



作者 | 萌萌的糖 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/656880112
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标跟踪】技术交流群
本文只做学术分享,如有侵权,联系删文
1 简介
Apollo视觉跟踪模块已经和视觉障碍物检测模块融合,从上回视觉障碍物检测中我们发现,在障碍物检测pipeline配置文件:camera_detection_pipeline.pb.txt出现了多个OMT_OBSTACLE_TRACKER,内容如下:
stage_type: OMT_OBSTACLE_TRACKER
stage_type: Smoke_OBSTACLE_DETECTION
stage_type: OMT_OBSTACLE_TRACKER
stage_type: MULTI_CUE_OBSTACLE_TRANSFORMER
stage_type: LOCATION_REFINER_OBSTACLE_POSTPROCESSOR
stage_type: OMT_OBSTACLE_TRACKER
stage_type: OMT_OBSTACLE_TRACKER
stage_config: {
stage_type: OMT_OBSTACLE_TRACKER
...
...
}
stage_config: {
stage_type: Smoke_OBSTACLE_DETECTION
...
...
}
...其实障碍物检测和跟踪在Apollo中按照以下流程进行,以下流程分别和上面stage对应:
进行障碍物2D中心位置、速度和3D位置、速度预测(也称为先验估计)
障碍物检测(得到障碍物观测数据)
障碍物2D关联匹配(添加观测数据,并更新2D状态)
障碍物2D到3D投影
障碍物3D关联匹配(添加观测数据,并更新3D状态)
进行跟踪。(实际上在在这里什么都没做)
代码和stage的对应关系:
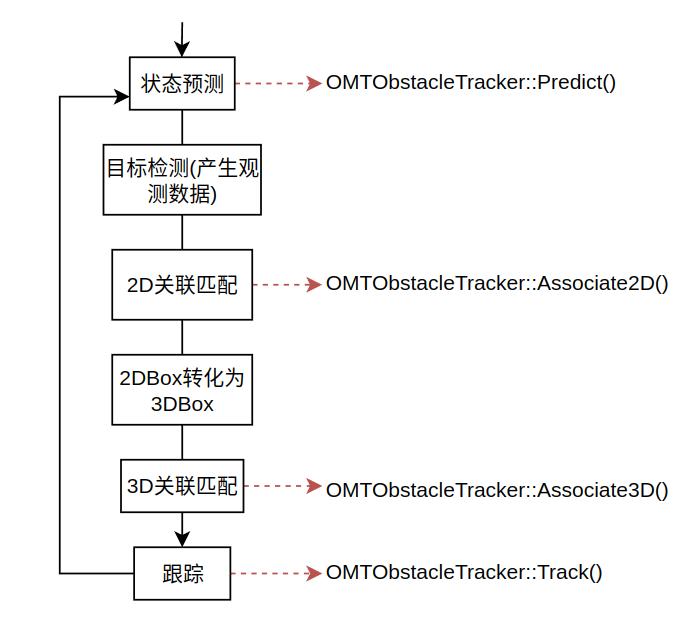
出现多个跟踪stage是下因为跟踪是按照Predict->Associate2D->Associate3D->Track的流程,每个stage对应一个方法。视觉跟踪代码位于modules/perception/camera/lib/obstacle/tracker/omt/omt_obstacle_tracker.cc,具体的实现在OMTObstacleTracker类中,下面是头文件中的声明:
class OMTObstacleTracker : public BaseObstacleTracker {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
OMTObstacleTracker() = default;
~OMTObstacleTracker() = default;
// 初始化
bool Init(const ObstacleTrackerInitOptions &options) override;
// @brief: predict candidate obstales in the new image.
// @param [in]: options
// @param [in/out]: frame
// candidate obstacle 2D boxes should be filled, required.
bool Predict(const ObstacleTrackerOptions &options,
CameraFrame *frame) override;
// @brief: associate obstales by 2D information.
// @param [in]: options
// @param [in/out]: frame
// associated obstacles with tracking id should be filled, required,
// smoothed 2D&3D information can be filled, optional.
bool Associate2D(const ObstacleTrackerOptions &options,
CameraFrame *frame) override;
// @brief: associate obstales by 3D information.
// @param [in]: options
// @param [in/out]: frame
// associated obstacles with tracking id should be filled, required,
// smoothed 3D information can be filled, optional.
bool Associate3D(const ObstacleTrackerOptions &options,
CameraFrame *frame) override;
// @brief: track detected obstacles.
// @param [in]: options
// @param [in/out]: frame
// associated obstacles with tracking id should be filled, required,
// motion information of obstacles should be filled, required.
