 Dropout新发现:不仅防过拟合,还能减轻欠拟合
Dropout新发现:不仅防过拟合,还能减轻欠拟合




编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
本文目录
1 Dropout 不仅可以防止过拟合,也可以减小欠拟合?
(来自 FAIR,Meta AI,UC Berkeley,MBZUAI,DenseNet,ConvNeXt 第一作者)
1 Dropout Reduces Underfitting 论文解读
1.1 重新审视过拟合和欠拟合
1.2 Dropout 的新困境
1.4 Dropout 的新困境
1.4 背景和动机
1.5 Dropout 如何解决欠拟合问题
1.6 Early Dropout
1.7 Early Dropout 实验结果
1.8 Late Dropout 实验结果
1.9 下游任务实验结果
Hinton 等人在2012年提出 Dropout[1],作为一种防止神经网络过拟合的正则化器,已经经受住了时间的考验。在现代的背景下,随着 AIGC 技术的发展,训练数据量暴增,很多时候我们需要面对的反而是模型复杂度远低于数据复杂度而导致的欠拟合问题。
来自 FAIR,Meta AI,UC Berkeley,MBZUAI 的研究员们继续对 Dropout 进行了探索,证明了在训练开始时使用 Dropout 也可以缓解欠拟合。
作者发现 Dropout 在训练的早期阶段减少了 mini-batch 梯度的方向差异,并有助于将小 mini-batch 梯度与整个数据集的梯度对齐。这有助于抵消 SGD 的随机性,并限制单个 mini-batch 对模型训练的影响。
基于这个发现,作者找到了一个针对模型出现欠拟合问题时的解决方案,即:Early Dropout。这个方法的意思是,只在训练的初始阶段使用 Dropout,训练一段时间之后不用了。与没有 Early Dropout 的模型相比,Early Dropout 模型的最终训练损失更低。作者也在很多模型中证明了 Early Dropout 是解决模型欠拟合问题的手段。
1 Dropout 不仅可以防止过拟合,也可以减小欠拟合?
论文名称:Dropout Reduces Underfitting
论文地址:
https://arxiv.org/pdf/2303.01500.pdf
1.1 重新审视过拟合和欠拟合
要研究这个文章,首先要了解机器学习中的过拟合和欠拟合。
这里大家可以参考G-kdom:欠拟合、过拟合及如何防止过拟合(https://zhuanlan.zhihu.com/p/72038532)和过拟合与欠拟合_Minouio的博客-优快云博客(https://link.zhihu.com/?target=https%3A//blog.youkuaiyun.com/qq_42012732/article/details/107318550)的介绍,本小节也是基于这两篇博客介绍一下:
