






作者 | ahrs365 编辑 | 哎嗨人生
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
用了15天时间,做了一个可以回放停车场数据集,以及将数据集内的车辆,行人,车位,拓扑路线转化成决策规划可用的语义地图的形式。可以再这个仿真环境用开发自己的决策规划c++代码。
在自动驾驶中,按照场景,可以分成行车和泊车两种,行车一般指的是在道路上,高架上,城区里等有明显车道线,路标,以及红绿灯的场景下进行无人驾驶。而泊车特指在地面停车场或者地下车库里的自动驾驶。当然,现在常说的行泊一体,就是把这个种场景用的的算法进行统一。对于行车场景,有很多可选的开源项目和数据集,可以用来验证自己的算法,但是对于泊车场景,这类数据集就很少了。如果想要验证自己的泊车算法,就比较难了,尤其是停车场里有行人,有车辆,自行车等等,而且没有明显的车道线,没有数据集,就无法全面验证自己的算法。
那天,我发现了一个用于泊车的数据集,就想着,把这个数据集拿来做一个仿真项目,可以用来验证自己的代课泊车算法。之前文章介绍过这个数据集:
停车场环境,基于CNN和Transformer的轨迹预测模型ParkPredict+
第一步:解析数据集的格式
数据集地址:https://sites.google.com/berkeley.edu/dlp-dataset
作者提供的数据集是json格式的,我就一段一段复制下来,让GPT帮我解释,解释完我理解了,它也记住了这些格式,后续可以让它给我写数据回放的代码。
这里耗费了我很多时间,也尝试了不同的思路,试了将python代码嵌入到c++工程中的方式,遇到问题,放弃了。也尝试了用python脚本播放数据集,用c++工程接收,两个线程之间进行通讯的方式,太复杂,也放弃了。最后,决定用c++重写了数据回放的代码。这个开源项目险些在这一步就放弃了,还好在GPT的帮助下,完成了这一步的工作。
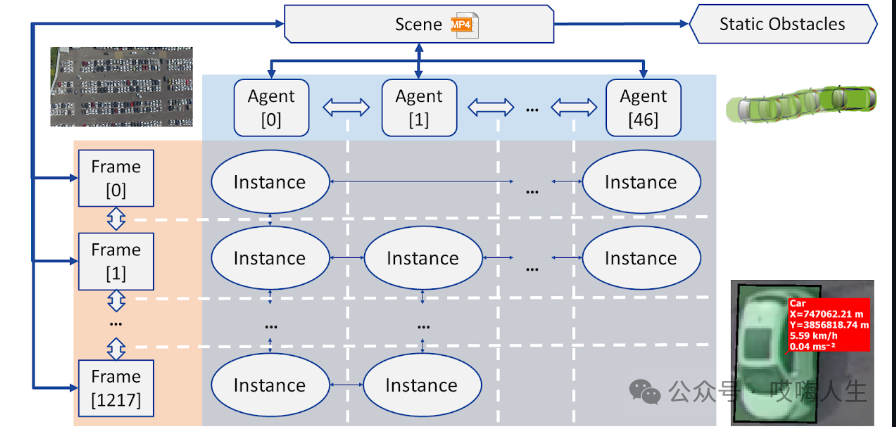
数据集的格式如下:
组件定义
场景 (Scene):代表一个连续的视频录制。包含指向该录制中的所有帧、代理和障碍物的指针。
