




2024年,随着Sora技术的璀璨登场,我们见证了智能创作的惊人突破,它不仅颠覆了传统影视制作,更在人工智能领域掀起了一场深刻的变革。

当埃隆·马斯克对Sora技术赞不绝口,称赞其为“人类愿赌服输”的创新时,我们就知道,这不仅仅是技术上的飞跃,更是对未来智能世界的一次大胆预言。从美国到中国,从一级市场到三级市场,生成式模型的热潮像涟漪一样扩散至全球每一个角落,激起了无数创业者和科技爱好者的无限遐想。
然而Sora模型并未开源,高昂的算力训练成本也让众多科研学者和开发者望而却步。尤洋教授在人工智能技术刚兴起时即敏锐关注到人工智能的算力瓶颈问题,并在2021年领导潞晨科技团队发布面向大模型的Colossal-AI深度学习加速系统,使得AI训练能够扩展到数千个处理器而不损失准确性,为大模型的训练、微调和推理任务提供了高效低成本的解决方案。工具一经开源便引爆全球关注热点,成为可扩展人工智能领域发展最快的开源项目之一。潞晨科技进一步推出了以Colossal-AI系统为核心的潞晨云平台,预置丰富的大模型镜像,以极致性价比和简捷的操作,为科研人员和大模型开发者提供了快速接入高端算力的途径。潞晨云平台实现了大模型计算成本的大幅度压缩,工具一经开放便引爆全球关注热点。在算力极度稀缺的背景下,这项突破对人工智能领域带来了深刻革新。
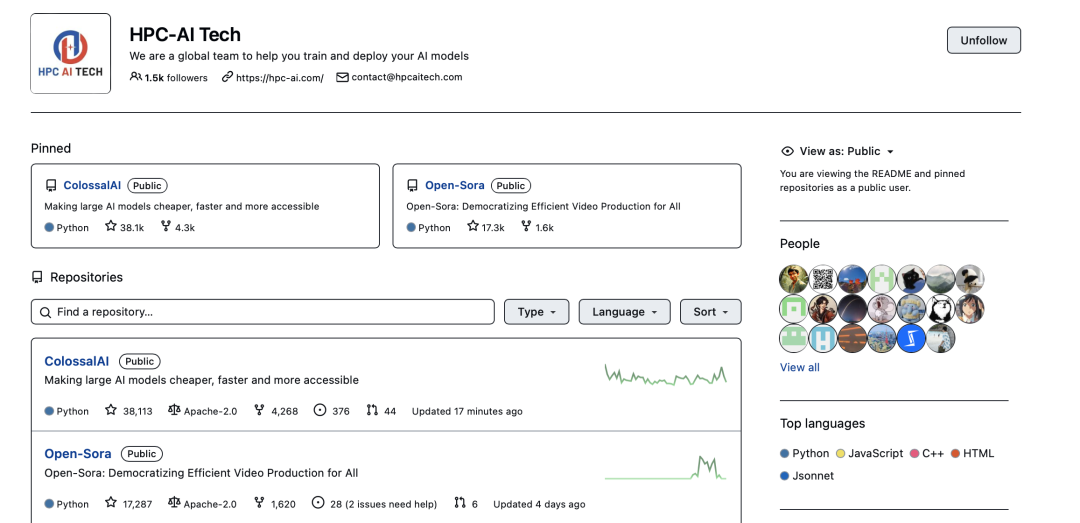

潞晨科技推出的潞晨云平台,以其算力选择的广泛性、界面的简洁易用性、以及预设的ColossalAI相关镜像,为科研人员和大模型开发者提供了一个快速接入高端算力的新途径。它让每一位创作者都能够轻松地在智能创作的海洋中遨游。
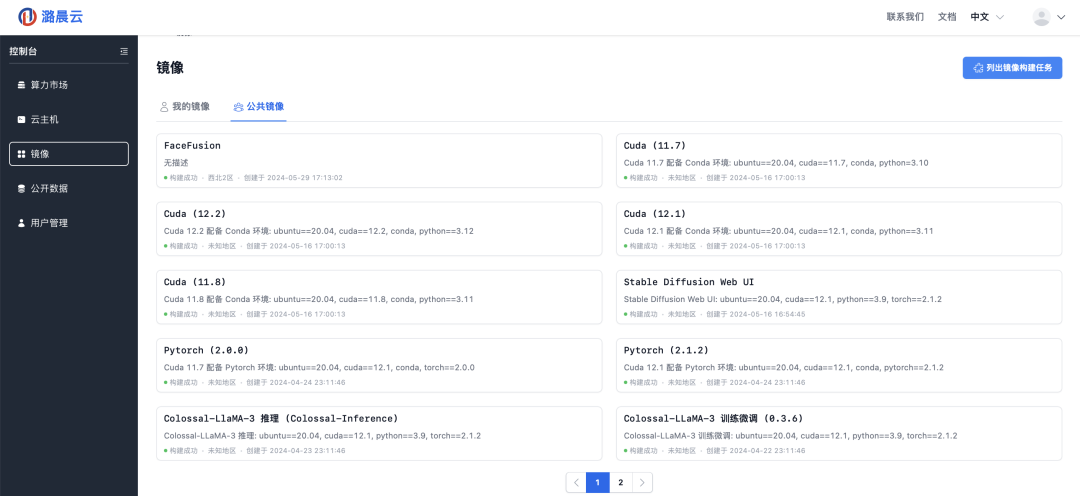
无论是视频生成、图像制作还是文本生成创作,都变得触手可及。
 ▲用户使用Open-Sora生成的视频Demo
▲用户使用Open-Sora生成的视频Demo
想跑起来Open-Sora等AI任务,还需要有GPU等算力支持。目前主流的AI云主机有AWS、AutoDL、阿里云等。但GPU资源不仅昂贵稀缺,供应商普遍还要求使用者必须预先进行高额投入,按年或提前数个月预付定金。潞晨云不仅提供了便捷易用的AI解决方案,还为力求为广大AI开发者和其他提供了随开随用的廉价算力:

