



作者 | ahrs365 编辑 | 哎嗨人生
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
1.特斯拉礼让行人并看懂行人手势
在下图中,行人速度比较快,特斯拉将其横穿马路的意图预测的很准确,并且做出了减速让行的决策。
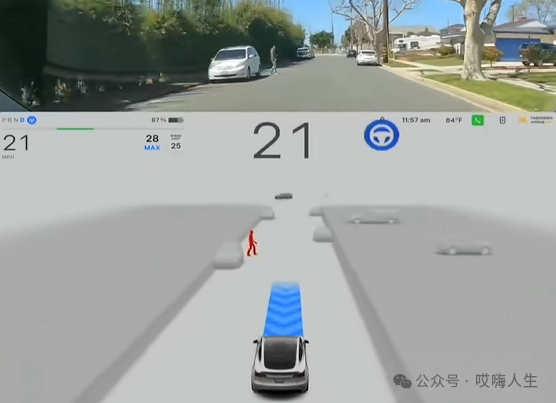
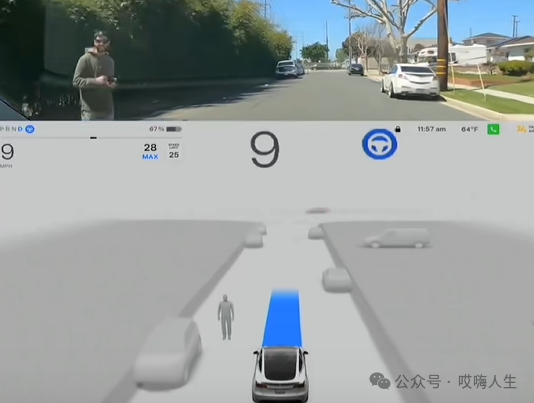
行人停下脚步以后,可以看到,渲染的行人变成了迎面走来的姿态。(当然,这个是渲染的行人,算法里真正拿到的行人意图可能与它不一致)。特斯拉做出了继续等待行人的决策。
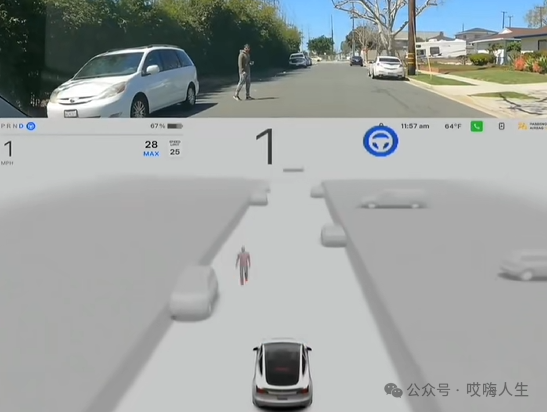
随后,行人挥手示意车辆通过,特斯拉做出了相应的决策,输出了轨迹,并加速离开。
2.自动驾驶中关于行人的决策
在自动驾驶中,高动态的障碍比如车辆和行人,自车需要与它们进行交互甚至博弈。对于车辆的行驶意图,它受到路沿、黄线、车辆运动学等等众多的约束,并且还有转向灯、刹车灯、倒车灯等信号提示,对于这类障碍物的意图预测,是比较准确的。但是对于行人的意图预测就很难了。
这个场景就是一个典型的自车与横穿行人交互的场景,按照传统的方法,也可以实现。首先是感知模块检查到动态行人,然后预测模块预测出行人横穿的意图,接下来,决策模块做出礼让行人的决策(比如在车前方加上停止线),最后规划模块优化出轨迹。那特斯拉基于端到端的方法,可能就没有这么多模块了,直接拿数据去驱动,只要训练的数据里有这种场景,它就能处理。
如果用传统的方法,怎么实现在行人挥手后,加速离开呢。这个好说,在预测模块中,增加人类手势识别的功能,将识别到的手势,给到决策模块,决策模块再根据这个场景,手写一些规则,如果满足这些规则,比如
if 行人速度为零 && 行人挥手 && 行人与自车一定距离 && 其他
决策-->加速绕行
else
停车等待如果用端到端的方法,无论是完全的端到端,还是类似于UniAD那种分成几个模块端到端的,通过大量的训练后,自动驾驶车辆在看到这个场景时,就会做出相应的决策和行为。
大部分场景,基于数据驱动的方式能做的,手写规则也能做,只是手写规则毕竟是人脑想出来的,一旦规则变得越来越多,各种规则之间相互影响,就很难再增加新的规则了。而基于数据驱动的方式,数据集可以一直加,模型可以一直训练。
3.手势识别的方法
本文重点还是记录一下手势识别的方法,通过这个来进一步了解机器学习的相关知识。重点学习基于视觉的手势识别。
3.1 基于雷达的手势识别
这个比较有名的是goolge的Soli项目,Soli雷达是由谷歌和英飞凌合作,专门为近距离感知任务研发的一款60GHz毫米波雷达产品。将各个特征沿着多普勒维连接在一起,利用3x3卷积提取运动信息。提取到的特征被送入LSTM模型进行分类预测,时间序列长度被设置为12帧。

算法就是CNN+LSTM。利用8层的CNN进行特征提取,利用LSTM对CNN提取的特征进行时序特征的提取和手势分类。
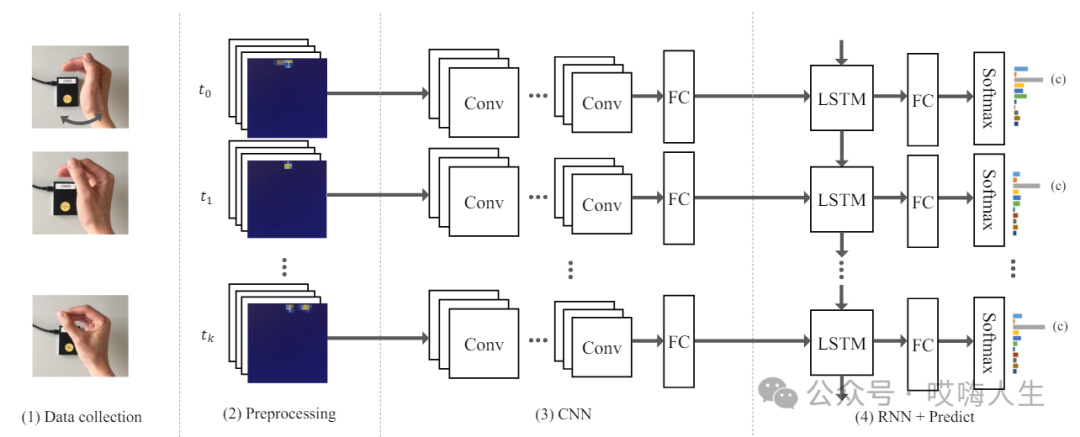
可能是由于手势定义过于精细,雷达精度达不到,最终这个手势识别的功能没有完整的应用到google手机上。不过CNN+LSTM的套路,是值得学习的,之后有时间我会实践一下,看下效果。
3.2 基于视觉的手势识别
opencv,CNN都可以做手势识别,本文重点记录一下google的开源框架MediaPipe,可以方便的在安卓,web,嵌入式设备中部署使用。
论文:https://arxiv.org/pdf/2111.00038
项目:https://ai.google.dev/edge/mediapipe/framework?hl=zh-cn
