




今天介绍的主干网络模型叫MobileNet,是为了在移动设备上高效运行而设计的轻量化模型;其实它并不是一个具体的模型,而是类似于残差块、Lora这种的一种卷积运算方式,其核心创新在于深度可分离卷积(Depthwise Separable Convolution),这是一种高效的卷积操作,可以显著减少计算量和模型大小;
一、模型介绍
MobileNet 是 "Mobile Neural Network" 的缩写,由 Google 在 2017 年的论文《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》中首次提出。该模型旨在为移动设备和嵌入式系统提供高效的深度学习解决方案,特别强调计算资源有限的环境下的性能;目前该模型有多个优化版本,分别为MobileNet-v1、MobileNet-v2、MobileNet-v3;
二、核心创新分析 —— 深度可分离卷积
MobileNet的优势就是减少卷积运算的参数量和运算量,所以其创新点就是使用一种变体的卷积操作,以减少卷积参数量,这种变体卷积叫做深度可分离卷积;大概的思路就是将原来的多通道卷积核变为单通道卷积核进行卷积运算,再通过多个1*1的卷积核将特征张量恢复到原来的通道数;下面我们结合一个例子来详细了解一下它的具体流程;
我们假设需要对一个3*256*256的特征矩阵进行卷积运算:
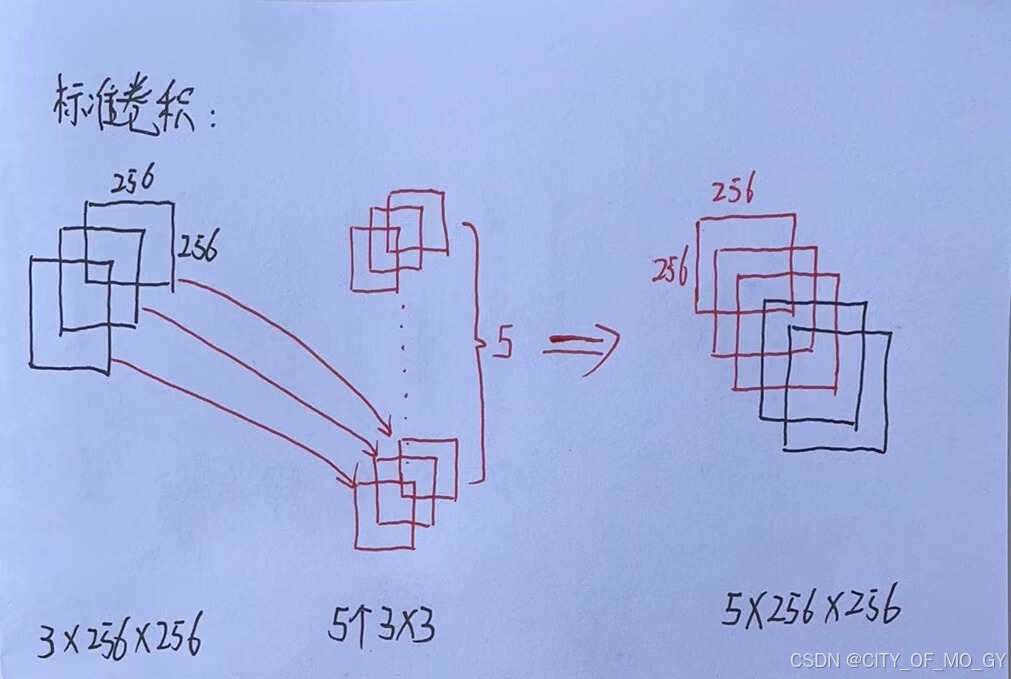
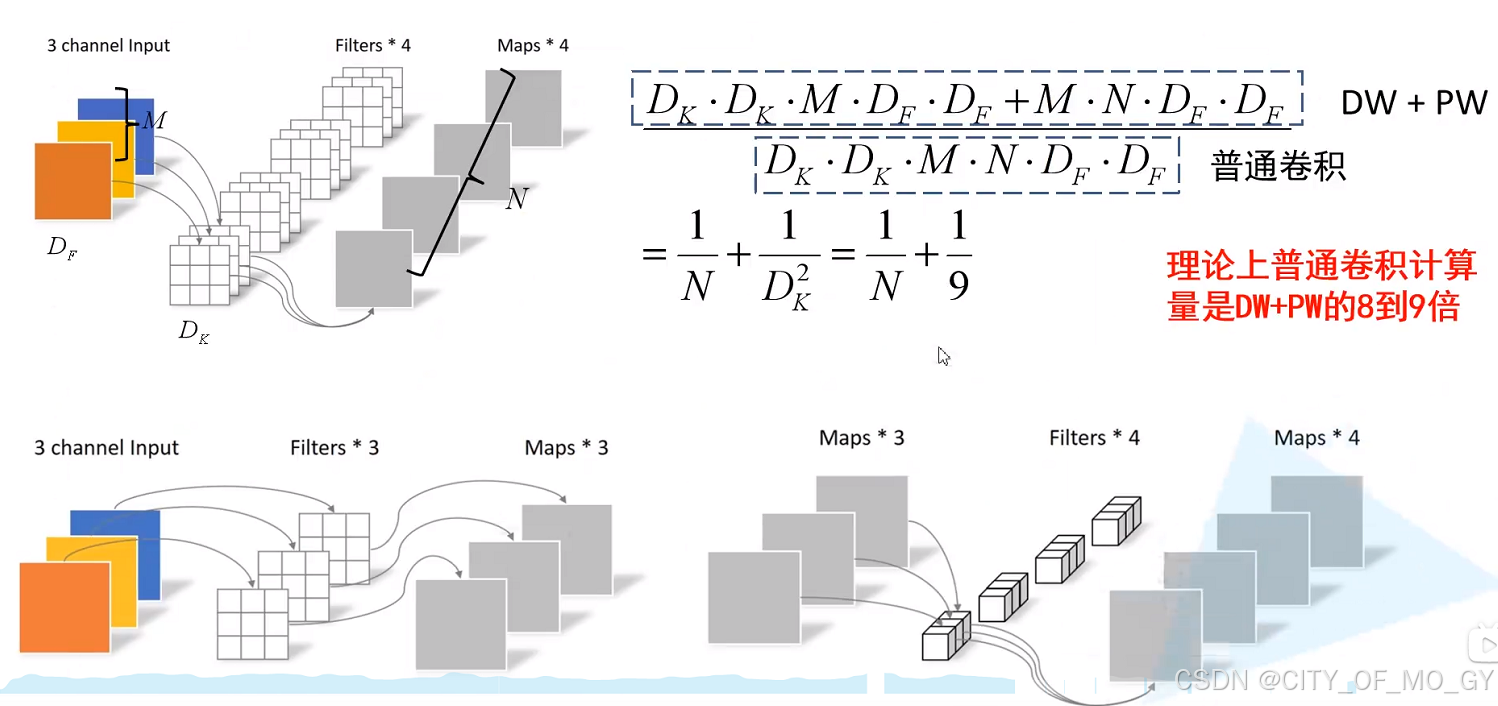
1)首先我们使用正常的卷积运行进行特征提取,假设我们使用5个3*3的卷积核进行运算(padding=1),那么通过卷积运算后的特征矩阵尺寸应该是5*256*256,卷积核的权重参数个数为3*3*3*5=135个;
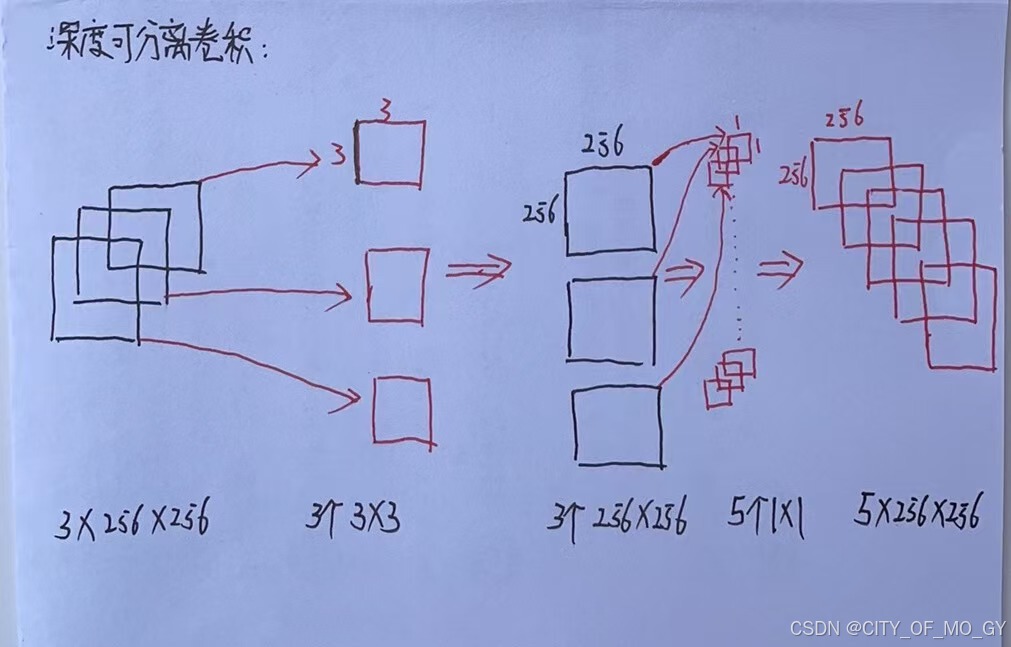
2)然后我们使用深度可分离卷积运算进行特征提取,深度可分离卷积会根据输入特征的通道数设定相同个数的单通道卷积核进行卷积运算,输入张量为3*256*256,所以单通道卷积核的个数为3,这里选择相同大小的3*3的卷积(padding=1),会得出3个256*256的特征矩阵,即3*256*256;再接入逐点卷积运算,逐点卷积运算的特点是全部都为1*1的卷积核,在深度网络中1*1的卷积核最主要的作用就是调整特征矩阵的通道数;因为上面正常卷积的通道数是5,所以逐点卷积需要5个1*1的卷积核进行运算,运算结果特征矩阵尺寸为5*256*256,下面我们计算一下一次深度可分离卷积一共需要多少个参数:
单通道卷积:3个单通道3*3卷积核,参数个数=3*3*3=27;
逐点卷积:5个1*1卷积核,参数个数=1*1*3*5=15;
所以总参数量=单通道卷积核+逐点卷积核=27+15=42个;