bool Track(const ObstacleTrackerOptions &options, CameraFrame *frame) override;
// 输入stage_config初始化
bool Init(const StageConfig& stage_config) override;
bool Process(DataFrame* data_frame) override;
bool IsEnabled() const override { return enable_; }
std::string Name() const override { return name_; }
private:
float ScoreAppearance(const Target &target, TrackObjectPtr object);
float ScoreMotion(const Target &target, TrackObjectPtr object);
float ScoreShape(const Target &target, TrackObjectPtr object);
float ScoreOverlap(const Target &target, TrackObjectPtr track_obj);
void ClearTargets();
bool CombineDuplicateTargets();
void GenerateHypothesis(const TrackObjectPtrs &objects);
int CreateNewTarget(const TrackObjectPtrs &objects);
private:
omt::OmtParam omt_param_;
FrameList frame_list_;
SimilarMap similar_map_; // 保存frame_list_中两帧中物体间的相似度,为4维矩阵
std::shared_ptr<BaseSimilar> similar_ = nullptr; // 特征相似度计算器
apollo::common::EigenVector<Target> targets_; // 保存成功关联匹配的target
std::vector<bool> used_; // 用于保存障碍物是否已经和target关联上
ObstacleReference reference_; // 用于求地平面方程的参考
std::vector<std::vector<float>> kTypeAssociatedCost_; //类型转化的cost
int track_id_ = 0;
int frame_num_ = 0;
int gpu_id_ = 0;
float width_ = 0.0f;
float height_ = 0.0f;
protected:
ObjectTemplateManager *object_template_manager_ = nullptr;
};2 跟踪模块初始化
跟踪模块首先还是调用OMTObstacleTracker::Init()方法完成参数配置,值得注意的是地平面参考初始化,reference_主要用于地平面方程求取。
reference_.Init(omt_param_.reference(), width_, height_);2.1 reference_初始化
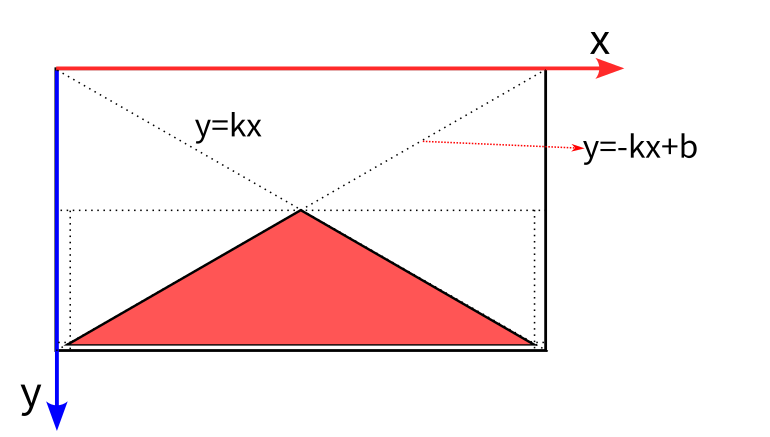
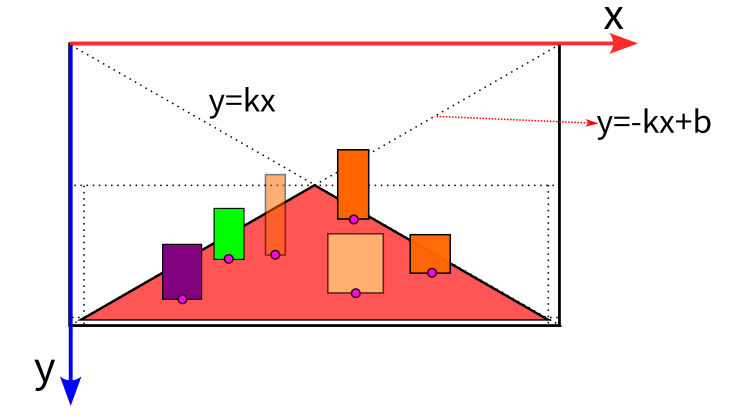
reference_的初始化是按经验确定车道平面位于图像的大致区域,用于车道平面拟合时过滤不在车道平面上的障碍物,如,天上、马路牙子上的障碍物。具体内容如下:
void ObstacleReference::Init(const omt::ReferenceParam& ref_param, float width, float height)
{
/******
* margin: 2
* min_allow_height: 50
* area_decay: 0.98
* down_sampling: 25
* height_diff_ratio: 0.1
*/
ref_param_ = ref_param; // 参数
img_width_ = width; // 1920
img_height_ = height; // 1080
// 进行了下采样
ref_width_ = static_cast<int>(width / static_cast<float>(ref_param.down_sampling()) + 1);
ref_height_ = static_cast<int>(height / static_cast<float>(ref_param.down_sampling()) + 1);
static const float k = static_cast<float>(ref_height_) / static_cast<float>(ref_width_);
static const float b = static_cast<float>(ref_height_);
// 填充可能是车道平面的区域
init_ref_map_.resize(ref_height_);
for (int y = 0; y < ref_height_; ++y) {
init_ref_map_[y].resize(ref_width_, -1);
if (y < ref_height_ / 2 || y > ref_height_ - ref_param_.margin()) {
continue;
}
for (int x = ref_param.margin(); x < ref_width_ - ref_param.margin(); ++x) {
if (y > -k * static_cast<float>(x) + b && y > k * static_cast<float>(x)) {
init_ref_map_[y][x] = 0;
}
}
}
object_template_manager_ = ObjectTemplateManager::Instance();
}init_ref_map_为图2红色区域,为了方便计算,其大小为原始图像的的25分之一,在后续地平面检测中将会介绍其具体的用法。
3 障碍跟踪处理接口
整个跟踪其核心方法为Process,展示了整个障碍物跟踪的流程,代码如下:
bool OMTObstacleTracker::Process(DataFrame *data_frame) {
if (data_frame == nullptr) {
return false;
}
CameraFrame *camera_frame = data_frame->camera_frame;
ObstacleTrackerOptions tracker_options;
auto track_state = data_frame->camera_frame->track_state;
// 判断跟踪状态
switch (track_state) {
case TrackState::Predict: {
// 第一步,状态预测(又称先验估计)
Predict(tracker_options, camera_frame);
data_frame->camera_frame->track_state = TrackState::Associate2D;
break;
}
case TrackState::Associate2D: {
// 第二步
// 当完成目标检测后,也就是得到了观测数据。
// 1.对检测到的障障碍物类别和3Dbox进行修正
// 2.进行2Dbox关联匹配.
