



点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享自动驾驶思维链的工作汇总!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『大模型思维链』技术交流群
前言
CoT prompting的核心思想是通过让模型生成中间推理步骤,从而促进其推理能力,特别是在解决复杂问题如数学题或逻辑推理时。传统 prompting 方法可能直接问答案,而CoT则是让模型一步步思考,比如先分解问题,再逐步解决,最后得出答案。COT从最初在语言模型中提出基于文本的链式思维推理(few-shot,zero-shot),逐步扩展至多模态领域,并进一步结合垂直场景需求(如自动驾驶中的结构化决策、运动预测),通过引入分阶段推理、知识蒸馏、轻量化部署及结构化标注数据,推动CoT从通用推理工具向可解释、高效率、场景适配的认知智能范式演进,最终实现复杂任务中“逻辑透明性”与“性能优越性”的统一,是大模型迈向类人推理的关键技术路径。
思维链(Chain-of-thought)论文汇总
Chain-of-thought prompting elicits reasoning in large language models
论文链接:https://arxiv.org/abs/2201.11903
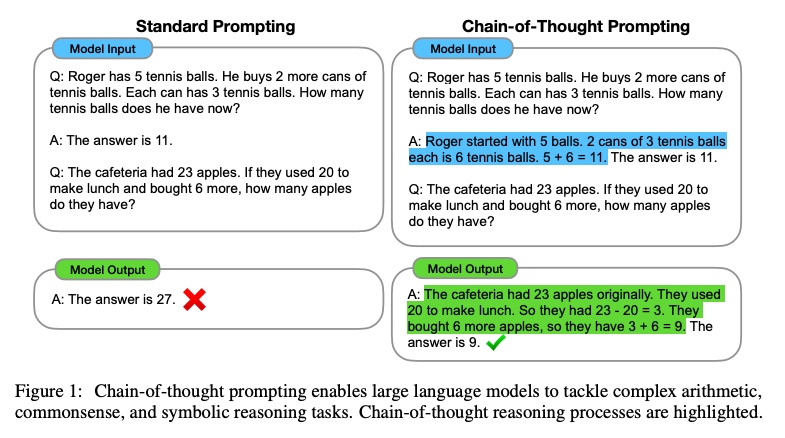
核心思想:
提出思维链(chain of thought)概念,通过少量样本(few shot)提示引导模型生成中间推理步骤,模拟人类“逐步思考”的过程,最终得出答案。
在输入中插入3-5个带有详细推理过程的示例(如:"问题→分步推导→答案"),即可激活模型的隐式推理能力,无需对模型参数进行任何微调。
Large Language Models are Zero-Shot Reasoners
论文链接:https://arxiv.org/pdf/2205.11916

核心思想:
提出“零样本思维链”(Zero-Shot CoT)方法,通过向模型提供通用推理指令(如“Let’s think step by step”),直接引导其生成中间推理步骤,而无需提供任何任务相关的示例(Few-shot CoT需要人工设计示例。
首次证明大型语言模型在完全零样本条件下(无示例、无微调)能够自主分解问题并生成逻辑连贯的推理链条,最终输出正确答案。
Self-Consistency Improves Chain of Thought Reasoning in Language Models
论文链接:https://arxiv.org/pdf/2203.11171
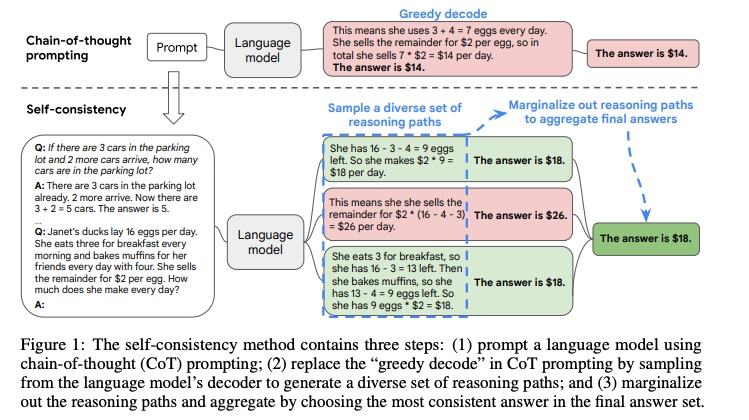
