



作者 | 陈陈 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/6223910015
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
记得两年前刚投稿ICLR时,扩散策略(Diffusion Policy)还基本是一个纯理论的概念,全网只有寥寥两三篇arxiv,而现在它俨然已成为RL和具身领域的“显学”了。组里目前也在探索大规模扩散通用具身智能体的构建(RDT-1B)。最近闲了点,打算梳理一下近两年领域的理论进展,也算总结下自己研究的心路历程,做个宣传。
要回答的问题:
扩散策略究竟“好”在哪?
扩散模型引入RL,带来的本质挑战和核心难点(坑)是什么?
总结Diffusion Policy的经典RL优化算法。以我自己的工作为主线,尽量用统一的理论体系归纳相关工作。侧重high-level的理解。(可能更新后续系列细致讲解某一类算法)
(我内心中)各个算法、特别是自己提出的算法缺陷到底是什么?目前Diffusion+RL还有哪些Open problem?
文章前置知识:
有一定ML数学基础,比如熟悉KL散度的定义,大概知道forward/reverse KL的定义和区别,知道minimize KL和maximize likelihood是等价的。
了解Diffusion modeling,知道它本质上是在估计score function,能看懂Diffusion Loss function (不需要会推导),了解Diffusion Guidance (CG&CFG)。
有一丢丢RL基础,知道s,a,r,s',a' 这五个物理量的意思,大概知道Q函数,Advantage函数和V函数是什么。如果熟悉Offline RL背景会更好。
PS:对于具身领域的读者,需要说明本文研究的Diffusion Policy并非单纯模仿学习训练,这只是第一步,更加侧重如何给定Task Reward或Human Preference后进一步优化扩散策略。
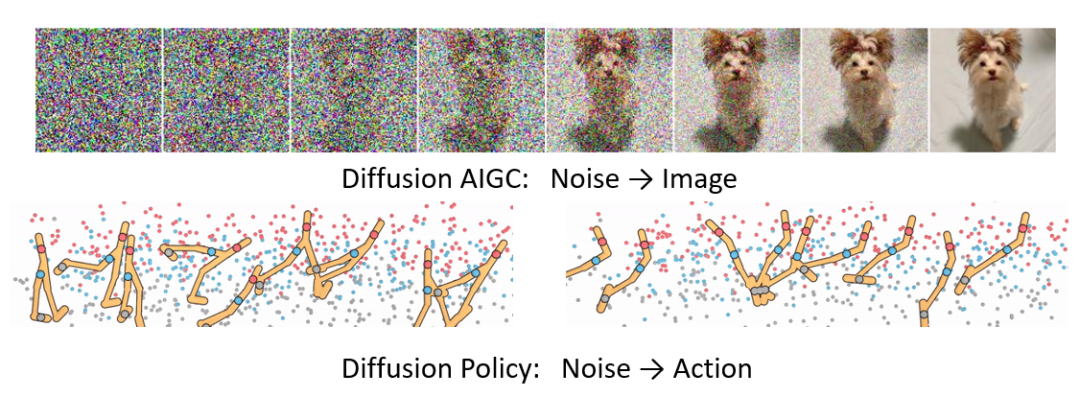
一、扩散策略的优势/研究动机
目前“扩散策略优于高斯/确定性策略”似乎已经被当做某种常识了,大家无外乎有这么几点论据:
(1)Policy Diversity。如果一个任务有多个最优解,确定性高斯策略最多只能学会一个,扩散策略可能全学会。
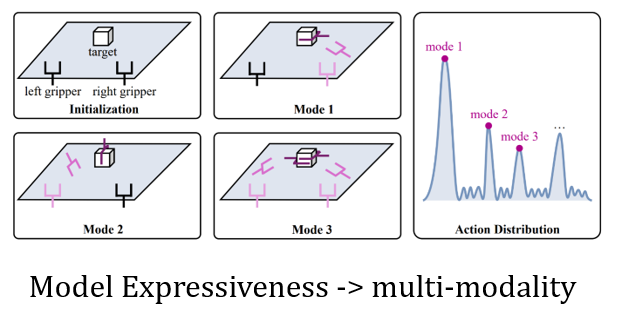
(2)刷榜。在D4RL这种标准榜单上性能领先Gaussian Policy一个身位(DiffusionQL[2]),在具身领域尽管没有统一benchmark,但众多文章的ablation study也显示扩散优于高斯(DP[3])。
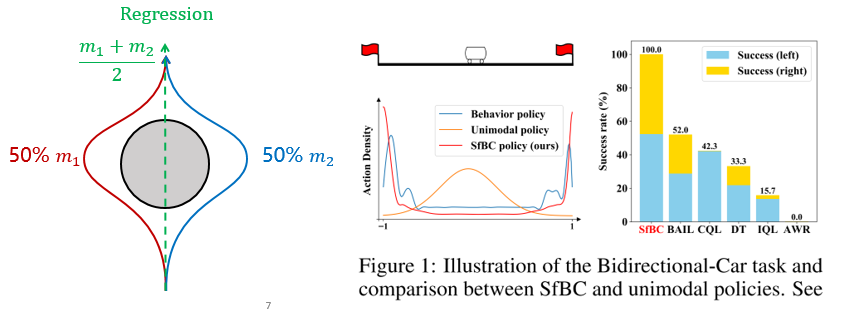
(3)不会“左右为难”。在模仿学习中如果既有向左走也有向右走的数据,确定性策略可能卡死不动,而扩散策略会学到“多峰”动作分布。(SfBC[4]; DP[3])
(4)Expressive Modeling Ability of Human Behaviors。扩散策略模拟人类复杂多样的行为数据,其拟合和建模能力肯定远优于高斯,上限更高。(Diffusion BC[5])
(5)兼容性。因为视频模型已经是基于Diffusion了,扩散策略方便与Diffusion World (video) Model无缝对接。目前也只有扩散模型适合做world model中一次性predict future sequence而不仅仅是predict one step的任务(Diffuser[6], Decision-Diffuser[7])