对比我们会发现在输出特征矩阵尺寸不变的前提下,深度可分离卷积的参数量远小于正常卷积的参数量,大大减少了模型训练时的梯度更新量和模型推理时的运算量;
三、拓扑结构
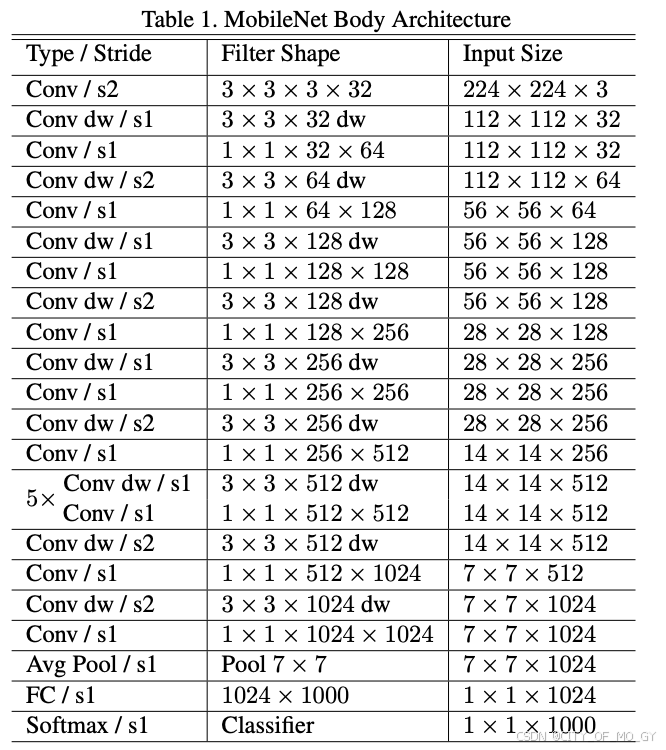
MobileNet目前有三个版本,分别是v1、v2和v3,v1就是简单的将深度可分离卷积层添加到卷积神经网络中,v2通过改变激活函数和升维的方式解决了v1中训练结果卷积核空置的情况,v3添加了NAS机制和SE模块,同时调整了耗时层卷积核数量和激活函数类型,使得模型效果和推理速度更好,具体优化细节请参考这篇博文;这里我简单罗列一下三个版本的拓扑结构:
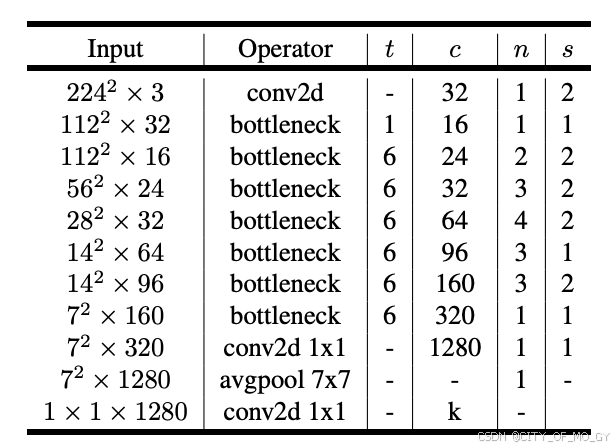
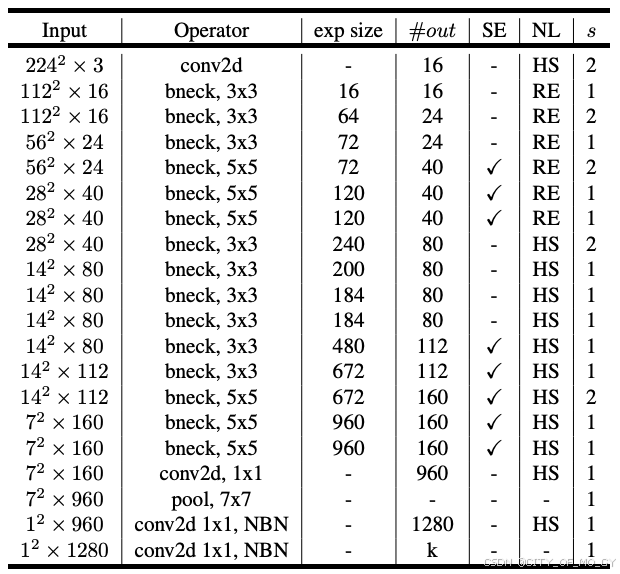
四、代码实现
根据前面的介绍,我们大概了解了MobileNet的核心深度可分离卷积的思路,下面我们就试着用pytorch来实现一下MobileNet-v3作为Backbone的代码;
# Backbone-MobileNetV3
import torch
import torch.nn as nn
import torch.nn.functional as F
def h_swish(x):
return x * F.relu6(x + 3) / 6
class SEBlock(nn.Module):
def __init__(self, in_channels, reduction=4):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction, in_channels, bias=False),
nn.Hardsigmoid(inplace=True)
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class InvertedResidual(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, expand_ratio, use_se=False, use_hs=False):
super(InvertedResidual, self).__init__()
assert stride in [1, 2]
hidden_dim = int(round(in_channels * expand_ratio))
self.use_residual = stride == 1 and in_channels == out_channels
self.use_se = use_se
self.use_hs = use_hs
layers = []
if expand_ratio != 1:
layers.append(nn.Conv2d(in_channels, hidden_dim, 1, 1, 0, bias=False))
