



1 CPU虚拟化
1. 关键底层机制
保持控制权的同时获得高性能
1).受限制的操作
划分用户模式(user mode)和内核模式(kernel mode)
用户模式下:不能直接访问硬件资源或者引用内存,必须通过系统API来实现
内核模式下:可以执行任何指令和操作任何内存地址
2).进程之间切换
(1)如何保证操作系统对CPU的控制权
协作方式下:等待进程进行系统调用,将CPU控制权交给OS
非协作方式下:进程拒绝系统调用,通过时钟中断
(2)保存和恢复上下文
简单来说,就是在发生中断时,系统如何知道上一个程序执行到哪里,并且在处理完这个中断之后,接着运行上一个程序。
为了保存当前正在运行的进程的上下文,操作系统会执行一些底层汇编代码,来保存通用寄存器、程序计数器,以及当前正在运行的进程的内核栈指针,然后恢复寄存器、程序计数器,并切换内核栈,供即将运行的进程使用。通过切换栈,内核在进入切换代码调用时,是一个进程(被中断的进程)的上下文,在返回时,是另一进程(即将执行的进程) 的上下文。当操作系统最终执行从陷阱返回指令时,即将执行的进程变成了当前运行的进 程。至此上下文切换完成。
3).并发情况
在中断处理过程中发生另外一个中断
2. 动态重定位
将虚拟地址转换为物理地址,需要两个硬件寄存器,基址寄存器(base)和界限寄存器(bound),此过程没有有操作系统的接入,完全由硬件处理
基址寄存器:虚拟地址为0处的实际加载地址
映射实现:进程中使用的内存引用都是虚拟地址,硬件将虚拟地址加上基址寄存器中的内容得到物理地址,界限寄存器提供访问保护,确保进程产生的所有地址都在进程的地址界限中。
内存管理单元(Memory Managemen Unit,MMU):CPU中负责地址转换的部分
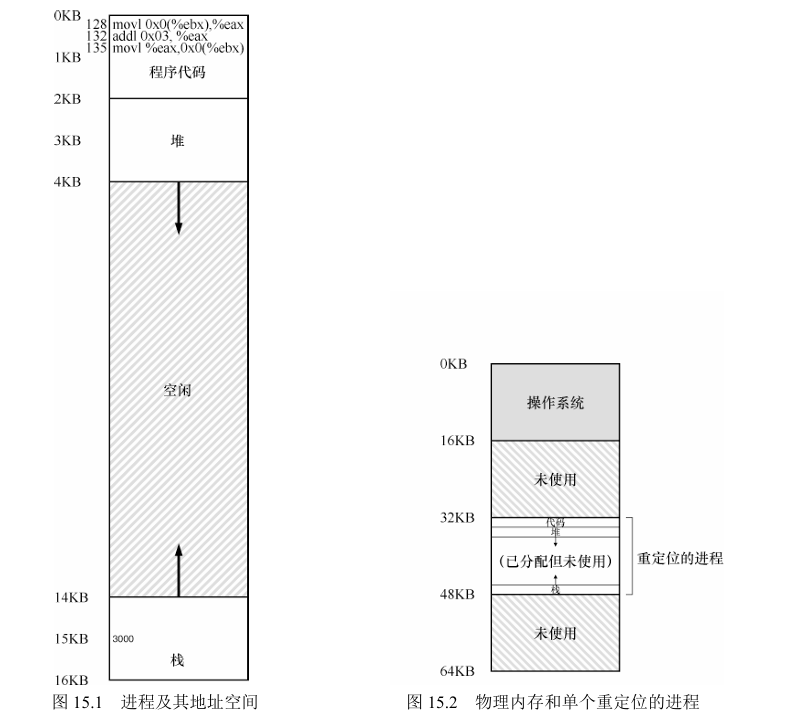
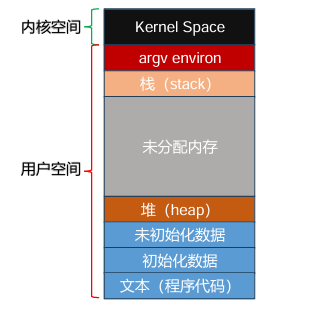
将整个地址空间放入物理内存,那么栈和堆之间的空间并 没有被进程使用,却依然占用了实际的物理内存
存在问题:容易产生内存碎片,图15.2中重定位的进程内部堆栈占用空间很少
