



点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
年前有星友接到了一个新活,团队要做去高精地图的城区NOA,算力要求还不能高,真的是既要又要了,没办法,这么卷的市场下,做出高性价比的方案才能活下去。他觉得无从下手,很多问题搜不到答案,对这块还是一脸懵的状态,正好我们邀请了一个无图感知方向的专家来做了一场无图感知的直播(直播视频获取地址),他如获至宝,心中的疑惑解了很多,听说最近已经调研选型完成,进入开发阶段了,高手点播一下,能少走很多弯路。下面是一部分核心问题:
1、有使用卫星地图进行定位的无图研究么?
就是用SD map做定位的。最近是有一些这样的工作的,就有一篇叫MapLocNet:Coarse-to-Fine Visual Neural Re-Localization in Navigation Maps,可以去看一下。
2、P-MapNet是BEV图和LIDAR数据先融合在一起吗
对,是的,我们是先对纯视觉,就是环视相机提到一个BEV特征,然后拿这个BEV特征再和雷达的BEV特征contact的在一块的,作为我们这里讲的这个BEV特征。
3、有试过做map change detection 么sd map信息是错的时侯
P-MapNet有一个limitations里面是讲到这个东西,他分好多种情况。比如,真实场景下是有一条路,然SD map没有这条路。以及另外一种情况是真实情况下没有这条路,然后SD map又告诉你有这条路。然后还有如果再加上机器的标注,那情况就又会比较多。就是机器标注告诉你有,但实际上没有;然后SD map又告诉你有,就这种排列组合情况非常多。然后一种可以解可以尝试的做法,其实就是从训练册训练时候加一些随机的drop out 这个,当然P-MapNet没有去还没有做到这一步。
4、instance建模方式下mae还会提升断断续续线的问题吗?
如果是instant建模下,就是矢量化的建模下,MAE这种方式其实不太好了。对,就是因为AME它处理的还是图像。我推荐你去看一下Polly deviation这个工作。对,就是我在最开始讲相关工作的时候,有提到那个politician那篇。他其实是对矢量化,用division model去做对。你如果你是instance的话,你还是要先把它做栅格化,做栅格化完之后,然后才能用MAE。对,然后你最后用了ME之后,你得到的还是一张图片,还是一个分割的结果,还要做后处理,这个就得不偿失了。
5、栅格化看起来效果要比矢量化稳定,但是栅格化的东西下游怎么用呢?
对于OCC任务来说,它里面很多的一些做法可以参考map之前的发展。就比如说map其实但map里面它又会有有很多之前OD那块的一些工作的一些借鉴。、比如说融合持续,当然融合时序。有好几个层面,一种就是BEV层面,然后另外一种就是像做这种tracker,像maptracker。对然后融合一些历史的一些历史的这种,就是叫其实叫通勤模式。对,然后这块其实也是可以迁移到OCC这块。
6、未来的一个研究点
比较火的像VLM,然后对VLM能不能对我们的map对做一些增强,就比如说最近看到有一篇就是用VLM去做一些拓扑推理。其实VLM它是非常适合做一些return做一些推理。然后能不能基于这个去对现有的一些任务做一些增强然后。
热门行业直播干货汇总
自动驾驶之心星球部分行业直播一览(直播视频获取地址):

自动驾驶人的私域知识库,三天内免费体验,72小时内不满意随时退款,星球内每天都在更新的自动驾驶、大模型相关私域知识。
2025年,自驾人一定会遇到很多挑战,别焦虑,来我们星球敞开心扉聊聊技术,谈谈人生,一定会收获满满,现在加入,还有大额优惠,扫码领取:自动驾驶之心知识星球。
新用户66元现金优惠!微信扫码领取

