



作者 | FudanMagicLab 编辑 | 自动驾驶与AI
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【占用网络】技术交流群
后台回复【OccupanyNetwork】获取Occupany Network相关论文干货资料!
PART
01
How to get Occupancy Label?
1.1
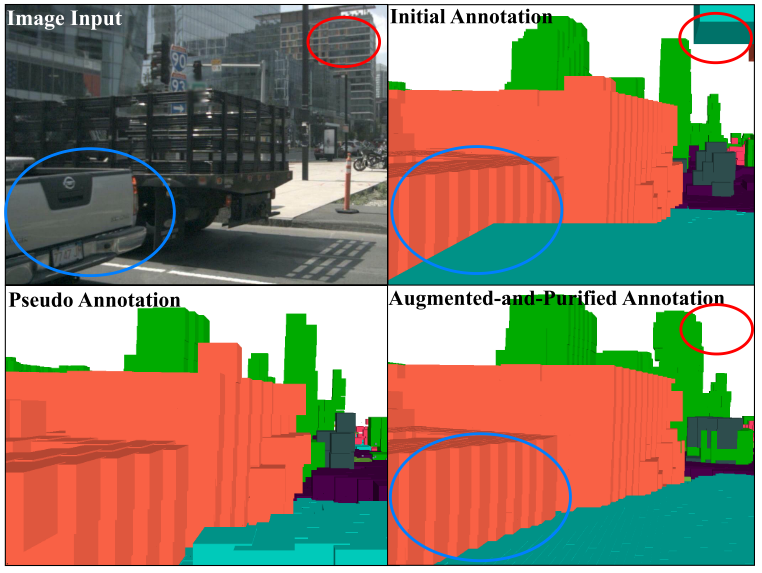
[OpenOccupancy] AAP
用{3D目标检测label, 3D语义分割label}生成{occupancy label, semantic label} of voxel,AAP(Augmenting And Purifying) 的流程:
Step 1: 将多帧静态点云变换到世界坐标系下,将多帧移动的点云变换到相应 bounding box的坐标系下,然后将它们栅格化为初步的 ,对于一些没有语义标签的点云给一个pseudo的semantic label (self-training)。
Step 2: 在 数据上训练一个多模态的coarse的 (不计算之前无语义点云的semantic loss), 的 coarse occupancy label 由预训练模型提供。
Step 3: , 用 填补 中空的格子。
Step 4: 人工purify一下前面生成的occupancy label。
1.2
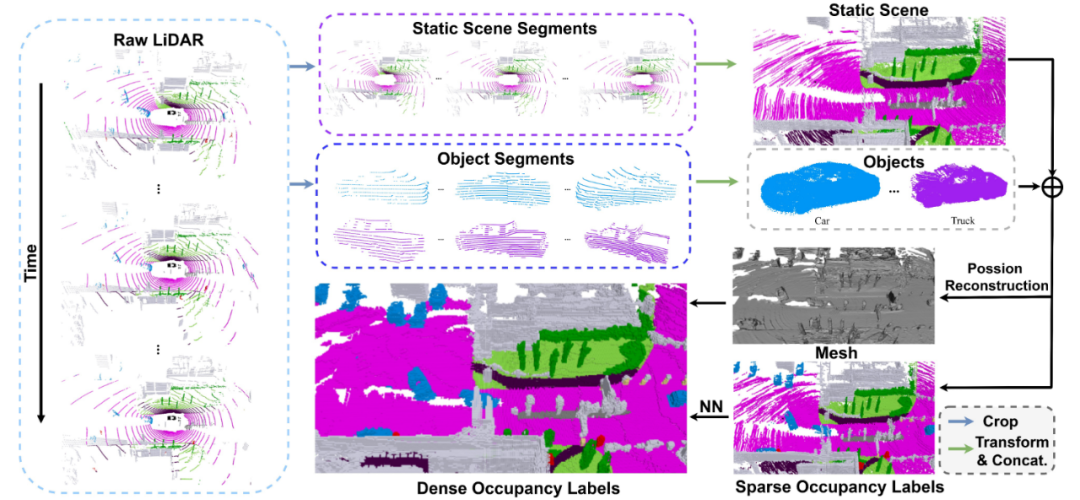
[SurroundOcc] Dense occupancy ground truth generation
用{3D目标检测label, 3D语义分割label}生成{occupancy label,semantic label} of voxel:
Step 1: 根据目标检测label将点云分为static和dynamic,并分别累计多帧静态点云和动态点云。
Step 2: 累计的多帧点云还存在hole,因此用泊松重建的方法得到更稠密的volumetric occupancy label。
Step 3: 没有语义信息的grid选择距离最近的带有语义标注的grid作为自己的semantic label。
PART
02
Sensor data → OccFeature
(Encoder)
2.1 [TPVFormer] HCAB(Hybrid Cross Attention Block) + HAB(Hybrid Attention Block)

Input: Multi-RGB
Output: TPV Feature
(这篇文章不涉及gt occupancy label,是相对早一些的工作,只用点云语义信息作为标注,但是能展示出很好的occupancy推理效果)
Step 1: Employ an image backbone network to extract multi-scale features for multi-camera images.