// 3.向各类滤波器中添加观测数据,并更新其状态量
Associate2D(tracker_options, camera_frame);
data_frame->camera_frame->track_state = TrackState::Associate3D;
break;
}
case TrackState::Associate3D: {
// 第三步
// 3Dbox关联匹配
Associate3D(tracker_options, camera_frame);
data_frame->camera_frame->track_state = TrackState::Track;
break;
}
case TrackState::Track: {
// 什么都不做
Track(tracker_options, camera_frame);
data_frame->camera_frame->track_state = TrackState::Predict;
break;
}
default:
// do nothing
break;
}
return true;
}由于跟踪模块启动一开始,直接看Predict()方法从代码的角度让人有点不知所以,我们暂时先不管Predict()方法,先从Associate2D()开始介绍,
4 2D关联匹配
假设现在调用Smoke网络完成了障碍物检测,接着会进入Associate2D()方法,进行2D的关联匹配,同时这也是跟踪模块最重要的函数。
bool OMTObstacleTracker::Associate2D(const ObstacleTrackerOptions &options, CameraFrame *frame) {
inference::CudaUtil::set_device_id(gpu_id_);
frame_list_.Add(frame); // 加入当前帧
// 取出当前帧的前一帧与前面所有帧的计算算相似度
for (int t = 0; t < frame_list_.Size(); t++) {
// 遍历所有帧
int frame1 = frame_list_[t]->frame_id;
// 当前帧的前一帧
int frame2 = frame_list_[-1]->frame_id;
similar_->Calc(frame_list_[frame1], frame_list_[frame2], similar_map_.get(frame1, frame2).get());
}
// 跟丢lost_age+1
for (auto &target : targets_) {
target.RemoveOld(frame_list_.OldestFrameId());
++target.lost_age;
}
TrackObjectPtrs track_objects; // 保存当前帧关联匹配成功到的目标
// 统计检测到的障碍物
for (size_t i = 0; i < frame->detected_objects.size(); ++i) {
// 跟踪目标初始化
TrackObjectPtr track_ptr(new TrackObject);
track_ptr->object = frame->detected_objects[i];
track_ptr->object->id = static_cast<int>(i);
track_ptr->timestamp = frame->timestamp;
track_ptr->indicator = PatchIndicator(frame->frame_id, static_cast<int>(i), frame->data_provider->sensor_name());
track_ptr->object->camera_supplement.sensor_name = frame->data_provider->sensor_name();
// 两个相机都会检测到物体,将其中一个12mm焦距相机检测到的物体的2Dbox坐标投射到6mm相机的图像坐标系下,方便后续计算。
// 这部分内容可以查看第二节的InitProjectMatrix()方法,因为6mm相机的投影矩阵为单位矩阵,12mm投影矩阵可以通过内参和外参计算得到。
ProjectBox(frame->detected_objects[i]->camera_supplement.box,
frame->project_matrix, &(track_ptr->projected_box));
track_objects.push_back(track_ptr);
}
// 修正但前帧检测到物体的wlh
// 1.通过先验信息调整类别高度->调整3Dbox尺寸
// 2.通过地平面估计,得到物体的深度,在利用深度信息根据相机投影关系求取高度信息
// 3.根据历史参考,找到与当前检测到的物体的最小高度差,确定当前物体的高度信息
// 4.最终物体的高度为3者中位数
// 5.按比例调整3Dbox的w和l
reference_.CorrectSize(frame);
used_.clear();// 保存障碍物是否和target成功关联匹配上。
used_.resize(frame->detected_objects.size(), false);
// 计算但前帧的所有检测到的障碍物和历史target_中的的障碍物之间的图像特征、运动、形状、iou相似度
// 得到成功的匹配
GenerateHypothesis(track_objects);
// 没有匹配上的判断是否是新target
int new_count = CreateNewTarget(track_objects);
AINFO << "Create " << new_count << " new target";
for (auto &target : targets_) {
if (target.lost_age > omt_param_.reserve_age()) {
AINFO << "Target " << target.id << " is lost";
target.Clear();
} else {
// 更新目标类型,使用均值滤波器重庆更新目标框大小
target.UpdateType(frame);
// 均值滤波修正box长宽,卡尔曼滤波修正box中心点位置
target.Update2D(frame);
}
}
CombineDuplicateTargets();
ClearTargets(); // 清除空白target
// return filter reulst to original box
Eigen::Matrix3d inverse_project = frame->project_matrix.inverse();
for (auto &target : targets_) {
if (!target.isLost()) {
ProjectBox(target[-1]->projected_box, inverse_project,
&(target[-1]->object->camera_supplement.box));
RefineBox(target[-1]->object->camera_supplement.box, width_, height_,
&(target[-1]->object->camera_supplement.box));
}
}
return true;
}4.1 相似度计算
匹配开始,首先进行两帧之间检测到的物体相似度计算。相似度计算器similar_初始化为GPUSimilar,具体实现也是调用cuda的Gemm矩阵运算库,相似度计算代码如下,感兴趣的同学可以查一下Gemm,这也是神经网络卷积运算的核心基础。
// 计算图像块相似度
bool GPUSimilar::Calc(CameraFrame *frame1, CameraFrame *frame2,base::Blob<float> *sim) {
int n = static_cast<int>(frame1->detected_objects.size());
int m = static_cast<int>(frame2->detected_objects.size());
// 如果两帧都没有检测到目标
if ((n && m) == 0) {
return false;
}
sim->Reshape({n, m}); // n*m的相识度矩阵
if (frame1->track_feature_blob == nullptr) {
AERROR << "No feature blob";
return false;
}
// 检测到的物体的特征向量
int dim = frame1->track_feature_blob->count(1);
// 特征向量的维度必须一致
assert(dim == frame2->track_feature_blob->count(1));
float *s = sim->mutable_gpu_data();
float const *feature1 = frame1->track_feature_blob->gpu_data();
float const *feature2 = frame2->track_feature_blob->gpu_data();
// 计算其相似度调用cuda中的基本线性运算矩阵库:cublas。调用Gemm完成矩阵运算
