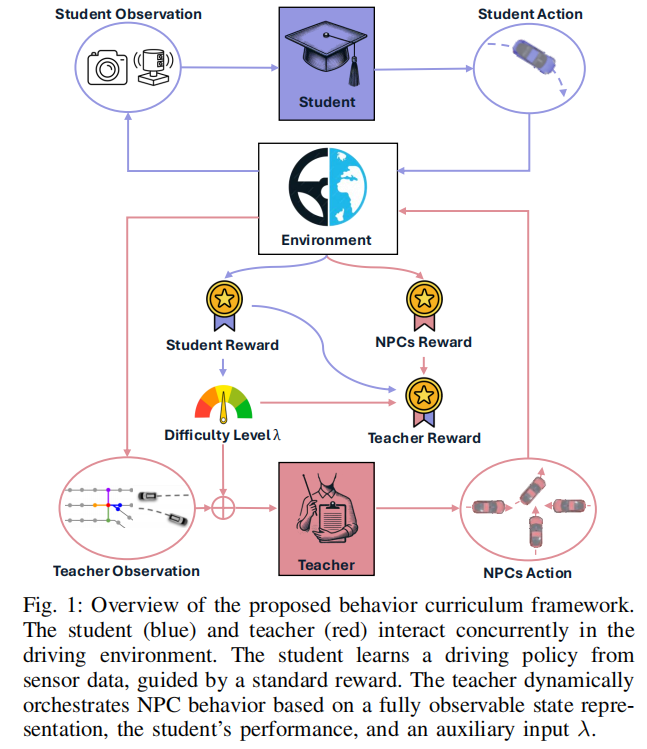
面向自动驾驶的多样自适应行为课程
一种基于多智能体强化学习的学生-教师框架
德国信息技术研究中心与卡尔斯鲁厄理工学院IROS 2025中稿的工作,本文提出自适应行为课程框架,通过多智能体强化学习教师动态生成多样化交通行为,使学生智能体在未信号化交叉口场景中的平均速度提升至1.63 m/s(较基线0.82 m/s提升98%),成功率提高至40%(λ=-1最高难度场景)。
论文标题:Diverse and Adaptive Behavior Curriculum for Autonomous Driving: A Student-Teacher Framework with Multi-Agent RL
论文链接:https://arxiv.org/abs/2507.19146
主要贡献:
提出一种基于学生 - 教师框架的自动驾驶行为课程学习方法,通过融合多智能体强化学习(MARL)与课程学习,提升自动驾驶智能体对多样化交通行为的泛化性和鲁棒性。
设计了基于 MARL 的教师组件,其采用图网络架构和新型奖励函数,能够生成不同难度水平的交通行为。