乍一看都非常有道理,Diffusion Policy 牛逼! 但这些论据合理性其实还是值得推敲的。
对(1),扩散策略天然具有多样性,但是传统RL任务以及具身任务中,“策略多样性”真的是我们的top priority吗?我们是希望模型稳定,可预测地完成任务,最大化奖励,还是希望它搞出各种花里胡哨的解决方案?再者,真的有很多任务存在多个“严格一样好”的控制策略吗?
对(2),D4RL榜单是典型只比较evaluation reward,不看policy diversity的榜单。难道只有扩散策略能够刷到很高的分数,传统高斯策略就不行吗?22/23年那会儿,我对(2)完全是持否定态度的,其实挺多传统算法后来也刷到了比较高的分数,但是没啥人关心罢了。这里面其实有很强的幸存者偏差:“扩散策略看起来有novelty,所以我要用;因为我要用,所以他就强”。(不过最近搞具身的同学不断给我反馈扩散策略就是明确强,我一直在琢磨是不是还有什么本质优势我没想清楚)
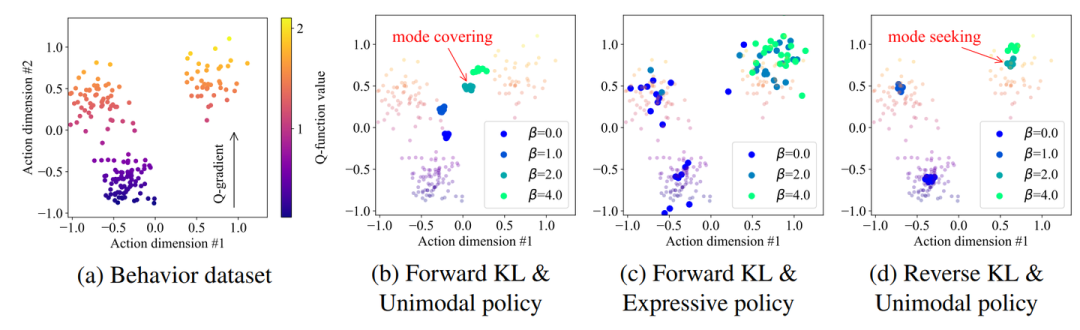
对(3),“左右为难”其实并不是高斯策略的问题,而是部分forward KL/Regression算法导致的mode-covering 的问题,换用有mode-seeking性质的reverse KL算法可以基本解决这个问题。典型反例就是SRPO[8]作为高斯策略,性能和Diffusion Policy持平,动作采样又远远快于扩散策略。后续文章会详细讨论。
对(4),这个没啥说的。特别是在游戏AI上,我们更希望人机表现更“像人”,而不是完虐人类。可惜绝大部分游戏的action输入都是离散变量,不适合扩散建模。鼠标/轮盘移动除外,[5]这篇代表作也是在cs go游戏上搞得(鼠标)。
对(5),也没啥反驳的。不过这种结合world model + planning 的方法一般计算量都超级大,我本人涉及不多(后面讨论也较少有MBRL方法,尽管这方面也有很多有意思的工作)。
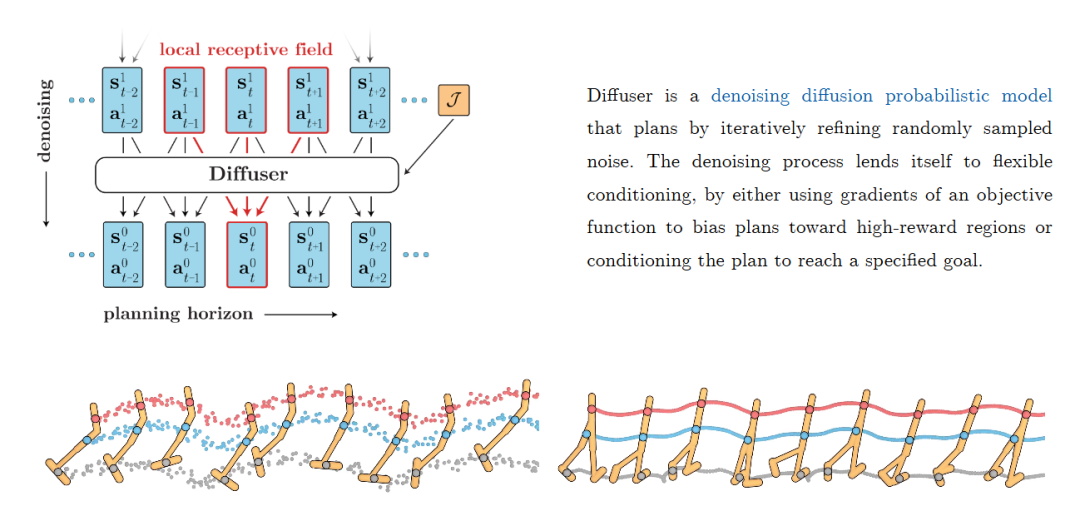
当然无可否认的事,扩散策略能够短时间内收到如此广泛的关注,其本质优势(哪怕是incremental的),也是明确而不可忽视的。上面五条单独看某一条都可以辩论下,但放在一起就是强有力的论据了。审慎辩证地看待扩散策略优势是我们找出其问题所在,开展更进一步研究的前提。
二、扩散策略带来的本质挑战是什么?
有人说扩散策略是用生成式视角处理RL问题。但是对于做强化学习的人来讲,生成模型(如GAN, VAE, EBM)用于RL训练也不是一天两天的事儿了。在强化学习中把VAE换成扩散模型,是不是简单套用前人研究,做模块化替换,A+B的组合就可以呢?虽然有些这么做的工作,但这样其实很难触及和把握领域的前沿问题/方向。
我的观点:研究扩散策略,还是要先搞清楚“扩散建模”带来的哪些难点是本质的,我认为其理论层面引入独一无二的挑战只有两个:似然估计问题和采样效率问题。
1. 似然估计问题
在扩散策略之前,整个强化学习的理论系统都是围绕着Explicit Likelihood Modeling 设计的,这在连续控制上反应为高斯模型,反应在离散动作(如LLM)上是分类模型(Categorical models)。以PPO为例
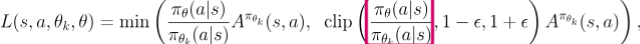

不仅仅是RL算法,由于相同原因,LLM Alignment中经典的DPO算法以及诸多Preference Learning方法都无法直接迁移到扩散策略上。以DPO为例:

现状:
