



点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享北大最新的工作—OpenAD!自动驾驶全面迈向开放3D检测世界。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
论文作者 | Zhongyu Xia等
编辑 | 自动驾驶之心
写在前面 & 笔者的个人理解
开放世界自动驾驶包括域泛化和开放词汇。领域泛化是指自动驾驶系统在不同场景和传感器参数配置下的能力。开放词汇是指识别训练中没有遇到的各种语义类别的能力。在本文中,我们介绍了OpenAD,这是第一个用于3D目标检测的现实世界开放世界自动驾驶基准。OpenAD建立在与多模态大型语言模型(MLLM)集成的角案例发现和标注管道之上。所提出的管道以统一的格式为五个具有2000个场景的自动驾驶感知数据集标注corner case目标。此外,我们设计评估方法,评估各种2D和3D开放世界和专业模型。此外,我们提出了一种以视觉为中心的3D开放世界目标检测基线,并通过融合通用和专用模型进一步引入了一种集成方法,以解决OpenAD基准现有开放世界方法精度较低的问题。
项目链接:https://github.com/VDIGPKU/OpenAD
总结来说,本文的主要贡献如下:
提出了一个开放世界基准,同时评估目标检测器的领域泛化和开放词汇表能力。据我们所知,这是3D开放世界物体检测的第一个现实世界自动驾驶基准。
设计了一个与MLLM集成的标注管道,用于自动识别极端情况场景,并为异常目标提供语义标注。
提出了一种结合二维开放世界模型的三维开放世界感知基线方法。此外,我们分析了开放世界和专业模式的优缺点,并进一步介绍了一种融合方法来利用这两种优势。
相关工作回顾
Benchmark for Open-world Object Detection
2D基准。各种数据集已被用于2D开放词汇表目标检测评估。最常用的是LVIS数据集,它包含1203个类别。
在自动驾驶领域,如表1所示,也提出了许多数据集。其中,CODA是一个用于自动驾驶中二维物体检测的道路拐角案例数据集,包含1500个道路驾驶场景,其中包含34个类别的边界框注释。然而,一些数据集只提供语义分割注释,没有特定的实例,或者将目标注释为异常但缺乏语义标签。此外,从真实世界的驾驶数据中收集的数据集规模较小,而来自CARLA等模拟平台的合成数据缺乏真实性,因此难以进行有效的评估。相比之下,我们的OpenAD提供了来自真实世界数据的大规模2D和3D边界框注释,用于更全面的开放世界目标检测评估。
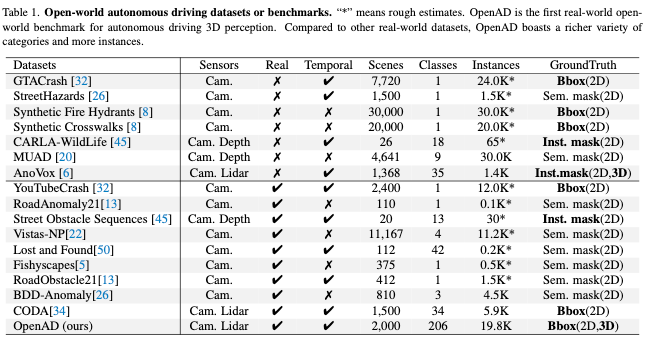
3D基准。3D开放世界基准测试可分为两类:室内和室外场景。对于室内场景,SUN-RGBD和ScanNet是两个经常用于开放世界评估的真实世界数据集,分别包含约700和21个类别。对于户外或自动驾驶场景,AnoVox是一个合成数据集,包含35个类别的实例掩码,用于开放世界评估。然而,由于模拟资产有限,合成数据的质量和实例多样性不如真实世界的数据。除了AnoVox之外,现有的用于自动驾驶的真实数据3D目标检测数据集只包含少数目标类别,很难用于评估开放世界模型。为了解决这个问题,我们提出了OpenAD,它由真实世界的数据构建而成,包含206个出现在自动驾驶场景中的不同corner-case类别。
