




点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享东南大学最新的世界模型综述!全面复盘了世界模型在自动驾驶中的工作及未来发展趋势。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
论文作者 | Ao Fu等
编辑 | 自动驾驶之心
写在前面 & 笔者的个人理解
世界模型和视频生成是自动驾驶领域的关键技术,每项技术在提高自动驾驶系统的鲁棒性和可靠性方面都发挥着至关重要的作用。模拟真实世界环境动态的世界模型和产生逼真视频序列的视频生成模型正越来越多地被整合,以提高自动驾驶汽车的态势感知和决策能力。本文研究了这两种技术之间的关系,重点研究了它们的结构相似性,特别是在基于扩散的模型中,如何有助于更准确、更连贯地模拟驾驶场景。我们研究了JEPA、Genie和Sora等领先工作,这些工作展示了世界模型设计的不同方法,从而突显了世界模型缺乏普遍接受的定义。这些不同的解释强调了该领域对如何针对各种自动驾驶任务优化世界模型的不断发展的理解。此外,本文还讨论了该领域采用的关键评估指标,如用于3D场景重建的Chamfer distance和用于评估生成视频内容质量的FID。通过分析视频生成和世界模型之间的相互作用,本调查确定了关键挑战和未来的研究方向,强调了这些技术共同提高自动驾驶系统性能的潜力。本文的研究结果旨在全面了解视频生成和世界模型的集成如何推动开发更安全、更可靠的自动驾驶汽车的创新。
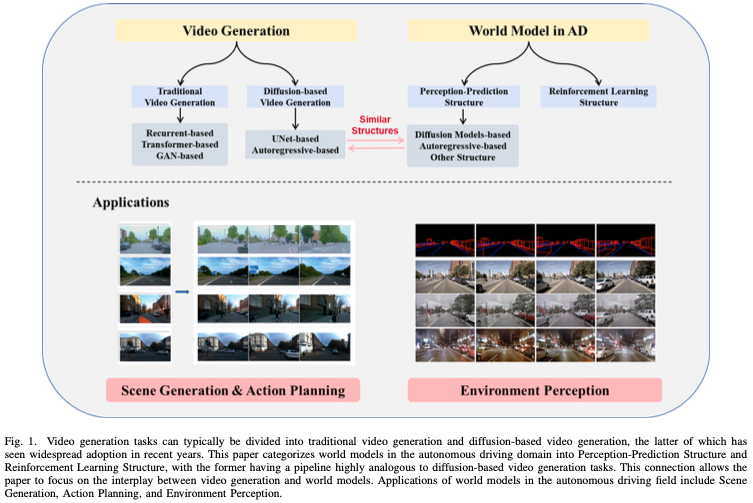
总结来说。本调查探讨了集成视频生成和世界模型的最新进展和挑战,重点关注它们在自动驾驶中的应用,如图1所示。它旨在突出这些技术的结构相似性和协同潜力,为自动驾驶汽车技术领域的未来研究方向和实际应用提供见解。具体而言,与其他作品相比,本综述有以下四个主要贡献:
分析了各个领域的世界模型的定义,强调世界模型的概念并不完全固定。它
介绍了我们对世界模型的理解,并考察了自动驾驶领域世界模型的结构一致性。
强调了视频生成模型和世界模型之间的结构相似性,解释了这些相似性如何提高自动驾驶系统的性能和能力。
确定了整合视频生成和世界模型的关键挑战和机遇,提供了如何在现实世界场景中进一步开发和应用这些技术的见解。
视频生成
视频生成涉及通过深度神经网络利用历史数据预测未
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