inference::GPUGemmFloat(CblasNoTrans, CblasTrans, n, m, dim, 1.0, feature1, feature2, 0.0, s);
return true;
}4.2 reference_修正障碍物长宽高
reference_.CorrectSize()功能如下:
通过先验信息调整类别高度
通过地平面估计,得到物体的深度,在利用深度信息根据相机投影关系求取高度信息
通过在线的相机标定,得到物体的深度,在利用深度信息根据相机投影关系求取高度信息
根据历史参考,找到与当前检测到的物体的最小高度差,确定当前物体的高度信息
最终物体的高度为4者中位数
按比例调整3Dbox的w和l
为什么大费周章的对障碍物高度进行修正?原因在于目标检测出的深度往往误差较大,每类障碍物的高度其实相差不大,通过严格确定障碍物的高度,再通过相机投影模型可以直接求取深度,这样的方法并不完全依赖于神经网络,更为鲁棒。从这里可以看出Apollo没有直接采用目标检测得到的尺寸,而是对其进行3个方面的修正,做了比较谨慎的处理,相当细节。reference_.CorrectSize()方法内容比较长,将会按照上面描述的6个步骤进行分析。
4.2.1 按照障碍物模板对3Dbox修正
Apollo预先统计好了不同类型障碍的长宽高、最大速度限制的模板,用这些先验知识修正障碍物长宽高。在ObstacleReference类中模板为object_template_manager_成员变量,是指向ObjectTemplateManager的指针,查看ObjectTemplateManager的头文件,发现存在DECLARE_SINGLETON(ObjectTemplateManager)的声明,这是cyber的单例模式typedef。模板的具体可以参考ObjectTemplateManager::Init()初始化的代码,这里直接介绍按模板修正的方法。
void ObstacleReference::CorrectSize(CameraFrame* frame)
{
// 模板中种类障碍物的最小尺寸,hwl顺序
const TemplateMap& kMinTemplateHWL = object_template_manager_->MinTemplateHWL();
// 模板中种类障碍物的最小尺寸
const TemplateMap& kMaxTemplateHWL = object_template_manager_->MaxTemplateHWL();
// 模板中所有种类障碍物的尺寸
const std::vector<TemplateMap>& kTemplateHWL = object_template_manager_->TemplateHWL();
for (auto& obj : frame->detected_objects) {
// 目标框信息3D size按照“lwh”排列
float volume_object = obj->size[0] * obj->size[1] * obj->size[2];
ADEBUG << "Det " << frame->frame_id << " (" << obj->id << ") "
<< "ori size:" << obj->size.transpose() << " "
<< "type: " << static_cast<int>(obj->sub_type) << " "
<< volume_object << " " << frame->data_provider->sensor_name();
base::CameraObjectSupplement& supplement = obj->camera_supplement;
// 通过体积限制长宽高
// 如果该障碍物类型可以通过模板调整尺寸
if (Contain(object_template_manager_->TypeRefinedByTemplate(), obj->sub_type)) {
float min_template_volume = 0.0f;
float max_template_volume = 0.0f;
auto min_tmplt = kMinTemplateHWL.at(obj->sub_type);
auto max_tmplt = kMaxTemplateHWL.at(obj->sub_type);
min_template_volume = min_tmplt[0] * min_tmplt[1] * min_tmplt[2];
max_template_volume = max_tmplt[0] * max_tmplt[1] * max_tmplt[2];
// 该障碍物的体积小于最小体积,或者该物体的高度小于模板的最小高度*0.9
if (volume_object < min_template_volume || obj->size[2] < (1 - ref_param_.height_diff_ratio()) * min_tmplt[0]) {
obj->size[0] = min_tmplt[2];
obj->size[1] = min_tmplt[1];
obj->size[2] = min_tmplt[0];
// 该障碍物的体积大于最大体积,或者该物体的高度大于模板的最小高度*1.1
} else if (volume_object > max_template_volume || obj->size[2] > (1 + ref_param_.height_diff_ratio()) * max_tmplt[0]) {
obj->size[0] = max_tmplt[2];
obj->size[1] = max_tmplt[1];
obj->size[2] = max_tmplt[0];
}
}
...
...
}
...
}总的来说,就是通过限制障碍物最大最小体积,上面代码还比较简单。object_template_manager_->TypeRefinedByTemplate()其实包含了所有类型,其定义如下:
std::vector<base::ObjectSubType> kTypeRefinedByTemplate = {
base::ObjectSubType::CAR, base::ObjectSubType::VAN,
base::ObjectSubType::BUS, base::ObjectSubType::TRUCK,
base::ObjectSubType::PEDESTRIAN, base::ObjectSubType::TRAFFICCONE,
base::ObjectSubType::CYCLIST, base::ObjectSubType::MOTORCYCLIST,
};4.2.2 地平面拟合修正障碍物模板对3Dbox
if (Contain(object_template_manager_->TypeRefinedByRef(), obj->sub_type)) {
std::string sensor = frame->data_provider->sensor_name();
std::vector<float> height;
// ymax -ymin = (1/z)(fy * h)
// 通过严格限制目标检测的类型->目标高度->深度信息
// z_obj为相机根据投影关系求出来的深度
double z_obj = frame->camera_k_matrix(1, 1) * obj->size[2] / (supplement.box.ymax - supplement.box.ymin);
// h from ground detection 地面估计初始化
SyncGroundEstimator(sensor, frame->camera_k_matrix, static_cast<int>(img_width_), static_cast<int>(img_height_));
auto& ground_estimator = ground_estimator_mapper_[sensor];
// 地平面方程为:a*ymax + b*(1/z) + c = 0
// l[3] 分别对应于a,b,c三个系数
float l[3] = { 0 };
// 其实这里是调用上一帧地面检测得到的地平面方程
if (ground_estimator.GetGroundModel(l)) {
// 先求出逆深度1/z,再求z
double z_ground_reversed = (-l[0] * supplement.box.ymax - l[2]) * common::IRec(l[1]);
double z_ground = common::IRec(z_ground_reversed);
// 为什么取最大值?
z_ground = std::max(z_ground, z_obj);
// 从新调整了k2。k2 = z/fy
float k2 = static_cast<float>(z_ground / frame->camera_k_matrix(1, 1));
// 根据障碍物深度信息按照相机投影关系,重新计算物体3D高度
float h = k2 * (supplement.box.ymax - supplement.box.ymin);
h = std::max(std::min(h, kMaxTemplateHWL.at(obj->sub_type).at(0)),kMinTemplateHWL.at(obj->sub_type).at(0));
height.push_back(h);
...
...
