




 本文介绍了一种名为PyFu的新型多传感器融合网络,该网络利用金字塔结构进行激光雷达与摄像头的深度融合,以改善3D语义分割任务的表现。通过自顶向下和自底向上的特征融合策略,该方法能够有效地捕捉不同尺度的多模态信息,实验证明其在SemanticKITTI和PandaSet数据集上均取得了显著的效果提升。
本文介绍了一种名为PyFu的新型多传感器融合网络,该网络利用金字塔结构进行激光雷达与摄像头的深度融合,以改善3D语义分割任务的表现。通过自顶向下和自底向上的特征融合策略,该方法能够有效地捕捉不同尺度的多模态信息,实验证明其在SemanticKITTI和PandaSet数据集上均取得了显著的效果提升。
摘要
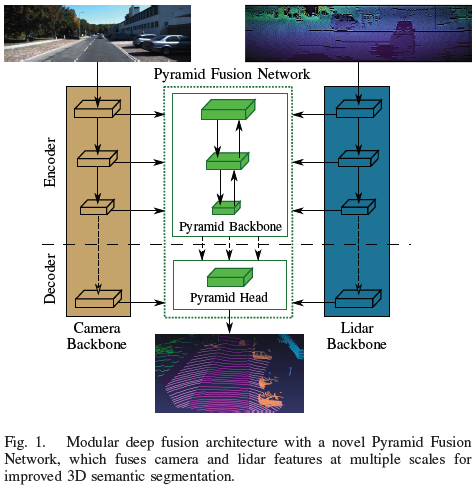
自动驾驶汽车的鲁棒环境感知是一项巨大的挑战,这使得多传感器配置与例如相机、激光雷达和雷达至关重要。在理解传感器数据的过程中,3D 语义分割起着重要的作用。因此,本文提出了一种基于金字塔的激光雷达和摄像头深度融合网络,以改进交通场景下的 3D 语义分割。单个传感器主干提取相机图像和激光雷达点云的特征图。一种新颖的 Pyramid Fusion Backbone 融合了这些不同尺度的特征图,并将多模态特征组合在一个特征金字塔中,以计算有价值的多模态、多尺度特征。Pyramid Fusion Head 聚合这些金字塔特征,并结合传感器主干的特征在后期融合步骤中进一步细化。该方法在两个具有挑战性的户外数据集上进行了评估,并研究了不同的融合策略和设置。论文基于range view的lidar方法已经超过迄今为止提出的所有融合策略和结构。
论文的主要贡献如下:
-
模块化多尺度深度融合架构,由传感器主干和新颖的金字塔融合网络组成;
-
金字塔融合主干用于激光雷达和图像在range view空间中的多尺度特征融合;
-
金字塔融合头用于聚合和细化多模态、多尺度的金字塔特征。
相关工作
2D语义分割
全卷积网络(FCN)开创了2D语义分割的新局面。全卷积网络专为端到端像素级预测而设计,因为它们用卷积替换全连接层。由于最初的 FCN 难以捕捉场景的全局上下文信息 [7],因此出现了新的结构 [7]-[9] — 基于金字塔特征进行多尺度上下文聚合,在收集全局上下文的同时保留精细细节。PSPNet [7] 应用了一个金字塔池化模块(PPM),其结合最后一个特征图的不同尺度。因此,网络能够捕获场景的上下文以及精细的细节。HRNetV2 [9] 等其他方法利用主干中已经存在的金字塔特征进行特征提取。对于全景分割的相关任务,EfficientPS [8] 通过应用双向特征金字塔网络 (FPN) [10],自底向上和自顶向下结合各种尺度的特征,之后使用语义头,包含大规模特征提取器 (LSFE)、密集预测单元 (DPC) [11] 和不匹配校正模块 (MC),以捕获用于语义分割的大尺度和小尺度特征。
3D语义分割
与将 CNN 应用于规则网格排列的图像数据相比,它们不能直接应用于 3D 点云。目前得到广泛应用的已经有几种表示形式和专门的体系结构。
直接处理
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2758
2758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