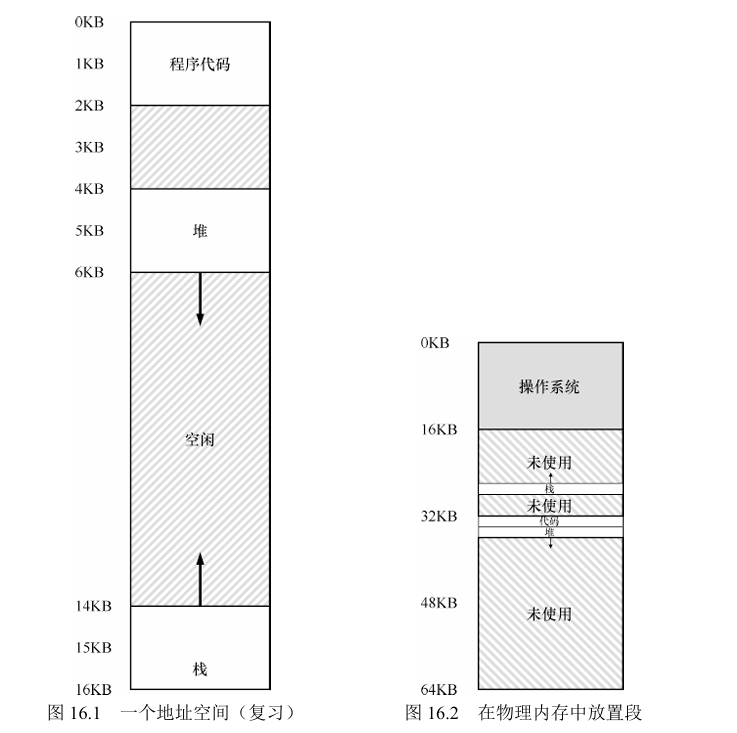
3. 分段
在MMU中引入不止 一个基址和界限寄存器对,而是给地址空间内的每个逻辑段(segment)一对。一个段只是地址空间里的一个连续定长的区域,在典型的地址空间里有 3 个逻辑不同的段:代码、栈 和堆。分段的机制使得操作系统能够将不同的段放到不同的物理内存区域,从而避免了虚拟地址空间中的未使用部分占用物理内存。
4. 分页
- 分页:将进程的地址空间分成固定大小的单元,每个单元成为1页,一页大小为4kb,存储4096个字节
- 页表(page):记录地址空间的每个虚拟页放在物理内存中的位置,为地址空间的每个虚拟页面保存地址转换(address translation),从而让我们知道每个页在物理内存中的位置
注:每个进程都有相应的页表
- TLB(translation-lookaside buffer):频繁发生的虚拟到物理地址转换的硬件缓存(cache)
作用:提高访问效率,对每次内存访问,硬件先检查TLB,看看其中是否有期望的转换映射,如果有,就完成转换,不用访问页表(其中有全部的转换映射)
多级页表:将线性页表变成类似于树的结构
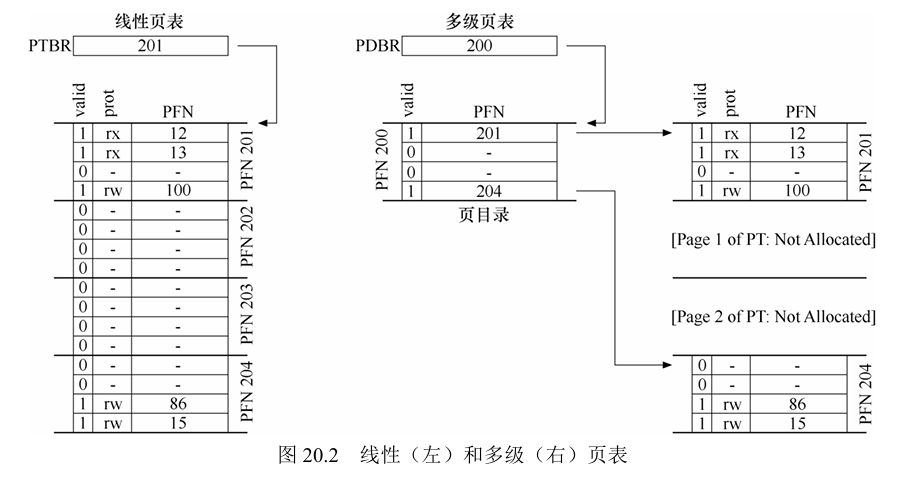
页表的存放位置:CPU内
5. 超越物理内存
1)交换空间:
将当前不用的地址空间存在硬盘中,而不占用内存,需要的时候在交换回内存中
存在位:设置为1表示该页存在于物理内存中,为0则表示在硬盘上
页错误:访问的页不在物理内存中,页错误由操作系统来管理
2 进程
1. 定义:
2. 进程状态:
- 运行(running):此时正在占用CPU,执行指令中
- 就绪(ready):等待调度器调度任务,随时可以进入运行状态
- 阻塞(blocked):等待事件唤醒,使其进入就绪态(注意阻塞状态不能直接进入运行态)
三种状态的转换:
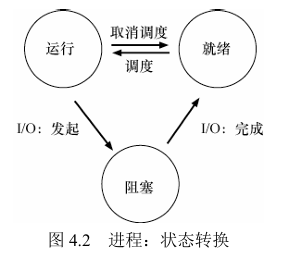
注:除了上述三种状态,系统还有初始状态、僵尸状态以及终止状态
初始状态:比较短暂,进程在创建时处于的状态