}上面地平面检测ground_estimator.GetGroundModel(l)其实只调用了上一帧地平面检测的结果,得到地平面方程系数,然后求取该障碍物深度,再通过相机投影模型得到障碍物高度。上面代码的公式推导如下:

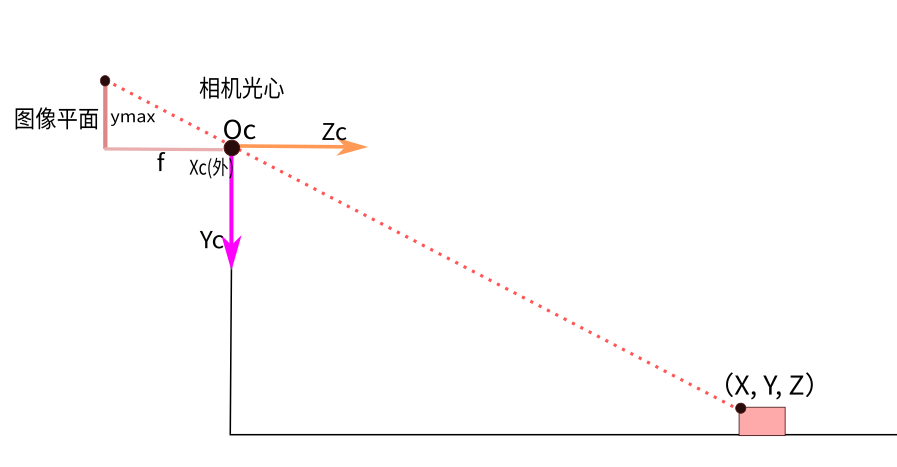
根据相机投影模型可知:
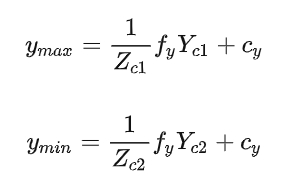
假设障碍物底部和顶部处于同一深度,也就是=,两式相减可得障碍物3D高度和图像高度的关系如下:
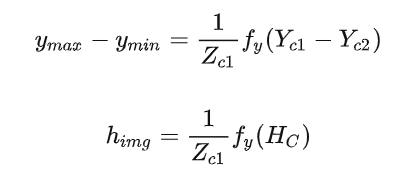
其中:表示障碍物在相机坐标系下的高度,也就是实际高度;表示障碍物在图像片上的高度。
具体的地平面检测算法其实是在OMTObstacleTracker::Associate3D()中调用reference_的UpdateReference()成员函数,具体为reference_.UpdateReference(frame, targets_),代码如下:
void ObstacleReference::UpdateReference(const CameraFrame* frame, const EigenVector<Target>& targets)
{
// 传感器名字
std::string sensor = frame->data_provider->sensor_name();
// 初始化地对应相机的平面检测器,已经初始化了则不需要重新初始化
SyncGroundEstimator(sensor, frame->camera_k_matrix,static_cast<int>(img_width_), static_cast<int>(img_height_));
auto& ground_estimator = ground_estimator_mapper_[sensor];
auto& refs = reference_[sensor]; // 该传感器的参考
auto& ref_map = ref_map_[sensor]; // 该传感器的参考
if (ref_map.empty()) {
ref_map = init_ref_map_;
}
for (auto&& reference : refs) {
reference.area *= ref_param_.area_decay();
}
for (auto&& target : targets) {
// ############# 一些必要的判断 ##########################
if (!target.isTracked()) {
continue;
}
if (target.isLost()) {
continue;
}
auto obj = target[-1]->object;
if (!Contain(object_template_manager_->TypeCanBeRef(), obj->sub_type)) {
continue;
}
auto& box = obj->camera_supplement.box;
if (box.ymax - box.ymin < ref_param_.min_allow_height()) {
continue;
}
if (box.ymax < frame->camera_k_matrix(1, 2) + 1) {
continue;
}
if (box.ymax >= img_height_ + 1) {
AERROR << "box.ymax (" << box.ymax << ") is larger than img_height_ + 1 ("
<< img_height_ + 1 << ")";
return;
}
if (box.xmax >= img_width_ + 1) {
AERROR << "box.xmax (" << box.xmax << ") is larger than img_width_ + 1 ("
<< img_width_ + 1 << ")";
return;
}
float x = box.Center().x;
float y = box.ymax;
AINFO << "Target: " << target.id << " can be Ref. Type: " << base::kSubType2NameMap.at(obj->sub_type);
// #######################################
// ############### 第一部分:找到参考 ###################
// init_ref_map_做了25倍的下采样,这里将2dbox坐标除以25,得到box在下边框中心点
int y_discrete = static_cast<int>(y / static_cast<float>(ref_param_.down_sampling()));
int x_discrete = static_cast<int>(x / static_cast<float>(ref_param_.down_sampling()));
if (ref_map[y_discrete][x_discrete] == 0) { // 上边中心在地面位置
Reference r;
r.area = box.Area(); // 2d box 面积
r.ymax = y; // ymax
// ymax - ymin = (1/z) *(fy*h)
r.k = obj->size[2] / (y - box.ymin); // r.k = z/fy
refs.push_back(r);
// ref_map保存的是该传感器的第几个参考
ref_map[y_discrete][x_discrete] = static_cast<int>(refs.size());
}
// 如果同一个位置有两个物体,保存面积大的box作为ref
else if (ref_map[y_discrete][x_discrete] > 0) {
// index表示保存在refs的序号(第几个参考)
int index = ref_map[y_discrete][x_discrete] - 1;
// 更新面积大的参考
if (box.Area() > refs[index].area) {
// 更新参考
refs[index].area = box.Area();
refs[index].ymax = y;
refs[index].k = obj->size[2] / (y - box.ymin);
}
}
}
// ############### 第二部分:车道地平面拟合 ###################
// refs.size()表示有多少参考物,保存ymax和逆深度,为地平面拟合做准备
std::vector<float> vd_samples(static_cast<int>(refs.size() * 2), 0);
int count_vd = 0;
for (auto&& reference : refs) {
// reference.k = z/fy
// z_ref = z 为物体深度
float z_ref = reference.k * frame->camera_k_matrix(1, 1);
vd_samples[count_vd++] = reference.ymax; // 保存ymax
vd_samples[count_vd++] = common::IRec(z_ref); // 1/z 称为逆深度
}
int count_samples = static_cast<int>(vd_samples.size() / 2);
// calibration_service:车道线检测标定服务,可以计算相机相对于地面pitch角和高度
if (count_samples > ground_estimator.get_min_nr_samples() && frame->calibration_service != nullptr) {
// 地平面拟合
ground_estimator.DetetGround(frame->calibration_service->QueryPitchAngle(),
frame->calibration_service->QueryCameraToGroundHeight(),
vd_samples.data(), count_samples);
