



点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
这个春节全是DeepSeek!大模型已经引领了2025年新一轮的潮流,自动驾驶也不例外。今天星主就和大家一起复盘下2024年自动驾驶领域的大模型工作,40+工作大盘点~本文内容均出自『自动驾驶之心知识星球』,欢迎加入交流,这里已经汇聚了近4000名自动驾驶从业人员,每日分享前沿技术、行业动态、岗位招聘、大佬直播等一手资料!
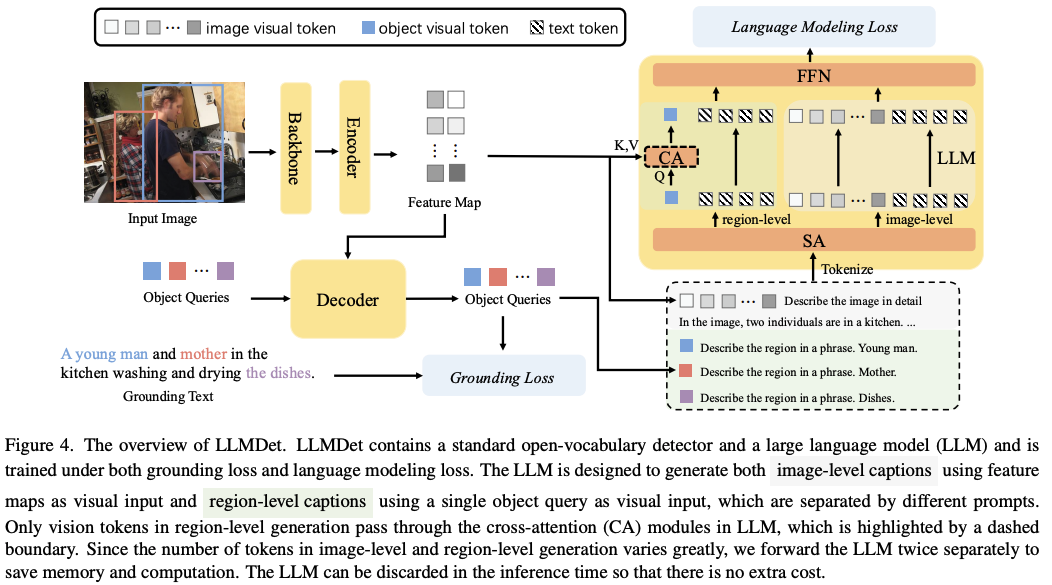
1、 题目:LLMDet: Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models
链接:https://t.zsxq.com/Qb92s
简介:LLMDet:在大型语言模型监督下学习强大的开放词汇目标检测器
时间:2025-02-03T15:16:18.110+0800
欢迎加入自动驾驶之心大家庭

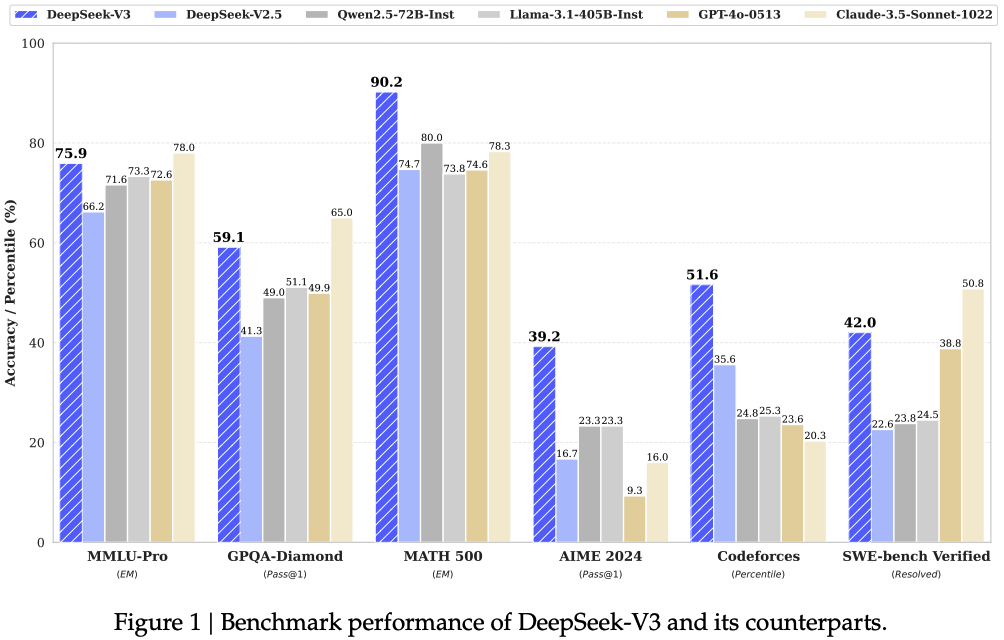
2、 题目:大火的DeepSeek V3技术报告
链接:https://t.zsxq.com/GhOkA
简介:大火的DeepSeek V3技术报告
时间:2025-01-30T20:48:13.279+0800
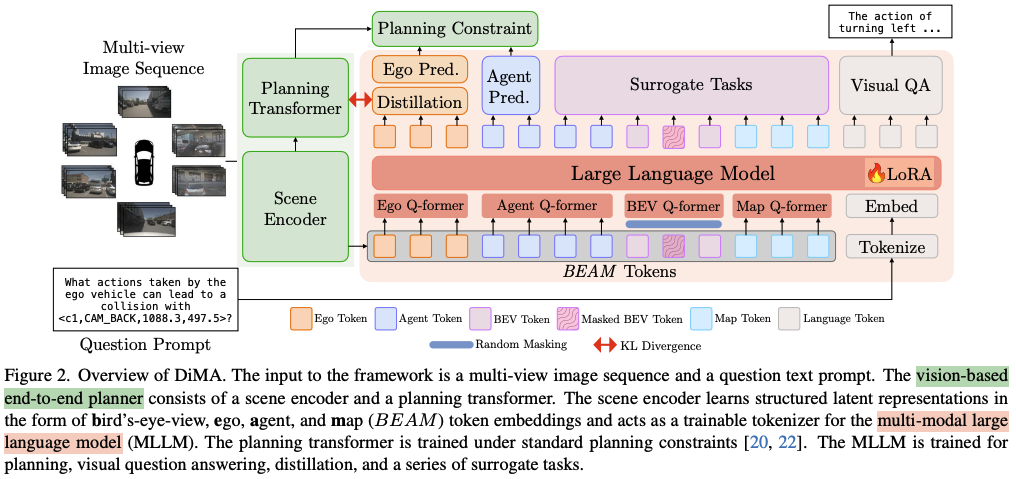
3、 题目:Distilling Multi-modal Large Language Models for Autonomous Driving
链接:https://t.zsxq.com/gG6mQ
简介:DiMA:旨在提高自动驾驶系统性能,同时解决计算效率问题的方案
时间:2025-01-17T23:25:06.463+0800
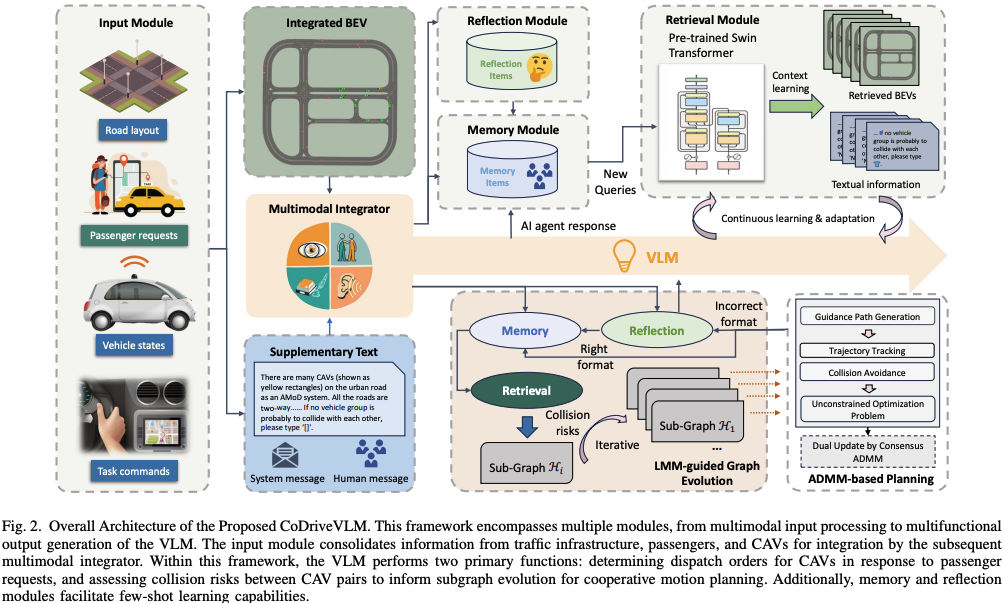
4、 题目:CoDriveVLM: VLM-Enhanced Urban Cooperative Dispatching and Motion Planning for Future Autonomous Mobility on Demand Systems
链接:https://t.zsxq.com/B24KA
简介:CoDriveVLM: 一种针对未来 AMoD 系统的高保真同时调度与协作运动规划集成框架
时间:2025-01-13T23:41:15.880+0800
5、 题目:Integrating LLMs with ITS: Recent Advances, Potentials, Challenges, and Future Directions
