



作者 | 一介书生
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
目前面临的问题
随着自动驾驶技术的发展,无论是基于BEV Transformer 的自动驾驶技术,还是另大家期待的端到端自动驾驶技术,目前来看,大家量产需要面临的都有很大量的badcase 去解决。比如端到端的自动驾驶的仿真的问题,在必然各种各种样长尾corner case 的产生问题。这些都将成为靠数据驱动的自动驾驶技术的瓶颈。
我们曾简单的讨论过世界模型是不是会对自动驾驶标注带来一些影响。
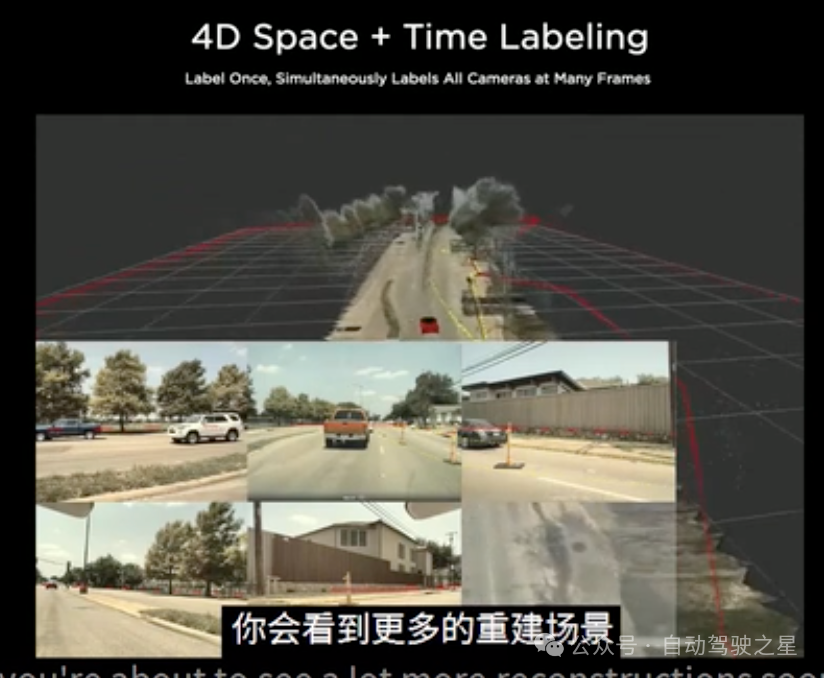
图1: Tesla 4D 重建数据
如图1: 所示,Tesla 完全有能力把一个城市的道路场景给重建出来,这也是为什么大家体验了Tesla fsdv12 端到端自动驾驶驾驶之后感觉,它的能力相比于v11的版本有了质的飞跃。
图2: FSD V12 Beta 版本解读
目前Tesla FSD V12 端到端自动驾驶版本以及开启了大规模推送。随着车端的模型越来越多,需要的数据量越来越多,模型的迭代周期也希望越来越快,再开传统的采集,送标,人为路测的方法迭代,可能已经无法满足日益激烈的量产需求。
世界模型会不会成为自动驾驶的最后一块拼图?
首先我们简单的看一下关于世界模型的定义。“世界模型”是目前技术流派中难度最高的一种,其特点在于让机器能够像人类一样对真实世界有一个全面而准确的认知,不仅包括对事物的描述和分类,还包括对事物的关系、规律、原因和结果的理解和预测,从而进行推理和决策。“世界模型”也被认为是通往AGI的最优解。那么世界模型是否能够来解决目前自动驾驶领域面临的一些问题,以及是否在世界模型的加持下,端到端的自动驾驶技术会更快的大规模落地呢?
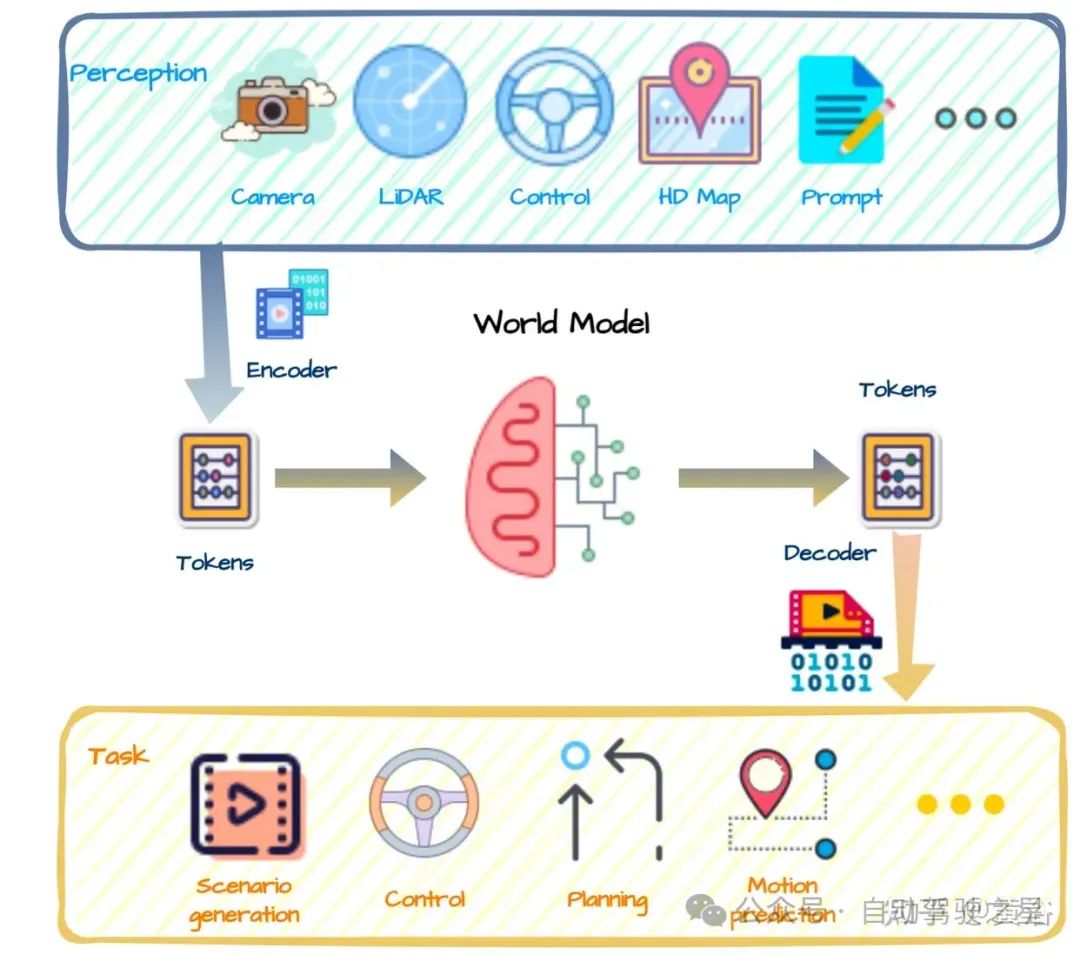
图3: 自动驾驶中如何使用世界模型
那么世界模型会不会成为自动驾驶的最后一块拼图吗?在世界模型的加持下,自动驾驶的算法会变的越来越智能吗?Tesla 的fsd v12端到端的技术会再一次引领自动驾驶科技的浪潮吗?
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近2700人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦2D/3D目标检测、语义分割、车道线检测、目标跟踪、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、在线地图、点云处理、端到端自动驾驶、SLAM与高精地图、深度估计、轨迹预测、NeRF、Gaussian Splatting、规划控制、模型部署落地、cuda加速、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