我们常说的过拟合和欠拟合,就是指一个机器学习模型,在一定的训练数据上训练到一定程度时所呈现的状态,是对当前参数下的模型性质的描述。
欠拟合:
欠拟合,讲得通俗一点,就是:小的模型被用在了大的数据集上,即:模型的复杂度相比于数据集的复杂度低了。模型太弱,相比而言的数据量太多。不足的模型参数量使得模型的拟合能力受限,没法适应这么多的训练数据。
欠拟合的现象:
当模型出现欠拟合时,我们通常会感觉这个模型 "训练不动","不管怎么训练" 训练误差还是一直很大,降不下去。出现这样的现象就说明我们的模型可能欠拟合了。
欠拟合的原因和解决方案:
如前文所述,出现欠拟合的本质原因是小的模型被用在了大的数据集上。模型的复杂度不够,模型能力太弱,没法适应大量的数据。为了解决这个问题可以:
增加模型的复杂度: 简单来讲就是让模型的能力变得更强,我们可以加宽模型的特征,或者加深模型的层数来解决。
减小训练时使用的正则化: 正则化手段一般是用于防止模型过拟合的。现在模型的情况恰恰相反,出现了欠拟合,因此就不再需要那么多的正则化技术了。因此可以适当介绍正则化方法的使用。
过拟合:
过拟合,讲得通俗一点,就是:大的模型被用在了小的数据集上,即:模型的复杂度相比于数据集的复杂度高了。模型太强,相比而言的数据量太少。过剩的模型参数量使得模型的拟合能力太强,训练数据不足了。当一个模型被训练得非常好地拟合训练数据,但不适用于测试数据时,就会发生过拟合。
过拟合的现象:
当模型出现过拟合时,我们通常会感觉这个模型 "好像训练得太好了" ,但是 "在测试集上实际测试时却很拉胯" 。即:训练误差虽然很小,但是放到测试集上就发现性能特别差。出现这样的现象就说明我们的模型可能过拟合了。
过拟合的原因和解决方案:
如前文所述,出现过拟合的本质原因是大的模型被用在了小的数据集上。模型的复杂度过剩,模型能力太强,数据量太少了。为了解决这个问题首先就可以:
增加训练过程中使用的数据量: 这个增加过程中训练使用的数据量可以有两种实现方案。其一是直接扩大数据集,比如从 ImageNet-1K 换成 ImageNet-22K,但是实际我们往往受到资源限制有时候用不了太大的数据集。其二是使用更多的数据增强策略,数据增强也是一种正则化的技巧,一张图片,可以通过翻转,缩放,裁剪,变色,平移等方式变成标签不变的新图片。这种方法也属于变相扩充数据的手段。
降低模型的复杂度: 直接使用更小的模型,或者更简单的模型,削弱模型的复杂度。
正则化技巧: 比如 L1 / L2 正则化,Dropout,Early Stopping,Ensemble 等。Ensemble 和 Dropout 本质上都相当于是融合了多个不同的模型的预测结果,降低了算法对单个模型的依赖,从而减小过拟合。
