



作者 | Sean 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/663742537
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【自动泊车】技术交流群
本文只做学术分享,如有侵权,联系删文
自动驾驶泊车算法学习记录
Introduction
最近在学习自动驾驶泊车方面的算法,看的论文主要有以下三篇,分别是Path Planning for Autonomous Vehicles in Unknown Semi-structured Environments, DL-IAPS and PJSO: A Path/Speed Decoupled Trajectory Optimization and its Application in Autonomous Driving, Speed Profile Planning in Dynamic Environments via Temporal Optimization
Path Planning for Autonomous Vehicles in Unknown Semi-structured Environments
这篇论文应该只要是学习Hybrid Astar的人都看过,主要讲的是在开放空间搜索泊车路径,第一步先搜索出一条大概满足运动学约束的路径,然后密集插值,在进一步采用CG算法优化平滑度,保持原来关键的位置不变,这样也不用害怕碰撞了,这篇论文进一步求路径点对应的速度
DL-IAPS and PJSO: A Path/Speed Decoupled Trajectory Optimization and its Application in Autonomous Driving
这篇论文是逻辑上和上一篇论文挺像的, 先搜索一条路径,然后对路径点进一步平滑,这个论文平滑的时候会采用一个信赖半径, 发生碰撞了就缩小关键点的可移动范围, 除此之外DL-IAPS and PJSO还求解了路径的速度,这是比较牛逼的,但我看不太懂- -,后续有机会再进一步研究