layers.append(nn.BatchNorm2d(hidden_dim))
layers.append(nn.Hardswish() if self.use_hs else nn.ReLU(inplace=True))
layers.extend([
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, kernel_size//2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.Hardswish() if self.use_hs else nn.ReLU(inplace=True),
SEBlock(hidden_dim) if self.use_se else nn.Identity(),
nn.Conv2d(hidden_dim, out_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(out_channels)
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_residual:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV3LargeFeatures(nn.Module):
def __init__(self, width_mult=1.0):
super(MobileNetV3LargeFeatures, self).__init__()
self.width_mult = width_mult
settings = [
# k, t, c, SE, HS, s
[3, 1, 16, False, False, 1],
[3, 4, 24, False, False, 2],
[3, 3, 24, False, False, 1],
[5, 3, 40, True, False, 2],
[5, 3, 40, True, False, 1],
[5, 3, 40, True, False, 1],
[3, 6, 80, False, True, 2],
[3, 2.5, 80, False, True, 1],
[3, 2.3, 80, False, True, 1],
[3, 2.3, 80, False, True, 1],
[3, 6, 112, True, True, 1],
[3, 6, 112, True, True, 1],
[5, 6, 160, True, True, 2],
[5, 6, 160, True, True, 1],
[5, 6, 160, True, True, 1]
]
self.features = []
input_channels = make_divisible(16 * width_mult, 8)