Step 2: 使用cross-attention将2D feature lift 到 3D feature。
Step 3: 使用HyBird-Attention跨视图融合feature。
(Cross-Attention就是在不同尺度上的特征层做self-atten,HyBird-Attention是TPV三个特征之间做self-atten,且全部使用deformable transformer来减少计算量。)
2.2 [OpenOccupancy]
点云/Multi-RGB/(点云+Multi-RGB) → Feature
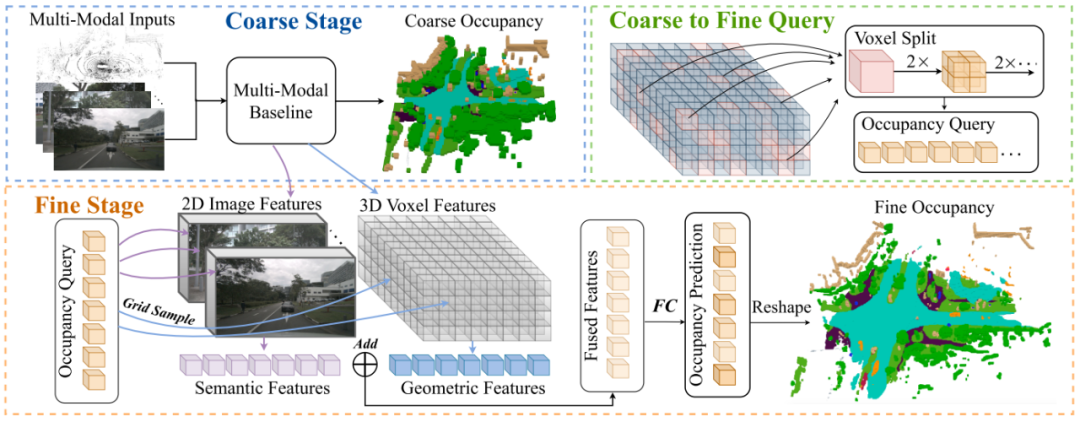
Lidar-based pipeline
Input:
Output:
Step 1: 雷达点云经过3D sparse Convolution得到voxelized features。
Step 2: voxelized features经过3D Convolution得到multi-scale voxel features ( )。
Step 3:多尺度的feature经过上采样得到:
( )。
Camera-based pipeline
Input: Multi-RGB
Output:
Step 1: Resnet提取6张图的feature
Step 2: 使用2D to 3D transform将2D feature变换到车身坐标系下的3D feature。
Multi-model based pipeline
Input: Multi-RGB + Lidar PointCloud
Output:
Step 1: Adaptive Fusion Module
都过一个3D卷积计算这俩的类似权重关系的值
Step 2: 类似加权求和
3D Sparse Convolution:
由于点云是稀疏的,3D稀疏卷积是通过建立哈希表,保存特定位置的计算结果实现卷积操作: (1) 依据常规卷积流程记录有值生成的output并记录相应的位置索引作为 ,每个离散的点都对应一张 , 将它们取并集,得到 哈希表。(2) 建立Rulebook: Rulebook主要实现输入索引到输出索引的映射。记录离散的输入到底只需要卷积核的哪个参数,并将对应的offset写入GetOffset()表中,整体实现的就是根据输入的索引找到其在卷积核中对应权重的位置索引的流程。
2.3 [SurroundOcc] ResNet101 + 2D-3D spatial attention
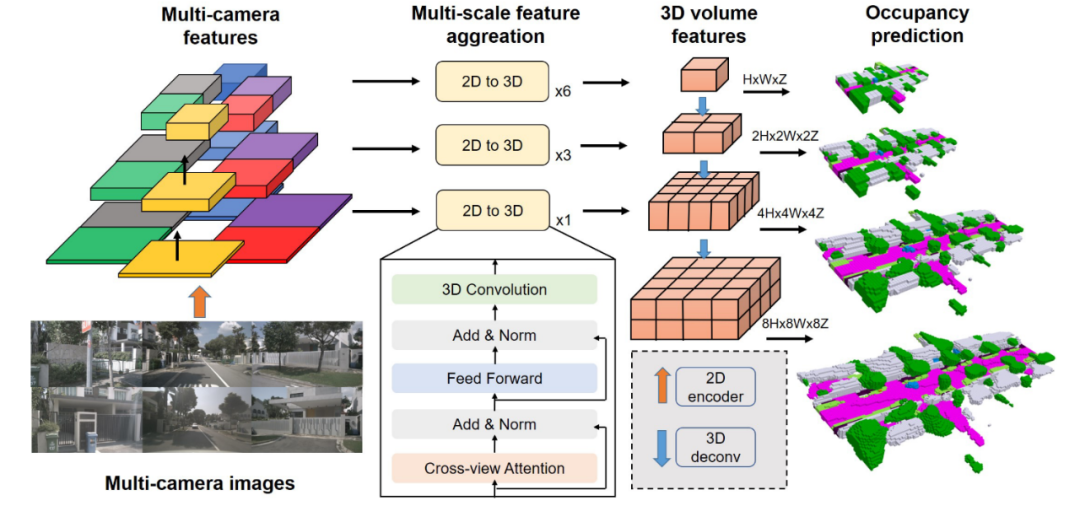
Input:
Output:
Step 1: N张图分别过Resnet101提feature, 提M个Level,最终得到M×N的features(FPN)。
Step 2: 设计了一种 2D-3D 类似U-Net的结构,把UNet的Conv Block换成了
空间注意力(Spatial Attention), 将M×N的 feature 变成 3D feature, 记作volume feature。(在每一个Level作spatial cross attention)Step 3: 将输出的3D volume feature(H×W×Z) upsample得到多种scale的3D volume feature:
{H×W×Z, 2H×2W×2Z, ... 8H×8W×8Z}空间注意力(Spatial Attention):
类似于BEVFormer中的空间注意力, 由于多摄像头3D感知的输入规模很大,普通多摄像头注意力的计算成本非常高。因此使用基于 Deformable attention的Spatial Attention模块:
2.4 [OccFormer] LLS’s method + Dualpath Encoder
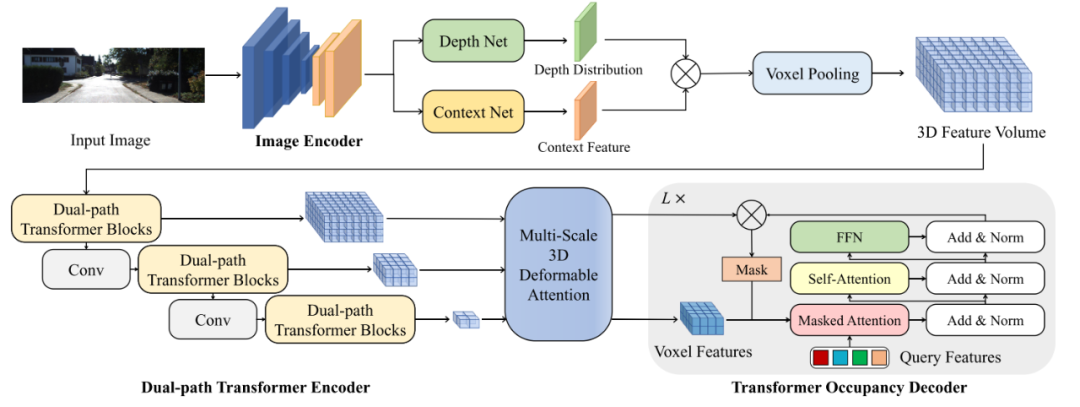
Input:
Output:
Step 1: Image Encoder提2D features (N个相机,C个Channel)
Step 2: Image-to-3D transformation: 将2D feature lift到3D volume(借鉴了LLS的方案)。
Step 3: 多帧2D feature得到上下文信息 与深度分布,最终生成 。
PART
03
OccFeature → Occupancy
(Decoder)
相关文章都没有详细介绍这一部分,我从文章中了解到的信息:
OpenOccupancy: 只在图片中写了个FC作为occupancy head。
TPVFormer: 为了预测semantic occupancy,对TPV feature求和以后,过一个轻量级的occupancy head
PART
04
Summary
Sensor→ Feature:
提取点云feature的工作较少,用的是3D稀疏卷积。分别提取多图像feature大多使用的ResNet提取multi-scale的2D feature,主要区别在于之后“如何将2D feature们lift成3D feature”与“如何融合每张图的feature”: (1) TPVFormer并没有3D Feature,是用3张BEV feature(TPV Feature)存储的,同时在三张feature间做了attention; (2) SurroundOcc的方案是“UNet+Spatial Attention”, UNet的多尺度跳跃连接可以帮助网络学习低级细粒度特征,多尺度的监督学习可以帮助模型更好的收敛; (3) OpenOccupancy的方案是“2D to 3D transform”,这个是BEVFusion中的方案; (4) OccFormer的方案借鉴了LLS的方法,得到了3D Feature Volume;
资源消耗:
method train infer(1600×900) SurroundOcc 8×3090,
2.5days1×3090,
memory: 12.4G
latency: 0.73sTPVFormer --- 1×3090,
memory: 5.1G,
latency: 0.32sOpenOccupancy 8×A100
20~40h---
参考文献
[1] MonoScene,CVPR2022: https://github.com/astra-vision/MonoScene
[2] SurroundOcc: https://github.com/weiyithu/SurroundOcc
[3] TPVFormer,CVPR2023:https://github.com/wzzheng/TPVFormer
[4] OpenOccupancy: https://github.com/JeffWang987/OpenOccupancy
[5] Semantic KITTI: http://semantic-kitti.org/
[6] OccFormer: https://github.com/zhangyp15/OccFormer
[7] BEVFusion,ICRA2023: https://github.com/mit-han-lab/bevfusion
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 5218
5218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









