







 超级会员免费看
超级会员免费看
 本文深入解析FastText模型,包括论文解读、源码分析及文本分类的应用。介绍了层次Softmax、词和字符N-gram等技巧,并提供使用FastText进行文本分类的步骤,涵盖词袋、Word2Vec、LDA模型的使用。
本文深入解析FastText模型,包括论文解读、源码分析及文本分类的应用。介绍了层次Softmax、词和字符N-gram等技巧,并提供使用FastText进行文本分类的步骤,涵盖词袋、Word2Vec、LDA模型的使用。
一、论文解读
论文《Bag of Tricks for Efficient Text Classification》是2017年发布于ACL的文章,目前引用数3806,主要是基于FastText的文本分类,提出了文本分类的很多实用技巧。
模型结构比较简单,如下:
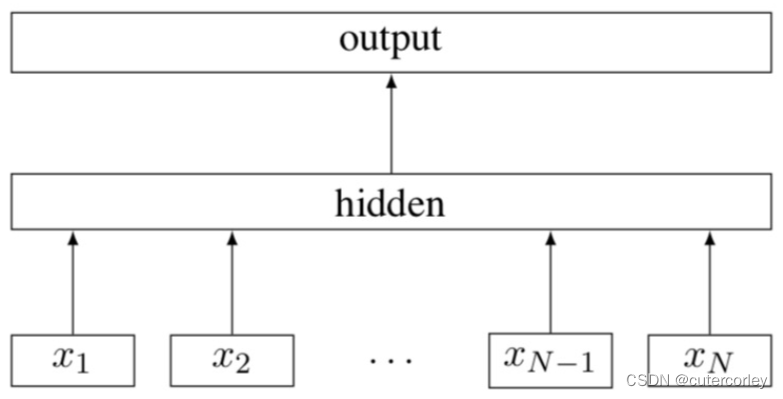
可以看到,这是具有 N 个 ngram 特征x1、…、xN的句子的fasttext模型架构。词的特征可以被平均到一起,形成良好的句子表征,即特征被嵌入并平均以形成隐藏变量。模型架构类似于Word2vec的CBOW模型,中间的词被一个标签代替。
负对数似然概率公式如下:
− 1 N ∑ n = 1 N y n log ( f ( B A x n ) ) -\frac{1}{N} \sum_{n=1}^{N} y_{n} \log \left(f\left(B A x_{n}\right)\right)

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