layer1 = nn.Sequential(
nn.Conv2d(3, input_channels, 3, 2, 1, bias=False),
nn.BatchNorm2d(input_channels),
nn.Hardswish(inplace=True)
)
self.features.append(layer1)
for k, t, c, use_se, use_hs, s in settings:
output_channels = make_divisible(c * width_mult, 8)
layer = InvertedResidual(input_channels, output_channels, k, s, t, use_se, use_hs)
self.features.append(layer)
input_channels = output_channels
last_channels = make_divisible(960 * width_mult, 8)
layer_last = nn.Sequential(
nn.Conv2d(input_channels, last_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(last_channels),
nn.Hardswish(inplace=True)
)
self.features.append(layer_last)
self.features = nn.Sequential(*self.features)
def forward(self, x):
x = self.features(x)
return x
def make_divisible(v, divisor=8, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
# 创建 MobileNetV3-Large 特征提取模块
def mobilenet_v3_large_features(width_mult=1.0):
return MobileNetV3LargeFeatures(width_mult)
# 示例用法
if __name__ == "__main__":
model = mobilenet_v3_large_features(width_mult=1.0)
input_tensor = torch.randn(1, 3, 224, 224) # 假设输入图像大小为224x224
output = model(input_tensor)
print(output.shape) # 输出形状应为 (1, 960, 7, 7)代码解释:
-
h_swish 激活函数:
h_swish是一种改进的激活函数,定义为 x⋅ReLU6(x+3)/6x⋅ReLU6(x+3)/6。