我和4000+小伙伴们等你来:自动驾驶之心知识星球,专为自动驾驶人开设的技术和心灵港湾,有难题这里有解决方案!我们熬夜总结了自动驾驶、大模型等方向里程碑工作、前沿报告和学习路线,超全,读完一定会茅塞顿开。
认识下我的星球
保持竞争力的前提是个人技术和视野要常用常新,要让自己能搞定一个或多个模块,要常和行业内人士交流(比如经常参加行业大佬的直播)。一起为智驾站台,一起相信智驾的未来!最后真心推荐大家加入『自动驾驶之心知识星球』!
🔥【我们是谁】
『自动驾驶之心知识星球』目前最大自动驾驶学习交流私域社区,会员近4000人,行业大咖云集,60+合伙人和嘉宾,有问必答。
🔥【星球内有什么】
🎓1、35+自动驾驶方向学习路线;
🎓2、自动驾驶各方向面试100问汇总;
🎓3、每月精选问答,已积累近1000+条;
🎓4、100+大咖直播分享回放视频;
🎓5、100+自动驾驶行业报告;
🎓6、100+精选行业书籍;
🎓7、更多惊喜在星球内。
🔥【加入星球能获得什么】
🎓1、免费获得几十位专业嘉宾的问题解答(有问必答)🎓2、永久免费浏览、下载星球内容(目前6700+,每天更新,会员过期后,过期前的内容可继续免费浏览下载)
🎓3、所有自动驾驶之心的付费课程8折优惠(价值3000元)
🎓4、直播视频免费无限期回放(现有100+场行业直播,未来一年持续邀请大咖分享)
🎓5、免费赠送优质课程视频(多门)
🎓6、星球积分榜前10名,获得丰富现金奖励
🎓7、免费咨询求职招聘相关问题
🎓8、加入专属VIP群,获得最新资讯
『自动驾驶之心知识星球』已经近4000人了!说句心里话,作为长期排名前十,内容和活跃度超过99%的平台,我们倾注了全部心血,社区就像个孩子一样,在大家细心的照料下,终于长大成人了。我们给大家准备了一个现金优惠大礼包,绝对超值。
新用户66元现金优惠!微信扫码领取

自动驾驶之心知识星球,创办于2022年7月份,致力于打造为自动驾驶行业中的 ”黄埔军校“,目前已近4000人,聚集了近60+自动驾驶行业专家为大家答疑解惑。这是国内首个以自动驾驶技术栈为主线的交流学习社区,汇总了自动驾驶感知(目标检测、语义分割、车道线检测、BEV检测、Occupancy、在线地图、目标跟踪、多模态、多传感器融合等)、自动驾驶定位建图(高精地图、SLAM)、自动驾驶规划控制与预测、多传感器标定、端到端自动驾驶、自动驾驶仿真、自动驾驶开发、领域技术方案、AI模型部署落地等几乎所有子方向的学习路线!除此之外,还和数十家自动驾驶公司建立了1v1内推渠道,简历直达!这里可以自由提问交流,许多算法工程师和硕博日常活跃,解决问题!初衷是希望能够汇集行业大佬的智慧,在学习和就业上帮到大家!星球的每周活跃度都在国内前30,非常注重大家积极性的调度和讨论,欢迎加入一起成长!
星球内已经打磨出近35+的学习路线,涉及端到端自动驾驶、BEV感知、动态/静态障碍物检测、多传感器融合、多传感器标定、目标跟踪、模型部署与cuda加速、仿真等方向,沉淀了大量工程上的解决方案、学术上的优化思路!星球主要内容一览:

这些热门技术方向,星球里面全都有!
现在自动驾驶技术迭代期越来越短,从原来的单目3D到BEV,再到OCC,再到大模型和端到端,高阶智驾现阶段的技术点已经比较清晰。
O、热门方向大佬视频分享




1.前沿工作
【Senna: 一种将LVLM(Senna-VLM)与端到端模型(Senna-E2E)相结合的自动驾驶系统】对两个数据集的广泛实验表明,Senna在规划性能上达到了最先进的水平;
【Ramble:具有强化学习的高交互交通场景中的端到端驾驶】Ramble在CARLA Leaderboard 2.0上实现了路线完成率和驾驶评分的最新性能;
【CARLA中的端到端自动驾驶全面综述】讨论了基于CARLA的最先进实现如何通过各种模型输入、输出、架构和训练范式解决端到端自动驾驶中遇到的各种问题;
【端到端预测和规划最新SOTA!一种用于端到端自动驾驶的新交互机制:PPAD】。
2.报告和行业大佬直播分享