H800:最适合处理大规模模型(数十亿到上百亿参数),具有强大的分布式计算和数据处理能力。
>>H800配置:NVLink:GPU:8 x H800-80G SXM NVLink CPU:2 x 8470-52c 内存:32 x 64G 集群网络:8 x 400G RoCE 系统盘:2x960G NVME 本地存储:4*7.68T NVME
A800:适合大规模深度学习模型的训练和高性能计算任务,特别是在需要高内存和高带宽的情况下。
>>A80配置:CPU:2*Intel Xeon Platinum 8358P @2.60GHz 32核 内存:1024GB 硬盘:2*SSD 960G+ 1*7.68T NVME SSD 网络:4*200Gbps IB计算+2*200Gbps IB存储预留+2*10Gbps Eth NIC GPU:8*Nvidia A800 80G SXM + Nvlink
4090:适合中型到大型模型的训练和推理,适合作为高性能AI开发工作站。
>>4090配置:CPU:Intel 8352V*2 内存:DDR4 3200 64G*16 系统盘:480G SATA SSD*2 raid1 数据盘:3.84T NVME U.2*1 GPU:4090 涡轮版*8 网卡:25G 光口网卡(不含模块) * 2 raid 卡:raid 卡*1,支持 RAID 0,1,5,6,10,50 和 60,带缓存 电源:冗余后电源 4000W 以上,支持 热插拔 管理卡:远程 BMC 管理
潞晨云网址:https://cloud.luchentech.com