1)上面的问题对于Offline RL并不太致命,22年左右扩散策略研究工作的核心就是在解决这个问题。其中SfBC[4]这篇文章首次明确提出了这个难点,Diffuser[6],CEP[9],Decision Diffuser[7] 三篇文章分别使用Energy Guidance和Classifier Free Guidance (CFG)手段对上面问题给出了比较漂亮的理论解析,Diffusion-QL[2]用基于ELBO的监督训练方法给出了一种实用的算法。重采样/引导采样/监督训练 三类手段基本也成为了目前Diffusion RL主流方法。
2)然而,PPO/REINFORCE算法无法直接使用,对于Online RL影响巨大。我目前还没看到特别漂亮的解决方案。现有的方法基本上还是把Online Diffusion Policy 优化近似等于iterative offline RL去优化,也没有充分考虑online RL中特有的Exploration问题(扩散策略是可以多峰探索的!有巨大想象空间),感觉有点不本质。自己做的一些理论推导尝试也都不满意。目前我感觉还是Open Problem。
3)对于Diffusion Policy+Alignment问题。由于LLM Alignment发展的助推,最近这个方向的研究有很多,但应用并不在“扩散策略”上,而是在“图像生成模型上”,譬如DDPO[10],Diffusion-DPO[11]这类算法。然而,即使在图像上,目前也没有理论特别完美的算法,基本依赖推导中引入较多“约等于”符号,导致扩散与语言模型Alignment算法基本属于两个独立的体系。在扩散策略上基本不依赖近似,直接引入现有LLM Alignment策略的,我认为自己Nips24的工作EDA[12]算一个,但其也有本质问题,如对模型结构有特殊要求,有机会后面详细介绍。总体而言,我觉得这个领域处于active exploration状态。
2. 采样效率问题
扩散模型需要多步采样,图像一般是15-100步,具身/RL中一般是5-50步。采样效率不仅仅是扩散策略,而是整个扩散模型领域的本质问题。但这个问题反应在控制任务中比在图像视频采样问题中解决需求更加急迫一些。
(1)控制频率问题。这个好理解,扩散模型一般参数要多一些,特别是RDT-1B这种大模型,叠加上多步采样,可能会很大程度上降低控制频率,直接影响“能用”还是“不能用”的问题。目前我了解到的解决方法有
a. 强行降低采样步数到5步,Diffusion-QL[2],RDT-1B[1]就是这样。在实践中,这些工作发现5步其实已经效果很好(足够)了,但是我对这个操作还是很担心,因为从ODE数值积分理论上推,5步采样几乎没有任何采样精度保证,所以这个系统效果有点看命,我自己的工作基本采用DPM-Solver采样,感觉最低也就是到10步,和图像上的经验一致。传统Diffusion基本就是10步图片能看,5步不太能看的水平。
b. 蒸馏。这类方法基本上就是跟着图像领域的发展走,都是先训练一个diffusion policy再进一步蒸成单步策略。我目前知道主流的方案一是Consistency model/policy,最早的工作是[13,14],二是score distillation,最早的工作是SRPO[8]。目前给我的感觉,方案一的主要问题就是CM本身的问题:基于bootstrapping的损失函数有训练有点不稳定、参数敏感。方案二的主要问题是,蒸馏出来的新模型损失掉了diversity,重新变成了Gaussian Policy。不过后续有一些新工作用Gaussian Mixture [15]或者GAN [16]的思路部分解决了这个问题。
c. 近似采样。这类工作更理论一些,基本就是用Diffusion Sampling过程中的一些数学性质,直接近似估计x_0而不走完完整的采样流程。代表工作是EDP[17],这也是我所知道最早专门针对扩散策略解决采样效率问题的工作。这类方法的问题和降低采样步数到5步方法的局限性比较类似,就是引入的“约等号”有点粗糙了,缺乏强理论保证,不知道能不能scale up。
(2)Q函数优化问题