1.2 防止过拟合的手段
a) Dropout
在每次训练迭代中,Dropout 层将每个神经元以一定的概率 pp 随机设置为0,其他的神经元都是活跃的,但是要按照 的系数缩放,以保持训练时的期望值和推理时的不变,使用公式表示就是:
训练时:
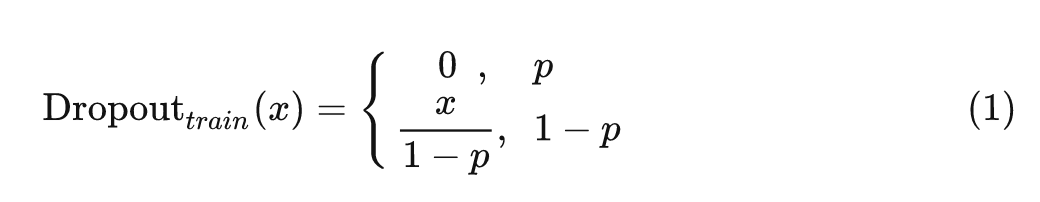
推理时:

PyTorch 实现 (摘自 4.6. 暂退法(Dropout) - 动手学深度学习 2.0.0 documentation(https://zh.d2l.ai/chapter_multilayer-perceptrons/dropout.html)):
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)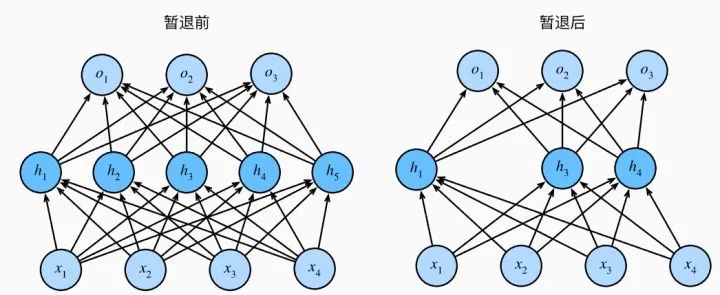
公式中的 pp 被称为是 Dropout rate,Dropout 可以被看作是很多模型的隐式集合。Dropout 已经在很多工作里面被用于防止神经网络的过拟合。
b) Stochastic depth
Dropout 有许多改进的版本,比较有名的是 DropConnect[2],Spatial Pyramid Pooling[3],DropBlock[4]等等。Stochastic depth[5]也是一种经典的 Dropout 的变体,也是一种神经网络的正则化技术。对于每个 mini-batch,网络随机选择一些块直接跳过,使模型更浅,因此得名 "Stochastic depth"。Stochastic depth 技术在现代的神经网络中十分常见,比如 DeiT,ConvNeXt 和 MLP-Mixer 都有使用。其中很多模型同时使用了 Stochastic depth 和 Dropout 技术。本质上 Stochastic depth 就可以看做是一种 Block 级别的 Dropout。
1.3 Dropout 的新困境
早期的模型,如 VGG 和 GoogleNet 使用0.5或更高的 Dropout rate。ViT 在 ImageNet 上使用0.1的 Dropout rate,并且在更大的 JFT-300M 数据集上进行预训练时不使用 Dropout。最近的多模态模型 CLIP[6] 或自监督视觉模型 MAE[7] 不使用 Dropout。这一趋势可能是由于数据集的规模不断增加。该模型对大量数据不容易过拟合。
随着更大数据集的不断诞生,以及 AIGC 的发展使得生产数据量迅速增长,可用数据的规模可能很快就会超过模型的能力。数据的复杂度以惊人的速度持续增长 (每天千万亿字节) ,但模型仍然需要在有限的物理设备上存储和运行,比如服务器、数据中心或移动电话。这就带来了模型训练的新困境,即:可用于训练的模型复杂度的增速不如数据的增速。