大模型
1.前沿工作
【全面回顾当前关于L(V)LM在自动驾驶应用方面的研究】重点关注四个关键领域:模块化整合、端到端整合、数据生成和评估平台。
【自动驾驶中的大语言模型(LLM4AD):概念、基准、仿真和实车实验】LLMs在提升自动驾驶技术各个方面的显著潜力,包括感知、场景理解、语言交互和决策;
【基于 LLM 驱动的鲁棒 RL 自动驾驶数据合成与策略调整】RAPID能够有效将LLM的知识整合到缩减版的RL策略中,以高效、适应性强且鲁棒的方式运行;
【大型语言模型会成为自动驾驶的灵丹妙药吗?】本文对LLM在自动驾驶系统中的潜在应用进行了详尽的分析。
2.报告和行业大佬直播分享

BEV感知
1.前沿工作
【nuScenes和nuScenes最新SOTA!】Focus on BEV: 基于自标定周期视图变换的单目BEV图像分割;
【MambaBEV:一种基于mamba2的BEV目标检测】还采用了端到端的自动驾驶范式来测试该模型的性能。模型在nuScenes数据集上表现出了相当好的结果:基础版本达到了51.7%的NDS;
【QuadBEV: 高效的多任务感知框架】它利用四个关键任务——3D目标检测、车道检测、地图分割和占用预测——之间共享的空间和上下文信息。
【nuScenes-360和DeepAccident-360最新SOTA!】OneBEV:利用一幅全景图像进行鸟瞰语义建图!在nuScenes-360和DeepAccident-360上分别达到了51.1%和36.1%的mIoU,取得了最先进的性能。
2.报告和行业大佬直播分享

Occupancy感知
1.前沿工作
【OccLoff框架:旨在“学习优化特征融合”以进行3D占用预测】具体提出了一种稀疏融合编码器和熵掩模,该编码器可以直接融合3D和2D特征,从而提高模型的准确性,同时减少计算开销;
【nuScenes最新占用预测SOTA! TEOcc: 一种基于Radar-相机多模态的时间增强占用预测网络】所提出的时间增强分支是一个即插即用的模块,能够轻松集成到现有的占用预测方法中以提升占用预测的性能;
【SyntheOcc: 通过扩散模型生成的系统,它通过在驾驶场景中以占据标签为条件来合成真实感和几何控制的图像】
【RELIOCC:一种旨在增强基于相机的占用网络可靠性的方法】首次从可靠性角度对现有的语义占用预测模型进行全面评估。显著提高了模型的可靠性,同时保持几何和语义预测的准确性。
2.报告和行业大佬直播分享