帧 (Frame):录制中的一个离散时间步。包含在这个时间步可见的所有实例列表。指向前一帧和后一帧。
代理 (Agent):在场景中移动的对象。包含对象的尺寸、类型和轨迹(由实例列表构成)。
实例 (Instance):代理在某个时间步的状态。包括位置、方向、速度和加速度。指向代理轨迹中的前一个和后一个实例。
障碍物 (Obstacle):在录制中从未移动过的车辆。
数据集统计
场景数:30
帧数:317,873
代理数:5,188
实例数:15,383,737
关系
场景 (Scene):包含多个帧 (Frame),包含多个代理 (Agent),包含多个障碍物 (Obstacle)
帧 (Frame):包含在这个时间步可见的实例 (Instance),有前一帧和后一帧的关系
代理 (Agent):包含在不同时间步的多个实例 (Instance),每个实例表示代理在某个时间步的状态
实例 (Instance):关联代理 (Agent),有前一个实例和后一个实例的关系
第二步:编写数据回放的代码
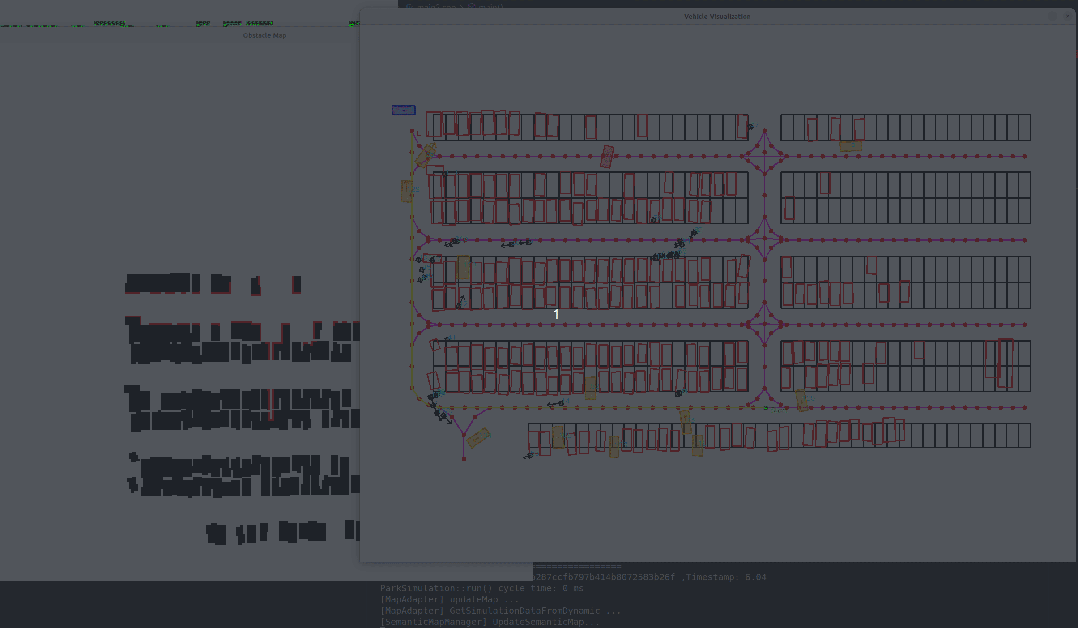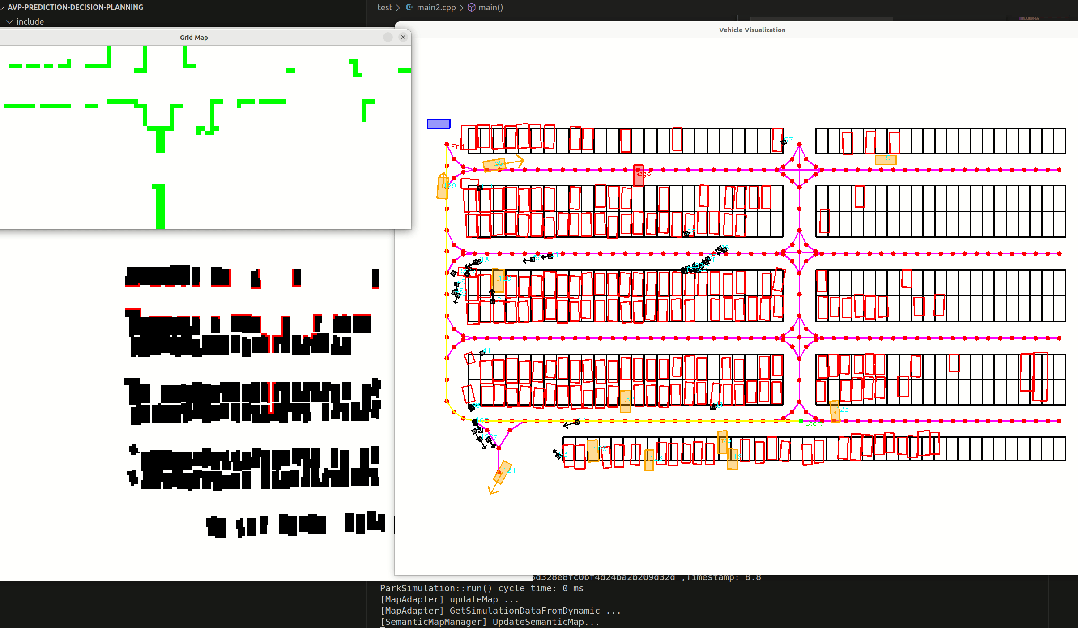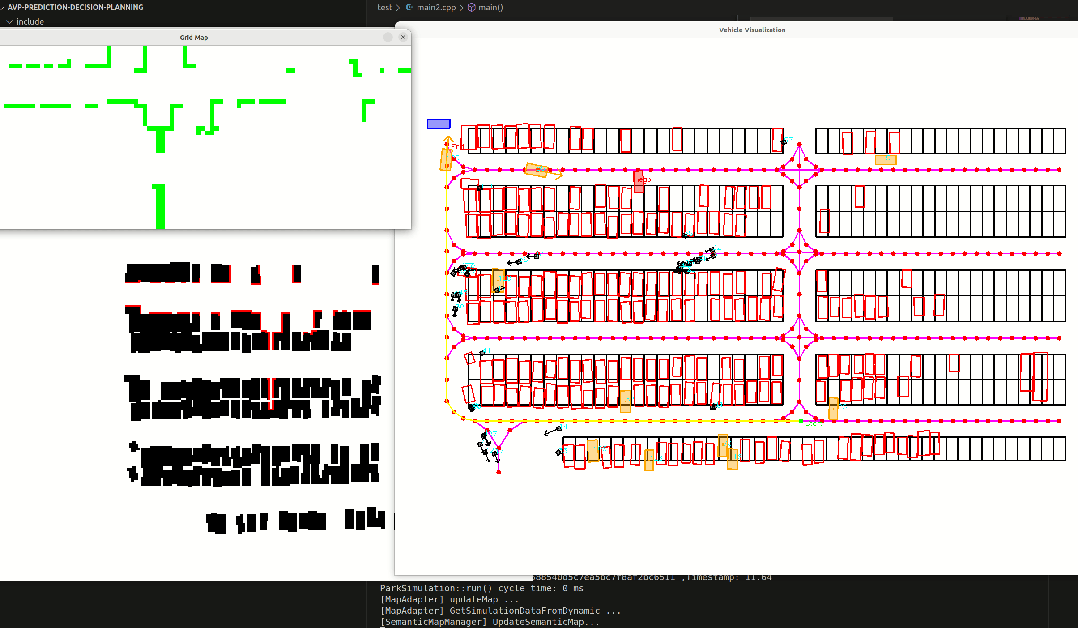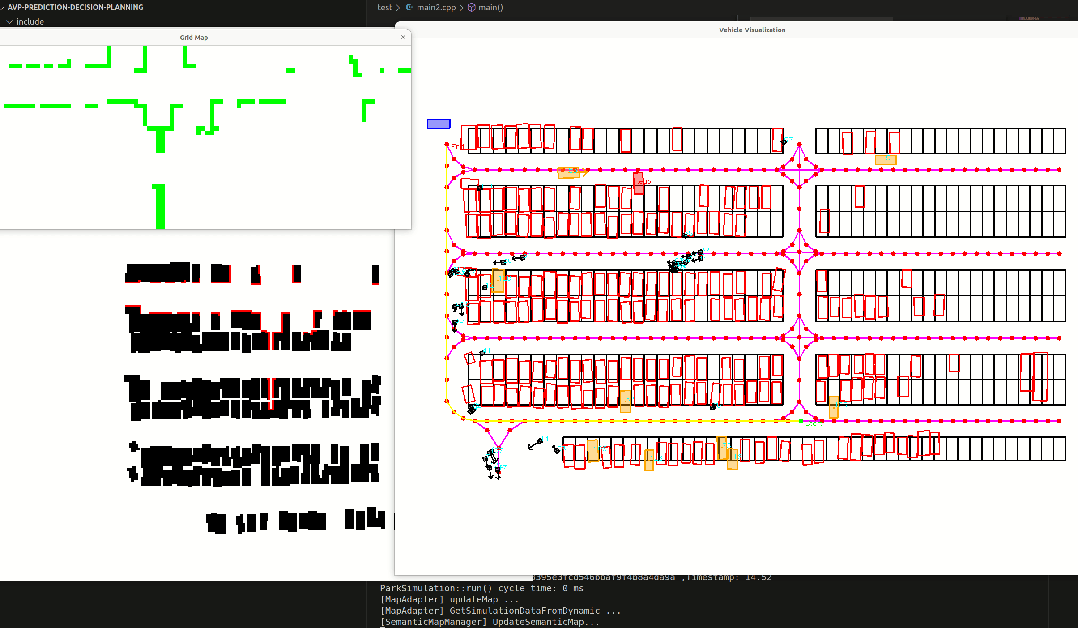
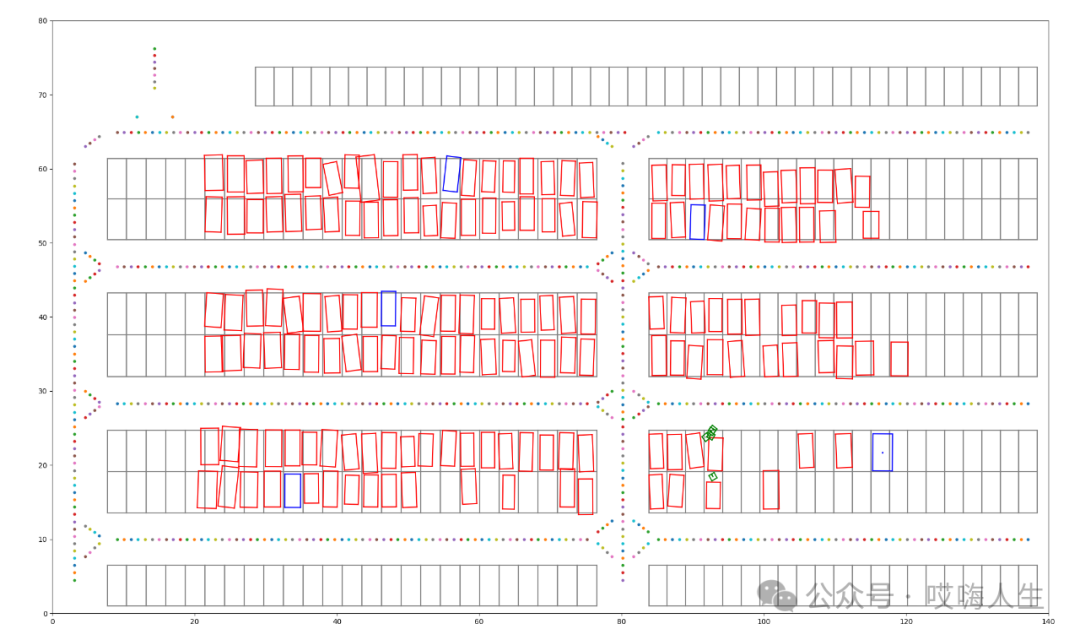
原作者有回放数据的开源代码,但是是python写的,我需要用c++去实现一下。其实也不算是我写的,我需要设计一个大体的框架,然后让gpt去写。因为我上一步中,已经把数据集的格式给gpt了,所以在它可以很快就写出数据回放的代码。其实也不快,这一步都花费了一周时间,它可以不一个函数写的很好,但是你让它给你写完整的一个类,它很有可能会乱写。经过耐心的沟通,和反复的修改,终于完成了数据回放的代码,效果如下,可以逐帧播放数据集,显示出了拓扑路线,停车位,静态车,动态车,行人所有的元素。
