



点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
编辑 | 自动驾驶之心
TensorRT-LLM是NVIDIA推出的一款高性能深度学习推理优化库,专注于提升大型语言模型(LLM)在NVIDIA GPU上的推理速度和效率。如果您绕不开Nvidia的芯片,那么一定要好好了解这款推理库。
项目链接:https://github.com/NVIDIA/TensorRT-LLM
一、TensorRT-LLM的优势
TensorRT-LLM(TensorRT for Large Language Models)旨在解决大型语言模型在实际应用中面临的性能瓶颈问题。通过提供一系列专为LLM推理设计的优化工具和技术,TensorRT-LLM能够显著提升模型的推理速度,降低延迟,并优化内存使用。
二、TensorRT-LLM的核心功能
1)易于使用的Python API
TensorRT-LLM提供了一个简洁易用的Python API,允许用户定义大型语言模型并构建包含先进优化的TensorRT引擎。
该API设计类似于PyTorch,使得具有PyTorch经验的开发者能够轻松迁移和集成。
2)模型优化
TensorRT-LLM支持多种量化选项(如FP16、INT8等),用户可以根据具体需求选择合适的配置,实现性能与精度的平衡。
通过层级融合、内核选择和精度调整等优化技术,TensorRT-LLM能够显著提升模型的推理速度。
3)内存管理
TensorRT-LLM通过智能内存分配和分页注意力机制,优化了内存使用,降低了内存占用。
4)多线程并行与硬件加速
支持多线程并行处理,提高处理速度。
充分利用NVIDIA GPU的计算能力,加速模型推理。
5)动态批处理
TensorRT-LLM支持动态批处理,通过同时处理多个请求来优化文本生成,减少了等待时间并提高了GPU利用率。
6)多GPU与多节点推理
支持在多个GPU或多个节点上进行分布式推理,提高了吞吐量并减少了总体推理时间。
7)FP8支持
配备TensorRT-LLM的NVIDIA H100 GPU能够轻松地将模型权重转换为新的FP8格式,并自动编译模型以利用优化的FP8内核。这得益于NVIDIA Hopper架构,且无需更改任何模型代码。
8)最新GPU支持
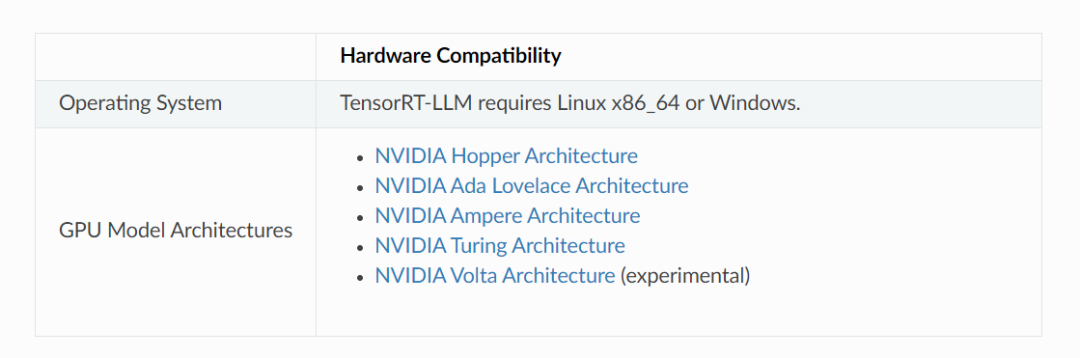
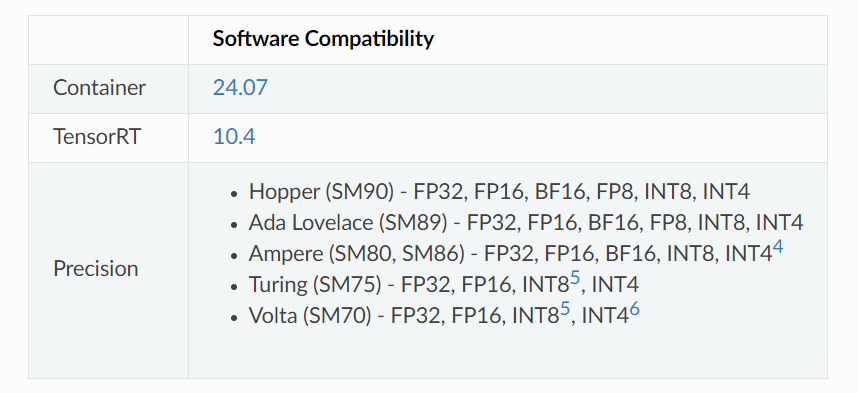
TensorRT-LLM 支持基于 NVIDIA Hopper、NVIDIA Ada Lovelace、NVIDIA Ampere、NVIDIA Turing 和 NVIDIA Volta 架构的GPU。
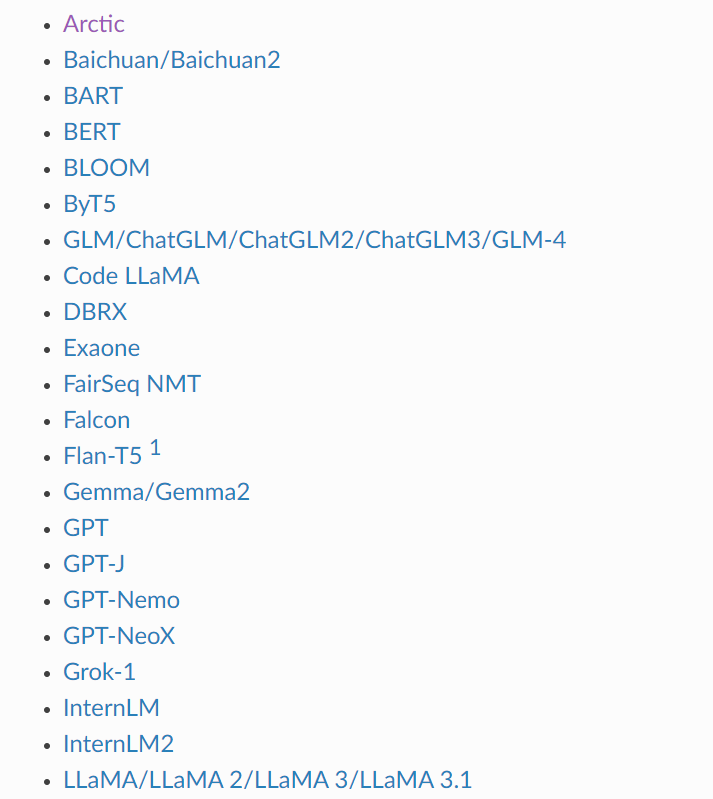
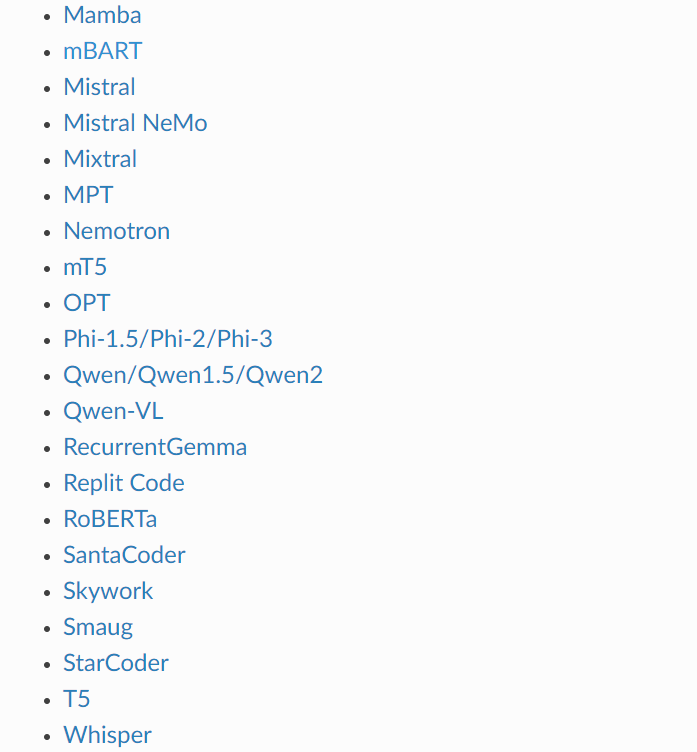
三、TensorRT-LLM支持部署的模型
1)LLM系列
2)多模态大模型

