



点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
本文是我在学习Thomas老师的《轨迹预测理论与实战课程》时输出的个人学习笔记,欢迎大家交流讨论~
说明: 每小节内符号使用是一致的;预测目标、目标、活动对象以及对象会混用,都是指场景中的交通参与者,例如车辆、行人等,英文文献中多使用 agent 表示。
轨迹预测结果的表示方法有不同的分类方法,例如,在综述 (Rudenko and Palmieri et al. 2020) 中将其分为三类:Single trajectory、Parameter distribution、Non-Parameter distribution,而在 MultiPath++ 中总结了近来的一些工作并归为 8 种具体的形式:
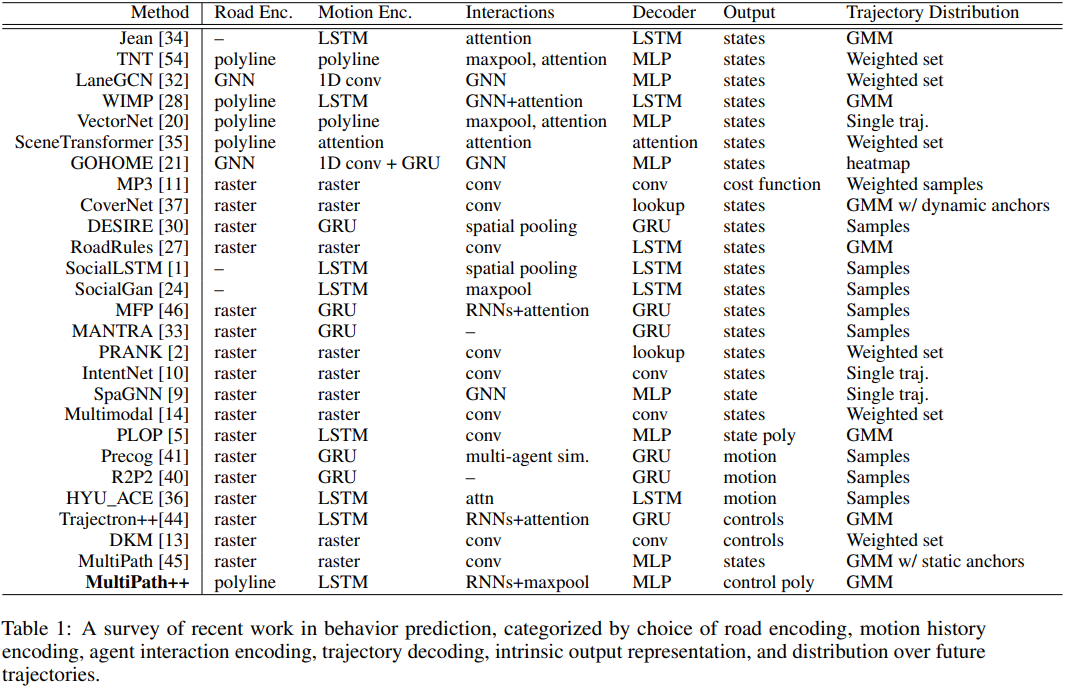
本文内容均出自《轨迹预测理论与实战课程》,欢迎领取优惠券加入学习!


扫码领取优惠券,加入学习!
下面参考 Multipath++ 的分类,对每一种轨迹预测的输出形式结合具体工作分别介绍之。
Single traj.
VectorNet
Code on Github(https://github.com/Liang-ZX/VectorNet)
VectorNet 在其文章的公式 中描述了预测输出的形式,其中 代表第 个预测目标(可能是行人、车辆等), 代表了第 个目标的特征, 是一个 ,预测结果 代表是一系列二维轨迹点,形状为 ,如果将预测结果按照顺序在地图上连接,将形成一条轨迹,这也就是 Single traj. 的含义。
Samples
SocialLSTM
SocialLSTM 是一种联合预测(Joint Prediction)方法。
联合预测是考虑对象在未来发生的交互的预测方式。假设观测了场景 中 个对象在 时刻的轨迹,预测第 个对象在未来 时刻的位置 时,需要考虑其他对象在 时刻的位置,以评估场景中可能存在的交互对 产生的影响。
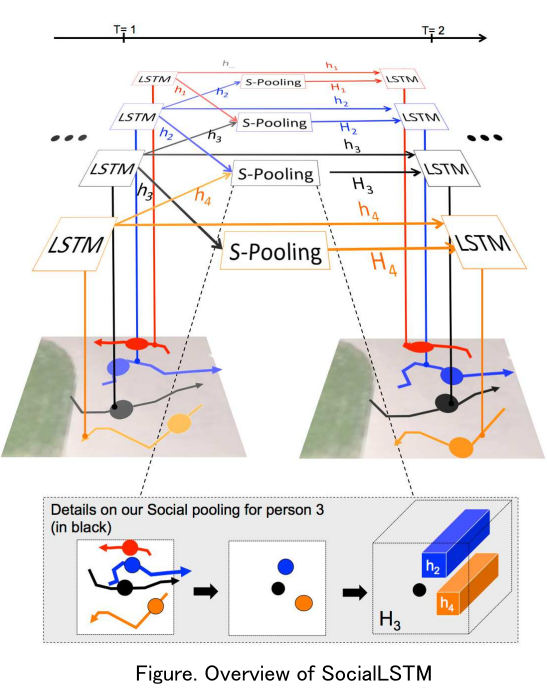
SocialLSTM 是通过迭代来实现联合预测,对同一个场景中不同对象的预测是耦合在一起的,可以认为该方法的输入的场景,输出是场景中所有对象的轨迹,即 .
