



作者 | 迪迦奥特曼 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
极市导读
实时目标检测中击败YOLO家族?来看看百度飞桨的PaddleDetection团队提出的 RT-DETR究竟强在哪里。
众所周知,实时目标检测(Real-Time Object Detection)一直被YOLO系列检测器统治着,YOLO版本更是炒到了v8,前两天百度飞桨的PaddleDetection团队发布了一个名为 RT-DETR 的检测器,宣告其推翻了YOLO对实时检测领域统治。论文标题很直接:《DETRs Beat YOLOs on Real-time Object Detection》,直译就是 RT-DETR在实时目标检测中击败YOLO家族!

论文链接:https://arxiv.org/abs/2304.08069
代码链接:
https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/rtdetr
去年各大YOLO争相发布各显神通的场景才过去没多久,如今RT-DETR发布,精度速度都完胜所有YOLO模型,是否宣告了YOLO系列可以淘汰了?其实之前本人已经写过3篇文章介绍各个YOLO【从百度飞桨PaddleYOLO库看各个YOLO模型】(https://zhuanlan.zhihu.com/p/550057480),【YOLO内卷时期该如何选模型?】(https://zhuanlan.zhihu.com/p/566469003)和 【YOLOv8精度速度初探和对比总结】,如今还是想再结合 RT-DETR的论文代码,发表一下自己的一些浅见。
关于RT-DETR的设计:
结合PaddleDetection开源的代码来看,RT-DETR是基于先前DETR里精度最高的DINO检测模型去改的,但针对实时检测做了很多方面的改进,而作者团队正是先前PP-YOLOE和PP-YOLO论文的同一波人,完全可以起名为PP-DETR,可能是为了突出RT这个实时性的意思吧。
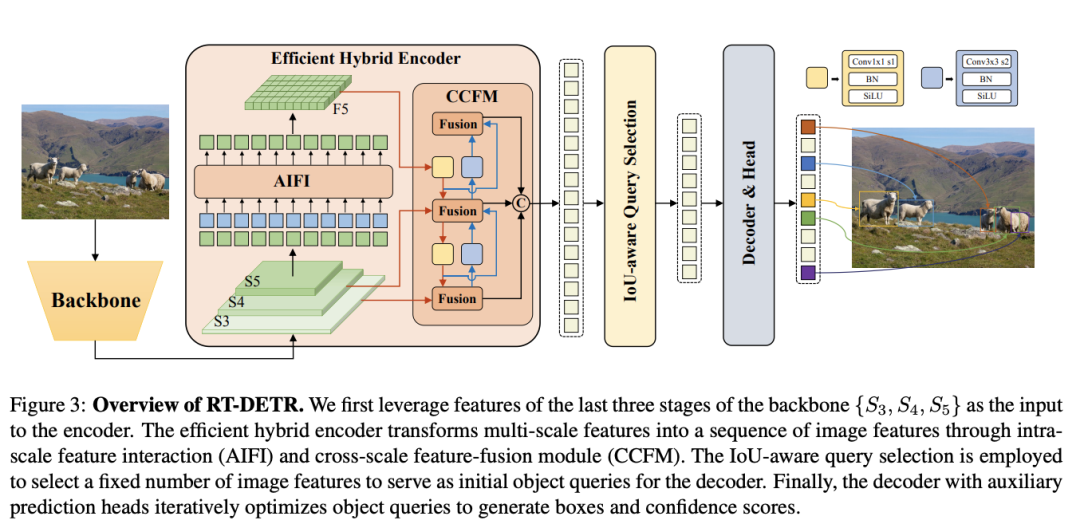
(1)Backbone: 采用了经典的ResNet和百度自研的HGNet-v2两种,backbone是可以Scaled,应该就是常见的s m l x分大中小几个版本,不过可能由于还要对比众多高精度的DETR系列所以只公布了HGNetv2的L和X两个版本,也分别对标经典的ResNet50和ResNet101,不同于DINO等DETR类检测器使用最后4个stage输出,RT-DETR为了提速只需要最后3个,这样也符合YOLO的风格;