●使用FaceFusion等工具创作AI换脸的数字人短视频 @Jack-Cui博主
现在 AI 数字人很火,各种数字人带货通过提前录制含有特定动作的视频,然后利用 AI 换脸算法,驱动人脸的面部表情和动作完成创作。UP主分享了自己使用
FaceFusion开源工具在潞晨云平台的4090显卡完成的视频项目。并将其制作成打包成一键启动懒人包,可以使用云平台一键启动镜像进行计算。
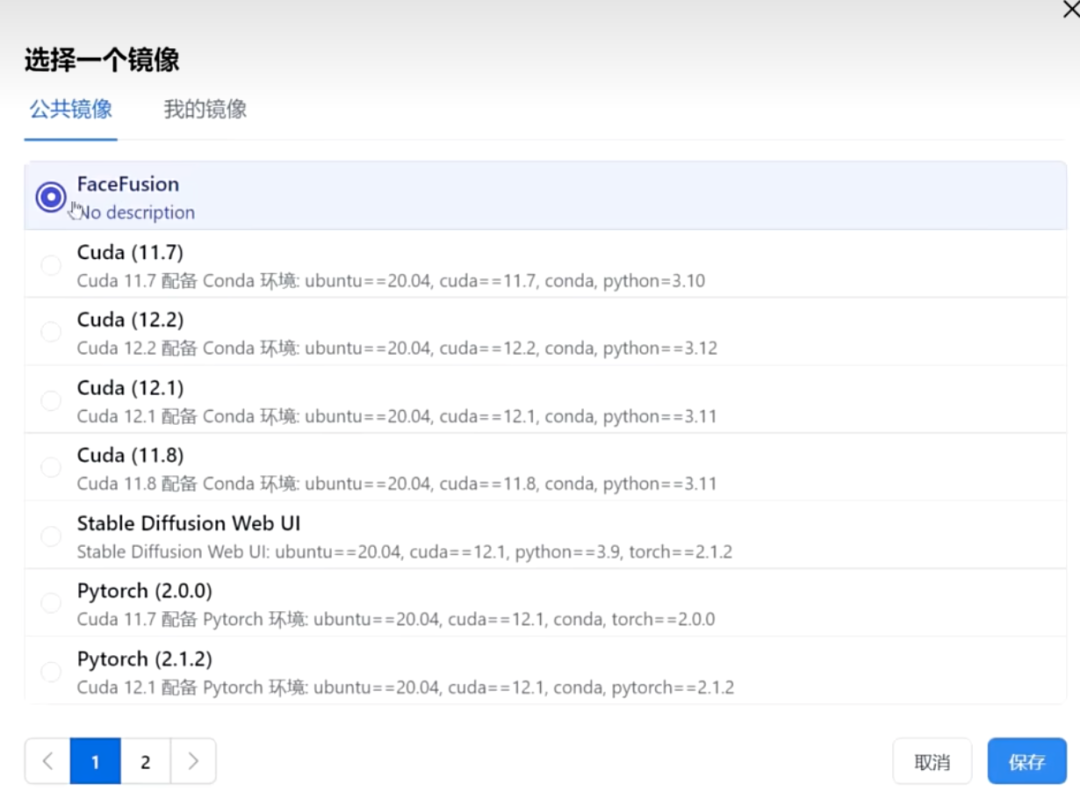
UP主说:
“选择创建一个新的云主机,选择4090 显卡一般就够用了。4090 性价比很高,目前每小时只需要 1.59 元。当然这里也有性能更强 80GB 显存的H800 和 A800。镜像这里填写UP主为大家准备好的镜像,点击创建即可。祝大家玩得开心。”
●使用Stable Diffusion和Open-Sora等工具创作绘本故事 @Crossin的编程教室
Crossin的编程教室也使用潞晨云创作和投稿了一个绘本故事短视频。
1)脚本:首先是创作故事脚本。UP主的想法是用Meta前阵子刚刚发布的开源大语言模型Llama 3帮忙完成。作者创作了一个四格卡通连环画的剧本,主角是一只想学做饭的猫,并让模型提供配图的中文说明和英文提示词。
curl -fsSL https://ollama.com/install.sh | sh
ollama serve
ollama run llama32)绘图:有了剧本和提示词,作者接下来开始绘制插画。潞晨云默认提供了Stable Diffusion WebUI的镜像,选择此镜像创建主机后(建议选择1卡H800机器),直接启动网页版的StableDiffusion。把llama3生成的提示词贴进去稍作修改,设定下出图的数量,就能得到与剧情配套的插图。然后UP主尝试使用了潞晨云提供的提供了OpenSora的镜像进一步将插图变为动态内容。
cd /root/stable-diffusion-webuibash webui.sh -f
sh -CNg -L 本地端口:127.0.0.1:7860 root@云主机地址 -p 端口号3)配音:最后,UP主通过语音合成开源工具包Coqui-TTS给故事只做了一个朗读旁白。通过pip命令安装,支持包括中文在内的多种语言。用 tts 命令把 llama3 生成的配图说明转成语音,再同前面生成的视频整合到一起。
pip install TTS
tts --text "需要转换为语音的文字内容" --model_name "tts_models/zh-CN/baker/tacotron2-DDC-GST" --out_path speech.wav4)最终的效果图:

UP主说:
“这个演示中,我用的都是基础模型和默认配置,大家可以在此基础上进一步微调和优化。虽然这几样功能,市面上都有现成产品可以实现。但对于学习AI的人来说,是要成为AI的产生者而不是消费者,所以还是得靠自己动手部署和开发。这种情况下,尤其对学生党来说,云服务的性价比就很高了。假设只有3000块的预算,买台带4090显卡的电脑就别想了,但在潞晨云上,4090的云主机按2块钱一小时,平均每天使用4小时来算,就能用上375天了。而且还能根据你的需求快速升级和扩容,这点上比自己的电脑还要方便。”

随着潞晨科技的这一创新步伐,我们正站在一个新时代的门槛上。这是一个由人工智能驱动的创作时代,一个充满无限可能的智能未来。潞晨科技不仅为我们打开了这扇门,更为我们展示了一个全新的创作世界。
特别活动
◆【百万补贴】优质线上算力资源百万补贴等你来薅,随开随用。
◆【企业认证】企业用户参与潞晨云企业认证可得500元代金券。
◆【分享有礼】:用户在社交媒体和专业论坛(如知乎、小红书、微博、优快云等)上分享使用体验,有效分享一次可得100元代金券。
◆【创作激励】:在平台分享AI应用镜像等,可根据后续平台用户的调用时长,获得现金奖励。
◆【用户社群】:不定时发放特价资源、代金券等优惠活动。
👇点击“阅读原文”,立刻薅羊毛

















 4071
4071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