扩散策略不仅仅拖慢inference速度,也拖慢训练速度,原因就是很多RL算法训练的时候依赖训练一个Q函数,而这个过程是依赖于实时从当前policy中采样的:
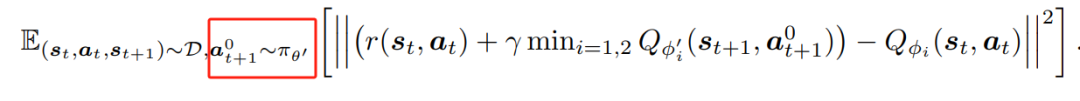
如果a要从扩散模型中采样,这个损失函数就会变得非常低效。更加要命的问题是,比如Diffusion-QL本身动作采样就是5步完成的,采样已经很不精确了,且扩散策略在训练初期,没收敛的模型采样出来的动作样本还有严重的数值问题(比如采出来个1e5这种离群点),现在采样不精确性造成的误差会进一步通过训练传导到Q函数中,Bootstrapping Q loss本身又不稳定。几个因素叠加,就回导致这种方法训练高度依赖调参,且在部分稀疏奖励任务上还容易炸掉。
这个问题说实在还没有太好的解决方法,我在后期的工作中都选用了IQL算法预训练一个Q函数,至少解耦policy learning和Q-learning,可以大大降低调参难度。
(插一嘴,尽管目前不得不用,我认为bootstrapping q learning的算法一定不是未来长远的rl算法,合理的q学习不应当是左脚踩右脚的耦合系统,我比较看好用类似dpo的方法直接学trajectory reward从而孤立出q function,可以参考我之前from r to q* 一篇blog,很希望在这块与有兴趣同学交流合作)
(3)模型优化问题
多步采样,也会导致扩散策略较难用DDPG这种梯度反传的方式来优化policy:
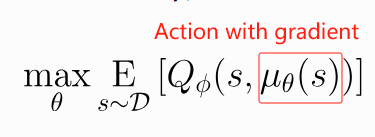
原因很简单,多步采样会使模型梯度层层累积,最终导致梯度爆炸问题。
然而不得不承认,这种方法在特定场景下也还能用,甚至有奇效。比如Diffusion-QL中,通过强行压低采样步数为5,模型又只使用3层的MLP解决了这个问题。这个方法在图像Alignment领域也是主流方法之一,然而图像至少要20步以上采样,直接使用此方案必然导致梯度爆炸,现在的主流算法是采样图片的前15步强行detach gradient,只在最后5步保留梯度信息。我反正觉得有点tricky,不够优雅。(:相关工作的作者别打我
(4)Online RL问题
Online RL不再是从静态数据集学习,要一边和环境交互一边学习。然而交互需要扩散策略产生动作,采样动作有精度误差又很慢。。。。。难受,研究不了一点儿(我想现在搞llm alignment 中online算法的研究者应该也是一样的感觉吧
三、Forward KL or Reverse KL?扩散优化算法理论体系
后续系列已经更新
陈陈:扩散策略算法归纳整理(二):前向KL优化理论
https://zhuanlan.zhihu.com/p/8615075797
相关文献
[1] ="https://arxiv.org/abs/2410.07864">RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation 2024.10
[2] DiffusionQL: Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning 2022.8
[3] DP: Diffusion Policy: Visuomotor Policy Learning via Action DiffusionDiffusion Policy: Visuomotor Policy Learning via Action Diffusion 2023.3
[4] SfBC: Offline Reinforcement Learning via High-Fidelity Generative Behavior Modeling 2022.9
