



点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
在CARLA v2中以专家级的熟练程度运行。
题目:Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-v2)
作者单位:上海交通大学
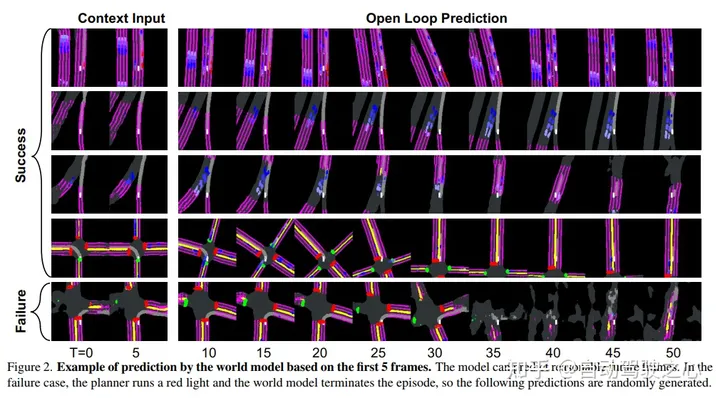
现实世界中的自动驾驶(AD),尤其是城市驾驶,涉及许多corner case。最近发布的AD仿真器CARLA v2在驾驶场景中增加了39个常见事件,并提供了比CARLA v1更接近真实的测试平台。这给社区带来了新的挑战,到目前为止,还没有文献报告CARLA v2中的新场景取得了任何成功,因为现有的工作大多都必须依赖于特定规则进行规划,但它们无法涵盖CARLA v2中更复杂的情况。这项工作主动直接训练一个规划器,希望能够灵活有效地处理corner case,认为这也是AD的未来方向。据我们所知,我们开发了第一个基于模型的强化学习方法,名为Think2Drive,用于AD,具有一个世界模型来学习环境的转变,然后它充当神经仿真器来训练规划器。这种范式极大地提高了训练效率,因为世界模型中的低维状态空间和张量的并行计算。
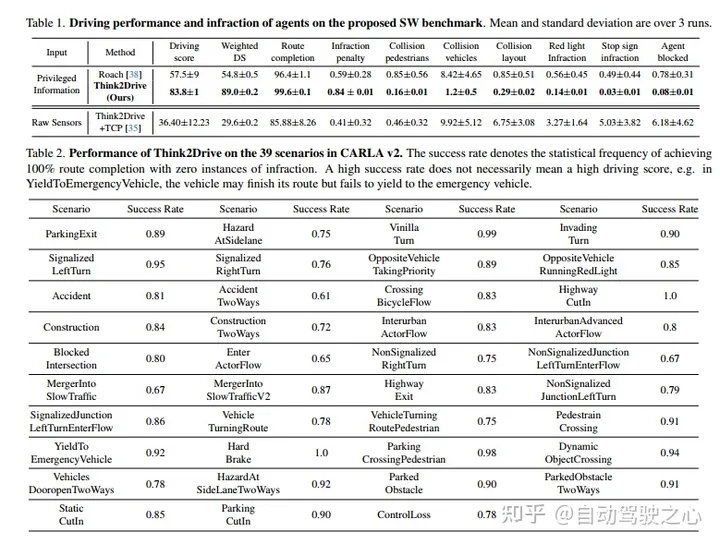
结果,Think2Drive能够在单个A6000 GPU上进行3天的训练后,在CARLA v2中以专家级的熟练程度运行,据我们所知,迄今为止尚未报告有关CARLA v2的成功(100%的路线完成)。还提出了CornerCase-Repository,这是一个支持通过场景评估驾驶模型的基准。此外,提出了一个新的平衡指标来评估性能,包括路线完成、违规次数和场景密度,以便驾驶分数可以提供更多关于实际驾驶表现的信息。
实验结果
写在最后
欢迎star和follow我们的仓库,里面包含了BEV/多模态融合/Occupancy/毫米波雷达视觉感知/车道线检测/3D感知/多模态融合/在线地图/多传感器标定/Nerf/大模型/规划控制/轨迹预测等众多技术综述与论文;
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近2700人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦2D/3D目标检测、语义分割、车道线检测、目标跟踪、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、在线地图、点云处理、端到端自动驾驶、SLAM与高精地图、深度估计、轨迹预测、NeRF、Gaussian Splatting、规划控制、模型部署落地、cuda加速、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