-
SEBlock 模块:
SEBlock是一个 Squeeze-and-Excitation 模块,用于增强特征图的通道信息。- 通过全局平均池化、全连接层和激活函数,生成一个权重矩阵,然后将其与输入特征图相乘。
-
InvertedResidual 模块:
InvertedResidual是 MobileNet-V3 中的基本构建块,包括膨胀卷积、深度卷积、逐点卷积等。expand_ratio控制膨胀比例,use_se和use_hs分别控制是否使用 SE 模块和 h-swish 激活函数。use_residual控制是否使用残差连接。
-
MobileNetV3LargeFeatures 类:
- 初始化方法中定义了模型的各个层,包括初始卷积层、多个
InvertedResidual模块和最后一个逐点卷积层。 width_mult参数用于控制模型的宽度,可以用于创建不同大小的模型。make_divisible函数用于确保通道数是8的倍数,以提高计算效率。
- 初始化方法中定义了模型的各个层,包括初始卷积层、多个
-
mobilenet_v3_large_features 函数:
- 创建并返回一个 MobileNetV3-Large 特征提取模块。
-
示例用法:
- 创建一个
MobileNetV3LargeFeatures实例,并传入一个随机生成的输入张量,输出形状为(1, 960, 7, 7),这符合 MobileNetV3-Large 的特征提取部分的输出。
- 创建一个
五、模型优缺点
优点:
- 高效性:通过深度可分离卷积,MobileNet 显著减少了计算量和模型大小,适合在资源受限的环境中运行。
- 高准确率:尽管模型轻量化,但 MobileNet 在多个基准数据集上仍能保持较高的准确率。
- 灵活性:通过调整宽度乘子和分辨率乘子,可以在模型大小和计算成本之间进行权衡,以适应不同的应用场景。
- 广泛的适用性:MobileNet 不仅适用于图像分类任务,还可以用于目标检测、语义分割、人脸检测等多种视觉任务。
缺点:
- 特征提取能力有限:相比于更复杂的模型(如ResNet、EfficientNet等),MobileNet的特征提取能力较弱,可能在某些复杂任务上表现不佳。
- 优化难度:由于模型结构较为简单,可能需要更多的调参和优化才能达到最佳性能。
- 精度损失:在某些情况下,为了减少模型大小和计算量,可能会牺牲一定的精度。
MobileNet 通过引入深度可分离卷积,实现了在保持较高准确率的同时,大幅减少模型大小和计算成本的目标。它特别适合在移动设备和嵌入式系统上运行,是轻量化深度学习模型的典型代表。



















 2668
2668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