数据回放的代码完成后,我又在可视化上花费了好多天,尝试了各种方式,因为考虑的太多了,想着以后可能需要界面交互,比如在界面上选择一个车位作为目标车位。所以我想着用QT,用Dear Imgui,用FLTK等等,后来忽然发觉,我陷入了美化可视化界面的泥潭中无法自拔,一周时间都过去了。最后想了个方法,做了一个可视化类,做成单例模式,用opencv可视化,这样,在工程中的任何地方,都可以插入可视化的代码,方便前期的开发和调试。等到后期,也可以方便的把可视化代码移除,非常解耦。
回放的主代码如下:
void ParkSimulation::run() {
loadData();
findStartFrame();
// common::GridMapMetaInfo map_info(280, 160, 0.5);
common::GridMapMetaInfo map_info(300, 300, 0.5);
semantic_map_manager::AgentConfigInfo config;
config.obstacle_map_meta_info = map_info;
config.surrounding_search_radius = 150;
semantic_map_manager::SemanticMapManager semantic_map_manager;
semantic_map_manager.setConfig(config);
semantic_map_manager::MapAdapter mapAdapter(&semantic_map_manager);
planning::EudmServer planner;
while (!currentFrameToken.empty()) {
auto start_time = std::chrono::steady_clock::now();
auto it = frames.find(currentFrameToken);
if (it == frames.end()) {
break;
}
const auto& frame = it->second;
env->loadFrame(frame);
// 输出当前帧的信息
std::cout << "\n=============================================\n";