Samples 体现在预测对象 在时间 的位置是从双变量高斯分布 中采样获得的,即 .
DESIRE
Code on Github(https://paperswithcode.com/paper/desire-distant-future-prediction-in-dynamic)
DESIRE 的第二阶段设计了 refinement 过程来评估场景中对象未来的交互,因此该方法也属于联合预测。该方法第一阶段是边缘预测(Marginal Prediction)的过程,具体来说 DESIRE 是使用 为每个对象生成 条轨迹,表示为 .
边缘预测与联合预测相对,即不对对象之间未来可能发生的交互进行显式的建模。
DESIRE 的 refinement 模块会根据对其他对象的预测生成 来调整对象 的每一条轨迹,最终预测结果为 ,其中 .
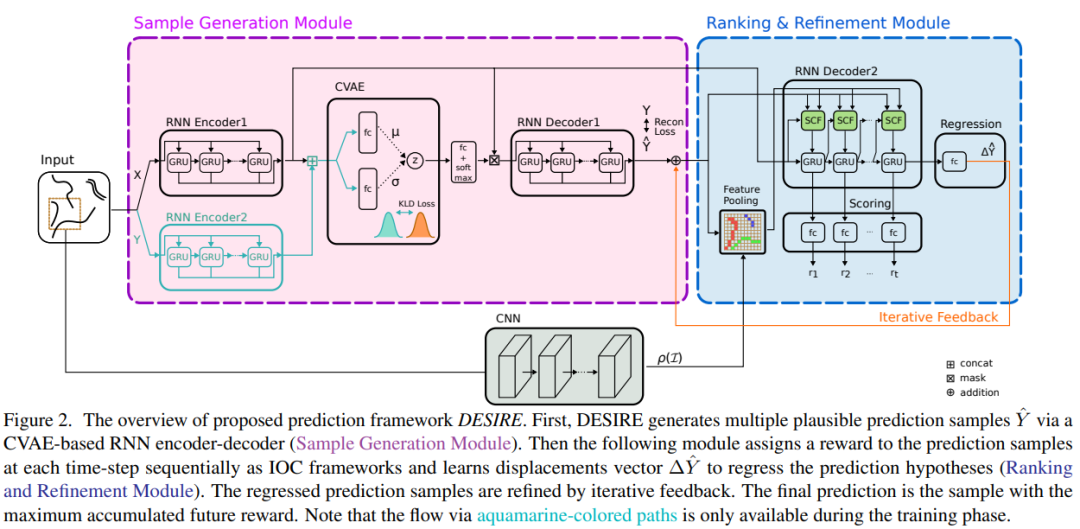
Sample 体现在生成 条轨迹的过程,即从先验分布 中采样得到 ,然后基于 生成 .
Weighted samples
MP3
MP3 是一个 E2E 的模型,其中包括预测的模块。预测的输出不是活动对象的轨迹,而是 张占据栅格 . 初始占据栅格 上的值为 0 或 1,栅格 上的值表示在时间 该位置被占据的概率。方法评估 上每个对象的 个移动模式,因此为每个对象了生成 个 记为 和 个 记为 . 根据设计的 Occupancy Flow 流程就可以得到 .