Speed Profile Planning in Dynamic Environments via Temporal Optimization
我觉得路径和速度解耦求解的还可以看这篇伯克利的论文, 这篇论文是默认已经有一条光滑的路径,然后对时间变量优化,最后求解出路径点的速度,加速度,我复现了下发现这个方法会很容易收到路径点是否平滑的影响(曲率连续),如果路径点不够平滑,求解出来的速度也不好,这里论文没有说这个问题。
Idea
我看传统的泊车方法好像都需要先搜索出一条路径,然后再作进一步的处理,我觉得Hybrid Astar的搜索速度非常依赖于地图分辨率,分辨率小了就会很慢,大了就没法精确避障了, 如果直接使用一条直线段连接成的路径作为参考线,不用搜索的结果了,然后对这个直线段采用最优化的方案进行求解效果会如何。TEB就是直接对直线段进行优化,并且也实现了car-like方面的路径规划, 于是我去下载了源码然后跑了一下,发现效果不太好,速度很慢, 很容易出现无解的情况, 我觉得可能是因为TEB还多了一个时间变量需要处理,时空联合规划很容易失败,如果我把这个时间给去掉,在进行优化的话效果会不会就不一样了?
Method

kinematic cost function
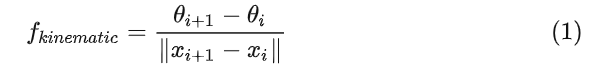
nonholonomic constraint
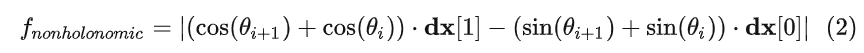
safety constraint
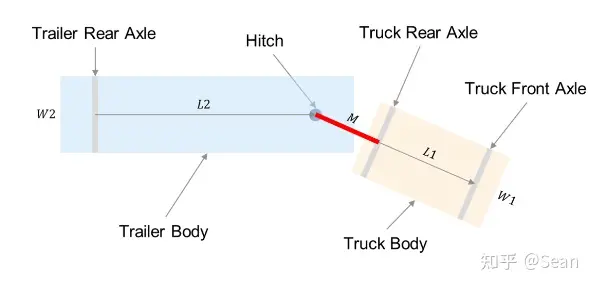
vehicle with trailer kinematic 参考文献

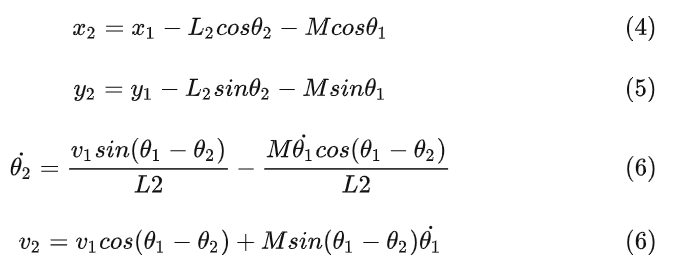
code
代码方面就是把TEB的代价函数复制过来就可以了,优化器改成ceres-solver的, 车辆模型,我不仅实现了汽车模型,还顺带在卡车模型啥也测试了一波。
Result
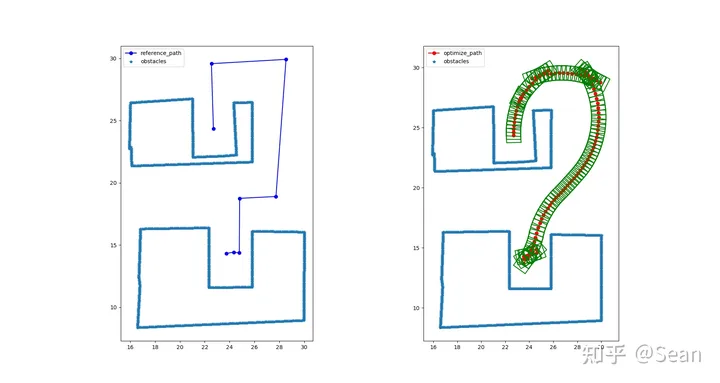
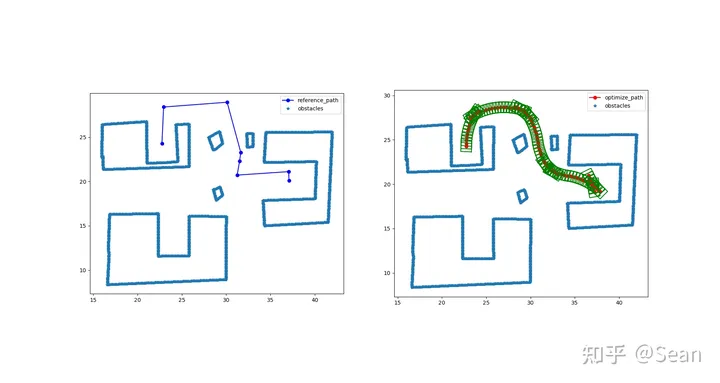