提出自动课程算法,通过交替训练学生和教师组件,动态调整任务难度以匹配学生性能,实现行为课程的自适应生成。
算法框架:
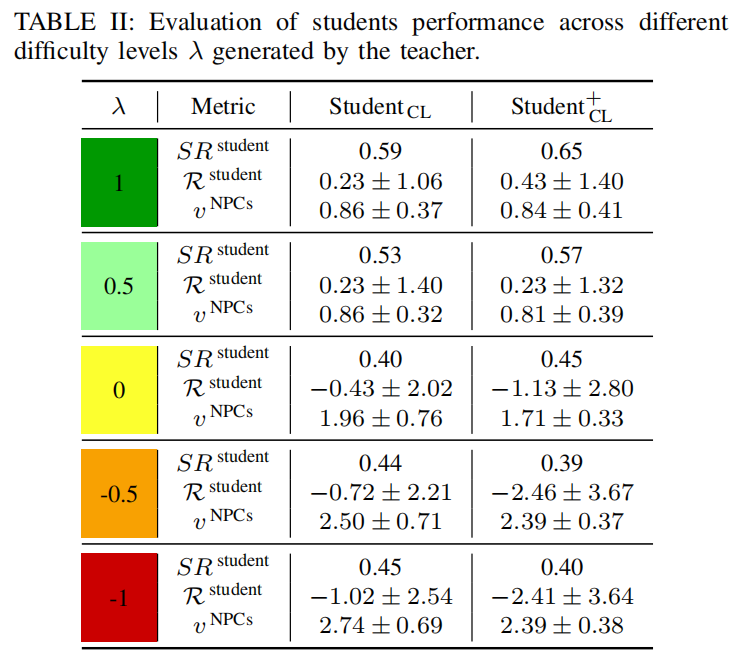
实验结果:
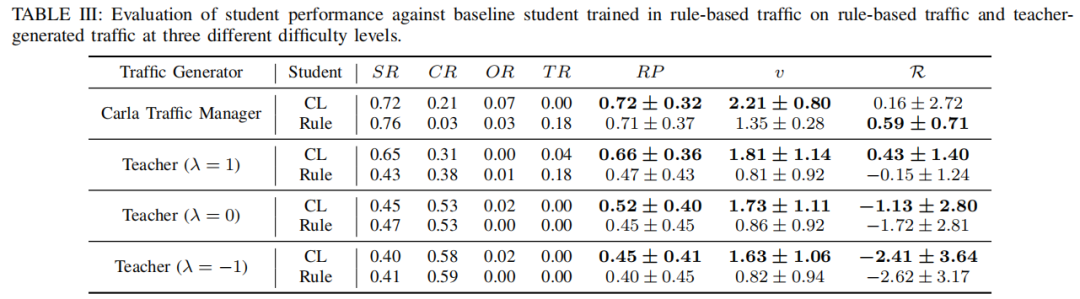
可视化:

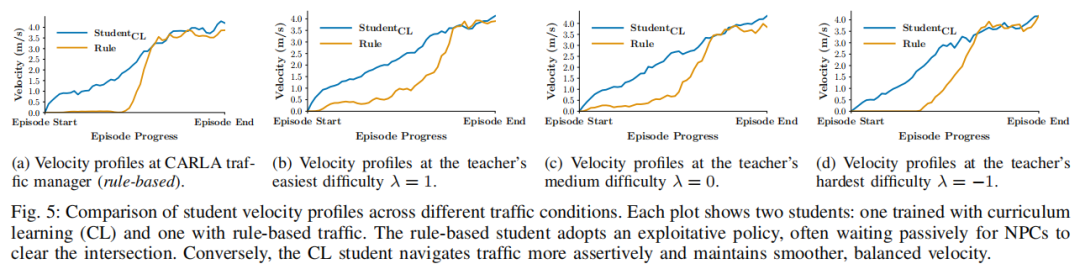
Diffusion-FS
基于扩散模型的自动驾驶多模态FreeSpace预测
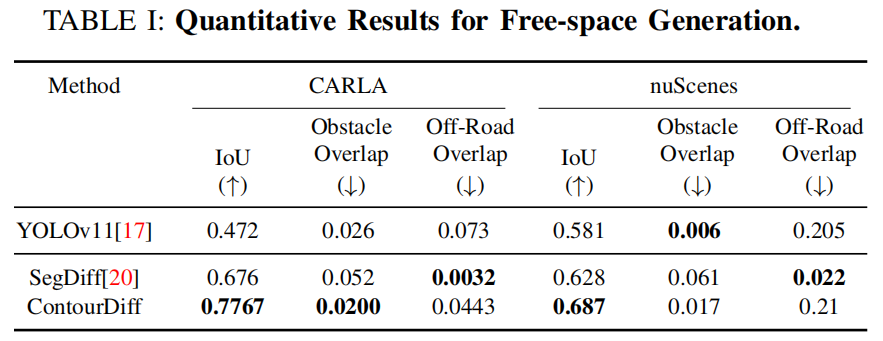
IROS 2025中稿的工作,本文提出ContourDiff模型,突破单目视觉多模态驾驶通道预测技术,在CARLA实现0.7767 IoU与0.02障碍物重叠率,支持6种驾驶行为生成。
论文标题:Diffusion-FS: Multimodal Free-Space Prediction via Diffusion for Autonomous Driving
论文链接:https://arxiv.org/abs/2507.18763
代码:https://diffusion-freespace.github.io/
主要贡献:
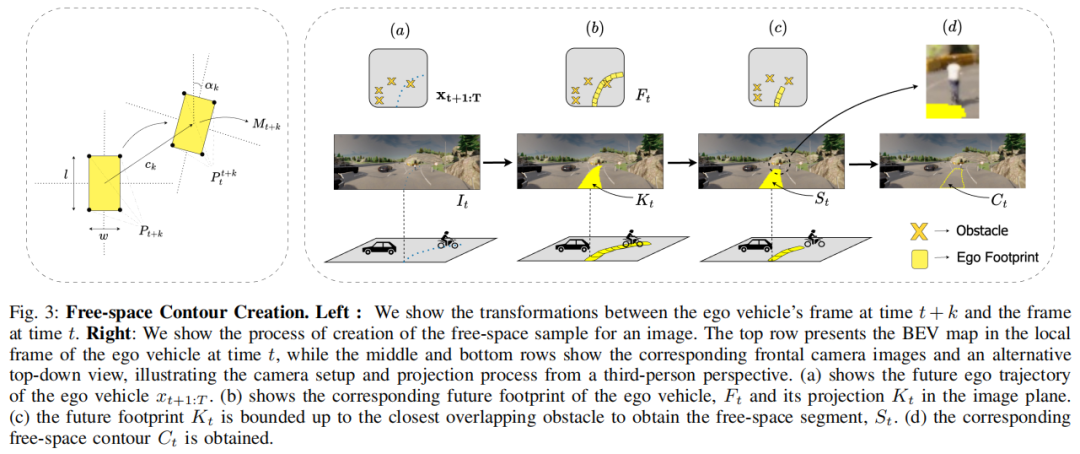