僵尸状态:进程已经结束,但是其PCB(进程控制块)为被清理
终止状态:
3.进程创建
1)fork()系统调用
创建子进程,并复制父进程的内存地址,寄存器,程序计数器等,如图下
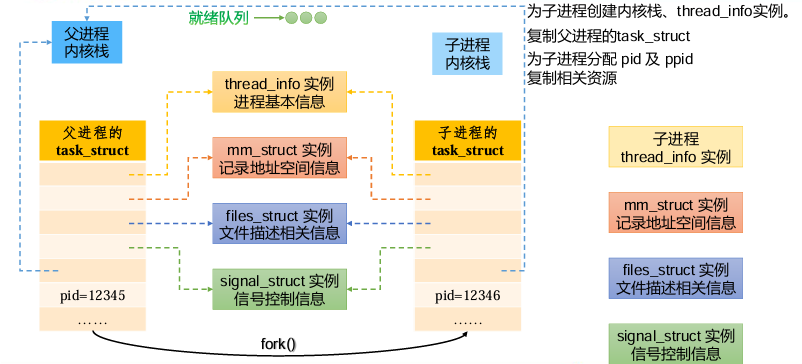
注意:父进程和子进程的PID不同
int pid = fork(),当pid大于0时为父进程,pid等于0时为子进程
或者通过getpid()函数,获取当前进程的PID
getppid()可以得到当前进程的父进程的PID
2)wait()系统调用
作用:在父进程中调用wait(),延迟自己的执行,等待子进程先执行完毕
在进程结束时回收资源很关键
3)exec()系统调用
是创建进程API(应用程序接口)的重要部分,通过exec()可以使得子进程和父进程执行不同的程序
具体操作:将当前运行的程序替换为不同的运行程序,成功调用后不会返回
4.进程调度
1.简单调度策略
1)先进先出(First In First Out,FIFO)/ 先到先服务(First Come First Served, FCFS)
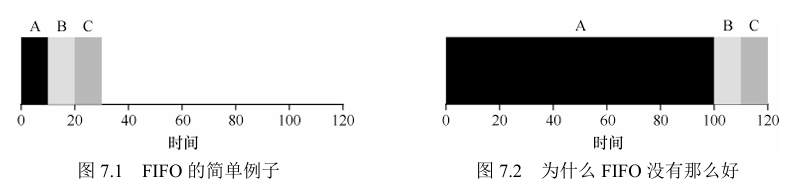
对于某些执行时间很长的任务却先到时,采用FIFO会使得系统平均周转时间很长
2)最短任务优先(Shortest Job First ,SJF)
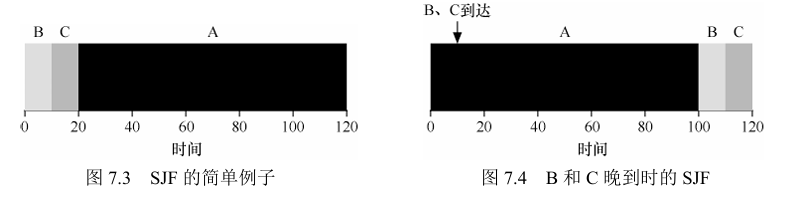
最短的任务可能很晚才到达,仍然要运行时间长的任务
3)最短完成时间优先(Shortest Time-Comletion First,STCF)
抢占式调度
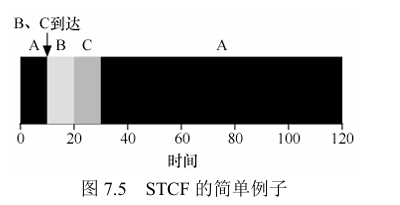
新任务进入系统时,确定在剩余的任务和新任务中,哪个任务的距离完成的剩余时间最短,并执行这个剩余时间最短的
4)轮转调度(Round-Robin,,RR)
在一个时间片内运行一个任务,然后切换到运行队列中的下一个任务,而不是一直运行一个任务直到结束(时间片是时钟中断周期的倍数)
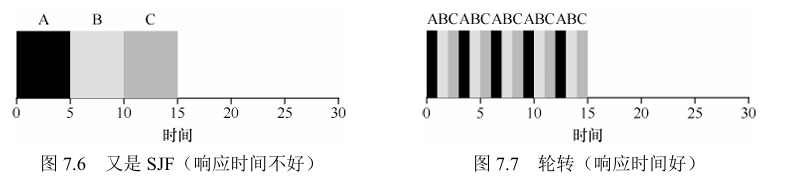
