



编辑 | 3D视觉之心
原文链接:https://www.zhihu.com/question/640949959/answer/35913196118
点击下方卡片,关注“3D视觉之心”公众号
第一时间获取3D视觉干货
>>点击进入→3D视觉之心技术交流群

mtfy的回答
不会再审了,
但还是希望好的文章能够尽可能多地走到读者面前吧。
现在的书写套路太固化了,必须有公开的dataset,必须有公开的benchmark,必须有公开的baseline,必须有ablation,还得有帅帅的pipeline和满满的实验。其实,都到在现在这个时候了,这种套路反而是非常限制创新的,而且也没有做难题的土壤了。
如果没这些东西,那就几乎中不了,我真的不知道这到底是卷还是懒,还是说既卷又懒,再加上一堆一堆提前勾兑打招呼的,甚至还有不少直接造假的,真的没意思。
上一届分到我手里的,确实有几篇论文,很有新意,用新方法做了新问题,也能看出来作者做的很不容易,于是我给了高分,但其他审稿人只是喷没有dataset,没有benchmark,没有baseline,没有ablation,最后这几篇论文也没中。
哎,导师的难处,学生的难处,大厂研究者的难处,我也都理解,但我真的不知道这风气啥时候是个头。
总之我还是不审了。
CogitoErgoSum的回答
没卡=做不了火热的LLM/VLM/VLA/Video Generation/Diffusion...=none of sense.
做的low level vision的工作,得分223,被认为是none of sense....
哎,没卡没活路了呀~~~
ArthurMoon的回答
本菜鸟文章被拒习惯了,第一次这么生气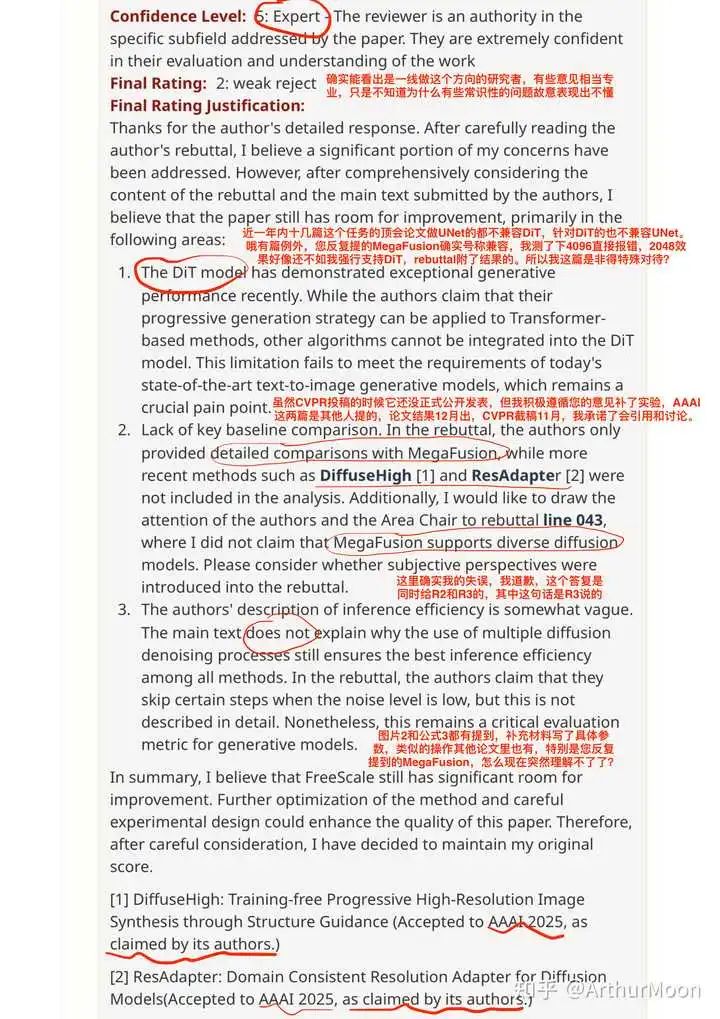
科普+质疑:更高分辨率图像生成的入门
随着扩散模型的迅猛发展,简单输入文字即可生成高质量的图片。当下最流行的生成模型主要有两种结构,旧时代的经典UNet(代表模型SDXL),暂时登基的新王DiT(代表模型FLUX)。然而两者都只能生成有限分辨率的结果,如果强制模型直接生成更高的分辨率(通俗说就是尺寸更大),会因为推理阶段的行为和训练阶段产生偏差导致各种问题。“更高分辨率生成”这个任务应运而生,其中一个主流分支就是不通过微调,直接纠正模型在推理阶段的偏差来获得更好的结果。 然而如上图所示,在直接生成更高分辨率的实验中,UNet模型遇到的问题是重复的物体随着分辨率的提高不断变多,而DiT模型遇到的问题是画质随着分辨率的提高不断退化。虽然两者的任务相同,但由于框架的区别,导致本身面临的问题也不同。之前绝大部分这个分支的论文,都是单独解决其中一者。举个例子,都是肠胃炎,细菌性肠胃炎和病毒性肠胃炎的诱因完全不同,所需要的治疗方式也大为不同。专业的审稿人既然拉满置信度,想必这么入门的知识不会不懂吧。
然而如上图所示,在直接生成更高分辨率的实验中,UNet模型遇到的问题是重复的物体随着分辨率的提高不断变多,而DiT模型遇到的问题是画质随着分辨率的提高不断退化。虽然两者的任务相同,但由于框架的区别,导致本身面临的问题也不同。之前绝大部分这个分支的论文,都是单独解决其中一者。举个例子,都是肠胃炎,细菌性肠胃炎和病毒性肠胃炎的诱因完全不同,所需要的治疗方式也大为不同。专业的审稿人既然拉满置信度,想必这么入门的知识不会不懂吧。
干货部分结束,下面是私货部分:然而某篇论文声称可以同时解决两者,经过实测,这个方法的其中三分之一,确实能起到一定作用,但远远达不到解决的程度,另外三分之二更是完全不兼容。最后这篇文章呢也没有被顶会录用,只能退而求其次找其他会议。但是偏偏凑巧,刚录用完甚至还没正式发表,俩审稿人就马上将之奉为榜样,全然无视之前那一年内的十几篇顶会都是只支持UNet,说不支持DiT就不配发。我一开始limitation主动提这个局限性,我觉得大家都没解决列出来完全没问题,然后这俩审稿人就用他们的榜样来贬低我的工作。我一看他们说的榜样,就这效果也好意思说兼容俩框架?欣然摆出实验反驳说按这个这么低的标准我也能兼容效果还更好些。结果他们双标到说哦你这个只有一部分生效了,其他部分不生效,所以还是要拒你。天呢你忘了你自己提的榜样也是只有一部分生效?我都明确说了这一点还故意视而不见是吧。