[5] Diffusion BC: Imitating Human Behaviour with Diffusion ModelsImitating Human Behaviour with Diffusion Models 2023.1
[6] Diffuser: Planning with Diffusion for Flexible Behavior Synthesis 2022.05
[7] DD: Is Conditional Generative Modeling all you need for Decision Making? 2022.11
[8] SRPO: Score Regularized Policy Optimization through Diffusion Behavior 2023.10
[9] CEP/QGPO: Contrastive Energy Prediction for Exact Energy-Guided Diffusion Sampling in Offline Reinforcement Learning 2023.04
[10]: DDPO: Training Diffusion Models with Reinforcement LearningTraining Diffusion Models with Reinforcement Learning 2023.5
[11] DiffusionDPO: Diffusion Model Alignment Using Direct Preference OptimizationDiffusion Model Alignment Using Direct Preference Optimization 2023.11
[12] EDA: Aligning Diffusion Behaviors with Q-functions for Efficient Continuous Control 2024.7
[13]:Consistency Models as a Rich and Efficient Policy Class for Reinforcement Learning 2023.9
[14]:Boosting Continuous Control with Consistency Policy 2023.9
[15]: Variational Distillation of Diffusion Policies into Mixture of ExpertsVariational Distillation of Diffusion Policies into Mixture of Experts Variational Distillation of Diffusion Policies into Mixture of Experts
[16]:One-Step Diffusion Policy: Fast Visuomotor Policies via Diffusion Distillation 2024.10
[17]: Efficient Diffusion Policies for Offline Reinforcement LearningEfficient Diffusion Policies for Offline Reinforcement Learning Efficient Diffusion Policies for Offline Reinforcement Learning
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1524
1524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