std::cout << "Current Frame: " << frame.frame_token
<< " ,Timestamp: " << frame.timestamp << std::endl;
// 移动到下一帧
currentFrameToken = frame.next;
auto end_time = std::chrono::steady_clock::now();
std::cout << "ParkSimulation::run() cycle time: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(
end_time - start_time)
.count()
<< " ms" << std::endl;
mapAdapter.run(env);
planner.run(&semantic_map_manager);
}
std::cout << "Simulation finished." << std::endl;
// 清理环境对象
delete env;
}第三步:构建语义地图
EPSILON是港科大开源的一个非常优秀的自动驾驶开源系统,这里基于Epsilon的语义地图模块,进行了修改和适配,用于提供管理栅格地图,碰撞检查等功能。这里的工作量主要在于,数据读取和回放模块,存储了各种元素,需要将这些元素转换成语义地图接收的格式。
一些转换函数如下:
void GetSimulationDataFromStatic(Environment* env);
void GetSimulationDataFromDynamic(Environment* env);
void GetPolygonFromSimulationData(const StaticObstacle& obs,
common::PolygonObstacle* poly);
void GetVehicleFromSimulationData(const DynamicObstacle& obs,
common::Vehicle* vehicle);
void GetLanRawFromRoute(const std::vector<std::pair<double, double>>& route,
common::LaneRaw* p_lane);
common::WaypointsGraph GetGraphFromSimulationData(
const std::unordered_map<std::string, Route>& routes);
void GetParkingSpotsFromSimulationData(
std::unordered_map<std::string, std::vector<ParkingSpot>>& sim_spots,
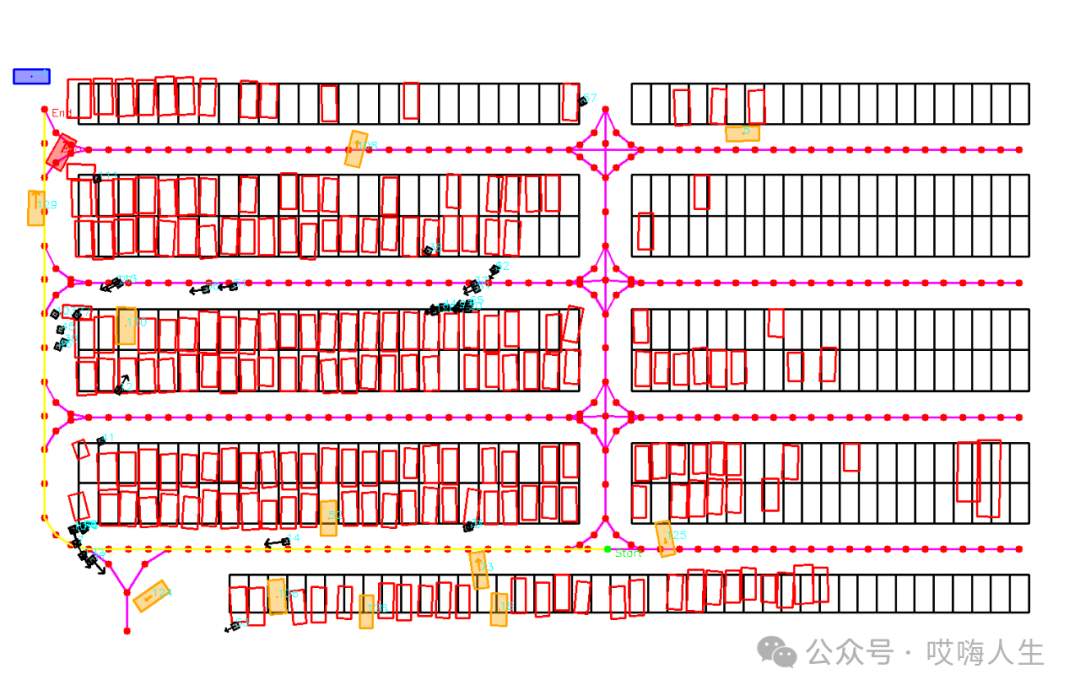
common::ParkingSpots* parking_spots);完成数据转换后,我需要将这些转换后的元素进行可视化,确保转换的没有问题。结果如下,分别时模拟的激光雷达扫到的障碍物,栅格地图,停车场地图以及车辆和行人和拓扑路线。
绿色为模拟的激光雷达扫到的障碍物边界。

黑色代表停车车位里的车辆,白色是可通行的区域

整个停车场如下,包含了拓扑路线,黄色路线为指定起点和终点,在拓扑图上搜索得到的路径,黑色方块是行人,橙色是动态车辆,黑色框代表车位。
第四步:开始开发预测、决策、规划模块
有了这个仿真框架,就可以开发代客泊车的相关算法了,仿真里提供了各种动态车辆和行人,也提供了车位,对于预测模块,可以用来对车辆进行意图预测,预测它是要直行还是倒车入库。对于决策模块,可以在这种高动态场景下,验证决策算法的合理性。
工程的main函数如下,非常简洁:
int main() {
// 创建对象
park::ParkSimulation simulation(
"./data/DJI_0012_scene.json", "./data/DJI_0012_agents.json",
"./data/DJI_0012_frames.json", "./data/DJI_0012_instances.json",
"./data/DJI_0012_obstacles.json", "./data/parking_map.yml", 0,