链接:https://t.zsxq.com/kDCmZ
简介:大语言模型(LLMs)和智能交通强强联合:最新进展、潜力、挑战和未来方向
时间:2025-01-12T13:19:09.482+0800

6、题目:2024中国AI大模型产业图谱3.0版
链接:https://t.zsxq.com/OH7mm
简介:2024年,AI大模型技术快速发展,已成为推动各行各业变革的核心力量。从文本处理到视频生成,再到自动化决策,AI大模型的应用正在渗透到各个领域,影响着产业格局的重构。为了帮助各界深入了解这一趋势并把握技术发展脉搏,经过不断研究与迭代,发布《2024中国AI大模型产业图谱3.0版》。
时间:2025-01-05T15:44:27.439+0800
7、 题目:Survey of Large Multimodal Model Datasets, Application Categories and Taxonomy
链接:https://t.zsxq.com/GpVND
简介:大型多模态模型数据集、应用和分类综述
时间:2024-12-28T19:26:31.325+0800
8、 题目:Application of Multimodal Large Language Models in Autonomous Driving
链接:https://t.zsxq.com/iXjzq
简介:自动驾驶中多模态大语言模型(MLLM)的应用
时间:2024-12-26T20:29:08.184+0800
9、 题目:VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving
链接:https://t.zsxq.com/ltFCA
简介:视觉-语言模型(VLMs)与强化学习强强联合!
时间:2024-12-23T19:20:33.501+0800
10、 题目:Large Language Models (LLMs) as Traffic Control Systems at Urban Intersections: A New Paradigm
链接:https://t.zsxq.com/c350c
简介:城市交叉口交通控制系统的大语言模型(LLM):一种新范式
时间:2024-12-22T22:46:42.561+0800
11、 题目:DriveGPT: Scaling Autoregressive Behavior Models for Driving
链接:https://t.zsxq.com/jP5tD