四、量化相关
INT8 SmoothQuant (W8A8)
SmoothQuant技术在:https://arxiv.org/abs/2211.10438中被介绍。它是一种使用INT8对激活和权重进行推理的方法,同时保持网络(在下游任务中)的准确性。如研究论文所述,必须对模型的权重进行预处理。TensorRT-LLM包含用于准备模型以使用SmoothQuant方法运行的脚本。
关于如何为GPT、GPT-J和LLaMA启用SmoothQuant的示例,可以在版本的examples/quantization文件夹中找到。
INT4和INT8仅权重量化 (W4A16和W8A16)
INT4和INT8仅权重量化技术包括对模型的权重进行量化,并在线性层(Matmuls)中动态地对这些权重进行反量化。激活使用浮点数(FP16或BF16)进行编码。要使用INT4/INT8仅权重量化方法,用户必须确定用于量化和反量化模型权重的缩放因子。
GPTQ和AWQ (W4A16)
GPTQ和AWQ技术分别在https://arxiv.org/abs/2210.17323和https://arxiv.org/abs/2306.00978中介绍。TensorRT-LLM支持在线性层中使用每组缩放因子和零偏移来实现GPTQ和AWQ方法。有关详细信息,请参阅WeightOnlyGroupwiseQuantMatmulPlugin插件和相应的weight_only_groupwise_quant_matmulPython函数。
代码中包括将GPTQ应用于GPT-NeoX和LLaMA-v2的示例,以及使用AWQ与GPT-J的示例。这些示例是实验性实现,并可能在未来的版本中有所改进。
FP8 (Hopper)
TensorRT-LLM包含为GPT-NeMo、GPT-J和LLaMA实现的FP8。这些示例可以在examples/quantization中找到。
五、TensorRT-LLM支持的硬件和软件
六、TensorRT-LLM的应用场景
TensorRT-LLM在多个领域展现了其强大的应用能力,包括但不限于:
在线客服系统:通过实时的对话生成,提供无缝的人工智能辅助服务。
搜索引擎:利用模型对查询进行增强,提供更精准的搜索结果。
自动代码补全:在IDE中集成模型,帮助开发者自动完成代码编写。
内容创作平台:自动生成文章摘要或建议,提升创作者的工作效率。
『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵



















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