(2) Neck: 起名为HybridEncoder,其实是相当于DETR中的Encoder,其也类似于经典检测模型模型常用的FPN,论文里分析了Encoder计算量是比较冗余的,作者解耦了基于Transformer的这种全局特征编码,设计了AIFI (尺度内特征交互)和 CCFM(跨尺度特征融合)结合的新的高效混合编码器也就是 Efficient Hybrid Encoder ,此外把encoder_layer层数由6减小到1层,并且由几个通道维度区分L和X两个版本,配合CCFM中RepBlock数量一起调节宽度深度实现Scaled RT-DETR;
(3)Transformer: 起名为RTDETRTransformer,基于DINO Transformer中的decoder改动的不多;
(4)Head和Loss: 和DINOHead基本一样,从RT-DETR的配置文件其实也可以看出neck+transformer+detr_head其实就是一整个Transformer,拆开写还是有点像YOLO类的风格。而训练加入了IoU-Aware的query selection,这个思路也是针对分类score和iou未必一致而设计的,改进后提供了更高质量(高分类分数和高IoU分数)的decoder特征;
(5)Reader和训练策略: Reader采用的是YOLO风格的简单640尺度,没有DETR类检测器复杂的多尺度resize,其实也就是原先他们PPYOLOE系列的reader,都是非常基础的数据增强,0均值1方差的NormalizeImage大概是为了节省部署时图片前处理的耗时,然后也没有用到别的YOLO惯用的mosaic等trick;训练策略和优化器,采用的是DETR类检测器常用的AdamW,毕竟模型主体还是DETR类的;
关于精度:
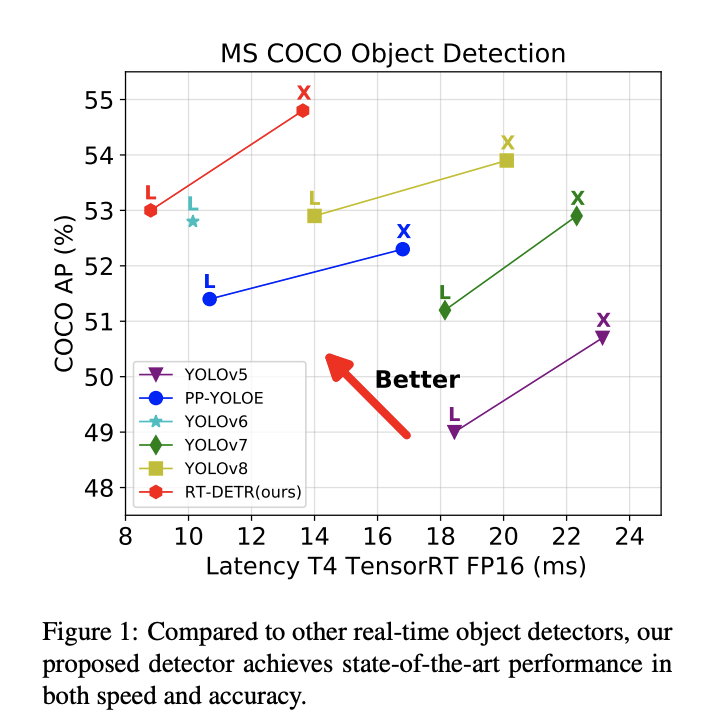
来看下RT-DETR和各大YOLO和DETR的精度对比:
(1)对比YOLO系列:
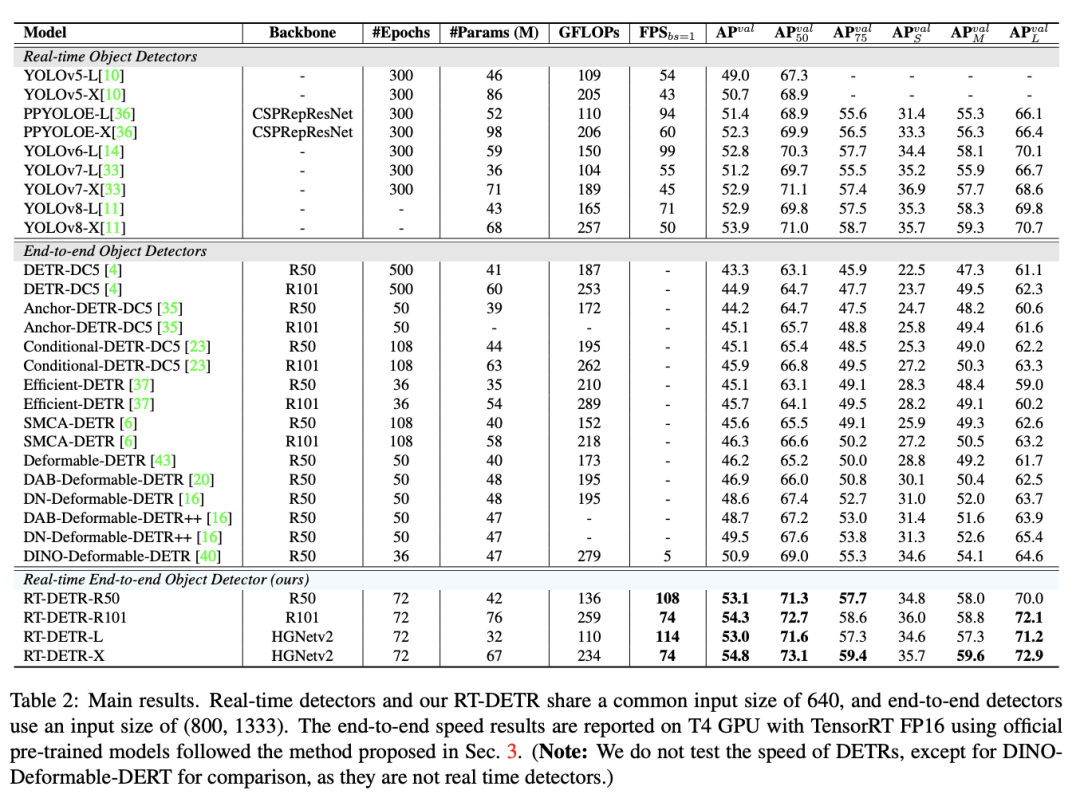
同级别下RT-DETR比所有的YOLO都更高,而且这还只是RT-DETR训练72个epoch的结果,先前精度最高的YOLOv8都是需要训500个epoch的,其他YOLO也基本都需要训300epoch,这个训练时间成本就不在一个级别了,对于训练资源有限的用户或项目是非常友好的。之前各大YOLO模型在COCO数据集上,同级别的L版本都还没有突破53 mAP的,X版本也没有突破54 mAP的,唯一例外的YOLO还是RT-DETR团队他们先前搞的PP-YOLOE+,借助objects365预训练只80epoch X版本就刷到了54.7 mAP,而蒸馏后的L版本更刷到了54.0 mAP,实在是太强了。此外RT-DETR的参数量FLOPs上也非常可观,换用HGNetv2后更优,虽然模型结构类似DETR但设计的这么轻巧还是很厉害了。
(2)对比DETR系列:
DETR类在COCO上常用的尺度都是800x1333,以往都是以Res50 backbone刷上45 mAP甚至50 mAP为目标,而RT-DETR在采用了YOLO风格的640x640尺度情况下,也不需要熬时长训几百个epoch 就能轻松突破50mAP,精度也远高于所有DETR类模型。此外值得注意的是,RT-DETR只需要300个queries,设置更大比如像DINO的900个肯定还会更高,但是应该会变慢很多意义不大。
关于速度:
来看下RT-DETR和各大YOLO和DETR的速度对比:
(1)对比YOLO系列:
首先纯模型也就是去NMS后的速度上,RT-DETR由于轻巧的设计也已经快于大部分YOLO,然后实际端到端应用的时候还是得需要加上NMS的...嗯等等,DETR类检测器压根就不需要NMS,所以一旦端到端使用,RT-DETR依然轻装上阵一路狂奔,而YOLO系列就需要带上NMS负重前行了,NMS参数设置的不好比如为了拉高recall就会严重拖慢YOLO系列端到端的整体速度。
(2)对比DETR系列:
其实结论是显而易见的,以往DETR几乎都是遵循着800x1333尺度去训和测,这个速度肯定会比640尺度慢很多,即使换到640尺度训和测,精度首先肯定会更低的多,而其原生设计庞大的参数量计算量也注定了会慢于轻巧设计的RT-DETR。RT-DETR的轻巧快速是encoder高效设计、通道数、encoder数、query数等方面全方位改良过的。
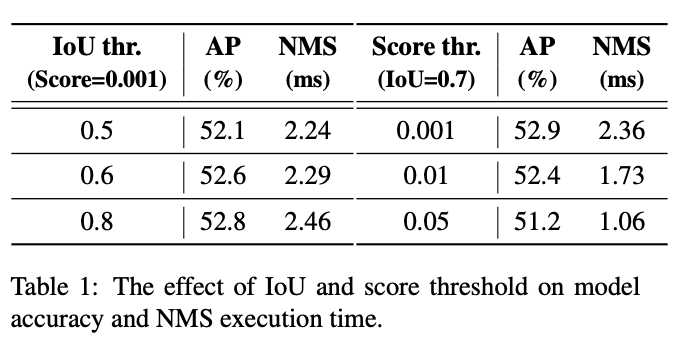
关于NMS的分析:
论文其实并没有一开始就介绍模型方法,而是通过NMS分析来引出主题。针对NMS的2个超参数得分阈值和IoU阈值,作者不仅分析了不同得分阈值过滤后的剩余预测框数,也分析了不同NMS超参数下精度和NMS执行时间,结论是NMS其实非常敏感,如果真的实际应用,不仅调参麻烦而且精度速度波动很大。以往YOLO论文中都会比一个纯模型去NMS后的速度FPS之类的,其实也很容易发现各大YOLO的NMS参数不一,而且真实应用的时候都得加上NMS才能出精确的检测框结果,所以端到端的FPS和论文公布的FPS(纯模型)不是一回事,明显会更慢的多,可以说是虚假的实时性。
此外一般做视频demo展示时,为了视频上实时出结果其实都会改成另一套NMS参数,最常见的操作就是改高得分阈值,比如原先eval精度时可能是0.001现在直接改大到0.25,强行过滤众多低分低质量的结果框,尤其在Anchor Based的方法如yolov5 yolov7这种一刀切会更加提速,以及还需要降低iou阈值以进一步加速。而DETR的机制从根本上去除了NMS这些烦恼,所以其实个人觉得去NMS这个点才是RT-DETR和YOLO系列比的最大优势,真正做到了端到端的实时性。
关于YOLO终结者的称号:
去年YOLO领域出现了一波百家争鸣的情况,各大公司组织纷纷出品自己的YOLO,名字里带个YOLO总会吸引一波热度,其中YOLOv7论文还中了CVPR2023,再到今年年初的YOLOv8也转为Anchor Free并且刷了500epoch,各种trick几乎快被吃干抹尽了,再做出有突破性的YOLO已经很难了,大家也都希望再出来一个终结性的模型,不要再一味往上叠加YOLO版本号了,不然YOLOv9甚至YOLOv100得卷到何时才到头呢?
此外,虽然各大YOLO都号称实时检测,但都只公布了去NMS后的FPS,所以我们实际端到端出检测结果时就最常发现的一个问题,怎么自己实际测的时候FPS都没有论文里写的这么高? 甚至去掉NMS后测还是稍慢。那是因为端到端测的时候NMS在捣乱,去NMS的测速虽然准确公平,但毕竟不是端到端实际应用,论文中的FPS数据都可以说是实时性的假象,实际应用时不能忽略NMS的耗时。
YOLOv8出来的时候我也在想那下一个出来的YOLO名字该叫什么呢?v9吗还是xx-YOLO,效果能终结下YOLO领域吗?
而RT-DETR我觉得是算得上一个有终结意义的代表模型,因为它的设计不再是以往基于YOLO去小修小改,而是真正发现并解决了YOLO在端到端实时检测中的最大不足--NMS。其实先前把YOLO和Transformer这两个流量方向结合着做模型的工作也有一部分,比如某个YOLO的FPN Head加几层Transformer之类的,还能做毕业设计和水个论文,其实都更像是为了加模块刷点而去改进,这种基于YOLO去小修小改,其实都没改变YOLO端到端上实时性差的本质问题,而且大都也是牺牲参数速度换点精度的做法,并不可取。
而这个RT-DETR就换了种思路基于DETR去改进,同时重点是做实时检测去推广,直接对标对象是YOLO而不是以往的轻量级的快速的DETR,将DETR去NMS的思路真正应用到实时检测领域里,我觉得是RT-DETR从思路到设计都是比较惊艳的。
至于说RT-DETR是不是真正的YOLO终结者,如果只从精度速度来看那肯定也算是了,但更出彩的是它的设计理念。正如YOLOX第一个提出AnchorFree的YOLO,思路上的突破往往更让人记住,RT-DETR正是第一个提出以DETR思路去解决甚至推翻YOLO的实时检测模型,称之为“YOLO终结者”并不为过。
不过CNN和YOLO系列以往的技术都已经发展的非常成熟了,使用模型也不止是看精度速度,根据自己的实际需求和条件去选择才是最优的,CNN和YOLO系列应该还会有较长一段生存空间,但Transformer的大一统可能也快了。、
『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 2888
2888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