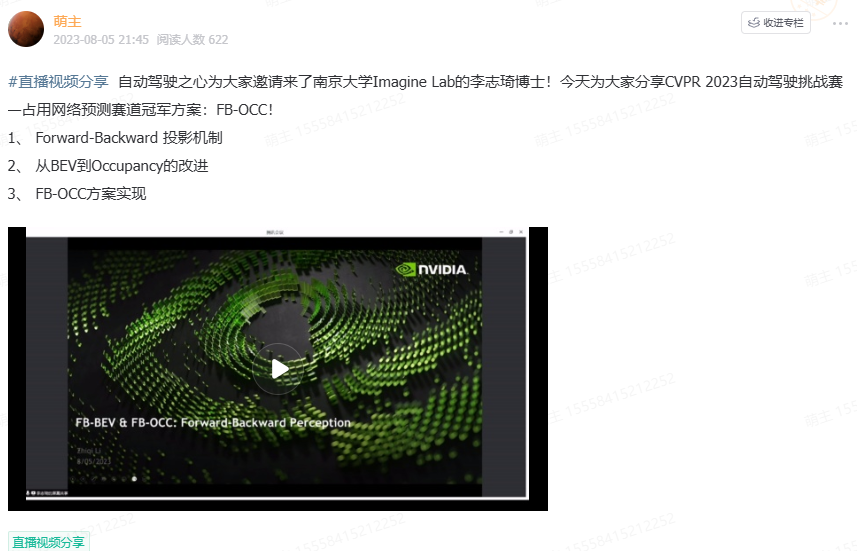
世界模型
1.前沿工作
【探索自动驾驶中视频生成与世界模型之间的相互作用:一项调查】探讨了这两种技术之间的关系,重点分析它们在结构上的相似性,尤其是在基于扩散的模型中,如何促进更准确和一致的驾驶场景模拟;
【从有效多模态模型到世界模型:探讨了MLMs的最新发展和挑战,强调它们在实现人工通用智能和作为通向世界模型的路径中的潜力】;
【nuPlan闭环规划新SOTA!AdaptiveDriver:一种基于模型预测控制(MPC)的规划器,可以根据BehaviorNet的预测展开不同的世界模型】将测试误差从6.4%减少到4.6%,即使应用于从未见过的城市;
【Vista:一个具有高保真度和多功能可控性的可泛化驾驶世界模型!】通过高效的学习策略,结合了一套多功能的控制方法,从高层次的意图(命令、目标点)到低层次的操作(轨迹、角度和速度),在超过70%的比较中优于最先进的通用视频生成器,并且在FID上超过最佳驾驶世界模型55%,在FVD上超过27%。
2.报告和行业大佬直播分享
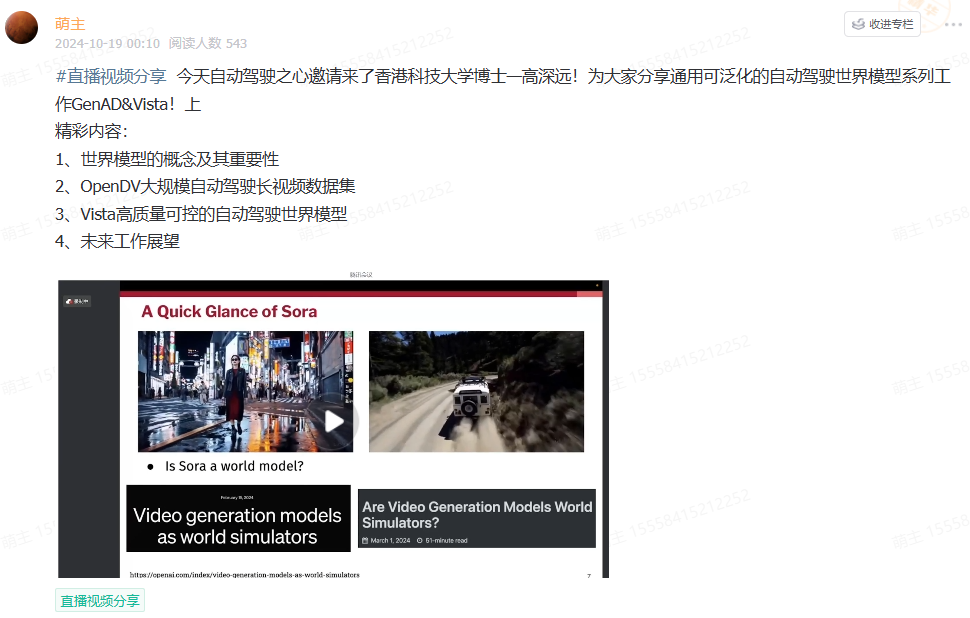
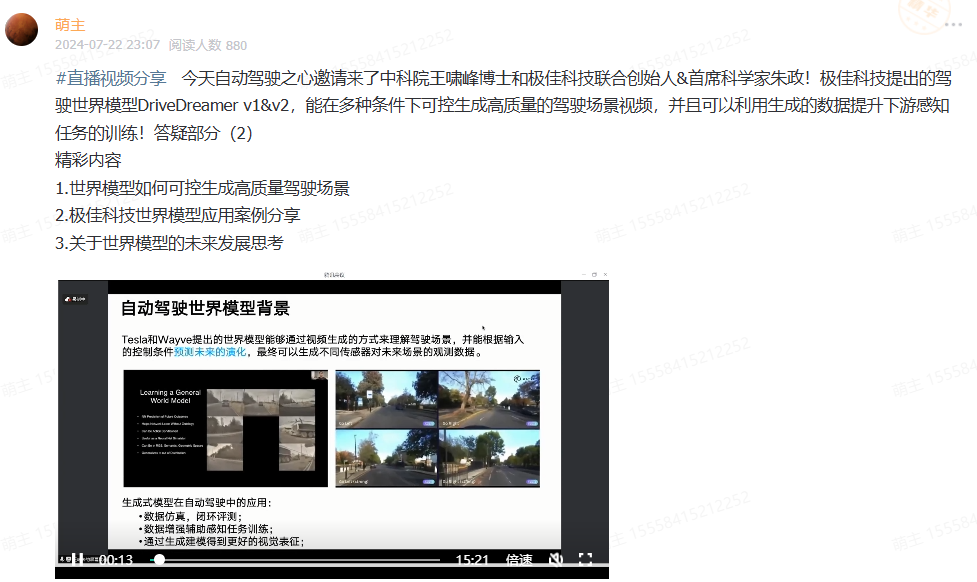
