 DeepSeek大模型创新解析与应用
DeepSeek大模型创新解析与应用






DeepSeek 的五大创新:从架构到推理全面领先
DeepSeek 系列模型,特别是 R1,在推理精度、推理链条、蒸馏能力和部署灵活性方面达到了行业领先地位,以下是其核心技术亮点简要概述。
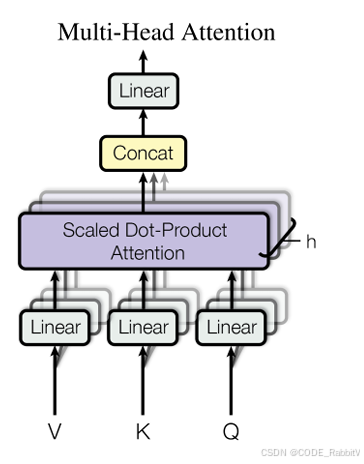
一、MLA:多头隐变量注意力(Multi-Head Latent Attention)
传统 KV 缓存(Key-Value Cache)大而慢,DeepSeek 引入 MLA 技术,将 KV 低秩压缩,大幅减小显存占用并提升速度
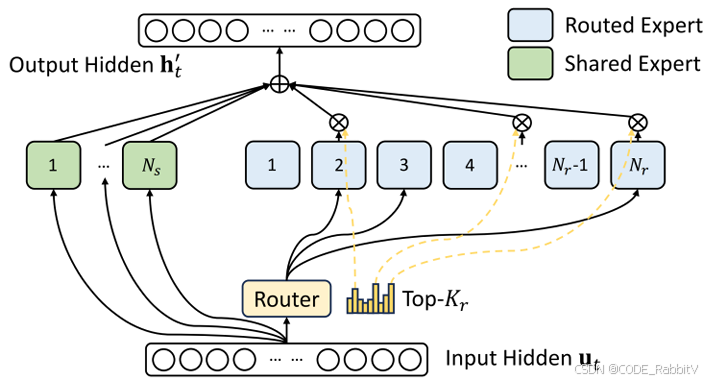
二、DeepSeek-MoE:智能分流的 MoE 架构
V3 版本使用 61 个专家模块,但每次仅激活少数专家,有效降低训练与推理计算成本
📌 类比:“普通模型像全科医生,DeepSeek-MoE 像分诊+专科医生”
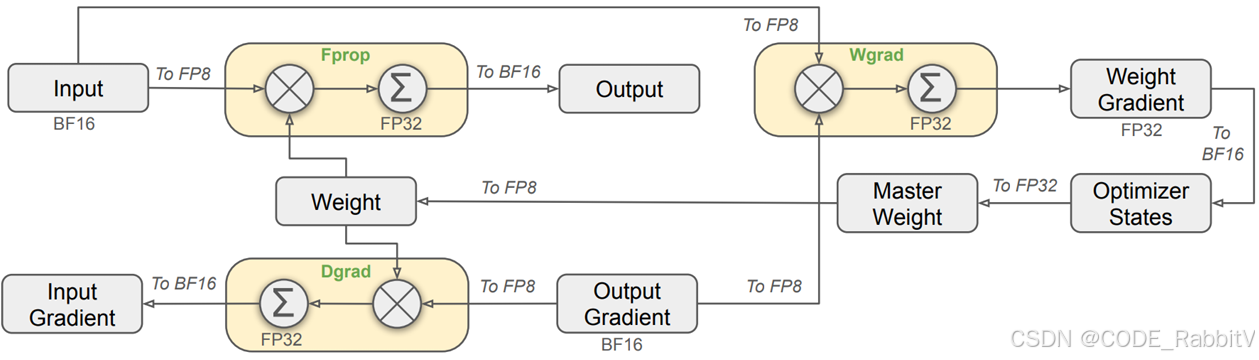
三、混合精度训练:引入 FP8 精度
采用混合精度框架(FP16、FP32、FP8 组合),在精度足够的场景下使用 FP8,极大提升计算效率并降低显存需求。
📌 优势:训练快、功耗低、成本更低。
四、训练策略:多 token 预测 + 强化学习 + 长链推理
- 多 Token 预测 MTP 提高训练信号密度
- 强化学习+少量高质量 SFT 提升模型逻辑能力
- Chain of Thought 机制支持多轮推理,思维链可达上万 Token
📌 R1 在数学、逻辑、代码能力上全面超越 o1-mini。
五、蒸馏能力强:小模型也很强
通过 R1 训练数据,蒸馏出多个小模型(如 7B、14B、32B、70B),效果对标甚至超过 o1-mini,非常适合边缘部署或资源受限场景。

总结:为什么选 DeepSeek?
| 模型 | 推理精度 | 显存优化 | 本地部署 | 开源许可 |
|---|---|---|---|---|
| DeepSeek R1 | ✅ 超强 | ✅ MLA + FP8 | ✅ Ollama/VLLM 支持 | ✅ MIT License |
| OpenAI o1 | 强 | ❌ | ❌ | ❌ |
| LLaMA3 | 中 | ✅ | ✅ | ❌ |
DeepSeek 正逐步改变国产大模型生态,值得持续关注与使用。


















 8872
8872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