2D Open-world Object Detection Methods
为了解决分布外(OOD)或异常检测问题,早期的方法通常采用决策边界、聚类等来发现OOD目标。最近的方法采用文本编码器,即CLIP,将相应类别标签的文本特征与框特征对齐。具体来说,OVR-CNN将图像特征与字幕嵌入对齐。GLIP将目标检测和短语基础统一用于预训练。OWL ViT v2使用预训练的检测器在图像-文本对上生成伪标签,以扩大检测数据用于自训练。YOLO World采用YOLO类型的架构进行开放词汇检测,并取得了良好的效率。然而,所有这些方法在推理过程中都需要预定义的目标类别。
最近,一些开放式方法提出利用自然语言解码器提供语言描述,这使它们能够直接从RoI特征生成类别标签。更具体地说,GenerateU引入了一种语言模型,可以直接从感兴趣的区域生成类标签。DetClipv3引入了一个目标字幕器,用于在推理过程中生成类标签和用于训练的图像级描述。VL-SAM引入了一个无需训练的框架,其中注意力图作为提示。
3D Open-world Object Detection Methods
与2D开放世界目标检测任务相比,由于训练数据集有限和3D环境复杂,3D开放世界目标探测任务更具挑战性。为了缓解这个问题,大多数现有的3D开放世界模型都来自预训练的2D开放世界模型,或者利用丰富的2D训练数据集。
例如,一些室内3D开放世界检测方法,如OV-3DET和INHA,使用预训练的2D目标检测器来引导3D检测器找到新的目标。同样,Coda利用3D box几何先验和2D语义开放词汇先验来生成新类别的伪3D box标签。FM-OV3D利用稳定扩散生成包含OOD目标的数据。至于户外方法,FnP在训练过程中使用区域VLMs和贪婪盒搜索器为新类生成注释。OV-Uni3DETR利用来自其他2D数据集的图像和由开放词汇检测器生成的2D边界框或实例掩码。
然而,这些现有的3D开放词汇检测模型在推理过程中需要预定义的目标类别。为了解决这个问题,我们引入了一种以视觉为中心的开放式3D目标检测方法,该方法可以在推理过程中直接生成无限的类别标签。
OpenAD概览
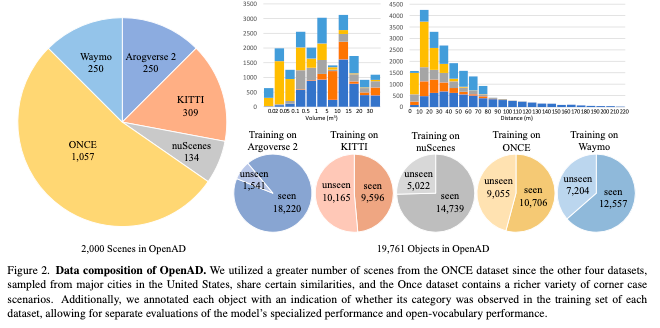
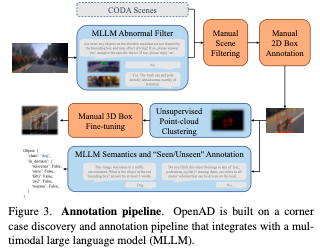
Baseline Methods of OpenAD
Vision-Centric 3D Open-ended Object Detec- tion
由于现有3D感知数据的规模有限,直接训练基于视觉的3D开放世界感知模型具有挑战性。我们利用具有强大泛化能力的现有2D模型来解决这个问题,并为3D开放世界感知提出了一个以视觉为中心的基线。
如图4所示,最初采用任意现有的二维开放世界目标检测方法来获得二维边界框及其相应的语义标签。同时,缓存由2D模型的图像编码器生成的图像特征图。随后,引入了一个结合了多个特征和一些可训练参数的2D到3D Bbox转换器,将2D box转换为3D box。
