



 本文探讨了特斯拉在端到端自动驾驶技术上的突破,如UniAD模型和FSD系统的简化,以及面临的训练稳定性、数据需求、算力挑战等问题。它指出端到端方法虽有潜力颠覆现状,但实施过程中仍需解决大量工程和数据难题。
本文探讨了特斯拉在端到端自动驾驶技术上的突破,如UniAD模型和FSD系统的简化,以及面临的训练稳定性、数据需求、算力挑战等问题。它指出端到端方法虽有潜力颠覆现状,但实施过程中仍需解决大量工程和数据难题。
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
2023 CVPR会议上,将best paper颁给了UniAD,由上海人工智能实验室李弘扬老师及其团队出品,端到端任务彻底掀开了帷幕。现在主流的量产方案通常是多个模块结果做融合处理,包括动态障碍物/静态障碍物检测、轨迹预测模块等,后处理及逻辑上需要花费大量的时间和精力,最终结合输出下游规控能用的结果。不得不说,这种方式不够优雅,功能上需要结合2D/3D任务,一个完整的自动驾驶产品级模块,至少需要5个模型及以上完成(当然也有多任务学习的one-model),每个模型需要反复优化处理各类corner case,耗时耗力。那么有没有去除类间任务不一致,做成统一模型的方案呢?能够直接输出车辆控制指令(如转向、加速、制动等)?答案是肯定的,当现有方案出现了问题或者瓶颈,往往会往人类认为最简约和直接的方向上靠。
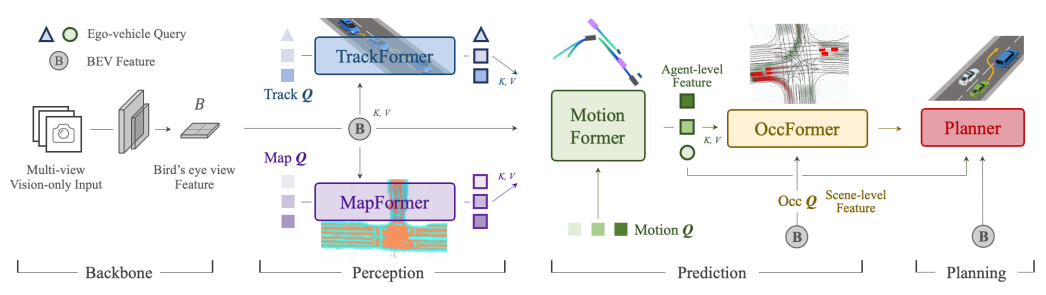
特斯拉是这个方向的先驱者,钢铁侠是一个极致追求简约和问题本质的人,从开始坚持纯视觉方案(去激光雷达)到提出BEV架构、Occupancy任务,一直在突破新的技术难点。今年特斯拉利用端到端大模型再次掀起革命,FSD系统从30万行,缩减到了3000行,端到端大模型被特斯拉率先工程化实现了,特斯拉又一次确立了自动驾驶技术领域的领军者地位。
那么端到端任务好做吗?首先说下模型训练部分,端到端的任务从视觉输入,到下游任务输出,中间gap过于大,导致训练很不稳定,UniAD采用了多任务多阶段微调,最终输出结果。而且中间的不可解释性会给产品的研发和迭代造成巨大的负面影响,所以很多自动驾驶公司不敢投入较大人力尝试。
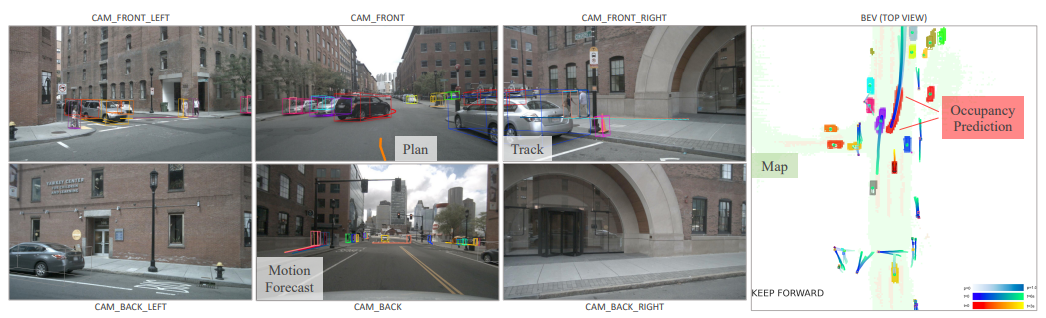
那端到端模型需要多少数据呢?特斯拉采用了近1000w视频序列数据保证了模型性能的稳定?这些数据怎么来?标签好做吗?需要完整甚至相当优秀的数据闭环系统支持?全球很少有自动驾驶公司能做到,这是个很大挑战,虽然现在world model、nerf等技术助力数据的生成,但是工业级的水准还待考究?
剩下就是怎么训这样的模型?这么大的模型+百万/千万级别的数据,对算力要求很高,抛开训练不讲,工程化的时候边缘端的算力有可能支持吗?如何工程化还是未知数。如果有一家公司,有端到端的工程经验,保证模型在简单和复杂场景下的感知都不退化,那这个技术将会有很大可能颠覆现有方案。
不过,每项技术的提出都会有很多研究者支持落地,还记得之前的深度学习刚出来的时候一片空白,但到现在为止,基本都上车或上产品了。特斯拉的端到端任务,也必将推动整个行业在这个领域做进一步探索和研究。
以上内容均出自【自动驾驶之心知识星球】

自动驾驶之心知识星球,创办于2022年7月份,致力于打造为自动驾驶行业中的 ”黄埔军校“,目前近2600人,聚集了近50+自动驾驶行业专家为大家答疑解惑。
星球内已经打磨出近30+的学习路线,涉及BEV感知、动态/静态障碍物检测、多传感器融合、多传感器标定、目标跟踪、模型部署与cuda加速、仿真等方向,沉淀了大量工程上的解决方案、学术上的优化思路!星球主要内容一览:



















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