}
}上面代码分两把部分:
1.对于每个target中最近检测到的物体,如果是可以参考的类型(CAR,VAN),同时其box的高度大于50,box的底边位置大于内参矩阵中的c_y(即box尽可能位于图像底部),此时该target可以被参考。将该box的底边中心点也进行下采样(y_discrete=y/25,x_discrete=x/25),这样可以与ref_map的尺寸对应。如果此中心点所对应的ref_map为0(即该点对应的参考图第一次被使用),将其对应的Reference信息push到数组reference_中存储,并将ref_map中对应位置置为当前refs存储的元素数否则,若该点对应的ref_map大于零 (表示该点已经存在某个物体,其中存储的值为当时的refs中对应的索引),同时此时box的area大于之前存在的 reference 的 area,则将属性进行替换。图3形象的解释了这部分内容,红色区域表示可到平面在图像中的先验位置,不同颜色的方框表示障碍物,其中紫色圆圈点表示检测到的物体底部中心点在ref_map的位置。
参考

frame->calibration_service->QueryPitchAngle()和frame->calibration_service->QueryCameraToGroundHeight()为调用相机的calibration服务,求取相机pitch角和高度,这里先留个坑,具体内容放在车道线检测章节介绍。这里解释以下ymax与逆深度和车道平面的关系,如图4,下面是推导过程

根据相机投影模型可得:
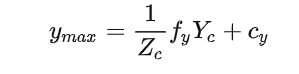
即
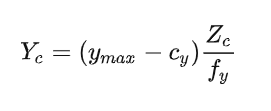
将其带入平面方程中可得
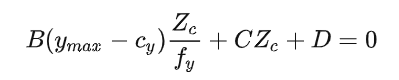
同时除以 整理可得
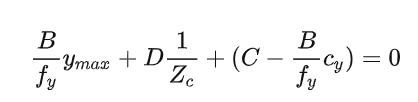
该平面方程对应于
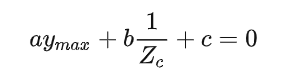
所以对于每一障碍物来说,其对应的ymax和逆深度都应该满足平面方程。当该帧有多个障碍物(理论大于3个),就可以求解其方程系数。求解方法可以是矩阵求逆,也可以通过最小二乘求解。ground_estimator.DetetGround()采用RANSAC算法去除外点+最小二乘完成平面拟合,具体代码解释可以参考大佬博客
4.2.3 地平面拟合修正障碍物模板对3Dbox
通过在线相机标定服务获取平面深度(标定服务代码留坑,放在车道线检测章节介绍...)。这部分代码为:
// 通过相机标定求取深度
if (frame->calibration_service != nullptr) {
double z_calib = 0.0;
bool success = frame->calibration_service->QueryDepthOnGroundPlane(
static_cast<int>(supplement.box.Center().x),
static_cast<int>(supplement.box.ymax), &z_calib);
if (success) {
z_calib = std::max(z_calib, z_obj);
float k2 = static_cast<float>(z_calib / frame->camera_k_matrix(1, 1));
float h = k2 * (supplement.box.ymax - supplement.box.ymin);
h = std::max(std::min(h, kMaxTemplateHWL.at(obj->sub_type).at(0)),
kMinTemplateHWL.at(obj->sub_type).at(0));
height.push_back(h);
} else {
height.push_back(kMaxTemplateHWL.at(obj->sub_type).at(0));
}
Eigen::Vector4d plane_param;
frame->calibration_service->QueryGroundPlaneInCameraFrame(&plane_param);
}4.2.4 从历史参考中求取高度
核心逻辑是找到与当前物体高度最相近的reference,认为该该物体的高度就是reference的高度。代码如下:
// h from history reference vote
// 从历史参考中求取高度
if (obj->sub_type != base::ObjectSubType::TRAFFICCONE || height.empty()) {
float cy = frame->camera_k_matrix(1, 2);
cy = std::min(supplement.box.ymax - 1, cy);
// 遍历所有在reference
for (auto&& reference : reference_[sensor]) {
// pick out the refs close enough in y directions
float dy = std::abs(reference.ymax - supplement.box.ymax);
float scale_y = (supplement.box.ymax - cy) / (img_height_ - cy);
float thres_dy = std::max(static_cast<float>(ref_param_.down_sampling()) * scale_y,
static_cast<float>(ref_param_.margin()) * 2.0f);
// 找到与当前物体高度最相近的reference,认为该该物体的高度就是reference的高度
if (dy < thres_dy) {
float k2 = reference.k;
k2 *= (reference.ymax - cy) / (supplement.box.ymax - cy);
float h = k2 * (supplement.box.ymax - supplement.box.ymin);
// bounded by templates
h = std::max(std::min(h, kMaxTemplateHWL.at(obj->sub_type).at(0)),
kMinTemplateHWL.at(obj->sub_type).at(0));
height.push_back(h);
}
}
height.push_back(obj->size[2]);
}4.2.5 处理4种方法求出的高度
障碍物的最终高度其实是这四中方法求出的中位数,最后按比例计算3Dbox的长和宽(wl),至此终于讲完了障碍物尺寸调整部分。
// 多种方法求出物体高度的中位数
std::sort(height.begin(), height.end());
int nr_hs = static_cast<int>(height.size());
float h_updated = height[nr_hs / 2]; // 多种方法计算出高度,取中位数
AINFO << "Estimate " << h_updated << " with " << height.size();
obj->size[2] = std::min(h_updated, kMaxTemplateHWL.at(obj->sub_type).at(0));
obj->size[2] = std::max(obj->size[2], kMinTemplateHWL.at(obj->sub_type).at(0));
std::vector<float> height_error(kTemplateHWL.size(), 0);
float obj_h = obj->size[2];
for (size_t i = 0; i < height_error.size(); ++i) {
// 统计高度误差
height_error[i] = std::abs(kTemplateHWL[i].at(obj->sub_type).at(0) - obj_h);
}
// 取出高度误差最小值
auto min_error = std::min_element(height_error.begin(), height_error.end());
// 找到对应的index