具体来说,我们使用现有的深度估计模型,如ZoeDepth、DepthAnything和UniDepth,通过2D框获得裁剪图像的深度图。我们还包括一个可选的分支,该分支利用激光雷达点云和线性拟合函数,通过将点云投影到图像上来细化深度图。同时,为了消除2D边界框内不属于前景目标的区域,我们利用Segment Anything Model(SAM)以2D框为提示对目标进行分割,从而产生分割掩码。之后,我们可以使用像素坐标、深度图和相机参数为分割掩模构建伪点云。我们将伪点云投影到特征图和深度图上,并通过插值将特征分配给每个点。然后,我们采用PointNet来提取伪点云的特征fp。同时,2D边界框内的深度图和特征图沿着通道维度连接,其特征fc是通过卷积和全局池化得到的。最后,我们利用MLP来预测具有fp和fc级联特征的目标的3D边界框。
在此基线中,2D到3D Bbox Converter中只有少数参数是可训练的。因此,培训成本低。此外,在训练过程中,每个3D目标都充当此基线的数据点,从而可以直接构建多域数据集训练。
General and Specialized Models Fusion
在实验中,我们发现现有的开放世界方法或通用模型在处理属于常见类别的目标方面不如闭集方法或专用模型,但它们表现出更强的领域泛化能力和处理极端情况的能力。也就是说,现有的通用和专用模型是相辅相成的。因此,我们利用它们的优势,通过结合两种模型的预测结果,提出了一个融合基线。具体来说,我们将两种模型的置信度得分对齐,并使用双阈值(即IoU和语义相似性)执行非最大抑制(NMS),以过滤重复项。
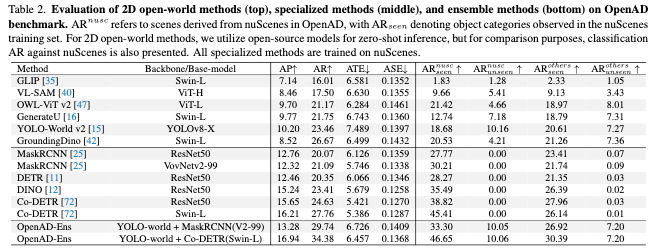
实验结果
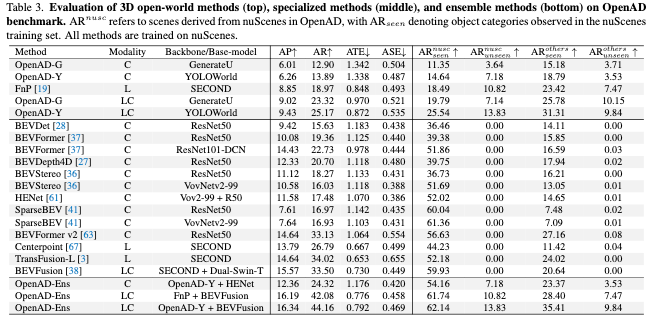


结论
在本文中,我们介绍了OpenAD,这是第一个用于3D目标检测的开放世界自动驾驶基准。OpenAD建立在与多模态大型语言模型集成的角案例发现和注释管道之上。该管道以格式对齐五个自动驾驶感知数据集,并为2000个场景注释角案例目标。此外,我们还设计了评估方法,并分析了现有开放世界感知模型和自动驾驶专业模型的优缺点。此外,为了应对训练3D开放世界模型的挑战,我们提出了一种结合2D开放世界模型进行3D开放世界感知的基线方法。此外,我们引入了一种融合基线方法,以利用开放世界模型和专用模型的优势。
通过对OpenAD进行的评估,我们观察到现有的开放世界模型在域内上下文中仍然不如专门的模型,但它们表现出更强的域泛化和开放词汇能力。值得注意的是,某些模型在域内基准测试上的改进是以牺牲其开放世界能力为代价的,而其他模型则不是这样。这种区别不能仅仅通过测试域内基准来揭示。
我们希望OpenAD可以帮助开发超越专业模型的开放世界感知模型,无论是在同一领域还是跨领域,无论是对于可见还是未知的语义类别。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1604
1604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