1200 // startFrameIndex, endFrameIndex
);
simulation.run();
return 0;
}预测和决策和规划模块,这里还没开始,敬请不期待,烂尾警告。
感谢开源项目EPSILON,感谢开源项目ParkPredict+。
题外话1
目前整个项目,我自己动手写的代码,占得比例非常少,我主要是设计整体的框架,设计具体类的功能,至于具体的代码,都是GPT写的。目前GPT4还会胡诌,需要我监督和不断的交流改错,那如果以后GPT5,6,7,8进化了,不需要我监督和设计框架,也就不需要我写代码了。以后,会写代码这个技能,会不会都不算一个技能了?
记得几年前,用到opencv可视化的时候,被它的坐标和一些可视化转换,搞得头昏脑涨,花了几天时间才学会怎么用,现在呢,我一个描述,gpt就给我写出来了,我不理解原理,它可以给我讲明白。
转行到现在,写了几年代码了,从一开始的恐惧代码,到后来不再害怕写代码,到后来体会到了通过写代码去驱动机器人完成一些功能的快乐,再到现在,一句话就能得到可用的代码,甚至都不用检查这段代码。
题外话2
以前做测试的时候,觉得工作没前途,转行做机器人,后来觉得自动驾驶里用的才是前沿的技术,就转行去做自动驾驶了。我自认为自己非常热爱学习,学习动力很足,自动驾驶行业技术迭代很快,所有很适合我。但是随着行业的发展,我感觉有点理解不了了。总是觉得,这行业不是很踏实,总是在炫技,炫技的目的不是为了提升用户体验,而是为了让资本看到,看吧,我这新技术无敌了,上限非常高,给我们投资吧。如果有那一天,靠着显卡和数据,就可以让自动驾驶成为一个成熟可用的产品,程序员会不会变成工业革命时候被迫下岗的纺织工人。
感觉写代码逐渐没有乐趣了,当你发挥自己的创意,解决了一个问题,你会被鄙视,因为你只是写if else解决了亿万个corner case中的一个而已。这些case,显卡和数据集也可以解决。
如果人人都能写代码了,那写代码这个技能,就无有用了。如果端到端模型,如果端到端的方法成为了自动驾驶的最终解,那也不用算法工程师了,都去踩自行车发电吧。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