简介:DriveGPT,一个可扩展的自动驾驶行为模型
时间:2024-12-21T20:27:57.297+0800
12、 题目:AUTOTRUST : Benchmarking Trustworthiness in Large Vision Language Models for Autonomous Driving
链接:https://t.zsxq.com/ExUEx
简介:AutoTrust:一个全面的自动驾驶大规模视觉语言模型(DriveVLMs)信任性基准
时间:2024-12-20T21:25:46.786+0800
13、 题目:DriveMM: All-in-One Large Multimodal Model for Autonomous Driving
链接:https://t.zsxq.com/2XPdI
简介:六大基准全部SOTA!DriveMM: 面向自动驾驶的多模态一体化全能型大模型
时间:2024-12-11T21:26:46.475+0800
14、 题目:NVILA: Efficient Frontier Visual Language Models
链接:https://t.zsxq.com/mZiRs
简介:NVILA:高效前沿的视觉语言模型
时间:2024-12-08T21:00:39.503+0800
15、 题目:CALMM-Drive: Confidence-Aware Autonomous Driving with Large Multimodal Model
链接:https://t.zsxq.com/E8v5q
简介:CALMM-Drive: 全新的基于置信感知大规模多模态模型(LMM)的自动驾驶框架
时间:2024-12-07T00:16:14.523+0800
16、 题目:FASIONAD : FAst and Slow FusION Thinking Systems for Human-Like Autonomous Driving with Adaptive Feedback
链接:https://t.zsxq.com/LnA3S
简介:又一个灵感来自“思考,快与慢”的自动驾驶系统FASIONAD
时间:2024-11-28T19:04:26.580+0800
17、 题目:DriveMLLM: A Benchmark for Spatial Understanding with Multimodal Large Language Models in Autonomous Driving
链接:https://t.zsxq.com/Q0lVI
简介:多模态大模型在自动驾驶中的空间理解能力如何评估?
