



作者 | Dcity 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
本文只做学术分享,如有侵权,联系删文
导读
本文介绍真实的客流统计算法从Nvidia环境往国产海光CPU+DCU进行迁移的训练过程,并验证了目标检测、行人重识别和多标签分类三个不同类型的任务,最后结果显示采用历史的训练代码,不做任何修改,就能完成整个训练!
2023年是作为AI领域从业者悲喜交加的一年,一方面是超级大模型带来的狂欢狂热,一方面是算力困境带来的无奈无助。甚至一度连消费级的Nvidia卡都要被禁,我们还能不能愉快地玩转人工智能深度学习了,说好的科研无国界呢!当然了,作为一名算法工程师,我们的使命就是解决技术和研发难题,自然不会坐以待毙。前面有了遥遥领先开路 ,于是我也在思考是否可以用国产替代呢,不是很痛的那种?
,于是我也在思考是否可以用国产替代呢,不是很痛的那种?
放眼望去,国产的AI软硬件近年也是风生水起、奋力追赶,到底哪家强,上手了才知道。本文本着工程师实事求是的精神,通过实际落地应用项目的迁移来记录国产方案替代的过程。这里介绍的是国产海光CPU+DCU的方案(不管是CPU还是AI加速器芯片都是国产的)。按照一般AI项目开发的流程,本文内容上分为训练篇和部署篇,方便的大家阅读理解。
项目任务介绍
在零售门店、大型商超和公共设施等场景下大都在出入口安装有监控摄像头,利用这些监控摄像头采用AI的技术方法进行客流信息统计是一类常见的需求。本文涉及的实战项目就是针对上述应用场景,算法应用具体包含的需求点是:
1)能够根据视频流实时统计门口的进入客流数量和出去客流数量(即同时记录出入两个方向的客流量);
2)能够实现客流去重,即频繁进出门口的客流需要在统计上去除重复;
3)能够实现特殊人员的筛选,比如门店工作人员、外卖人员、清洁人员等;
4)限制条件为不允许使用人脸信息和基于人脸的算法。(小伙伴们可以根据实际需求自己设计技术方案)
实现的一种技术方案大致如下:
对于俯视安装的摄像头拍摄到的画面,进行ROI设计,将画面分为门内区域(例如图中白色多边形)和门外区域(例如图中白色多边形以外),同时有一条虚拟的门线(例如图中的红线)。结合ROI区域和门线,可以判断客流运动在门店的进出的方向。采用目标检测器检测行人及头肩,并利用通用多目标跟踪器(比如ByteTrack(https://github.com/ifzhang/ByteTrack))进行连续跟踪,然后根据跟踪轨迹及方向来对进出门口的人数进行统计。为进行人员过滤和去重,结合行人重识别方法和人员属性信息,进行判断。大致逻辑是人员从店门区域走到店内区域就是进店候选,通过过滤来判断是不是真的进店,通过去重判断是不是首次进店:
step1: 人员进入店门区域,此时会维护一个长度为time_limit_before的入店前队列,队列中存放人员的位置box信息,再从入店前队列中取一张人员截图,该人员截图需满足没有与其他人员有重叠,或者整个过程中重叠的区域最小;
step2: 当人员的box与店内区域有交集时,此时触发入店,保存此时刻的人员截图作为第二张截图;这时又会维护一个长度为time_limit_after的入店后队列;
step3: 当time_limit_after这个队列长度达到time_limit_after时,选取此时的人员截图为第三张截图;
step4: 使用获取到的三张图片,进行人员过滤与去重,首先如果人员的三张截图中有一张背面朝向的,或者三张里面没有正面朝向的,直接认为不是真正的入店客流并过滤掉;如果未被过滤掉,将三张截图的特征与当前人员库中的特征作比较,相似度高于阈值则去重,低于阈值则认为是真实客流,比对完成后将三张截图的特征入库。