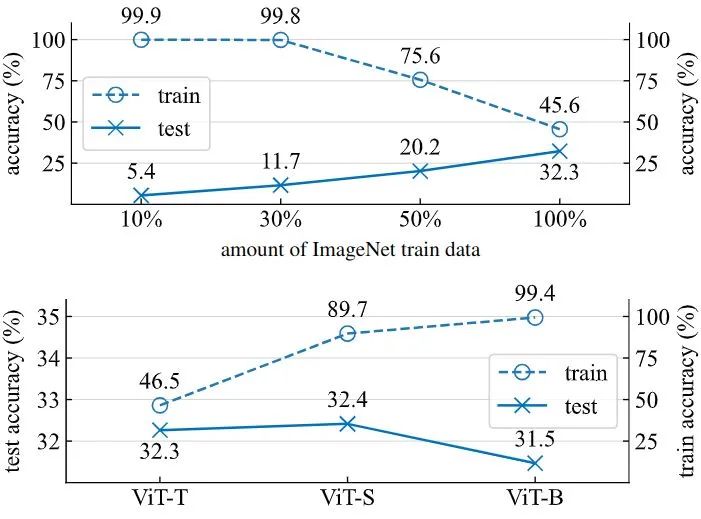
比如下图1是作者使用不同的 ImageNet-1K 训练数据量在不使用任何 Data Augmentation 的情况下训练 ViT-Tiny/32 4000 个 iteration 的结果。可以看到,在模型大小不变的前提下,训练的数据量越大,test accuracy 越高,证明过拟合现象在消失。在数据量大小不变的前提下,训练的模型越大,test accuracy 越低,证明过拟合现象在增强。
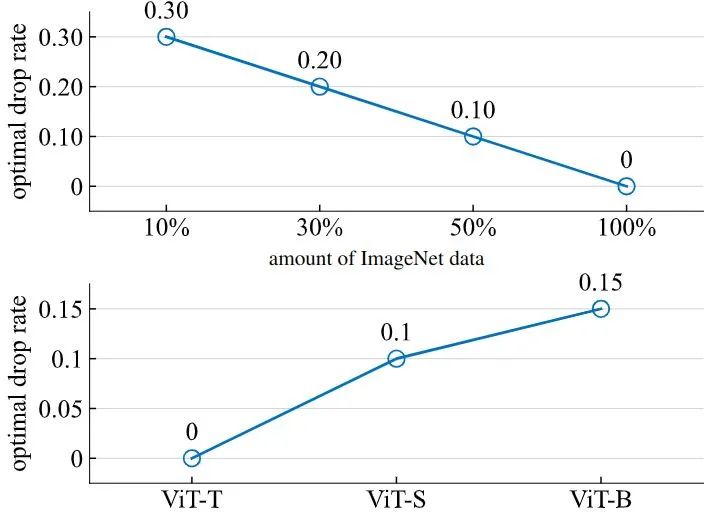
下图2是不同的 ImageNet-1K 训练数据量和不同的模型尺度下最优的 drop rate。可以看到,在模型足够大或者数据量足够小时,最佳的 drop rate 是0,这说明这种情况下使用 Dropout 可能没有必要了,并且反而可能会导致欠拟合问题。
因此新的困境是:未来的模型可能不再会遇到像之前模型那样的过拟合问题,更多的可能是恰恰相反的问题,即解决欠拟合。Dropout 等等用于解决过拟合的工具面对这样的新困境,需要探索如何借助它们来帮助模型更好地拟合大量数据,并减少欠拟合。
1.4 背景和动机
Dropout[1]作为一种防止神经网络过拟合的正则化器,已经经受住了时间的考验。在现代的背景下,随着 AIGC 技术的发展,训练数据量暴增,很多时候我们需要面对的反而是模型复杂度远低于数据复杂度而导致的欠拟合问题。使用了 Dropout 以后,训练损失增加,测试误差减小,模型泛化误差降低。
尽管 Dropout 这项技术一直很受欢迎,但其强度 (Dropout rate) 近年来总体上呈下降趋势。在最初的工作中,使用了0.5。最近在 ViT 和 BERT 里面却经常采用较低的 Dropout rate,比如0.1。这一趋势的主要驱动因素是可用训练数据的爆炸式增长,这使得我们越来越难见到过拟合的情况。而且,数据增强技术以及使用无标记的自监督算法提供了更多的数据进行训练。因此,我们可能很快就会遇到更多欠拟合的问题,而不是过拟合。
来自 FAIR,Meta AI,UC Berkeley,MBZUAI 的研究员们继续对 Dropout 进行了探索,证明了在训练开始时使用 Dropout 也可以缓解欠拟合。
1.5 Dropout 如何解决欠拟合问题
在本节中,作者从5个角度研究了 Dropout 如何解决欠拟合问题,分别如下:
1) 梯度的幅值 (Gradient norm)
作者首先研究了 Dropout 对于梯度幅值的影响 (通过测量梯度的 范数 ),结果如下图3所示,使用了 Dropout 的模型的梯度更小,这表明它在每次梯度更新时需要更小的步骤。按照这个结论,使用了 Dropout 的模型可能更新得慢一点。
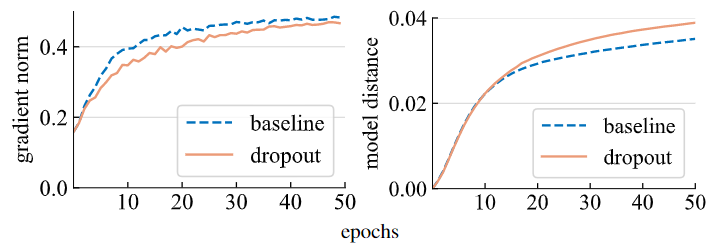