时间:2024-11-21T22:35:25.366+0800
18、 题目:On-Board Vision-Language Models for Personalized Autonomous Vehicle Motion Control: System Design and Real-World Validation
链接:https://t.zsxq.com/RJhf0
简介:首个基于VLM的端到端运动控制系统
时间:2024-11-20T16:10:26.824+0800
19、 题目:A Comprehensive Survey and Guide to Multimodal Large Language Models in Vision-Language Tasks
链接:https://t.zsxq.com/bTbmG
简介:视觉-语言多模态大模型的全面概述
时间:2024-11-14T17:49:47.618+0800
20、 题目:Large (Vision) Language Models for Autonomous Vehicles: Current Trends and Future Directions
链接:https://t.zsxq.com/hJu6x
简介:全面回顾当前关于L(V)LM在自动驾驶应用方面的研究
时间:2024-10-28T21:18:20.829+0800
21、 题目:Large Language Models for Autonomous Driving (LLM4AD): Concept, Benchmark, Simulation, and Real-Vehicle Experiment
链接:https://t.zsxq.com/F0F0R
简介:自动驾驶中的大语言模型(LLM4AD):概念、基准、仿真和实车实验
时间:2024-10-22T22:09:44.417+0800
22、 题目:大模型落地路线图研究报告(2024年)
链接:https://t.zsxq.com/KGMCu
简介:大模型落地路线图研究报告(2024年)
时间:2024-10-01T10:16:44.939+0800
23、 题目:XLM for Autonomous Driving Systems: A Comprehensive Review
链接:https://t.zsxq.com/KdFGu
简介:自动驾驶中的大模型!
时间:2024-09-17T19:52:01.672+0800
24、 题目:Hint-AD: Holistically Aligned Interpretability in End-to-End Autonomous Driving
链接:https://t.zsxq.com/b0nG8
简介:Hint-AD: 端到端自动驾驶中的整体一致性解释
时间:2024-09-11T22:07:18.325+0800
25、 题目:Hardware Acceleration of LLMs: A comprehensive survey and comparison
链接:https://t.zsxq.com/c1GjZ
简介:硬件加速大型语言模型的Transformer网络全面综述!
时间:2024-09-09T21:37:19.839+0800
26、 题目:Can LVLMs Obtain a Driver’s License? A Benchmark Towards Reliable AGI for Autonomous Driving
链接:https://t.zsxq.com/2BMoW
简介:自动驾驶缺少一个AGI可靠性基准!
时间:2024-09-07T00:01:23.089+0800
27、 题目:2024年中国AI大模型场景探索及产业应用调研报告
链接:https://t.zsxq.com/Xnw3C
简介:2024年中国AI大模型场景探索及产业应用调研报告——大模型“引爆”行业新一轮变革 AI大模型行业是技术驱动的行业,且仍具有巨大的挖掘潜力、技术更新进步速度也较快,行业技术能力拓展上限尚未出现。行业发展的七大趋势,一是技术趋势,具备强大预测能力的预测大模型、强大决策能力的决策大模型和能够自主学习、实时交互的具身智能大模型最有可能成为继自然语言大模型和多模态大模型后的下一个大模型行业风口;二是竞争趋势,AI大模型企业需将资源聚焦单一发展路径,行业竞争将开始分化;三是应用场景趋势,行业应用场景数量也将爆炸性的多元化增长,且会逐渐从当前的业务类场景向决策管理场景深入;四是应用行业趋势,前期信息化基础较好,对新兴技术接受度支付意愿也较高的金融、电商、教育和医疗领域是未来五年AI大模型应用潜力最高的四大下游行业领域;五是AI大模型的应用将反哺基础科学技术的发展;六是AI大模型将轻量化发展助力终端智能化;七是基础AI通用大模型将开源化赋能构建国产软件生态
时间:2024-09-04T21:52:22.892+0800
28、 题目:DriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving
链接:https://t.zsxq.com/yYUYz
简介:DriveGenVLM:基于视觉语言模型的自动驾驶实时视频生成
时间:2024-08-30T22:59:40.299+0800
29、 题目:Mixed Sparsity Training: Achieving 4× FLOP Reduction for Transformer Pretraining
链接:https://t.zsxq.com/mJTBi
简介:大模型的FLOP减少4倍,性能不受影响,你敢信?