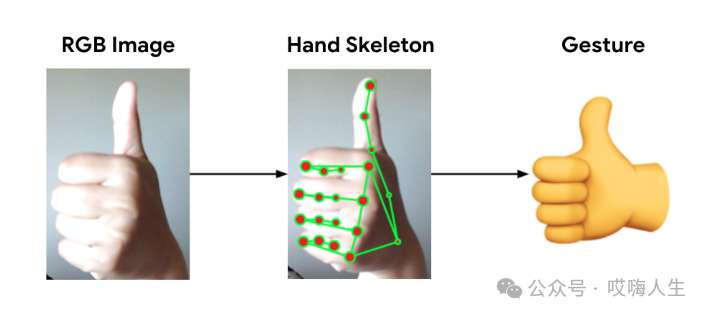
下边是实践代码,用opencv和MediaPipe实现的手部检测,只涉及手部追踪,下一次再学习手势分类。
需要安装:
1. 下载安装python
2. 下载安装vscode(其他ide也可以)
3. pip install opencv-python
4. pip install mediapipeimport cv2
import mediapipe as mp
import time
cap = cv2.VideoCapture(0)
mpHands = mp.solutions.hands
hands = mpHands.Hands()
mpDraw = mp.solutions.drawing_utils
handLmsStyle = mpDraw.DrawingSpec(color=(0,0,255), thickness=5)
handConStyle = mpDraw.DrawingSpec(color=(0,255,0), thickness =10)
pTime = 0
cTime = 0
while True:
ret, img = cap.read()
if ret:
imgRGB = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
result = hands.process(imgRGB)
# print(result.multi_hand_landmarks)
imgHeight = img.shape[0]
imgWidth = img.shape[1]
if result.multi_hand_landmarks:
for handLms in result.multi_hand_landmarks:
mpDraw.draw_landmarks(img,handLms,mpHands.HAND_CONNECTIONS, handLmsStyle,handConStyle)
for i, lm in enumerate(handLms.landmark):
xPos = int(lm.x * imgWidth)
yPos = int(lm.y * imgHeight)
cv2.putText(img,str(i),(xPos-25,yPos+5),cv2.FONT_HERSHEY_SIMPLEX,0.4,(0,0,255),2)
print(i,xPos, yPos)
cTime = time.time()
fps = 1/ (cTime-pTime)
pTime = cTime
cv2.putText(img,f"FPS : {int(fps)}",(30,50), cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0),3)
cv2.imshow('img',img)
if cv2.waitKey(1) == ord('q'):
break下边是代码参考的视频,感兴趣的可以看一看:
https://www.youtube.com/watch?v=x4eeX7WJIuA
https://www.bilibili.com/video/BV1GR4y1W7KS/?spm_id_from=333.337.search-card.all.click&vd_source=c22e088abc8e5f41edd4d4ebc99ecc48投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 5560
5560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