首次将视觉行驶区域预测定义为图像感知任务,不同于以往依赖 BEV 中心表示的方法,直接从单目前视图预测可行驾驶区域,避开障碍物和非道路区域。
提出一种新的自监督freespace样本生成方法,利用未来 ego 轨迹和图像生成样本,摆脱对密集标注数据的依赖。
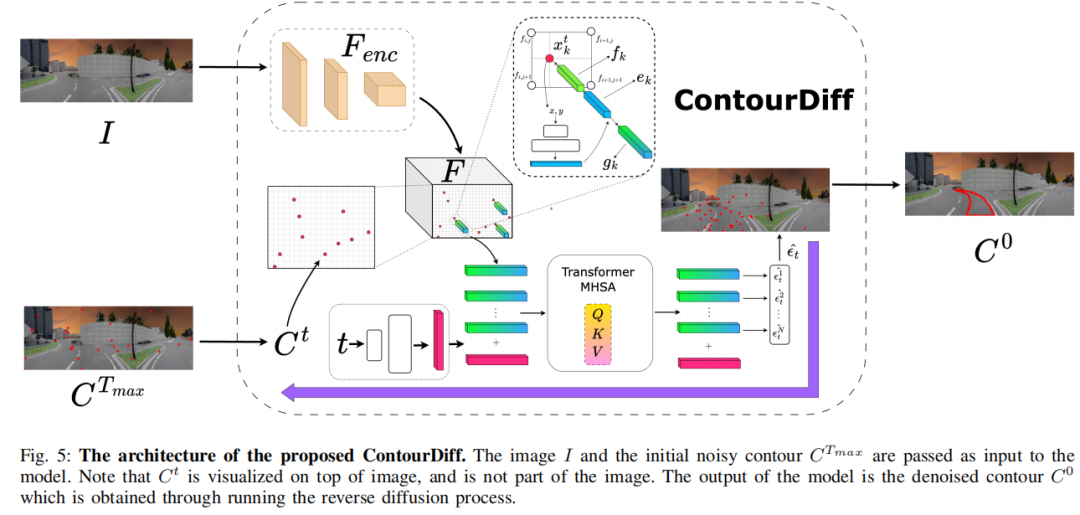
提出 ContourDiff - 一种基于轮廓点去噪的扩散架构,而非标准二进制mask表示,首次实现freespace / 可通行区域的多模态预测,且性能优于生成式和非生成式分割模型。
算法框架:
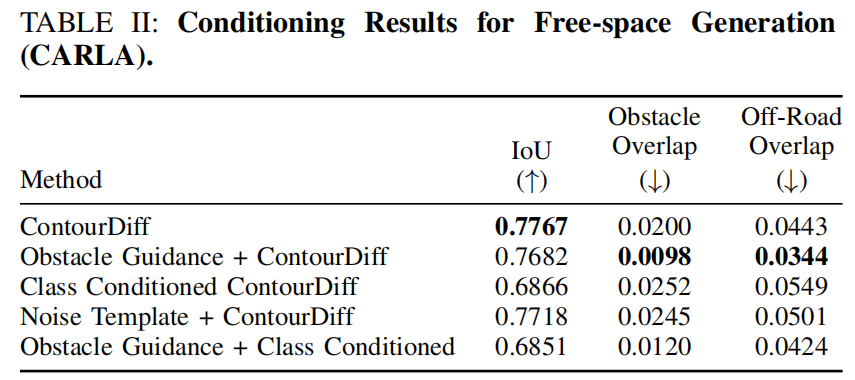
实验结果:
可视化:


最近正值秋招期间,很多应届生的同学都在集中时间刷题、投简历准备面试。我们准备了一个求职社群,内部主要讨论相关产业、公司、产品研发、求职与跳槽相关内容。如果您想结交更多同行业的朋友,第一时间了解产业,欢迎加入我们!
微信扫码添加小助理邀请进群,备注自驾+昵称+求职;





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