auto min_index = std::distance(height_error.begin(), min_error);
// 取出该类别障碍物的尺寸
auto& tmplt = kTemplateHWL.at(min_index).at(obj->sub_type);
// l和w进行等比缩放
float scale_factor = obj->size[2] / tmplt[0];
obj->size[1] = tmplt[1] * scale_factor;
obj->size[0] = tmplt[2] * scale_factor;
}4.3 关联匹配
计算当前帧所有检测到的障碍物和target中已经关联匹配上的的的障碍物之间的图像特征相似度、运动相似度、形状相似度和iou相似度,将得分加权,并根据最后的得分判断是否关联匹配成功。总体流程在GenerateHypothesis()方法中:
void OMTObstacleTracker::GenerateHypothesis(const TrackObjectPtrs &objects) {
std::vector<Hypothesis> score_list;
Hypothesis hypo;
for (size_t i = 0; i < targets_.size(); ++i) {
ADEBUG << "Target " << targets_[i].id;
for (size_t j = 0; j < objects.size(); ++j) {
hypo.target = static_cast<int>(i); // target id
hypo.object = static_cast<int>(j); // 障碍物在该帧的编号
// 计算前帧的第j个物体和第i个target(轨迹)的图像特征相似度
float sa = ScoreAppearance(targets_[i], objects[j]);
// 计算当前帧的第j个物体2Dbox中心和第i个target的运动相匹配度,假设物体为匀速直线运动。
// 采用的是卡尔曼滤波器
float sm = ScoreMotion(targets_[i], objects[j]);
// 2Dbox形状相似度,使用一阶低通滤波器,如果能关联匹配上形状变化应该不大。
// 返回值为负数?
float ss = ScoreShape(targets_[i], objects[j]);
// 计算障碍物2Dbox和第target中已经匹配上的障碍物间的IOU。和ScoreMotion使用同一个卡尔曼滤波器
float so = ScoreOverlap(targets_[i], objects[j]);
// 四个关联匹配得分加权得到匹配score
if (sa == 0) { // 如果没有特征提取功能
hypo.score = omt_param_.weight_diff_camera().motion() * sm +
omt_param_.weight_diff_camera().shape() * ss +
omt_param_.weight_diff_camera().overlap() * so;
} else {
// 计算匹配得分
hypo.score = (omt_param_.weight_same_camera().appearance() * sa +
omt_param_.weight_same_camera().motion() * sm +
omt_param_.weight_same_camera().shape() * ss +
omt_param_.weight_same_camera().overlap() * so);
}
int change_from_type = static_cast<int>(targets_[i].type);
int change_to_type = static_cast<int>(objects[j]->object->sub_type);
// 通过预先设置一些参数,排除跟踪错误的情况
// 当前是追踪列表目标为车,关联时候为人的概率,这种变化很大,所以应该给大权重值。
// 反之如果追踪列表目标为轿车,关联时候为SUV的概率,这种变化相对较小,所以可以给予较小的权重值。
hypo.score += -kTypeAssociatedCost_[change_from_type][change_to_type];
ADEBUG << "Detection " << objects[j]->indicator.frame_id << "(" << j
<< ") sa:" << sa << " sm: " << sm << " ss: " << ss << " so: " << so
<< " score: " << hypo.score;
// target_thresh = 0.6
// 如果匹配得分小于阈值认为没有匹配上。
if (sm < 0.045 || hypo.score < omt_param_.target_thresh()) {
continue;
}
score_list.push_back(hypo);
}
}
}4.3.1 相似度计算
从最后开始遍历,计算但前帧检测到的障碍物和target中所有已经匹配上的所有障碍物相似度,然后求取平均值。
这点好理解:如果当前的障碍物要想和该target关联上,则要和target中关联匹配上的障碍物都相似。
float OMTObstacleTracker::ScoreAppearance(const Target &target, TrackObjectPtr track_obj) {
float energy = 0.0f;
int count = 0;
auto sensor_name = track_obj->indicator.sensor_name;
// target.Size()返回的是已经关联匹配上的障碍物的数量,tracked_objects.size()
for (int i = target.Size() - 1; i >= 0; --i) {
// 比较细节,不同相机检测的障碍物不参与关联匹配
if (target[i]->indicator.sensor_name != sensor_name) {
continue;
}
PatchIndicator p1 = target[i]->indicator;
PatchIndicator p2 = track_obj->indicator;
// 在blob快中获取相似度
energy += similar_map_.sim(p1, p2);
count += 1;
}
return energy / (0.1f + static_cast<float>(count) * 0.9f);
}4.3.2 2D Box运动相似度计算
target.image_center被定义为KalmanFilterConstVelocity,该类为卡尔曼滤波器的实现。最后的得分是通过高斯分布衡量target中已经跟踪上的2DBox中心点和当前障碍物2Dbox中心点坐标相似性,值得注意的是:target.image_center.get_state()直接获取了状态量,其状态量为当前帧OMTObstacleTracker::Predict()方法运行结束后的状态预测值。最后用高斯分布衡量预测中心点和观测中心点是否距离较近。
float OMTObstacleTracker::ScoreMotion(const Target &target,TrackObjectPtr track_obj) {
Eigen::Vector4d x = target.image_center.get_state();
float target_centerx = static_cast<float>(x[0]);
float target_centery = static_cast<float>(x[1]);
base::Point2DF center = track_obj->projected_box.Center();
base::RectF rect(track_obj->projected_box);
// 高斯分布衡量中心点是否较近
float s = gaussian(center.x, target_centerx, rect.width) * gaussian(center.y, target_centery, rect.height);
return s;
}4.3.3 形状相似度相似度计算