对于前述的调度策略来说,在响应时间上,性能不是很好
时间片的选取:太短上下文切换的成本大影响整体性能,太长也会使得系统响应时间下降
2.度量指标
平均周转时间:所有任务从到达到完成任务的总时间 / 任务数量
响应时间:从任务到达系统到任务首次运行的时间
综合上述调度策略:
- SJF和STCF可以优化周转时间,但是对响应时间不利
- RR可以优化响应时间,但是对于周转时间不利
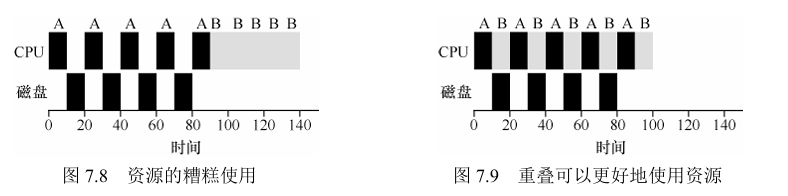
3. 调度结合I/O
任务在I/O期间是不使用CPU的
当任务运行中需要请求I/O时,在执行I/O的期间,可以执行其他任务,使得系统得到更好的利用,这一操作也称为重叠(overlap)
4. 多级反馈队列调度
多级反馈队列 (Multi-level Feedback Queue, MLFQ),解决上述周转时间和响应时间的矛盾
1.MLFQ基本规则
MLFQ中有许多独立的队列,每个队列优先级不同,且一个任务智能存在于一个队列中,MLFQ总是执行高优先级队列中的工作,对于一个队列中的任务,优先级相同,采用轮转调度
- 规则1:A的优先级 > B的优先级,运行A
- 规则2:A的优先级 = B的优先级,轮转运行
关键:设置优先级
MLFQ 没有为每个任务指定不变其优先级,而是在进程运行过程中观察行为来调整优先级
如果仅仅只有上述两个规则,可能会出现一下情况,任务A、B、C、D,只有A和B任务交替运行,C和D永远没有机会
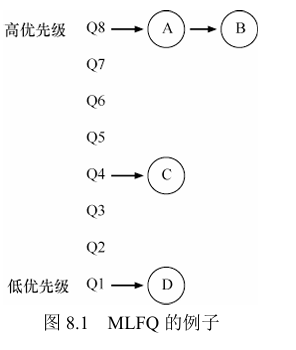
因此,必须增加其他的规则,实现更加相对公平且有效的调度算法
2. 尝试1:
改变优先级:
规则3:当任务进入系统时,优先级至于最高,
规则4a:用完整个时间片后降低优先级
规则4b:任务在时间片内主动释放CPU,保持优先级不变
存在漏洞:
1.对于I/O操作密集的工作,总在时间片内释放CPU,因此优先级总是比较高,导致时间长的任务饿死
2. 利用规则4b漏洞,总在时间片运行完之前,调用I/O操作,极端情况可以占用99%的时间片,近似于完全掌控CPU权力