2) 模型距离 (Model distance)
为了测量两个模型之间的距离,作者使用 范数, 用 表示, 其中 表示每个模型的参数。实验结果如上图3所示,令人惊讶的是,使用了 Dropout 的模型实际上比不使用 Dropout 的模型的权重更新得更快,这与梯度的幅值的预期结论相反。
这是为什么呢?想象两个人在走路,一个人大步走,另一个人小步走。但是步幅较小的人在同一时间段内从起点前进的距离更大。那这是为什么呢?可能是因为这个人朝着一个更一致的方向走,而步伐较大的人的步伐可能更随机。
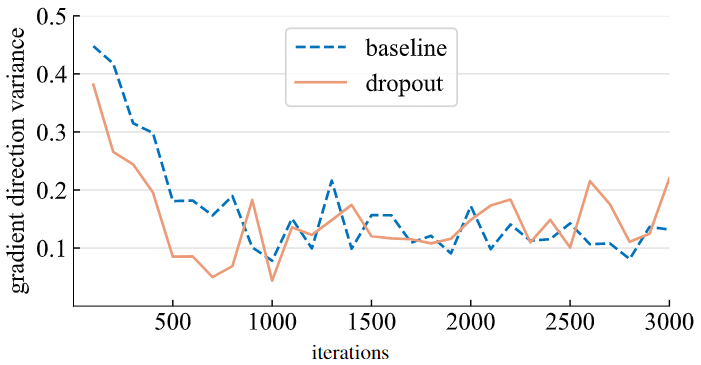
3) 梯度方向的方差 (Gradient direction variance)
为了验证上面的猜想,作者进行了假设:使用了 Dropout 的模型在小的 mini-batch 中产生了更一致的梯度方向。为了测试这一点,作者随机选取了一些 mini-batches,然后分别训练模型得到了一些梯度 ,然后计算平均成对余弦距离,得到梯度方向的方差 (Gradient direction variance,GDV):
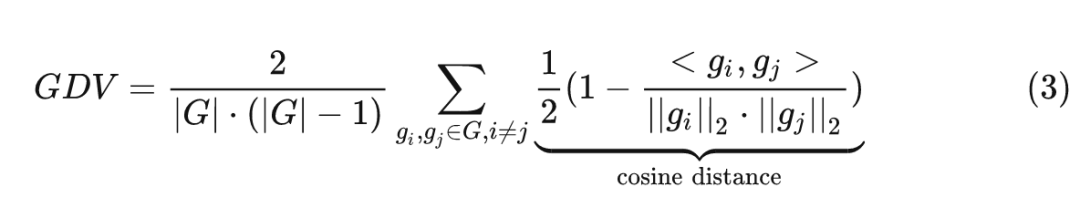
如下图4所示是基线模型和使用 Dropout 的模型的 GDV,可以看到大约1000次迭代,Dropout 的模型都显示出了较低的梯度方差,证明这样的模型在训练时权重朝着更一致的方向移动。
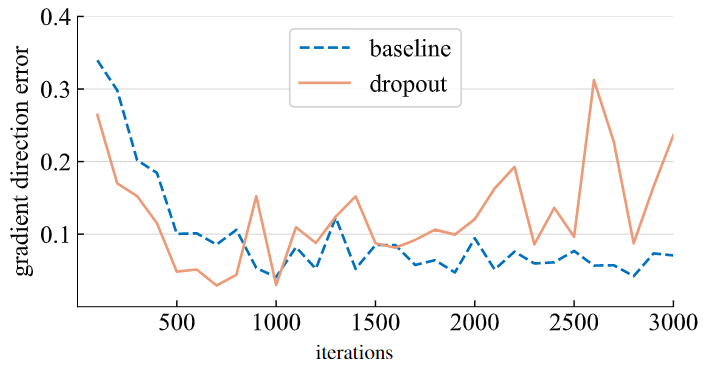
4) 梯度方向的偏差 (Gradient direction error)
那么梯度移动的正确方向应该是什么? 作者定义了一个 "ground-truth" 的梯度 , 定义从所有 到 的平均余弦距离为梯度方向的偏差 (Gradient direction error, GDE)

实验结果如下图5所示。使用了 Dropout 的在大约前1000次迭代的 GDE 都比基线模型更小,证明它正在朝着更理想的方向移动,以优化总的训练损失。在大约1000次迭代之后,退出模型产生的梯度就会相应地更远,这可能是减少欠拟合向减少过拟合过渡的转折点。
5) 偏差-方差的权衡 (Bias-variance tradeoff)
这个分析可以通过偏差-方差的权衡 (Bias-variance tradeoff) 的角度来看待。对于不使用 Dropout 的情况,SGD 的 mini-batch 梯度的期望值等于整个数据集梯度的无偏估计,因为mini-batch 梯度的期望值等于整个数据集梯度。对于使用 Dropout 的情况,mini-batch 梯度是由不同的子网络生成的,其期望梯度可能与整个网络的梯度不匹配,或多或少会产生偏差。但是,梯度方差显著减小,导致梯度的误差减小。