target.image_wh被定义为FirstOrderRCLowPassFilte类,为一阶RC低通滤波器。原因在于2Dbox的尺寸变化应该平滑过度。
float OMTObstacleTracker::ScoreShape(const Target &target,TrackObjectPtr track_obj) {
Eigen::Vector2d shape = target.image_wh.get_state();
base::RectF rect(track_obj->projected_box);
// 计算形状差异得分
float s = static_cast<float>((shape[1] - rect.height) *
(shape[0] - rect.width) / (shape[1] * shape[0]));
return -std::abs(s);
}4.3.4 IOU相似度相似度计算
对于运动障碍物,如果要想和该target关联上,则该障碍物要和target中关联匹配上的最新障碍物的预测2Dbox尽可能重合。由于自身车辆要移动,对于静止的障碍物可能会关联不上,所以要有其他类型的得分计算。
float OMTObstacleTracker::ScoreOverlap(const Target &target, TrackObjectPtr track_obj) {
Eigen::Vector4d center = target.image_center.get_state();
Eigen::VectorXd wh = target.image_wh.get_state();
base::BBox2DF box_target;
box_target.xmin = static_cast<float>(center[0] - wh[0] * 0.5);
box_target.xmax = static_cast<float>(center[0] + wh[0] * 0.5);
box_target.ymin = static_cast<float>(center[1] - wh[1] * 0.5);
box_target.ymax = static_cast<float>(center[1] + wh[1] * 0.5);
auto box_obj = track_obj->projected_box;
// iou 计算
float iou = common::CalculateIOUBBox(box_target, box_obj);
return iou;
}4.3.5 状态转移的处理
通过预先设置一些参数,排除跟踪状态发生错误的情况。当前是追踪列表目标为车,关联时候为人的概率,这种变化很大,所以应该给大权重值。反之如果追踪列表目标为轿车,关联时候为SUV的概率,这种变化相对较小,所以可以给予较小的权重值。
apollo中得分score会减去对于类型转换的cost,kTypeAssociatedCost_为:
0.0 0.0 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0
0.0 0.0 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0
0.0 0.0 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0
1.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 1.0 0.2 1.0 1.0
1.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 1.0 0.2 1.0 1.0
1.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 1.0 0.2 1.0 1.0
1.0 1.0 1.0 0.0 0.0 0.0 0.0 1.0 1.0 0.2 1.0 1.0
1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.2 0.1 1.0
1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.2 0.1 1.0
1.0 1.0 1.0 0.2 0.2 0.2 0.2 0.2 0.2 0.0 0.2 1.0
1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.1 0.1 0.2 0.0 1.0
0.0 0.0 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.04.3.6 判断是否有新的target
判断是否有新的target。判断标准:1.当前障碍物没有和历史target关联匹配上(当前target中的物体要有三帧匹配上);2.障碍物和历史target中的障碍物没有重叠或重叠部分较小(iou小于阈值)。代码为:
int new_count = CreateNewTarget(track_objects);4.3.7 类型更新和状态更新
具体的逻辑为:遍历targets,统计每个target是否跟丢。如果跟丢帧数大于阈值,将target中的跟踪到的物体tracked_objects清零。
如果没有跟丢:
1.可能出现类型转移错误的情况(对应于target.UpdateType(frame)):
取出target中最新加入的跟踪到(关联匹配成功)的物体,计算该障碍物的高度和该类模板
kMidTemplateHWL的高度的差,用高斯分布来拟合,差别越大概率值越小,差别越小概率越大。得分保存在type_probs中。type_probs表示该target中的跟踪的物体最有可能是哪一类目标。根据type_probs调整该障碍物类别和尺寸。
利用调整后的尺寸作为测量值,使用均值滤波器重新跟新目标框
2.一阶低通滤波修正每个target中最后一个目标box长宽,卡尔曼滤波更新box中心点位置(对应于target.Update2D(frame))。
总体代码代码如下,由于比较简单细节不再展示。
for (auto &target : targets_) {
if (target.lost_age > omt_param_.reserve_age()) {
AINFO << "Target " << target.id << " is lost";
target.Clear();
} else {
// 更新目标类型,使用均值滤波器重新更新目标框大小
target.UpdateType(frame);
// 均值滤波修正box长宽,卡尔曼滤波修正box中心点位置
target.Update2D(frame);
}
}5 障碍物3D关联匹配Associate3D
3D关联匹配比2D关联匹配简单,逻辑大致都差不多,难点在于参考的更新:reference_.UpdateReference(frame, targets_),这部分主要功能是估计车道平面方程,在2D关联匹配中已经讲过。
6 状态预测
当新帧到来之前,先要对已经跟踪上的target中的障碍物状态进行预测,其实也是调用各类滤波器的Predict()方法。值得注意的是,在Apollo中不同的状态如:2Dbox尺寸、2Dbox中心点、3Dbox尺寸,33Dbox中心、航向角、方向向量和实际速度等都采用不同类别的滤波器,更符合实际场景。
bool OMTObstacleTracker::Predict(const ObstacleTrackerOptions &options, CameraFrame *frame) {
for (auto &target : targets_) {
target.Predict(frame);
auto obj = target.latest_object;
frame->proposed_objects.push_back(obj->object);
}
return true;
}7 总结
至此跟踪模块的大部分细节已经介绍完了,还有小部分细节相对简单,稍微花点时间就能搞定。除此之外,没有提到的重点就属各种滤波器的实现。这部分有时间在写一篇序章吧。总的来说收获如下:
障碍物尺寸和类型修正方法
不同状态使用不同的滤波器
3D的关联匹配
车道平面拟合
检测模块和跟踪模块既相分离,又相耦合
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 940
940




 到【灌水乐园】发言
到【灌水乐园】发言