测试模型包含阿克曼汽车模型以及vehicle with trailer模型, 图中阿克曼就是用一个矩形来描述,卡车模型则用两个矩形来描述,小个的是车头,长条的是车厢(用c++画的图,很简陋- -),绿色框是辅助划线的可以不用管, 其他的多边形则为障碍物,
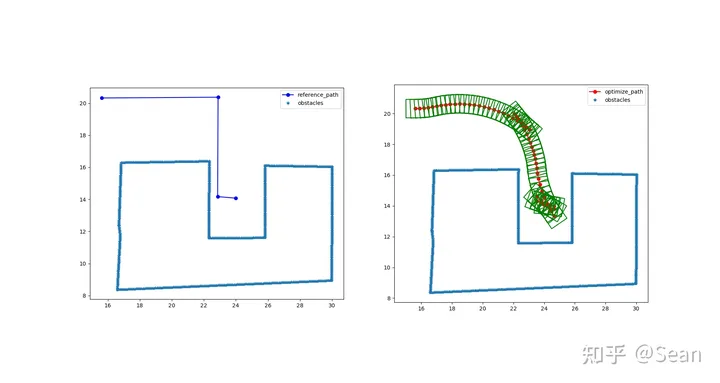
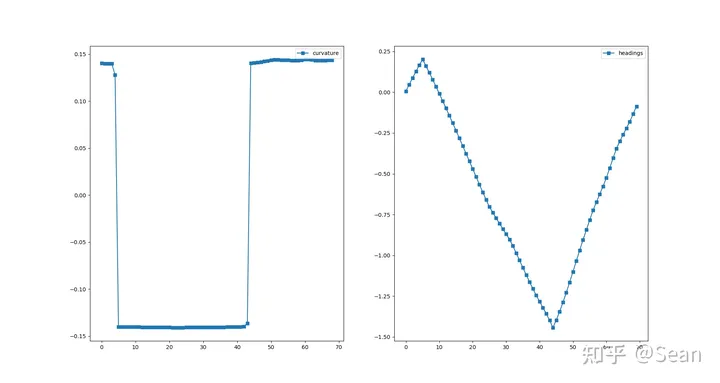
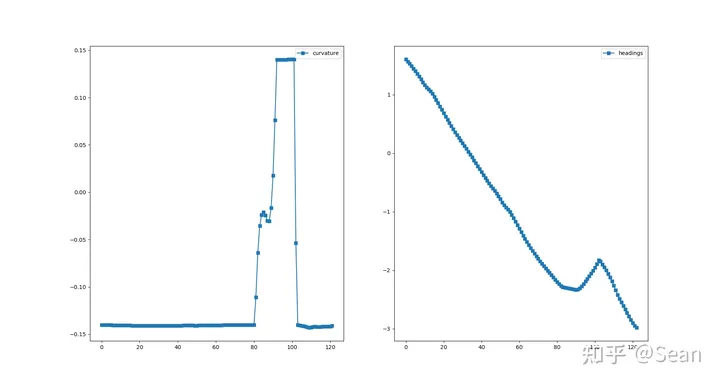
我以为测试结果会很差,结果还是有点出乎意料的,虽然有的时候会出现无解,但是只要初始线段给的好一点就不会出问题,优化的速度也挺快平均时间大概是0.3s, 路径的质量的评价我觉得主要是看平滑度和曲率大小,只要曲率不会超过车辆最小转弯半径就可以了, 这里我设置的曲率最大是0.155, 列了几组测试图,第一个是直线段参考线和优化后的路径图,第二幅是对应的曲率和航向
Test1
Test2
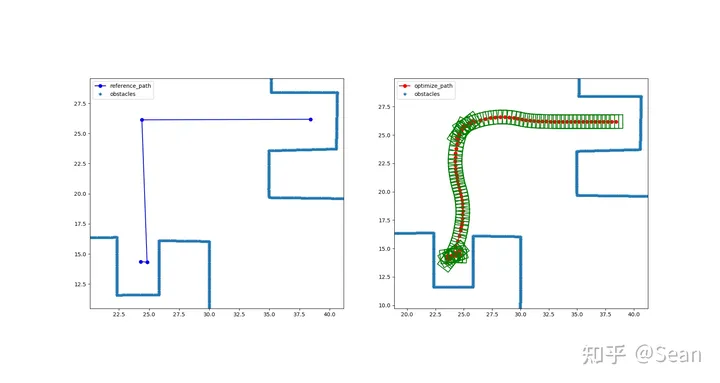
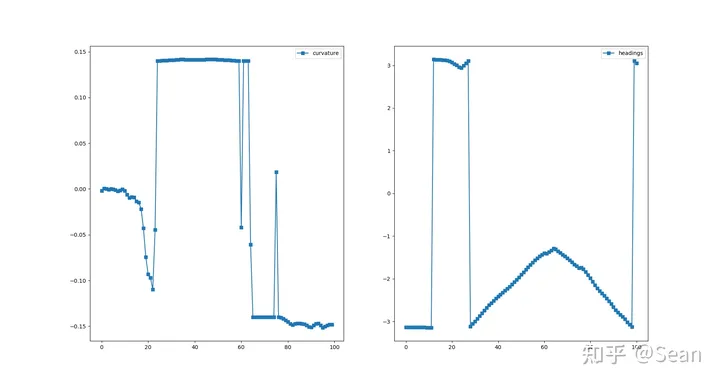
Test3
Test4
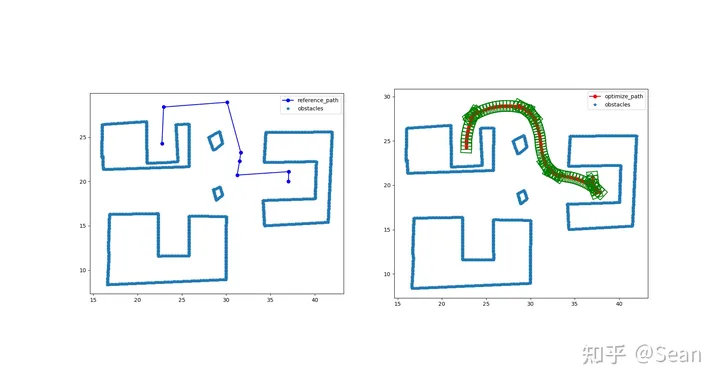
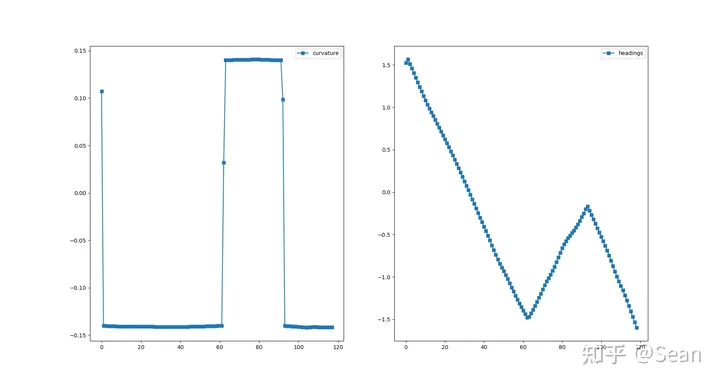
Test6
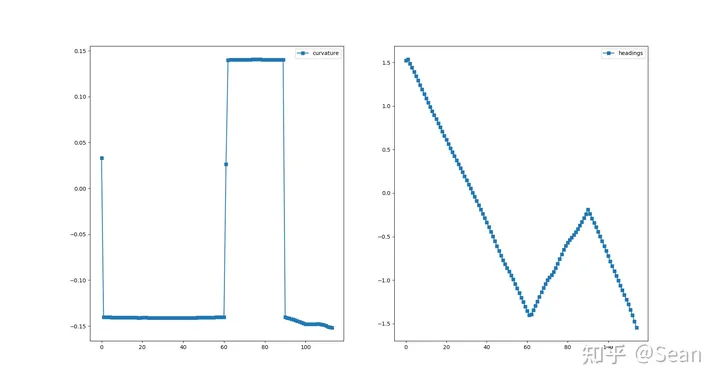
problem
路径点的间隔不能小,否则优化时间和质量都会受到影响,这个我觉得后期可以参考上述论文,先优化出一条大概得解,然后再密集插值进一步平滑
参数初始化的好坏也会影响到求解结果
曲率不连续,虽然路径点曲率都满足要求了,但是曲率还是存在突变
倒车次数比较多
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 2770
2770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