核心思想:
突破传统思维链(CoT)仅生成单一推理路径的限制,提出同时生成多个不同推理路径。引入"自我一致性"概念,认为正确的答案往往隐含在多数推理路径的共识中。通过统计多个推理路径的最终答案,采用多数投票机制选择出现频次最高的答案作为最终结果。
使用人工写好的COT prompting来提示语言模型,从LLM decoder中采样(温度采样/top-k/核采样)生成一系列候选推理路径,最后根据投票选择最终推理结果。
Automatic Chain of Thought Prompting in Large Language Models
论文链接:https://arxiv.org/pdf/2210.03493
项目链接:https://github.com/amazon-science/auto-cot
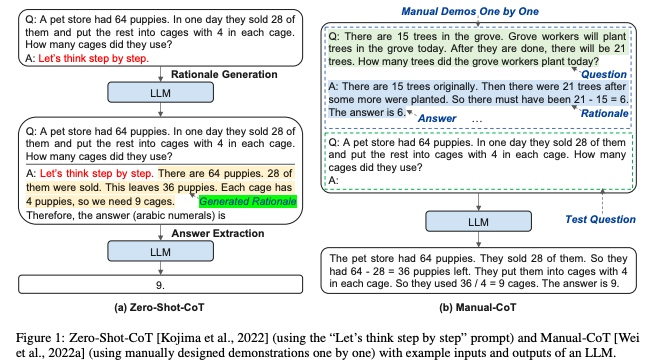
核心思想:
Zero-Shot-CoT 通过在问题前添加引导词(如“Let’s think step by step”)触发模型的逐步推理。缺点是提示过于笼统,缺乏针对性,可能导致推理不精确。Manual-CoT需要人工设计示例问题及其分步解答作为提示模板。缺点是依赖人工设计,成本高且示例覆盖范围有限,难以泛化到多样化问题。针对Zero-Shot-CoT 和 Manual-CoT 的不足,提出了Retrieval-Q-CoT方法;
通过自动化检索相关示例,动态生成适配当前问题的CoT prompt。
聚类备选问题库:对大量候选问题按语义或主题聚类,形成问题组。
生成演示答案:调用模型(如ChatGPT)为每个聚类中的问题生成分步解答,构建“问题-答案对”库。
相似度检索:当遇到新问题时,计算其与问题库中各聚类的相似度,检索最匹配的示例作为提示模板。
无需人工设计示例,通过数据驱动选择最相关提示,提升推理的精准性和泛化能力。
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
论文链接:https://arxiv.org/pdf/2205.10625
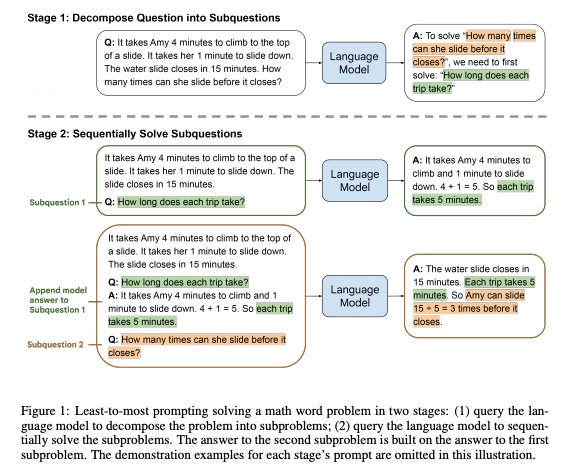
核心思想:
提出"由简至繁"(Least-to-Most)的提示策略,将复杂问题系统性分解为有序子问题序列。通过引导模型先解决基础性、前提性的子问题,逐步构建解决最终复杂问题的能力,类似于数学证明中"引理→定理"的递进结构。
常规的COT单次生成连续推理步骤(可能因步骤过长导致逻辑断层),Least-to-Most策略显式构建问题依赖图,通过中间答案的渐进式验证,确保每个子结论的正确性传导。
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