3.一个程序可能在不同的时间表现不同,可能只在某些时段I/O操作密集
3.尝试2:
提升优先级:周期性提升所有工作的优先级
规则5:每隔一段时间S,系统中的工作重新加入最高优先级队列
难题:S的值如何设定,也称之为“voo-doo const”
4.尝试3:
防止规则4b漏洞,MLFQ的每层队列提供更完善的CPU计时方式
规则4(New):一旦工作用完了它在某一层的时间分配额度(无论中途它主动放弃了多少次CPU),就降低优先级(移入低一级队列)
5.MLFQ调优
大多数MLFQ都支持不同队列可变的时间片长度,高优先级队列通常只有较短的时间片(10ms或更少),低优先级队列中更多是CPU密集型工作,配置更长的时间片。
Ousterhout定律:避免巫毒常量,通常会有一个写满各种参数默认值的配置文件,使得系统管理员可以方便进行修改调整,然而大多数不修改配置文件直接使用默认值
6.总结
一组优化的MLFQ规则
- 规则1:如果A的优先级 > B的优先级,运行A(不运行B)
- 规则2:如果A的优先级 = B的优先级,轮转运行A和B
- 规则3:工作进入系统时,放在最高优先级(最上层队列)
- 规则4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次 CPU),就降低其优先级(移入低一级队列)
- 规则5:经过一段时间S,就将系统中所有工作重新加入最高优先级队列
MLFQ不需要对工作的运行方式有先验知识,而是通过观察工作的运行来给出对应的优先级
5.比例份额调度
比例份额(proportional-share),也称为公平份额调度(fair-share),有两种实现
1.彩票调度:选取随机值,,每个进程具有一定的彩票数,确定当前的运行进程
2.步长调度:每个进程都有自己的步长,并且与票数成反比,调度时选取目前拥有最小行程值的进程,运行该进程后,将当前的行程值加上步长
但比例份额调度并没有被CPU调度广泛使用(一是不能很好的适合I/O,二是票数分配是个难题)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