从AI模型方面看,主要涉及到三个不同类型的模型:目标检测、行人重识别、多标签图像分类。对于CV方向的小伙伴们来说,这几类模型的技术不会陌生,能够实现的算法和模型结构也有很多的选择。因为是已有项目的迁移,我们没有采用最新的一些的模型技术方法,而是尽可能复用之前的训练工程代码。
先前目标检测模型是用pytorch框架、YOLOv5网络,在Intel CPU + Nvidia GPU上训练得到;行人重识别模型使用pytorch框架、fast-reid网络,在Intel CPU + Nvidia GPU上训练得到;多标签图像分类模型是用paddlepaddle框架、PaddleClas的PULC网络,在Intel CPU + Nvidia GPU上训练得到。现在我们准备将项目的开发迁移到国产AI硬件,选择采用海光的CPU和DCU,其CPU是属于x86架构,DCU是属于GPGPU,更多详细信息可自行查询。
模型训练流程
环境搭建
从事深度学习开发的小伙伴们最痛苦的事情之一应该是环境搭建,即便是有文档,甚至源码,最基本的运行起来都绝非易事。海光DCU开发的相关文档和资源可以在他们的社区光合开发者社区(https://developer.hpccube.com/)找到,下载拉取都很方便(不用受网络之苦)。
首先,我们有一台物理机,其CPU配置为EPYC 8-core Processor, DCU配置为DCU Z100L,预装国产操作系统NFSChina Server release 4.0。根据操作系统先选择安装驱动(https://cancon.hpccube.com:65024/6/main),我们选择的是dtk-22.10.1驱动。然后,就是在宿主机上安装容器环境docker(解决环境问题的利器)。接着是在官方镜像仓库(https://sourcefind.cn/#/service-list)选择所需要的docker镜像,直接docker pull即可。
我们选择了pytorch 1.10.0-ubuntu20.04-dtk-22.10-py37-latest 和paddlepaddle 2.3.2-ubuntu20.04-dtk-22.10-py37-latest两个,分别是pytorch框架和paddlepaddle框架,对应于我们项目上模型训练的历史环境。
至此,环境搭建基本完毕,剩下就是训练工程代码所需要的一些python包,直接pip install(采用pip国内源安装,快速且无任何问题)。这可能是我们在从Nvidia迁移到众多国内外AI硬件,开始第一关———环境搭建过程中最简单最愉快的一次。
模型训练
为了方便进行比较公平的对比,模型训练的工程代码完全复用项目上使用过的历史代码,训练数据和测试数据保持完全相同,并且保持所有超参一致,不修改任何一行代码。
作为对比的Nvidia环境机器配置是GeForce RTX 1080 Ti(实在是没有卡呀!)和Intel(R) Core(TM) i7-7700K CPU @ 4.20GHz,均是单卡真实训练。
1.目标检测模型训练
目标检测模型采用的是YOLOv5网络,具体使用的是轻量级的YOLOv5s,网络层没有进行大的修改,采用自定义的场景数据集,检测类别包括行人(person)和人头(head),训练轮次100+20,SGD优化器。训练速度上两种机器配置DCU和GPU基本一致,都在平均每秒4次迭代左右(4 it/s)。
训练结束后的精度对比如下图所示。可以看出在测试集上的表现,两者相差大约2个百分点,尚可接受。这是在两种硬件环境下由完全相同的训练代码和设置条件下得出的。

从部分推理结果图显示来看,DCU和GPU训练出来的模型在推理时表现几乎一样,连预测的置信度都没有差异(如下图所示)。

2.行人重识别模型训练
行人重识别模型采用的是fast-reid网络,具体使用的轻量级的R34网络,特征向量512维,输入图像分辨率256x128,训练轮次120.训练速度上,GPU机器平均每次迭代0.65s(0.65s/it),DCU机器平均每次迭代1.34s(1.34s/it)。因为采用的是完全相同的训练设置,这里的速度差异应该是由于训练数据加载导致(两个机器的CPU核数不同,论单核的性能DCU机器的CPU应该比GPU机器采用的Intel CPU差一些,毕竟从主频上就差距较大,前者是2.9GHz,后者4.2GHz)。
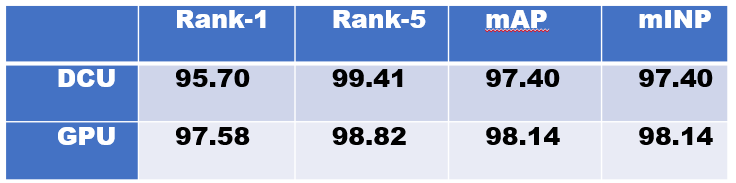
训练结束后的精度对比如下图所示, 可以看出在测试集上的表现,两者相差不到2个百分点,都还是不错的效果了。
从部分识别结果图来看还是符合预期的,能正确进行识别和区分。

3.多标签图像分类模型训练
多标签图像分类模型是采用paddlepaddle框架、PaddleClas实现。多标签分类模型的目的是对方便对人员属性进行区分,包含了性别(男女)、年龄段(儿童、青年、中年、老年、未知)、身份属性(普通客人、快递人员、穿制服工作人员、清洁工人等)、身体朝向(正面、背面、其他)。
具体实现是基于PaddleClas中的person_attribute,轻量级的PPLCNet网络进行改造。网络输入分辨率256x192,标签数量14,训练轮次100。训练速度上,DCU机器和GPU机器差异巨大,其中DCU训练的吞吐量约1410images/sec,GPU训练的吞吐量约194images/sec,尚不清楚差异的来源,因为两种环境的训练工程代码完全一致,没有任何的修改(对paddlepaddle比较熟悉的小伙伴可以去深究一下)。
训练结束后的精度对比如下图所示,可以看出在测试集上两者的差异在1个百分点之内,没有大的差别。

从一些识别结果样例图看,效果还是不错(不少场景下,截取到的行人图像质量较差)

总结
本文重点阐述了真实的客流统计算法从Nvidia环境往国产海光CPU+DCU进行迁移的训练过程,验证了pytorch和paddlepaddle两种主流的深度学习框架,以及目标检测、行人重识别和多标签分类三种类型的深度学习任务,详细对比了Nvidia GPU和Hygon DCU两种硬件环境下的训练结果。从使用体验上总体还是超出预期的,最难能可贵的是采用历史的训练代码,不做任何修改,就能完成整个训练,并且精度对比差异不大,这才是真的无痛平滑迁移!当然,此处进行的实验有限,不能说明太多问题,但是相信国产的AI软硬件在小伙伴们的共同努力下会越来越好,毕竟谁能一直忍受卡脖子呢!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!



















 2238
2238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