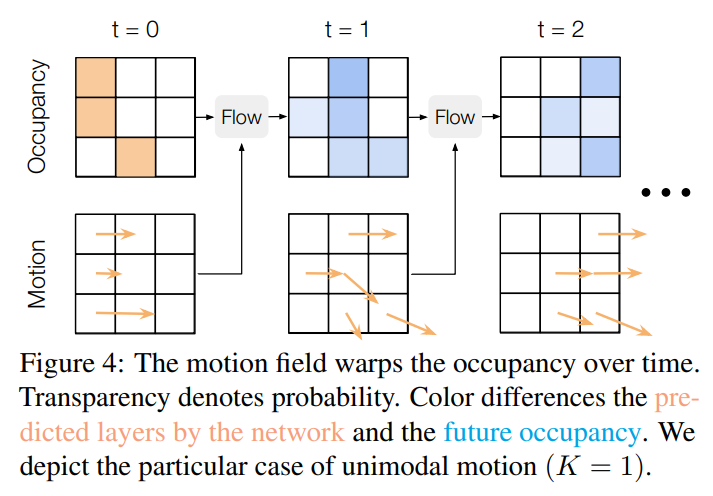
Weighted samples 体现在方法可以确切的给出 时刻对象从栅格位置 移动到栅格位置 的概率,因此根据预测的 可以得出对象 的 条轨迹,并且可以计算每条轨迹发生的概率,和 SocalLSTM 或 DESIRE 不同的是,MP3 的 Sample 空间是有限的。
Weighted set
Weighted set is a special case of GMMs where only means and mixture weights are modeled.
TNT [Code on Github]
TNT 对预测出的 条轨迹通过设计的模块 进行打分,然后经由 select 策略最终挑选出 条轨迹,即预测的输出分为两个部分, 条轨迹和 个得分。
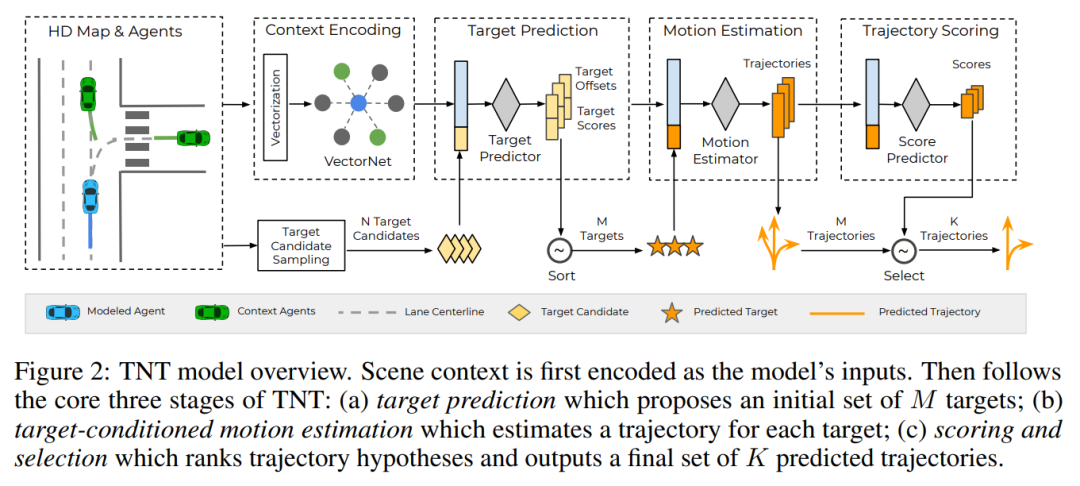
TNT 预测的粒度是对象,而类似SocialLSTM、DESIRE、MP3等方法,预测的粒度是场景,即除非场景中只存在一个活动对象,否则不能单独只对场景中某一个对象的未来轨迹做预测。
LaneGCN [Code on Github]
LaneGCN 的输出同样是 条轨迹和 个得分。LaneGCN 方法的创新主要在于提出的 FusionNet, 条轨迹由一个 residual block 和一个 linear layer 组成的模块回归得到, 个得分也使用了相同的结构进行预测。
和 Sample 一类方法不同的是,输出为 set 的方法,轨迹解的空间大小一般是有限的,例如 LaneGCN 只能输出对象的 条预测轨迹,而 Sample 一类方法可以从预测的分布中多次采样。
GMM
Trajectron++ [Code on Github]
对场景中的车辆 Trajectron++ 预测输出控制量(角速度和加速度)在每个未来时刻的高斯分布 ,然后在预测的分布中采样到具体的控制量,再经由积分器输出其预测轨迹,以保证每条输出的轨迹都满足运动学的约束。GMM(高斯混合模型)是由多个多元高斯分布成分(component)组成的分布,假设 Trajectron++ 直接输出轨迹而不经过积分器,那么模型预测的 GMM 分布可以表示为下面的形式:
Trajectron++将 构造为 one-hot vector,在其他方法中 也可以有其他形式,例如在MultiPath++中将其描述为 learned anchor.