论文链接:https://arxiv.org/pdf/2305.10601
项目链接:https://github.com/princeton-nlp/tree-of-thought-llm
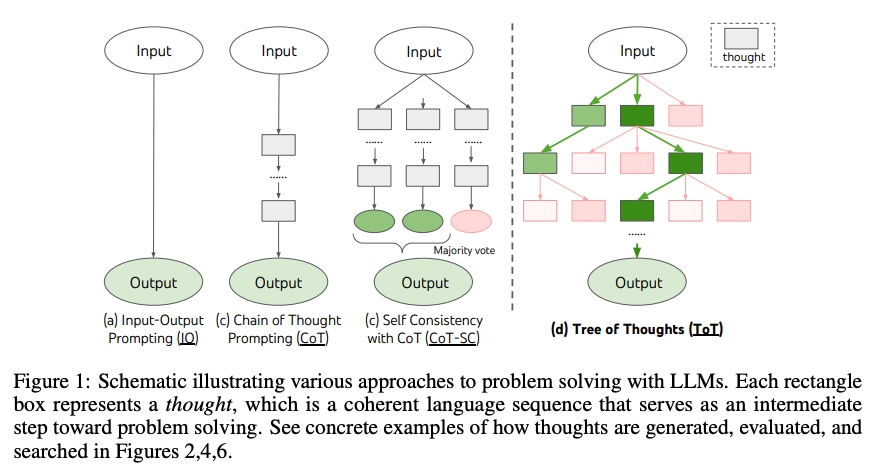
核心思想:
提出"思维树"(Tree of Thoughts, ToT)框架,颠覆传统语言模型从左到右的token级生成模式**。通过构建树状推理结构,允许模型在多个候选推理路径(称为"思维节点")间进行主动探索、回溯与全局决策,模拟人类解决复杂问题时的系统性思考过程。
将经典搜索算法(如广度优先搜索/BFS、深度优先搜索/DFS)与语言模型结合。
与现有方法的本质差异:Chain-of-Thought (CoT)单一路径的线性推理,无法纠正错误或优化路径;Self-Consistency:生成多条独立推理链后投票,缺乏路径间的交互验证;ToT构建显式搜索空间,通过前瞻(lookahead)与回溯(backtracking)实现系统性探索,在规划类任务(如解谜/创作)中展现显著优势。
Multimodal Chain-of-Thought Reasoning in Language Models
论文链接:https://arxiv.org/pdf/2302.00923
项目链接:https://github.com/amazon-science/mm-cot
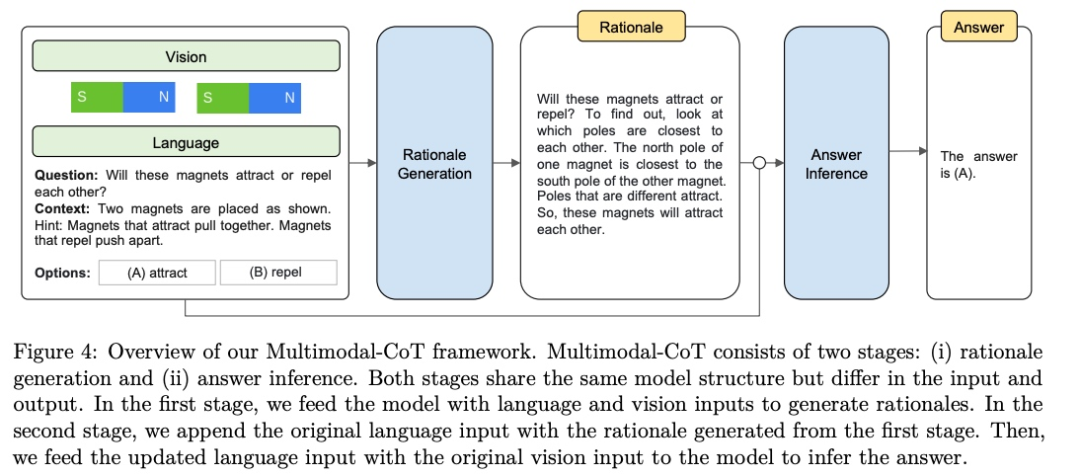
核心思想:
现有CoT研究聚焦单一语言模态,无法利用视觉信息(如图像、图表)进行跨模态逻辑推导,导致复杂问题(如科学问答、场景理解)的推理受限或产生“幻觉”(错误推理)。该研究提出多模态思维链(Multimodal Chain-of-Thought, CoT)推理框架,将视觉与语言信息深度融合,解决传统单模态CoT在复杂推理任务中的局限性。
提出两阶段多模态CoT框架:
第一阶段(Rationale Generation):融合文本与图像特征,生成多模态推理链(例如结合图像中的物体位置与文本描述推断物理原理)。
第二阶段(Answer Inference):将第一阶段生成的推理链与输入信息拼接输到LLM中进行答案预测,避免多模态噪声干扰。
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
论文链接:https://arxiv.org/pdf/2411.10440
项目链接:https://github.com/PKU-YuanGroup/LLaVA-CoT

核心思想:
在通用VLM(如LLaVA)基础上,提出四阶段自主推理流程(总结→视觉解释→逻辑推理→结论生成),替代传统链式思维(CoT)的线性提示方法。例如,面对“图中为何交通拥堵”的提问,模型依次做如下四阶段推理:
总结:提取图像关键元素(如车辆密度、信号灯状态);
视觉解释:识别具体视觉线索(红灯时长、车道占用);
逻辑推理:结合常识(长红灯导致车辆堆积);
结论生成:综合得出“信号灯故障引发拥堵”。
提出阶段级束搜索(Stage-level Beam Search)策略,在推理时动态优化各阶段输出的候选路径,提升多步推理的准确性与效率(如优先保留视觉解释正确的路径)
提出LLaVA-CoT-100k数据集,首个面向多阶段视觉推理的结构化数据集,涵盖科学问答、场景理解等任务,标注包括四阶段中间推理步骤,为模型提供明确的逻辑链学习目标。
DriveCoT: Integrating Chain-of-Thought Reasoning with End-to-End Driving
论文链接:https://arxiv.org/pdf/2403.16996
项目链接:https://drivecot.github.io/

核心思想:
通过引入思维链(Chain-of-Thought, CoT)推理机制,提升端到端自动驾驶系统的可解释性和可控性,在开环和闭环测试中,性能优于传统端到端方法,验证了方法的有效性。
数据集:基于CARLA模拟器创建DriveCoT数据集,涵盖传感器数据、控制决策及细粒度的思维链标注(如“是否需要变道”“目标车道选择”等推理步骤)。
思维链标注:利用规则驱动的策略,在复杂场景(高速行驶、变道)中生成思维链标注,为模型提供逻辑推理训练数据;
CoT-Drive:Efficient Motion Forecasting for Autonomous Driving with LLMs and Chain-of-Thought Prompting
论文链接:https://arxiv.org/abs/2503.07234v1
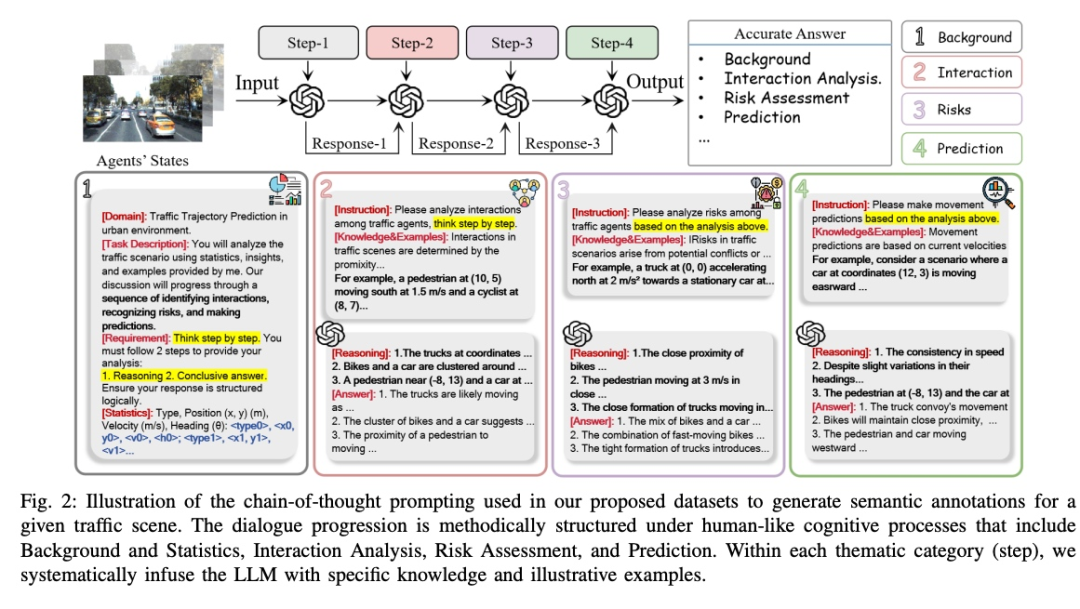
核心思想:
首次将LLM的复杂推理能力引入自动驾驶运动预测,利用CoT prompting技术生成细粒度语义标注,增强对动态场景的理解。
构建首个面向自动驾驶的结构化CoT标注数据集(超1000万token),涵盖背景统计→交互分析→风险评估→预测的完整逻辑链,支撑轻量模型的微调与泛化。
设计双编码器结构,语言指导编码器:处理CoT生成的语义标注;交互感知编码器:提取时空特征(动态交互、运动轨迹)。
利用知识蒸馏策略,将GPT-4 Turbo(教师模型)的场景理解能力迁移到轻量级语言模型(学生模型),实现实时边缘计算(如Qwen-1.5-0.6B仅需0.17秒/场景)。在保持LLM级推理性能的同时,模型参数量降低达90%。
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