光荣与梦想的回答
结论 : 审稿质量依旧底下
证据 : 有两个审稿人在major weakness 里说: 你在文章里提到 [1] 使用了GAN. 但是[1]根本没用GAN. 拒稿.
我的反驳 : [1]明明说了 "we used a ForkGAN mode to ..."
评论: 我不知道在PDF 文件里搜索一下GAN 这个词到底有多么难. 眼睛不要可以捐献
谁知我这种男孩子的回答
第一次投论文,就来挑战cvpr2025了,反正是初生牛犊不怕虎,哈哈哈。分数232(434),第一个2分,问我为啥不和sota比,然后又说我这个和sota比没有分数优势,和最新的idea比没有足够的创新,然后又说为什么我不去跑一跑别人的论文基线,而是直接采用他们论文中的数据,然后又问我在第二章相关工作中,为什么谈到了一些方法(2016 2017年的),但是最后没有拿出来比,但是我在最后的模型比较里面比的都是最新的论文2018-2024年的。然后就是经典的质疑:“你说你要在最后版本放出代码,那你真有这么好的效果吗,你的模型看起来一点也不复杂,我感觉这种简单模型不可能有好效果,所以我对你的代码保持高度质疑”
第二个评审人给的3分,主要是提了我的图片画的不够好,然后表格中最好把标准差这些也画出来,然后说我的图5可以删掉。
第三个评审人给的2分,主要是说我的创新不够,然后又说我的论文有些地方拼写错误,格式有瑕疵(有些地方忘了打空格),然后又说我最后的结论写的不够详细。
我已经准备润了,去试一试期刊把。哈哈哈。
分割线
——————————————————————
看见大家都比较好奇,我就再补充一点,评审并没有全提那种抽象的意见,也提了一些画图的意见和全文组织布局的意见,然后评委格外关注我的公式的推导过程,我有一步跳步了,就被三个评委都问了。
然后就是评委也说了,你这个尽量要和最新的相关工作多做比较,写明他们方法的劣势,你从中得出的启发,从而如何设计出你的方法。
但是第一个评委有点抽象,他问我:“你这个和别人都是做特征对齐的工作,既然别人的方法已经很优秀了,为什么你还要做你这个方法,请列出你的必要性。这个方向已经有人在做了,你这工作应该算是增量性的,而不是创新性的”。我都无大语了,照你这么说,别人(sota)谈了一个好方法,我们这后来的方法只要效果比不上他,那就都没有必要了哇?而且他在这个方向提了一个方法,我再提出我的方法,那我这个就不是创新了吗?不过这就是我在口嗨,我根本没去回复他。哈哈哈,只敢意淫一下咯。
【3D视觉之心】技术交流群
3D视觉之心是面向3D视觉感知方向相关的交流社区,由业内顶尖的3D视觉团队创办!聚焦三维重建、Nerf、点云处理、视觉SLAM、激光SLAM、多传感器标定、多传感器融合、深度估计、摄影几何、求职交流等方向。扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

扫码添加小助理进群
【3D视觉之心】知识星球
3D视觉之心知识星球主打3D感知全技术栈学习,星球内部形成了视觉/激光/多传感器融合SLAM、传感器标定、点云处理与重建、视觉三维重建、NeRF与Gaussian Splatting、结构光、工业视觉、高精地图等近15个全栈学习路线,每天分享干货、代码与论文,星球内嘉宾日常答疑解惑,交流工作与职场问题。


















 2026
2026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