GMM w/ static anchor
MultiPath
Code on Github(https://github.com/govvijaycal/confidence_aware_predictions)
Trajectron++中的隐变量 是一种抽象的行为概念,可能代表着左转、直行、右转等,而 MultiPath 的 anchor 也就是 Trajectron++ 中的 实际上是一条特定的轨迹,static anchor 表示的是生成 anchor 的方法是静态的,也就是提前设置 个由所有对象共享的 anchor,MultiPath 使用 k-means 算法获得 个 anchor 表示为 . MultiPath 模型在预测时候,先评估对象在 上的概率分布,然后预测轨迹上路径点的不确定性,模型预测的 GMM 分布可以表示为下面的形式:
GMM w/ dynamic anchors
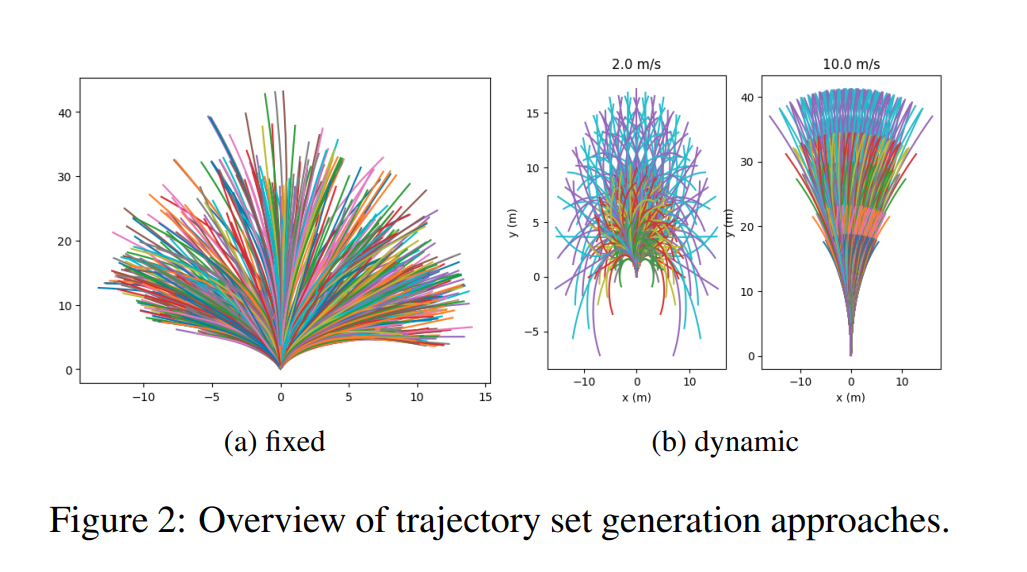
CoverNet
Code on Github(https://github.com/nutonomy/nuscenes-devkit/blob/master/python-sdk/nuscenes/prediction/models/covernet.py)
CoverNet 预测的 GMM 形式和 MultiPath 的一致,区别在于 dynamic anchors 指的是生成 anchor 的过程考虑了预测对象的当前运动状态,例如,对于正在以 2m/s 和 10 m/s 运动的对象将生成不同的 anchor 轨迹:
Heatmap
GOHOME
GOHOME 以 Heatmap 的形式表达在预测结束时刻对象出现某个位置的概率,具体来说,模型对 Lanelet(一段车道中心线) 打分排序后选择 个得分最高的 Lanelet 预测其局部的 Heatmap,然后再将 个局部的 Heatmap 投射到全局坐标系中。为了预测活动对象的未来轨迹,首先需要从全局的 Heatmap 中选择若干目标点(end points),再由 MLP 预测输出轨迹。
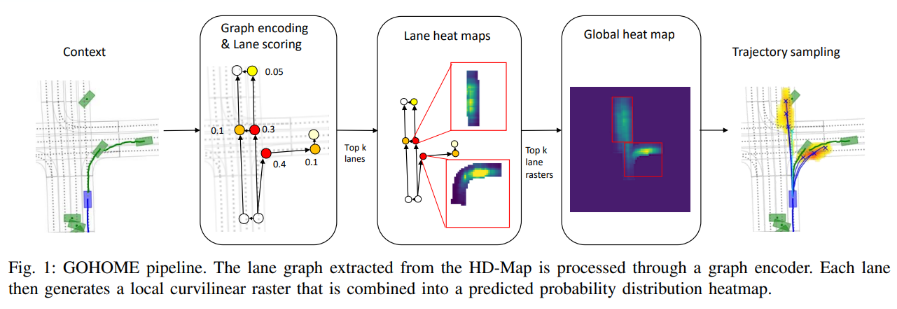
选择若干个目标点这一步,沿用了作者在 HOME 中的方法,以优化输出的轨迹集在 MissRate 指标上的表现。
总结
单纯从轨迹预测的角度来说,预测的形式也有多方面的影响:一是决定了如何从预测结果中获取预测轨迹,因为预测结果未必是对轨迹的直接表示;二是对于损失函数的选择或者设计有指导作用;三是对评价指标的适应性也不同,例如 LaneGCN 对预测的 条轨迹有对应的得分,那么经过简单排序可以计算不同的 ,而有的预测输出形式为评估在某一指标上的表现,则可能还需要多次推理或者多次采样等操作。
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 1585
1585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