直观来讲,方差和偏差的减少有助于防止模型过度拟合到特定的 mini-batch,尤其是在训练的早期阶段当模型发生重大变化的时候。
1.6 Early Dropout
如下图6所示是模型训练的 Loss Landscape。可以看到在训练的初始阶段,Dropout 技术减少了小 mini-batch 之间的梯度方差,允许模型在更一致的方向上进行更新。此外,它也使得梯度的方向与整个数据集的方向更加一致。因此,模型可以更有效地优化训练损失,而不是受单个 mini-batch 的影响。换句话说,Dropout 技术防止了由于早期训练中采样小 mini-batch 的随机性而导致的过度正则化。
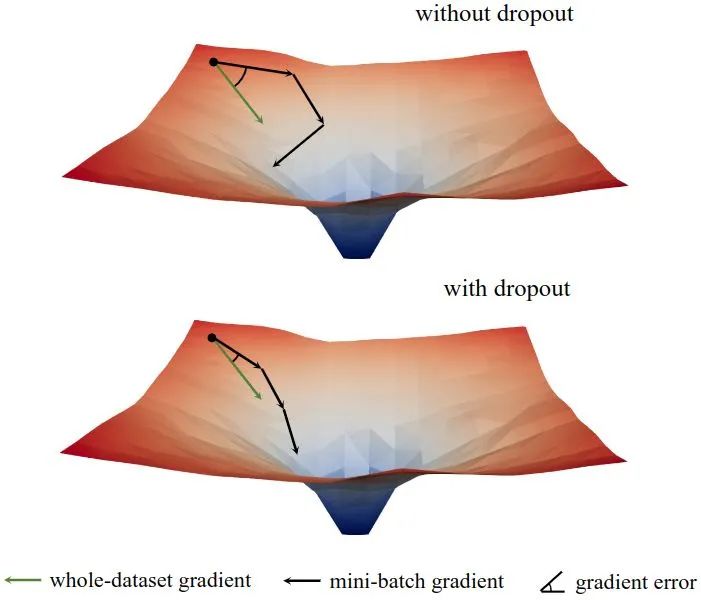
本文提出了一种称为 Early Dropout 的解决欠拟合问题的方法,和一种称为 Late Dropout 的解决过拟合问题的方法如下图7所示。

Early Dropout 就是在某个 iteration 之前使用 Dropout,然后在其余的训练中禁用,Late Dropout 反之。
这两项技术需要的两个超参数:停止 (或开始) 使用 Dropout 的 Epoch 数,以及 Dropout rate 都比较鲁棒。
1.7 Early Dropout 实验结果
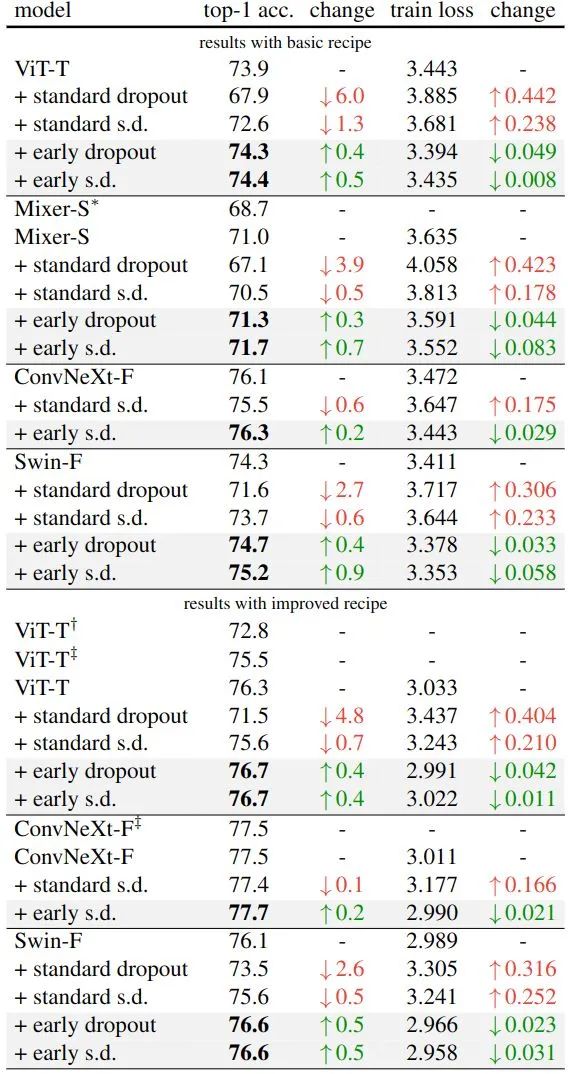
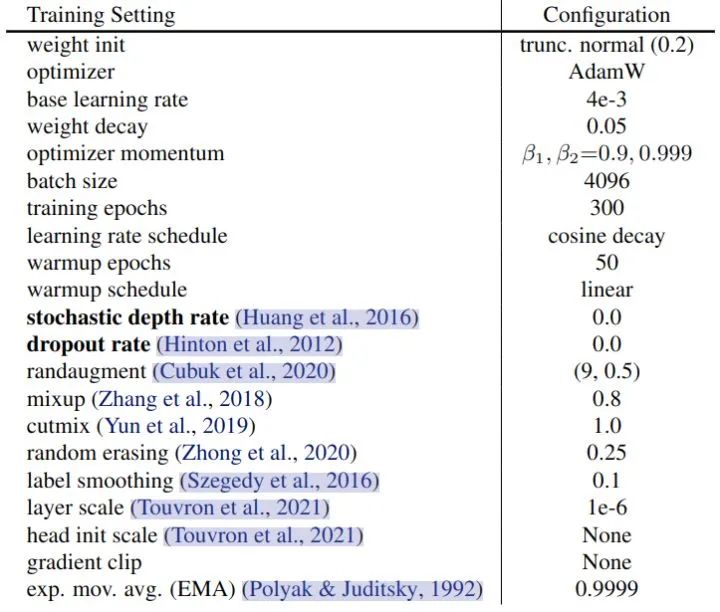
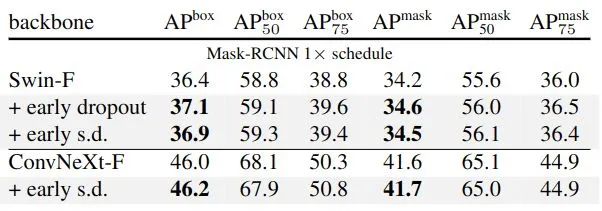
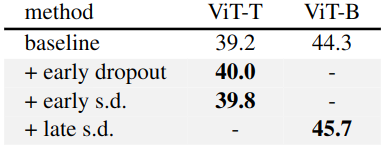
作者在 ImageNet-1K 上进行实验。为了验证 Early Dropout (和 Early Stochastic depth) 的性能 (需要模型处于欠拟合的状态),因此作者选取的都是小模型,包括 ViT-T/16,Mixer-S/32,ConvNeXt-Femto,Swin-F。实验结果如下图8所示,训练超参数如图9所示。
从图8可以看出,Early Dropout 和 Early Stochastic depth 有助于提高测试的精度,同时也降低了训练损失,表明 Early Dropout 有助于模型更好地拟合数据。与标准 Dropout 和 Stochastic depth 进行比较,这两者都对模型有负面影响。
1.8 Late Dropout 实验结果
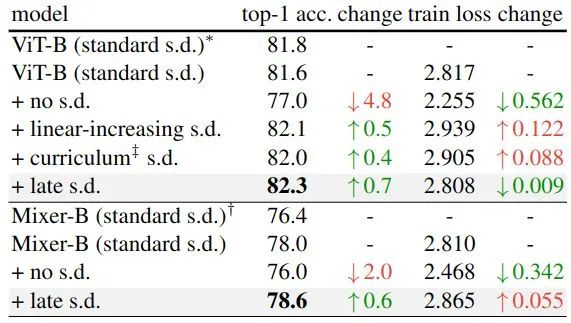
作者在 ImageNet-1K 上进行实验。为了验证 Late Dropout (和 Late Stochastic depth) 的性能 (需要模型处于过拟合的状态),因此作者选取的都是大的模型,包括 ViT-B,Mixer-B。实验结果如下图10所示。