时间:2024-08-22T23:30:36.335+0800
30、 题目:CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
链接:https://t.zsxq.com/mKJtd
简介:CoVLA(综合视觉-语言-动作)数据集
时间:2024-08-21T22:51:59.217+0800
31、 题目:Navigation Instruction Generation with BEV Perception and Large Language Models
链接:https://t.zsxq.com/DI9uc
简介:ECCV 2024
时间:2024-07-23T23:49:44.301+0800
32、 题目:From Efficient Multimodal Models to World Models: A Survey
链接:https://t.zsxq.com/NkhMA
简介:从有效多模态模型到世界模型:探讨了MLMs的最新发展和挑战,强调它们在实现人工通用智能和作为通向世界模型的路径中的潜力
时间:2024-07-03T23:47:17.369+0800
33、 题目:GPT-4V Explorations: Mining Autonomous Driving
链接:https://t.zsxq.com/NDnMu
简介:本文探讨了GPT-4V(视觉版大规模视觉语言模型)在采矿环境中的自动驾驶应用
时间:2024-06-25T22:20:58.939+0800
34、 题目:Asynchronous Large Language Model Enhanced Planner for Autonomous Driving
链接:https://t.zsxq.com/lgzDU
简介:大语言模型如何赋能自动驾驶规划?
时间:2024-06-23T16:00:03.578+0800
35、 题目:Autonomous Driving Systems with Large Language Models: A Comparative Study of Interpretability and Motion Planning
链接:https://t.zsxq.com/ovUgW
简介:分享一篇硕士论文,研究了将大型语言模型集成到自动驾驶系统中的方法,特别强调它们在增强可解释性、决策能力和规划能力方面的潜力。在CARLA模拟器中实现了数据驱动和知识驱动模型,涵盖各种场景,主要关注TransFuser和LMDrive框架。本研究利用一系列指标对这些模型进行了对比分析。结果表明,虽然LMDrive在运动规划方面存在某些限制,但它在可解释性方面表现出显著的能力,特别是在识别交通信号灯和检测颠簸路况方面。
时间:2024-06-18T21:05:47.529+0800
36、 题目:Text-to-Drive: Diverse Driving Behavior Synthesis via Large Language Models
链接:https://t.zsxq.com/17Y43
简介:LLM和自动驾驶越来越紧密了!文本到驾驶:通过大型语言模型合成多样化的驾驶行为
时间:2024-06-09T16:44:06.490+0800
37、 题目:Is a 3D-Tokenized LLM the Key to Reliable Autonomous Driving?
链接:https://t.zsxq.com/bkr7I
简介:2D Token的LLM能准确感知3D环境吗?
时间:2024-05-29T22:47:01.631+0800
38、 题目:Language-Image Models with 3D Understanding
链接:https://t.zsxq.com/5GZZQ
简介:Cube-LLM:具有3D理解能力的语言-图像模型新型MLLM
时间:2024-05-13T23:13:04.447+0800
39、 题目:OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception Reasoning and Planning
链接:https://t.zsxq.com/0Ko7W
简介:OmniDrive: 一个关于智能体模型与3D驾驶任务之间强大对齐的全面框架
时间:2024-05-04T13:56:58.171+0800
40、 题目:A Survey on Integration of Large Language Models with Intelligent Robots
链接:https://t.zsxq.com/hHdQd
简介:机器人领域的LLMs技术路线图
时间:2024-04-17T21:50:48.970+0800
41、 题目:DRIVEVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
链接:https://t.zsxq.com/mac9G
简介:自动驾驶与视觉大语言模型的强强联合会碰出怎样的火花?一起来看DRIVEVLM
时间:2024-02-20T22:02:08.269+0800
42、 题目:DME-Driver: Integrating Human Decision Logic and 3D Scene Perception in Autonomous Driving
链接:https://t.zsxq.com/GJCNi
简介:DME-Driver:自动驾驶中人的决策逻辑与3D场景感知的集成
时间:2024-01-10T23:26:44.013+0800
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入


















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









