 强化学习model-free策略梯度算法介绍
强化学习model-free策略梯度算法介绍




策略梯度 PG
Q-learning、DQN 及 DQN 改进算法都是基于价值(value-based)的方法,问题在于状态空间过大,或连续,难以解决。
策略梯度算法是基于策略的方法,基于策略的方法是直接显式地学习一个目标策略,基于值函数的方法主要是学习值函数。
假设目标策略πθ\pi_\thetaπθ是一个随机性策略,并且处处可微,其中θ\thetaθ是对应的参数。用一个神经网络模型来为这样一个策略函数建模,输入某个状态,输出一个动作的概率分布。
状态价值函数为:
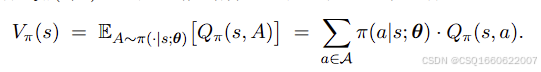
用于拟合策略函数的神经网络模型,目标函数为
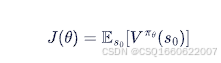
通过梯度上升,更新神经网络,从而更新策略,梯度为:
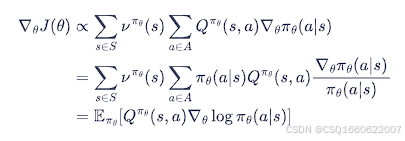
1. RENIFORCE算法
动机:用蒙特卡洛方法来估计梯度中的Q值,从而进行更新
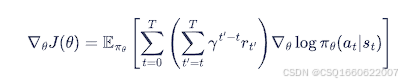
算法流程:

2. Actor-Critic算法
动机:用神经网络来估计梯度中的Q值,从而进行更新
两个网络:
actor网络:也就是策略网络,与环境交互,并在 Critic 价值函数的指导下用策略梯度学习一个更好的策略。
critic网络:也就是价值网络,通过 Actor 与环境交互收集的数据学习一个价值函数,进而帮助 Actor 进行策略更新。
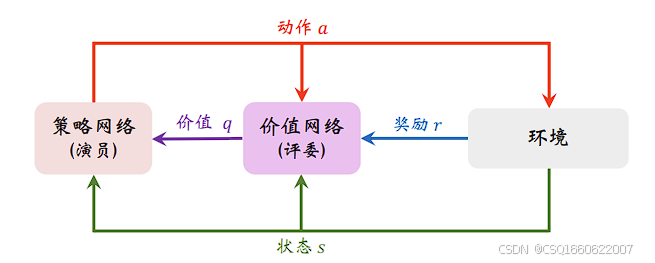
actor网络,通过策略梯度更新
critic网络,通过时序差分TD算法更新,用类似DQN更新目标网络的方式更新
即:价值网络目标函数,也就是损失函数
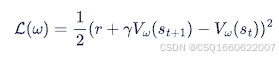
通过梯度下降,更新神经网络,从而更新价值,梯度为:
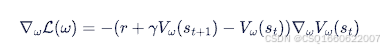
AC算法流程:

此外,为解决类似于DQN中的Q值自举高估问题,加入target网络,变为了三个神经网络。
A2C算法
动机:上述算法实践中效果并不理想,Q值方差大,引入基线函数减小方差,效果更好,使用基线
(baseline)之后,REINFORCE 变成 REINFORCE with baseline,actor-critic 变成 advantage
actor-critic(A2C)。
在AC算法中,用状态价值函数V作为基线,将critic神经网络输出的Q值减去基线V,称为优势函数。得到Advantage Actor-Critic算法,A2C。
3. TRPO 算法
动机:当策略网络是深度模型时,沿着策略梯度更新参数,很有可能由于步长太长,策略突然显著变差,进而影响训练效果,考虑在更新时找到一块信任区域(trust region),在这个区域上更新策略时能够得到某种策略性能的安全性保证,这就是信任区域策略优化算法TRPO算法。
TRPO 有两个优势:第一,TRPO表现更稳定,收敛曲线不会剧烈波动,而且对学习率不敏感;第二,TRPO 用更少的经验(即智能体收集到的状态、动作、奖励)就能达到与策略梯度方法相同的表现。
状态价值可写为:
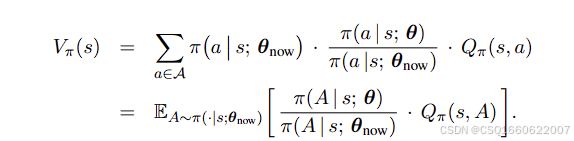
目标函数为:
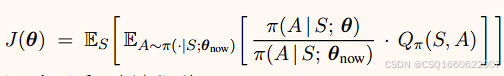
构造函数L近似目标函数,通过蒙特卡洛方法,与环境交互,得到轨迹,对上式中Q值进行估计
近似函数为:
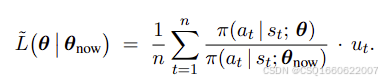
设定置信域,也就是说上述近似函数在什么范围内可以近似原目标函数
可以用二范数距离,或KL散度
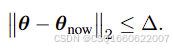
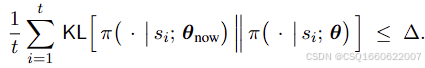
也就是说要求解的问题变为了一个带约束的最大化问题
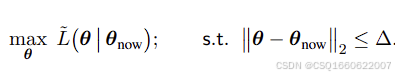
或
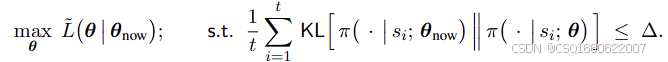
可以通过数值优化算法计算,共轭梯度法等,计算难度大,过于复杂
4. PPO算法
动机:TRPO算法计算过于复杂,运算量大
PPO-惩罚
用拉格朗日乘数法将TRPO中KL散度的约束加入到目标函数中,变为无约束优化问题,在迭代的过程中不断更新 KL 散度前的系数。
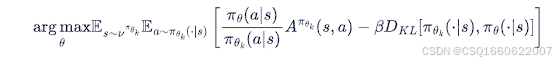
PPO-截断
在目标函数中进行限制,以保证新的参数和旧的参数的差距不会太大
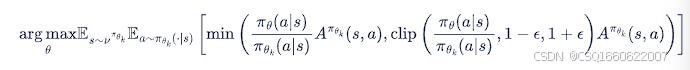
5. DDPG算法
动机:之前算法无法处理连续性动作的情况,DDPG算法输出一个确定的动作,而不是动作的概率分布
一种AC类的方法
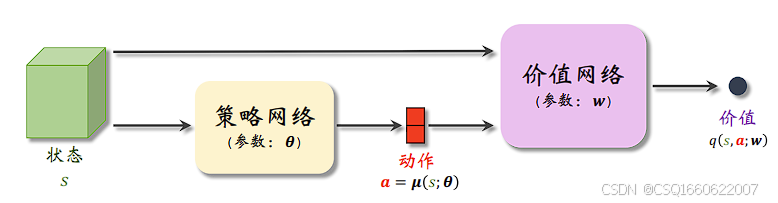
策略网络 µ(s; θ) 的输入是状态 s,输出是动作 a。价值网络 q(s, a; w) 的输入是状态 s 和动作 a,输出是价值。
通过已有数据,状态s输入给策略网络和价值网络,策略网络输出一个动作a后,将a输入到价值网络,价值网络基于状态s和动作a,输出价值q(s, a) .
与策略梯度算法,不同之处就是策略网络的更新方式,用链式法则,通过价值网络的梯度进行更新
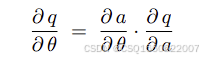
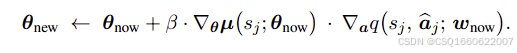
为防止自举高估,需添加目标网络
算法流程:

6. SAC算法
动机:在线策略算法的采样效率比较低,使用离线策略算法更优。虽然 DDPG 是离线策略算法,但是它的训练非常不稳定,收敛性较差,对超参数比较敏感,也难以适应不同的复杂环境。2018 年, Soft Actor-Critic(SAC)被提出,属于 Actor-Critic 方法的变体。它特别适合处理连续动作空间,并通过引入最大熵(Maximum Entropy)强化学习的思想,解决了许多传统算法中的稳定性和探索问题。
主要有三个组件
- 最大熵强化学习
主要想法是除了要最大化累积奖励,还要使得策略更加随机。如此,强化学习的目标中就加入了一项熵的正则项,定义为
最大熵强化学习,

考虑最大熵后,策略网络目标变为
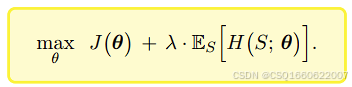
对应的梯度为
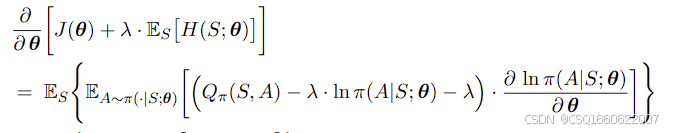
价值网络的目标变为
α\alphaα为熵系数,控制探索策略和奖励之间的平衡
2. 双Q网络
缓解 Q 值过估计的问题。
3. 目标网络
使用目标网络稳定 Q 值计算。
综上,SAC 一共5个网络,1个策略网络actor,4个价值网络critic(其中2个价值网络,2个与之对应的目标价值网络),相当于5个网络有3种作用。
搞搞清楚这5个网络
策略网络
接收环境数据si,ai,ri,si+1s_i, a_i, r_i, s_{i+1}si,ai,ri,si+1,输出ai+1a_{i+1}ai+1,提供给2个目标Q网络
接收价值网络的反馈进行更新
更新方式
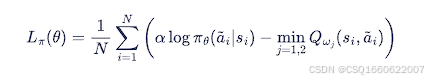
目标价值网络
接收策略网络输出的策略,负责提供目标价值给价值网络
更新方式
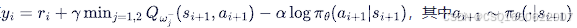
价值网络
接收目标价值网络提供的目标价值,负责提供反馈给策略网络
更新方式
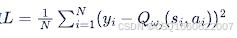
算法流程



















 4431
4431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