这些模型被认为处于过拟合状态,因为它们已经使用标准 Stochastic depth。在这个实验中,作者将 Late Stochastic depth 的 rate 设置成相同的值,在前50个 Epoch 中不使用 Stochastic depth,其余的训练使用恒定的Stochastic depth。实验结果如下图10所示。
可以看出,与标准的 Stochastic depth 相比,Late Stochastic depth 提高了测试精度,有效地减小了过拟合。
1.9 下游任务实验结果
作者使用 ImageNet-1K 上预训练的权重在下游任务进行微调,在微调过程中不使用 Dropout 来评估所学习的视觉表征。
如下图11所示是 COCO 目标检测和实例分割的实验结果,图12是 ADE20K 语义分割实验结果。使用 Early Dropout (和 Early Stochastic depth) 预训练的模型在 COCO 和 ADE20K 上做下游任务时始终保持其优势。
总结
Dropout 在解决过拟合方面的卓越表现已经闪耀了10年。本文揭示了它在辅助随机优化和减少欠拟合方面的潜力。本文提出 Dropout 对抗了 SGD 带来的数据随机性,并减少了早期训练的梯度方差,使得每个随机的 mini-batch 的梯度和整个数据集的梯度更加一致。
参考:
https://zhuanlan.zhihu.com/p/72038532
https://blog.youkuaiyun.com/qq_42012732/article/details/107318550
^abImproving neural networks by preventing co-adaptation of feature detectors
^Regularization of Neural Networks using DropConnect
^Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
^DropBlock: A regularization method for convolutional networks
^Deep Networks with Stochastic Depth
^Learning transferable visual models from natural language supervision
^Masked autoencoders are scalable vision learners
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 3377
3377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