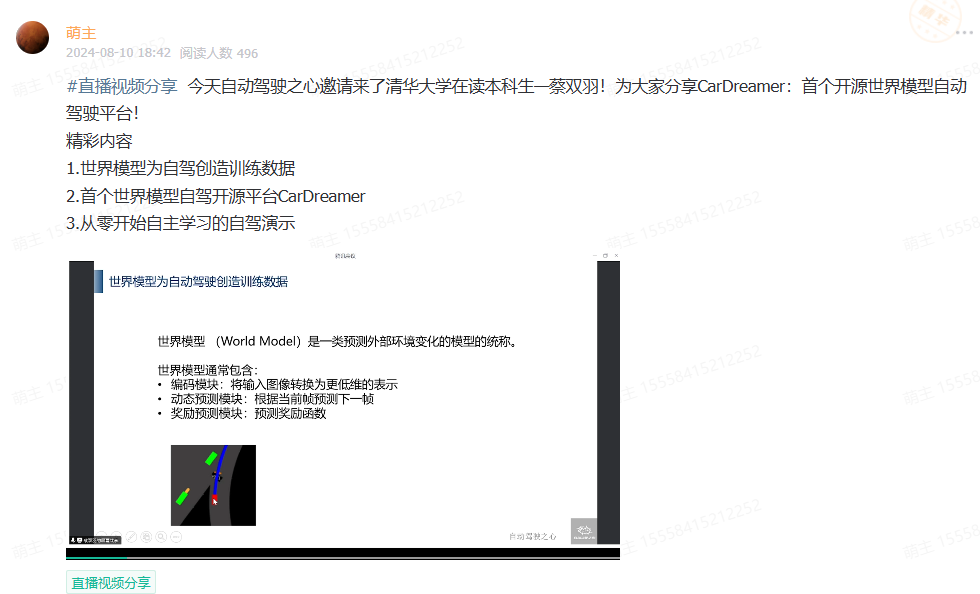
自动驾驶仿真
1.前沿工作
【IGDrivSim,一个基于Waymax仿真器的基准】证明人工专家与自动驾驶智能体之间的感知差距会妨碍安全和有效驾驶行为的学习;
【WorldSimBench:双重评估框架来评估世界仿真器】包括显式感知评估和隐式操作评估,涵盖了从视觉角度的人工偏好评估和具身任务中的动作级评估,涉及三个代表性的具身场景:开放式具身环境、自动驾驶和机器人操作;
【CARLA2Real,这是一个易于使用的公共工具(插件),适用于广泛使用的开源CARLA仿真器】;
【2024最新,自动驾驶框架和仿真器综述】本文回顾了开源和商业自动驾驶框架及仿真器,介绍并比较了它们的特点和功能等,还从硬件不足、自动驾驶算法、场景生成、V2X、安全与性能以及联合仿真等角度,提出了AD框架和仿真器在近期未来的有前景的研究方向。
2.报告和行业大佬直播分享


本文内容均出自『自动驾驶之心知识星球』,欢迎加入交流!
新用户66元现金优惠!微信扫码领取


















 39
39

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









